Quartet d'Anscombe
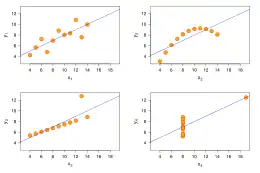
Le quartet d'Anscombe est constitué de quatre ensembles de données qui ont les mêmes propriétés statistiques simples mais qui sont en réalité très différents, ce qui se voit facilement lorsqu'on les représente sous forme de graphiques. Ils ont été construits en 1973 par le statisticien Francis Anscombe dans le but de démontrer l'importance de tracer des graphiques avant d'analyser des données, car cela permet notamment d'estimer l'incidence des données aberrantes sur les différentes indices statistiques que l'on pourrait calculer.
| Nommé en référence à | |
|---|---|
| Producteur | |
| Décrit par |
Graphs in Statistical Analysis (d) |
Dans la première page du premier chapitre de son ouvrage, The Visual Display of Quantitative Information, Edward Tufte utilise le quartet d'Anscombe pour démontrer l'importance de l'exploration graphique avant d'analyser un ensemble de données
Présentation
Chaque ensemble de données contient 11 points. Les quatre ensembles présentent ces propriétés :
| Propriété | Valeur |
|---|---|
| Moyenne des x | 9,0 |
| Variance des x | 10,0 |
| Moyenne des y | 7,5 |
| Variance des y | 3,75 |
| Coefficient de corrélation entre les x et les y | 0,816 |
| Équation de la droite de régression linéaire | y=3 + 0,5 x |
| Somme des carrés des erreurs relativement à la moyenne |
110,0 |
Le premier ensemble (en haut à gauche) présente deux variables (x et y) dont la distribution semble proche d'une loi normale et qui présentent entre elles une simple corrélation linéaire (avec un certain degré de bruit qui la rend donc imparfaite).
Le deuxième (en haut à droite) se caractérise par une relation non linéaire (en l'occurrence parfaitement quadratique) entre les deux variables : pour cette raison, les coefficients de corrélation de Pearson sont inappropriés car ils mesurent l'écart à une droite de régression et non à une parabole.
Dans le troisième ensemble (en bas à gauche), la corrélation linéaire est parfaite (avec une pente légèrement inférieure à 3) sauf pour une donnée aberrante qui influe sur le coefficient de corrélation global, le faisant passer de 1 (pour les 10 premières données) à 0,81 (pour les 11 données).
Finalement, le quatrième ensemble (en bas à droite) démontre qu'une seule donnée aberrante suffit pour obtenir un coefficient de corrélation élevé, alors même que, hormis cette 11e donnée, il n'existe pas de corrélation entre les deux variables puisque la variable x est constante.
Les ensembles de données sont comme suit (les valeurs des x sont les mêmes pour les trois premiers ensembles).
| I | II | III | IV | ||||
|---|---|---|---|---|---|---|---|
| x | y | x | y | x | y | x | y |
| 10,0 | 8,04 | 10,0 | 9,14 | 10,0 | 7,46 | 8,0 | 6,58 |
| 8,0 | 6,95 | 8,0 | 8,14 | 8,0 | 6,77 | 8,0 | 5,76 |
| 13,0 | 7,58 | 13,0 | 8,74 | 13,0 | 12,74 | 8,0 | 7,71 |
| 9,0 | 8,81 | 9,0 | 8,77 | 9,0 | 7,11 | 8,0 | 8,84 |
| 11,0 | 8,33 | 11,0 | 9,26 | 11,0 | 7,81 | 8,0 | 8,47 |
| 14,0 | 9,96 | 14,0 | 8,10 | 14,0 | 8,84 | 8,0 | 7,04 |
| 6,0 | 7,24 | 6,0 | 6,13 | 6,0 | 6,08 | 8,0 | 5,25 |
| 4,0 | 4,26 | 4,0 | 3,10 | 4,0 | 5,39 | 19,0 | 12,50 |
| 12,0 | 10,84 | 12,0 | 9,13 | 12,0 | 8,15 | 8,0 | 5,56 |
| 7,0 | 4,82 | 7,0 | 7,26 | 7,0 | 6,42 | 8,0 | 7,91 |
| 5,0 | 5,68 | 5,0 | 4,74 | 5,0 | 5,73 | 8,0 | 6,89 |
Des procédures pour créer d'autres ensembles de données exhibant les mêmes propriétés statistiques simples, mais des représentations graphiques dissemblables, sont proposées dans les ouvrages de la bibliographie.
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Anscombe's quartet » (voir la liste des auteurs).
Voir aussi
Liens externes
- (en) « Visualisation and Transformation of Data », Department of Physics, Université de Toronto
- (en) « Curve fitting », Central Queensland University, Australie
Bibliographie
- F. J. Anscombe, Graphs in Statistical Analysis, Am. Stat., vol. 27, n°1, 1973, pp. 17-21. DOI:10.1080/00031305.1973.10478966 JSTOR:2682899
- Edward Tufte, The Visual Display of Quantitative Information, 2nd Edition, Cheshire, 2001. (ISBN 0961392142)
- Sangit Chatterjee et Aykut Firat, Generating Data with Identical Statistics but Dissimilar Graphics: A Follow up to the Anscombe Dataset, Am. Stat., vol. 61, n°3, pp. 248-254 DOI:10.1198/000313007X220057 JSTOR:27643902
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique