Méthode de Viola et Jones
La méthode de Viola et Jones est une méthode de détection d'objet dans une image numérique, proposée par les chercheurs Paul Viola et Michael Jones en 2001. Elle fait partie des toutes premières méthodes capables de détecter efficacement et en temps réel des objets dans une image. Inventée à l'origine pour détecter des visages, elle peut également être utilisée pour détecter d'autres types d'objets comme des voitures ou des avions. La méthode de Viola et Jones a été l'une des méthodes les plus connues et les plus utilisées, en particulier pour la détection de visages et la détection de personnes.
| Nature | |
|---|---|
| Nommé en référence à |

En tant que procédé d'apprentissage supervisé, la méthode de Viola et Jones nécessite de quelques centaines à plusieurs milliers d'exemples de l'objet que l'on souhaite détecter, pour entraîner un classifieur. Une fois son apprentissage réalisé, ce classifieur est utilisé pour détecter la présence éventuelle de l'objet dans une image en parcourant celle-ci de manière exhaustive, à toutes les positions et dans toutes les tailles possibles.
Considérée comme étant l'une des plus importantes méthodes de détection d'objet, la méthode de Viola et Jones est notamment connue pour avoir introduit plusieurs notions reprises ensuite par de nombreux chercheurs en vision par ordinateur, à l'exemple de la notion d'image intégrale ou de la méthode de classification construite comme une cascade de classifieurs boostés.
Cette méthode bénéficie d'une implémentation sous licence BSD dans OpenCV, une bibliothèque très utilisée en vision par ordinateur.
Historique
Paul Viola et Michael Jones, alors employés au Cambridge Research Laboratory de la société américaine Compaq[1], publient la méthode qui porte leur nom pour la première fois le dans le journal scientifique International Journal of Computer Vision (IJCV)[2]. Les deux auteurs publient ensuite deux autres articles sur la méthode : une version moins détaillée, présentée à la Conference on Computer Vision and Pattern Recognition (CVPR) en [3] et une version révisée en 2004, toujours dans IJCV[4].
Les caractéristiques extraites par cette méthode sont inspirées des travaux de Papageorgiou, Oren et Poggio, datant de 1998[5],[2], qui utilisent des caractéristiques construites à partir d'ondelettes de Haar. La méthode s'inspire également de précédents travaux de Paul Viola et Kinh Tieu dans un autre domaine, celui de la recherche d'image par le contenu, en reprenant l'idée de sélection de caractéristiques par AdaBoost[6],[2]. Parmi les nombreuses méthodes de détection de visages publiées à l'époque[7], Viola et Jones considèrent en particulier celle de Rowley-Kanade[8] : en raison de ses excellents résultats et de sa rapidité, ils la prennent comme référence pour les comparaisons[2]. À performances équivalentes, Viola et Jones notent que la détection par leur méthode est 15 fois plus rapide que le détecteur de Rowley-Kanade[2].
La méthode, considérée comme l'une des plus efficaces en détection de visage, devient rapidement un standard dans ce domaine[9]. Les travaux de Viola et Jones sont parmi les plus utilisés et les plus cités par les chercheurs, et de nombreuses améliorations sont ainsi proposées[9],[10]. Leurs travaux sont également étendus à d'autres types d'objets que les visages et la méthode devient ainsi un standard en détection d'objet. La méthode est par ailleurs reconnue comme étant celle ayant eu le plus d'impact dans le domaine de la détection de visage dans les années 2000[11].
Éléments de la méthode
La méthode de Viola et Jones est une approche basée sur l'apparence[12], qui consiste à parcourir l'ensemble de l'image en calculant un certain nombre de caractéristiques dans des zones rectangulaires qui se chevauchent. Elle a la particularité d'utiliser des caractéristiques très simples mais très nombreuses. Une première innovation de la méthode est l'introduction des images intégrales, qui permettent le calcul rapide de ces caractéristiques. Une deuxième innovation importante est la sélection de ces caractéristiques par boosting, en interprétant les caractéristiques comme des classifieurs. Enfin, la méthode propose une architecture pour combiner les classifieurs boostés en un processus en cascade, ce qui apporte un net gain en temps de détection.
La méthode, en tant que méthode d'apprentissage supervisé, est divisée en deux étapes : une étape d'apprentissage du classifieur basé sur un grand nombre d'exemples positifs (c'est-à-dire les objets d'intérêt, par exemple des visages) et d'exemples négatifs, et une phase de détection par application de ce classifieur à des images inconnues.
Description

Plutôt que de travailler directement sur les valeurs de pixels, et pour être à la fois plus efficace et plus rapide, Viola et Jones proposent d'utiliser des caractéristiques, c'est-à-dire une représentation synthétique et informative, calculée à partir des valeurs des pixels. Viola et Jones définissent des caractéristiques très simples, les caractéristiques pseudo-Haar[2], qui sont calculées par la différence des sommes de pixels de deux ou plusieurs zones rectangulaires adjacentes. La figure ci-contre donne des exemples des caractéristiques proposées par Viola et Jones à 2, 3 ou 4 rectangles, dans lesquelles la somme de pixels sombres est soustraite de la somme des pixels blancs. Leur nom vient de leur similitude avec les ondelettes de Haar, précédemment proposées comme caractéristiques par Papageorgiou[5] et dont se sont inspirés Viola et Jones[2].
Pour calculer rapidement et efficacement ces caractéristiques sur une image, les auteurs proposent également une nouvelle méthode, qu'ils appellent « image intégrale ». C'est une représentation sous la forme d'une image, de même taille que l'image d'origine, qui en chacun de ses points contient la somme des pixels situés au-dessus de lui et à sa gauche. Plus formellement, l'image intégrale au point est définie à partir de l'image par[2] :




Grâce à cette représentation, une caractéristique formée de deux zones rectangulaires peut être calculée en seulement 6 accès à l'image intégrale, et donc en un temps constant quelle que soit la taille de la caractéristique[2].
Calcul
Les caractéristiques sont calculées à toutes les positions et à toutes les échelles dans une fenêtre de détection de petite taille, typiquement de 24 × 24 pixels[2] ou de 20 × 15 pixels[13]. Un très grand nombre de caractéristiques par fenêtre est ainsi généré, Viola et Jones donnant l'exemple d'une fenêtre de taille 24 × 24 qui génère environ 160 000 caractéristiques.
En phase de détection, l'ensemble de l'image est parcourue en déplaçant la fenêtre de détection d'un certain pas dans le sens horizontal et vertical (ce pas valant 1 pixel dans l'algorithme original[2]). Les changements d'échelles se font en modifiant successivement la taille de la fenêtre de détection[note 1]. Viola et Jones utilisent un facteur multiplicatif de 1,25, jusqu'à ce que la fenêtre couvre la totalité de l'image.
Finalement, et afin d'être plus robuste aux variations d'illumination, les fenêtres sont normalisées par la variance[2].
La conséquence de ces choix techniques, notamment le recours aux images intégrales, est un gain notable en efficacité, les caractéristiques étant évaluées très rapidement quelle que soit la taille de la fenêtre.
Sélection de caractéristiques par boosting
Le deuxième élément clé de la méthode de Viola et Jones est l'utilisation d'une méthode de boosting afin de sélectionner les meilleures caractéristiques. Le boosting est un principe qui consiste à construire un classifieur « fort » à partir d'une combinaison pondérée de classifieurs « faibles », c'est-à-dire donnant en moyenne une réponse meilleure qu'un tirage aléatoire. Viola et Jones adaptent ce principe en assimilant une caractéristique à un classifieur faible, en construisant un classifieur faible qui n'utilise qu'une seule caractéristique. L'apprentissage du classifieur faible consiste alors à trouver la valeur seuil de la caractéristique qui permet de mieux séparer les exemples positifs des exemples négatifs. Le classifieur se réduit alors à un couple (caractéristique, seuil).
L'algorithme de boosting utilisé est en pratique une version modifiée d'AdaBoost, qui est utilisée à la fois pour la sélection et pour l'apprentissage d'un classifieur « fort ». Les classifieurs faibles utilisés sont souvent des arbres de décision. Un cas remarquable, fréquemment rencontré, est celui de l'arbre de profondeur 1, qui réduit l'opération de classification à un simple seuillage.
L'algorithme est de type itératif, à nombre d'itérations déterminé. À chaque itération, l'algorithme sélectionne une caractéristique, qui sera ajoutée à la liste des caractéristiques sélectionnées aux itérations précédentes, et le tout va contribuer à la construction du classifieur fort final. Cette sélection se fait en entraînant un classifieur faible pour toutes les caractéristiques et en sélectionnant celui avec l'erreur la plus faible sur l'ensemble d'apprentissage. L'algorithme tient également à jour une distribution de probabilité sur l'ensemble d'apprentissage, réévaluée à chaque itération en fonction des résultats de classification. En particulier, plus de poids est attribué aux exemples difficiles à classer, c'est-à-dire ceux dont l'erreur est élevée. Le classifieur « fort » final construit par AdaBoost est composé de la somme pondérée des classifieurs sélectionnés.
Plus formellement, on considère un ensemble de images et leurs étiquettes associées , qui sont telles que si l'image est un exemple négatif et si est un exemple de l'objet à détecter. L'algorithme de boosting est constitué d'un nombre d'itérations, et pour chaque itération et chaque caractéristique , on construit un classifieur faible . Idéalement, le but est d'obtenir un classifieur qui prédise exactement les étiquettes pour chaque échantillon, c'est-à-dire . En pratique, le classifieur n'est pas parfait et l'erreur engendrée par ce classifieur est donnée par :













- ,

les étant les poids associés à chaque exemple et mis à jour à chaque itération en fonction de l'erreur obtenue à l'itération précédente. On sélectionne alors à l'itération le classifieur présentant l'erreur la plus faible : .



Le classifieur fort final est construit par seuillage de la somme pondérée des classifieurs faibles sélectionnés :


Les sont des coefficients calculés à partir de l'erreur .


Cascade de classifieurs
.svg.png.webp)
La méthode de Viola et Jones est basée sur une approche par recherche exhaustive sur l'ensemble de l'image, qui teste la présence de l'objet dans une fenêtre à toutes les positions et à plusieurs échelles. Cette approche est cependant extrêmement coûteuse en calcul. L'une des idées-clés de la méthode pour réduire ce coût réside dans l'organisation de l'algorithme de détection en une cascade de classifieurs. Appliqués séquentiellement, ces classifieurs prennent une décision d'acceptation — la fenêtre contient l'objet et l'exemple est alors passé au classifieur suivant —, ou de rejet — la fenêtre ne contient pas l'objet et dans ce cas l'exemple est définitivement écarté —. L'idée est que l'immense majorité des fenêtres testées étant négatives (c.-à-d. ne contiennent pas l'objet), il est avantageux de pouvoir les rejeter avec le moins possible de calculs. Ici, les classifieurs les plus simples, donc les plus rapides, sont situés au début de la cascade, et rejettent très rapidement la grande majorité des exemples négatifs[2]. Cette structure en cascade peut également s'interpréter comme un arbre de décision dégénéré, puisque chaque nœud ne comporte qu'une seule branche[2].
En pratique, la cascade est constituée d'une succession d'étages[note 2], chacune étant formée d'un classifieur fort appris par AdaBoost. L'apprentissage du classifieur de l'étage est réalisé avec les exemples qui ont passé l'étage ; ce classifieur doit donc faire face à un problème plus difficile : plus on monte dans les étages, plus les classifieurs sont complexes[2].

Le choix du nombre d'étages est fixé par l'utilisateur ; dans leur méthode originale, Viola et Jones utilisent étages. L'utilisateur doit également spécifier le taux de détection minimal et le taux de fausse alarme maximal à atteindre pour l'étage . Le taux de détection de la cascade est alors donné par :





et le taux de fausse alarme par :

En pratique, les taux et sont les mêmes pour tous les étages. Indirectement, ces taux déterminent également le nombre de caractéristiques utilisées par les classifieurs forts à chaque étage : les itérations d'Adaboost continuent jusqu'à ce que le taux de fausse alarme cible soit atteint. Des caractéristiques/classifieurs faibles sont ajoutés jusqu'à ce que les taux cibles soient atteints, avant de passer ensuite à l'étage suivant.
Pour atteindre des taux de détection et de fausse alarme corrects en fin de cascade, il est nécessaire que les classifieurs forts de chaque étage aient un bon taux de détection ; ils peuvent par contre avoir un taux de fausses alarmes élevé. Si l'on prend l'exemple d'une cascade de 32 étages, pour obtenir une performance finale et , chaque classifieur fort doit atteindre , mais peut se permettre (i.e. et ). Chaque étage ajouté diminue donc le nombre de fausses alarmes, mais aussi le taux de détection.






Plusieurs chercheurs font remarquer que cette idée de filtrer rapidement les exemples négatifs les plus simples n'est pas nouvelle[14],[15]. Elle existe dans d'autres méthodes sous forme d'heuristiques, comme la détection de la couleur chair[16],[17] ou une étape de pré-classification[17].
Étapes clés
Apprentissage
L'apprentissage est réalisé sur un très large ensemble d'images positives (c'est-à-dire contenant l'objet) et négatives (ne contenant pas l'objet). Plusieurs milliers d'exemples sont en général nécessaires. Cet apprentissage comprend :
- Le calcul des caractéristiques pseudo-Haar sur les exemples positifs et négatifs ;
- L'entraînement de la cascade : à chaque étage de la cascade, un classifieur fort est entraîné par AdaBoost. Il est construit par ajouts successifs de classifieurs faibles entraînés sur une seule caractéristique, jusqu'à l'obtention de performances conformes aux taux de détection et de fausse alarme souhaités pour l'étage.
Détection
La détection s'applique sur une image de test, dans laquelle on souhaite déceler la présence et la localisation d'un objet. En voici les étapes :
- parcours de l'ensemble de l'image à toutes les positions et échelles, avec une fenêtre de taille 24 × 24 pixels, et application de la cascade à chaque sous-fenêtre, en commençant par le premier étage :
- calcul des caractéristiques pseudo-Haar utilisées par le classifieur de l'étage courant,
- puis calcul de la réponse du classifieur,
- passage ensuite à l'étage supérieur si la réponse est positive, à la sous-fenêtre suivante sinon,
- et enfin l'exemple est déclaré positif si tous les étages répondent positivement ;
- fusion des détections multiples : l'objet peut en effet générer plusieurs détections, à différentes positions et échelles ; cette dernière étape fusionne les détections qui se chevauchent pour ne retourner qu'un seul résultat.
Performances
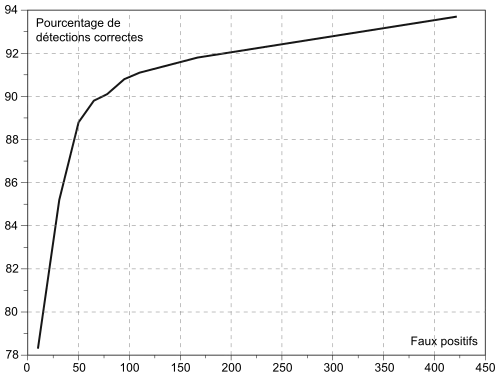
Viola et Jones ont testé leur algorithme sur la base de visages MIT+CMU, constituée de 130 images contenant 507 visages de face[8]. Ils présentent leur résultat sous la forme d'une courbe Receiver Operating Characteristic (ROC), qui donne le taux de détection correct en fonction du nombre de fausses alarmes total sur toutes les images du corpus. À titre d'exemple, pour 50 fausses alarmes, ils obtiennent un taux de détection de 88,8 %.
Viola et Jones comparent également les performances de leur méthode aux détecteurs de visages existants, notamment celui de Rowley-Kanade[8]. Ils constatent que les résultats sont globalement proches des autres détecteurs, quoique légèrement inférieures aux résultats de Rowley-Kanade pour un faible nombre de fausses alarmes, et légèrement supérieurs pour un nombre de fausses alarmes élevées[2].
La rapidité de détection, pour sa part, dépend directement du nombre de caractéristiques évaluées, donc du contenu de l'image. Sur un PC Pentium III cadencé à 700 MHz, les auteurs rapportent un temps de traitement moyen de 0,067 secondes pour une image de taille 384 × 288 pixels, correspondant à débit moyen de 15 images par seconde, assez proche des exigences du traitement vidéo en temps réel (soit 25 images par seconde). Finalement, sur la base de visages MIT+CMU, leur détecteur est 15 fois plus rapide que celui de Rowley-Kanade et 600 fois plus rapide que celui de Schneiderman-Kanade, pour des taux de détection et de fausse alarme comparables[2].
Limitations et extensions

De très nombreuses améliorations ont été proposées par la suite, visant à améliorer le paramétrage de la méthode, ou à en combler un certain nombre de limitations.
L'une des premières améliorations est apportée par Lienhart et Maydt en 2002[18]. Ils proposent d'étendre l'ensemble de caractéristiques pseudo-Haar utilisé de 4 à 14 caractéristiques. De même, ils introduisent des caractéristiques « de biais » (tournées de 45°), ainsi qu'une méthode pour les calculer basée sur une extension des images intégrales[18].
D'autres types de caractéristiques ont également été utilisées en remplacement des caractéristiques de Haar : les histogrammes de gradients orientés[19], les motifs binaires locaux ou la covariance de région[20]. Les chercheurs ont également proposé d'utiliser des variantes de l'algorithme de boosting, notamment RealBoost, qui produit un indice de confiance à valeurs réelles, en plus de la classification[21]. Plusieurs travaux ont ainsi montré la supériorité de RealBoost sur AdaBoost dans le cadre de l'algorithme de Viola et Jones[10],[22]
Viola et Jones étendent en 2003 leur système à la détection de piétons dans des vidéos, en incluant une information de mouvement en plus de l'information d'apparence[13].
Une des limitations de la méthode est son manque de robustesse à la rotation, et sa difficulté à apprendre plusieurs vues d'un même objet. En particulier, il est difficile d'obtenir un classifieur capable de détecter à la fois des visages de face et de profil. Viola et Jones ont proposé une amélioration qui permet de corriger ce défaut[23], qui consiste à apprendre une cascade dédiée à chaque orientation ou vue, et à utiliser lors de la détection un arbre de décision pour sélectionner la bonne cascade à appliquer. Plusieurs autres améliorations ont été proposées par la suite pour apporter une solution à ce problème[24],[25].
Une autre limitation importante de la méthode de Viola et Jones concerne le temps d'apprentissage de la cascade, compris généralement entre plusieurs jours et plusieurs semaines de calcul[2],[26], ce qui limite sévèrement les possibilités de tests et de choix des paramètres[27].
Un des problèmes majeurs de la méthode proposée par Viola et Jones est qu'il n'existe pas de méthode optimale pour choisir les différents paramètres régissant l'algorithme : le nombre d'étages, leur ordre ou les taux de détection et de fausses alarmes pour chaque étage doivent être choisis par essais et erreurs[10],[15]. Plusieurs méthodes sont proposées pour déterminer certains de ces seuils de manière automatique[10],[15],[28].
Un reproche également fait à la méthode concerne la perte d'information subie au passage d'un étage à l'autre de la cascade, perte due à l'effet couperet des décisions d'acceptation ou de rejet prises à chaque étage. Certains chercheurs proposent la solution de garder l'information contenue dans la somme pondérée des classifieurs faibles, par exemple le « boosting chain » de Xiao[29]. Une modification plus radicale de structure est proposée par Bourdev et sa notion de cascade souple, qui consiste essentiellement à supprimer le concept d'étages, en formant un seul classifieur fort, donc une seule somme, et en permettant de prendre une décision à chaque évaluation de classifieur faible et de s'affranchir de la contrainte des taux de détection et de fausses alarmes cibles[15].
Applications

La méthode de Viola et Jones a essentiellement été appliquée à la détection de visage et à la détection de personne, principalement en raison des nombreuses applications pratiques qu'offrent ces deux domaines, notamment en vidéosurveillance, en indexation d'images et de vidéo ou pour les interfaces homme-machine multimodales[30]. Un exemple d'application grand public de la méthode est donné par les appareils photographiques numériques, où elle sert à effectuer la mise au point automatique sur les visages. Combinée avec le standard JPEG 2000, la méthode peut également servir à compresser les visages avec un taux de compression plus faible que le reste de l'image, afin de préserver les détails des visages[31]. Les constructeurs automobiles s'intéressent également à la méthode pour concevoir des systèmes de sécurité capables de détecter automatiquement les autres usagers de la route, en particulier les piétons[32]. Des recherches ont également montré que l'efficacité de la méthode ne se limite pas au domaine visible, mais qu'elle s'étend également au domaine infrarouge[33].
La méthode de Viola et Jones a également été utilisée pour détecter d'autres types d'objets, par exemple des mains, pour la commande gestuelle d'une interface homme-machine[25], des voitures dans des images satellites pour la création de systèmes d'information géographique débarrassés de toute présence visuelle d'automobiles[34], ou pour l'évaluation et le suivi du trafic routier[35].
La méthode a également été évaluée pour la détection d'avions dans des images de basse résolution à partir d'une caméra embarquée dans un véhicule aérien, pour l'évitement de collisions[36]. Des applications militaires existent aussi pour la détection de cibles (chars, avions) dans des images aériennes ou satellitaires[37].
Implémentations
Il existe de nombreuses implémentations du détecteur de Viola et Jones, la plus utilisée étant celle en C++ présente dans la libraire de vision par ordinateur OpenCV, publiée sous licence BSD. Des implémentations ont été développées pour des environnements ou plates-formes spécifiques, notamment pour une exécution dans des navigateurs Web en utilisant le langage de script ActionScript du logiciel multimédia Flash[38]. Des implémentations matérielles ont également été développées sur ASIC[39], FPGA[40] et sur GPU[41]. L'utilisation de l'architecture parallèle de ces derniers permet un net gain de temps de détection par rapport à l'implémentation OpenCV traditionnelle[41].
Enfin, les implémentations les plus courantes sont celles rencontrées dans les appareils photographiques numériques pour la mise au point automatique par la détection de visage[42]. Elles nécessitent des optimisations particulières pour faire face à la faible puissance de calcul de ce type de matériel[42].
Notes et références
- Notes
- Les méthodes alternatives recourent principalement à la construction d'une pyramide d'images.
- On utilise parfois le terme de « couche » pour désigner un étage.
- Références
- (en) « Page personnelle de Paul Viola » (consulté le ).
- (en) Paul Viola et Michael Jones, « Robust Real-time Object Detection », IJCV, (lire en ligne).
- (en) Paul Viola et Michael Jones, « Rapid Object Detection using a Boosted Cascade of Simple Features », IEEE CVPR, (lire en ligne).
- (en) Paul Viola et Michael Jones, « Robust Real-time Face Detection », IJCV, , p. 137-154.
- (en) C. Papageorgiou, M. Oren et T. Poggio, « A General Framework for Object Detection », International Conference on Computer Vision, .
- (en) K. Tieu et P. Viola, « Boosting image retrieval », IEEE CVPR, .
- (en) M.-H. Yang, D. J. Kriegman et N. Ahuja, « Detecting faces in images: A survey », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no 1, , p. 34–58.
- (en) H. Rowley, S. Baluja et T. Kanade, « Neural network-based face detection », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, , p. 22–38 (lire en ligne).
- Szeliski (2010), p. 656.
- (en) S. Charles Brubaker, Matthew D. Mullin et James M. Rehg, « Towards Optimal Training of Cascaded Detectors », ECCV, .
- (en) Cha Zhang et Zhengyou Zhang, « A Survey of Recent Advances in Face Detection », Microsoft Research, (lire en ligne).
- Szeliski (2010) p. 653.
- (en) P. Viola, M. Jones et D. Snow, « Detecting Pedestrians using Patterns of Motion and Appearance », IJCV, vol. 63, no 2, , p. 153-161.
- (en) H. Schneiderman, « Feature-centric Evaluation for Efficient Cascaded Object Detection », IEEE CVPR, .
- (en) L. Bourdev et J. Brandt, « Robust Object Detection via Soft Cascade », CVPR, , p. 236-243.
- (en) H. Schneiderman et T. Kanade, « Object detection using the statistics of parts », IJCV, .
- (en) R. Féraud, O. Bernier, J. Viallet et M. Collobert, « A fast and accurate face detector based on neural networks », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no 1, .
- (en) Rainer Lienhart et Jochen Maydt, « An Extended Set of Haar-like Features for Rapid Object Detection », IEEE ICIP, .
- (en) Qiang Zhu, Shai Avidan, Mei C. Yeh et Kwang T. Cheng, « Fast Human Detection Using a Cascade of Histograms of Oriented Gradients », IEEE CVPR, , p. 1491-1498.
- (en) O. Tuzel, F. Porikli et P. Meer, « Human Detection via Classification on Riemannian Manifolds », IEEE CVPR, , p. 1–8,.
- (en) Jerome Friedman, Trevor Hastie et Robert Tibshirani, « Additive logistic regression: a statistical view of boosting », Annals of Statistics, vol. 28, .
- (en) Bo Wu, Haizhou Ai, Chang Huang et Shihong Lao, « Fast rotation invariant multi-view face detection based on real adaboost », IEEE International Conference on Automatic Face and Gesture Recognition, , p. 79–84.
- (en) M. Jones et P. Viola, « Fast Multi-view Face Detection », IEEE CVPR, .
- (en) A. L. C. Barczak, « Toward an Efficient Implementation of a Rotation Invariant Detector using Haar-Like Features », dans Proceedings of the 2009 IEEE/RSJ international conference on Intelligent robots and systems, Nouvelle-Zélande, Dunedin, (lire en ligne), p. 31-36.
- (en) M. Kölsch et M. Turk, « Analysis of Rotational Robustness of Hand Detection with a Viola-Jones Detector », ICPR, vol. 3, (lire en ligne).
- Szeliski (2010), p. 658.
- (en) C. Zhang et P. Viola, « Multiple instance pruning for learning efficient Cascade detectors », Neural Information Processing Systems, .
- (en) J. Sun, J. Rehg et A. Bobick, « Automatic cascade training with perturbation bias », IEEE CVPR, .
- (en) R. Xiao, L. Zhu et H.-J. Zhang, « Boosting Chain Learning for Object Detection », ICCV, , p. 709-715.
- (en) Reinlien Hsu et Anil K. Jain, « Face detection in color images », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no 5, , p. 696-706.
- (en) Andrew P. Bradley et Fred W. M. Stentiford, « JPEG 2000 and Region of Interest Coding », dans DICTA2002: Digital Image Computing Techniques and Applications, Melbourne, (lire en ligne), p. 21-22.
- (en) Fabien Moutarde, Bogdan Stanciulescu et Amaury Breheret, « Real-time visual detection of vehicles and pedestrians with new efficient adaBoost features », dans Workshop on Planning, Perception and Navigation for Intelligent Vehicles, Nice, (lire en ligne).
- (en) Li Zhang, Bo Wu et R. Nevatia, « Pedestrian Detection in Infrared Images based on Local Shape Features », CVPR, , p. 1-8.
- (en) F. Leberl, H. Bischof, H. Grabner et S. Kluckner, « Recognizing cars in aerial imagery to improve orthophotos », dans International symposium on Advances in geographic information systems, ACM, (lire en ligne), p. 1–9.
- (en) L. Eikvil, L. Aurdal et H. Koren, « Classification-based vehicle detection in high-resolution satellite images », ISPRS Journal of Photogrammetry and Remote Sensing, vol. 64, no 1, , p. 65–72 (lire en ligne).
- (en) Stavros Petridis, Christopher Geyer et Sanjiv Singh, « Learning to detect aircraft at low resolutions », ICVS, vol. 5008/2008, , p. 474-483.
- Xavier Perrotton, Détection automatique d’objets dans les images numériques : application aux images aériennes, (thèse), Télécom ParisTech, .
- (en) Theo Ephraim, Tristan Himmelman et Kaleem Siddiqi, « Real-Time Viola-Jones Face Detection in a Web Browser », dans Proceedings of the 2009 Canadian Conference on Computer and Robot Vision, IEEE Computer Society, (ISBN 978-0-7695-3651-4), p. 321-328.
- (en) T. Theocharides, N. Vijaykrishnan et M. J. Irwin, « A Parallel Architecture for Hardware Face Detection », dans IEEE Computer Society Annual Symposium on VLSI: Emerging VLSI Technologies and Architectures (ISVLSI'06), Karlsruhe, (ISBN 0-7695-2533-4), p. 452-453.
- (en) Junguk Cho, Bridget Benson, Shahnam Mirzaei et Ryan Kastner, « Parallelized architecture of multiple classifiers for face detection », dans Proceedings of the 2009 20th IEEE International Conference on Application-specific Systems, Architectures and Processors, (lire en ligne), p. 75-82.
- (en) Daniel Hefenbrock, Jason Oberg, Nhat Tan Nguyen Thanh, Ryan Kastner et Scott B. Baden, « Accelerating Viola-Jones Face Detection to FPGA-Level using GPUs », dans 18th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, Charlotte (USA), (ISBN 978-0-7695-4056-6, lire en ligne), p. 11-18.
- (en) Jianfeng Ren, N. Kehtarnavaz et L. Estevez, « Real-time optimization of Viola -Jones face detection for mobile platforms », dans Circuits and Systems Workshop: System-on-Chip - Design, Applications, Integration, and Software, Dallas, , p. 1-8.
Bibliographie
(en) Richard Szeliski, Computer Vision: Algorithms and Applications, Springer, ![]()
Voir aussi
Articles connexes
Liens externes
 Portail de l’imagerie numérique
Portail de l’imagerie numérique