Test statistique
En statistiques, un test, ou test d'hypothèse, est une procédure de décision entre deux hypothèses. Il s'agit d'une démarche consistant à rejeter ou à ne pas rejeter une hypothèse statistique, appelée hypothèse nulle, en fonction d'un échantillon de données.
Pour les articles homonymes, voir Test.
Il s'agit de statistique inférentielle : à partir de calculs réalisés sur des données observées, on émet des conclusions sur la population, en leur rattachant des risques d'être erronées.
Hypothèses du test
Définitions
L'hypothèse nulle notée H0 est celle que l'on considère vraie a priori. L’hypothèse est donc privilégiée et il faut des observations très éloignées de cette hypothèse pour la rejeter. Le but du test est de décider si cette hypothèse est a priori crédible. L'hypothèse alternative notée H1 est l'hypothèse complémentaire à l'hypothèse nulle.

Ces deux hypothèses ne sont toutefois pas symétriques. H1 est choisie uniquement par défaut si H0 n'est pas considérée comme crédible, étant l'hypothèse dont le rejet à tort est le plus préjudiciable. Le choix de H0 et de H1 est en général imposé par le test que l'on utilise et ne relève donc pas de l'utilisateur.
Écriture des hypothèses : exemple
Soit μ1 et μ2 les moyennes de tension artérielle de deux populations, l'une correspondant à la prise de médicament et l'autre de placebo. Une manière de démontrer qu'un médicament modifie la tension artérielle est de montrer que μ1 est différent de μ2. Les hypothèses du test deviennent alors
- H0 : les moyennes des deux populations sont égales et
- H1 : les moyennes des deux populations sont différentes.
On l'écrit succinctement sous la forme :


Toutefois les signes =, ≠, ≤ et ≥ dans l'écriture succincte des hypothèses ne correspond pas à l'égalité ou aux inégalités au sens mathématique du terme. Il s'agit d'une façon d'écrire :
- H0 : Il est crédible de penser que μ1 = μ2
- H1 : μ1 est significativement différente de μ2
Cependant, il convient également de faire attention aux fluctuations d'échantillonnage. En effet, lors de la réalisation d'un test on utilise le plus souvent des échantillons pour effectuer les calculs. On utilisera donc les moyennes et calculées à partir des échantillons et qui ne sont donc que des estimations de μ1 et μ2 (voir taille d'effet).


Statistique du test
La statistique de test S est une fonction qui résume l'information sur l'échantillon que l'on souhaite tester. On la choisit de façon à connaître sa loi sous H0.
S est une variable aléatoire, définie indépendamment des données observées. La valeur que prend cette variable aléatoire pour les données observées est appelée statistique observée et est notée Sobs dans la suite de l'article.
Suivant le type de statistique choisi, le test sera paramétrique ou non paramétrique.[Quoi ?]
Construction d'un test
La construction mathématique d'un test se fait grâce au lemme de Neyman-Pearson et nous donne la forme de la région de rejet.
Région de rejet et latéralité
La région de rejet est le sous-ensemble I de tel qu'on rejette H0 si Sobs appartient à I. La forme de la région de rejet définit la latéralité du test :

- Test bilatéral : On veut rejeter H0 si Sobs est trop grand ou trop petit, sans a priori. La région de rejet est alors de la forme .
- Test unilatéral à droite : On veut rejeter H0 seulement si Sobs est trop grand. La région de rejet est alors de la forme .
- Test unilatéral à gauche : On veut rejeter H0 seulement si Sobs est trop petit. La région de rejet est alors de la forme .



Probabilité critique
La probabilité critique (ou valeur p) est la probabilité, sous H0, que la statistique soit au moins aussi éloignée de son espérance que la valeur observée. En d'autres termes, c'est la probabilité d'observer quelque chose d'au moins aussi surprenant que ce que l'on observe.
Erreur de type I et II
Risque de première espèce et confiance
Le risque de première espèce α est la probabilité sous H0 de la région de rejet. En d'autres termes, il s'agit de la probabilité que l'on accepte de décider H1 si la vérité est H0.

La quantité 1 – α est la confiance du test. En d'autres termes, une proportion α des situations dans lesquelles la vérité est H0 verront une décision du test en faveur de H1. α est la probabilité avec laquelle on accepte de se tromper[Sur quoi ?] quand la vérité est H0[pas clair].
On peut comparer la valeur p à α plutôt que Sobs et la région de rejet[pas clair].
- Si la valeur p est supérieure à α, il n'est pas exceptionnel sous H0 d'observer la valeur effectivement observée. Par conséquent, H0 n'est pas rejetée.
- Si la valeur p est inférieure à α, la valeur observée est jugée exceptionnelle sous H0. On décide alors de rejeter H0 et de valider H1.
Cette méthode possède l'avantage de permettre de se rendre compte à quel point la décision du test est sûre : la position de la valeur p par rapport à α ne dépend pas de l'échelle des données, contrairement à Sobs et au(x) seuil(s) de la région de rejet.
Les valeurs du risque α couramment utilisées varient généralement entre 0,01 et 0,05. Dans le cas de variables continues, on peut choisir une valeur arbitraire de α et obtenir une région de rejet présentant exactement le risque α. Dans le cas de variables discrètes, le nombre de région de rejet, et donc de risques possibles, est fini et dénombrable. Dans ce cas, on fixe un risque, dit risque nominal par exemple de 5 %. On cherche alors la plus grande région ne dépassant pas ce risque, qui devient alors la région de rejet. Le véritable risque, dit risque réel peut alors être recalculé.
Risque de deuxième espèce et puissance
Le risque de deuxième espèce β est la probabilité de ne pas rejeter H0 alors que la vérité est H1. Il s'agit d'un risque qui n'est pas fixé a priori par le test, et il est souvent difficile à estimer. On prend ce risque lorsqu'on accepte l'hypothèse H0.

La quantité 1 – β est la puissance du test[1].
Choix de α et β
Pour se représenter ces différentes notions, on peut les représenter au travers du tableau suivant :

Le choix de α et de β se fait de façon assez arbitraire car si l'on cherche à en diminuer un l'autre va automatiquement augmenter. On définit généralement le risque α de façon arbitraire et la valeur du risque β s'ajuste automatiquement. Ce choix détermine alors une valeur seuil (notée S sur le schéma) qui représente la valeur de bascule pour la statistique du test entre les deux décisions (rejet ou non-rejet de H0). Le graphique suivant tente de représenter visuellement ces risques, la courbe noire représente la loi ici normale de la statistique du test sous l'hypothèse H0 et la courbe bleue représente la loi ici normale de la statistique du test sous l'hypothèse H1.

Si l'échantillon reste inchangé, une diminution de α entraîne une augmentation de β et inversement. Autrement dit, si on décide de réduire le nombre de faux positifs, on augmente le nombre de faux négatifs. La seule manière d'améliorer les deux critères est d'augmenter la taille de l'échantillon.
Courbe de puissance
Pour déterminer la puissance d'un test, il faut connaître la loi de la statistique S sous H1, ce qui n'est généralement pas le cas. On recourt alors à des courbes de puissance qui sont des courbes pour lesquelles la puissance est calculée pour des valeurs données des paramètres du problème ou de la taille de l'échantillon. On ne sait pas où se situe la situation réelle sur cette courbe mais on y lit la probabilité de détecter H1 en fonction de son « éloignement » de H0.
Tests classiques et tests bayésiens
Pour les tests classiques qui constituèrent longtemps[Quand ?] l'essentiel des tests statistiques, ces deux erreurs jouent un rôle asymétrique. On contrôle uniquement le risque de première espèce à un niveau α (principe de Neyman) ; cela revient à considérer que le risque de rejeter l'hypothèse nulle alors que cette hypothèse est vraie est beaucoup plus coûteux que celui de la conserver à tort (ce dernier risque n'étant pas maîtrisé).
Les tests bayésiens, qui commencent à compléter les méthodes classiques dans les années 1970 à mesure que se répandent les ordinateurs, pondèrent ces deux risques en représentant par une loi la connaissance incertaine de cette probabilité. Si on cherche par exemple à tester le fait qu'un certain paramètre θ vaut une certaine valeur θ0 cette probabilité a priori sera une loi de θ sur son domaine de plausibilité. Cette loi a priori modélise l'incertitude admise sur sa valeur. Les tests correspondants utilisent en coulisses des calculs plus complexes, mais sans difficulté de mise en œuvre supplémentaire quand ils sont effectués par des sous-programmes. Ils nécessitent de choisir une loi a priori, répondant aux contraintes connues, parmi celles d'entropie maximale puis de l'affiner à mesure des observations en la mettant à jour par la règle de Bayes (voir Théorème de Cox-Jaynes). Leur mérite essentiel est de permettre la consolidation d'informations minuscules apportés par un grand nombre d'échantillons hétéroclites qui auraient chacun été considéré comme non significatif par les méthodes classiques. Cette consolidation permet d'obtenir des résultats utiles à partir d'observations très ténues. On l'utilise par exemple en cassage de codes, en analyse d'image et en reconnaissance vocale, ainsi qu'en deep learning.
Tests paramétriques et non paramétriques
Définitions
Un test paramétrique est un test pour lequel on fait une hypothèse paramétrique sur la loi des données sous H0 (loi normale, loi de Poisson...); Les hypothèses du test concernent alors les paramètres de cette loi.
Un test non paramétrique est un test ne nécessitant pas d'hypothèse sur la loi des données. Les données sont alors remplacées par des statistiques ne dépendant pas des moyennes/variances des données initiales (tableau de contingence, statistique d'ordre comme les rangs...).[pas clair]
Comment choisir ?
Les tests paramétriques, quand leur utilisation est justifiée, sont en général plus puissants que les tests non paramétriques. Les tests paramétriques reposent cependant sur l'hypothèse forte que l'échantillon considéré est tiré d'une population suivant une loi appartenant à une famille donnée. Il est possible de s'en affranchir pour des échantillons suffisamment grands en utilisant des théorèmes asymptotiques tels que le théorème central limite. Les tests non paramétriques sont cependant à préférer dans de nombreux cas pratiques pour lesquels les tests paramétriques ne peuvent être utilisés sans violer les postulats dont ils dépendent (notamment dans le cas d'échantillons trop petits c'est-à-dire, par convention, quand l'effectif de l'échantillon est inférieur à 30). Les données sont également parfois récupérées sous forme de rangs et non de données brutes. Seuls les tests non paramétriques sont alors applicables.
Lorsque les données sont quantitatives, les tests non paramétriques transforment les valeurs en rangs. L’appellation « tests de rangs » est souvent rencontrée. Lorsque les données sont qualitatives, seuls les tests non paramétriques sont utilisables. La distinction paramétrique – non paramétrique est essentielle. Elle est systématiquement mise en avant dans la littérature. Les tests non paramétriques, en ne faisant aucune hypothèse sur les lois des données, élargissent le champ d’application des procédures statistiques. En contrepartie, ils sont moins puissants lorsque ces hypothèses sont compatibles avec les données.
Efficacité relative asymptotique
On fixe une confiance 1 – α, une puissance 1 – β. Soit une suite d'hypothèses alternatives (se rapprochant de H0) et n1k et n2k les tailles d'échantillons pour que T1 et T2 (deux tests statistiques) aient la même puissance 1 – β sous l'hypothèse . Sous certaines conditions, le quotient tend vers une constance, que l'on nomme efficacité relative asymptotique (ou ERA), quand k tend vers l'infini.



Une ERA de 2 signifie que pour détecter la même différence, il faut asymptotiquement des échantillons deux fois plus grands pour T2 que pour T1 pour obtenir la même puissance, cela implique que T1 est plus « efficace ». Cette mesure est asymptotique mais en pratique, l'efficacité pour des petits échantillons se révèle souvent proche de l'efficacité asymptotique.
Considérons l'exemple où T1 est le test du signe pour H0 : m = 0 et T2 est le test t pour H0 : μ = 0, dans le cas de lois symétriques. On peut montrer que l'ERA est de 2π (donc inférieure à 1) pour des lois normales et supérieure à 1 pour d'autres lois comme les doubles exponentielles ou les lois de Laplace. Même en cas de validité des tests paramétriques, les tests non paramétriques peuvent donc être concurrentiels, d'autant plus que la puissance de calcul des ordinateurs actuels permet maintenant leur utilisation sur de grands échantillons.
Notions de sensibilité et de spécificité
Distinctions préalables
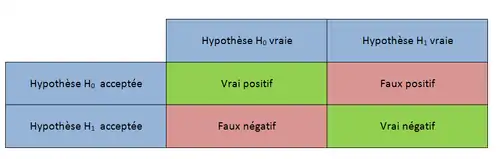
On distingue quatre types de données : les faux positifs, les faux négatifs, les vrais positifs et les vrais négatifs. Ces quatre types se recoupent avec les notions décrites précédemment que sont le risque α, le risque β, la puissance et la confiance.
Un vrai positif est un test qui a conduit à la décision d'accepter l'hypothèse H0 quand cette dernière était effectivement vraie. Un vrai négatif est un test qui a conduit à la décision de ne pas accepter l'hypothèse H0 quand cette dernière était effectivement fausse. À l'inverse, un faux positif est un test qui a conduit à la décision d'accepter l'hypothèse H0 alors que cette dernière était fausse et un faux négatif est un test qui a conduit à la décision de ne pas accepter l'hypothèse H0 alors que cette dernière était vraie. Ces notions sont très utilisées dans le cadre d'études épidémiologiques.
Sensibilité et spécificité
La sensibilité d'un test désigne la probabilité que le test conclu à une acceptation de H0 si cette dernière est vraie. Elle est donnée par . En épidémiologie, la sensibilité d'un test est sa capacité à identifier un individu comme étant malade si la maladie est effectivement présente.

La spécificité d'un test désigne la probabilité que le test conclu à un rejet de H0 si cette dernière est fausse. Elle est donnée par . En épidémiologie, la spécificité d'un test est sa capacité à identifier un individu comme n'étant pas malade si la maladie n'est effectivement pas présente.

Mises ensemble, ces deux valeurs donnent une appréciation de la validité du test. Leur analyse séparée est inutile car un test ayant une sensibilité de 95 % n'est pas très bon si sa spécificité n'est que de 5 %. Si la somme de la sensibilité et de la spécificité vaut 100 % cela signifie que le test est sans intérêt. De plus, les valeurs de sensibilité et de spécificité d'un test dépendent beaucoup de la valeur seuil choisie. En effet, à l'instar des risques α et β, la sensibilité d'un test diminue quand sa spécificité augmente et inversement. Il convient donc également de choisir la valeur seuil selon l'utilisation que l'on désire faire du test. Un test très sensible sera utile pour vérifier que H0 est vraie par exemple.
Valeur prédictive positive et valeur prédictive négative
La valeur prédictive positive est la probabilité que H0 soit vraie lorsque le test conclu à son acceptation. Elle est donnée par .

La valeur prédictive négative est la probabilité que H0 soit fausse lorsque le test conclu à son rejet. Elle est donnée par .

Cependant, ces calculs sont valides uniquement si l'échantillon sur lequel est réalisé le test est représentatif de la population (cf Échantillonnage). Ainsi, pour une même sensibilité et spécificité, la valeur prédictive négative d'un test donné va s'améliorer d'autant que la probabilité que H0 soit vraie est faible et la valeur prédictive positive du même test va s'améliorer d'autant que la probabilité que H0 soit vraie est élevée. Pour calculer les valeurs prédictives d'un test lorsque la représentativité de l'échantillon n'est pas certaine, on utilise des formulations reposant sur le théorème de Bayes, en utilisant la sensibilité et la spécificité calculées sur l'échantillon et la prévalence de l'affection à diagnostiquer. Lorsqu’un test a une bonne valeur prédictive positive, c’est surtout quand son résultat est positif qu’il est fiable. De la même manière, un test avec une bonne valeur prédictive négative est fiable lorsque son résultat est négatif. Par exemple, un test avec une bonne valeur prédictive négative et une mauvaise valeur prédictive positive donne une information valable s’il est négatif mais est difficile à interpréter si son résultat est positif.
Tableau récapitulatif
Courbe ROC
La courbe ROC[2] est une représentation graphique qui vise à mettre en lumière la « performance » d'un test. On l'appelle également courbe de performance ou courbe sensibilité/spécificité. En abscisses de ce graphique on place l'anti-spécificité (c'est-à-dire 1-spécificité) aussi appelée « taux de faux positifs » et en ordonnées on place la sensibilité aussi appelée « taux de vrais positifs ». Cette courbe permet de comparer 2 tests entre eux ou bien de chercher les valeurs de sensibilité et de spécificité optimales (c'est-à-dire le moment où les 2 valeurs sont maximisées).
Déroulement d'un test
Pour le cas spécifique d'un test unilatéral, le test suit une succession d'étapes définies :
- énoncé de l'hypothèse nulle H0 et de l'hypothèse de remplacement H1 ;
- calcul d'une statistique de test (variable de décision) correspondant à une mesure de la distance entre les deux échantillons dans le cas de l'homogénéité, ou entre l'échantillon et la loi statistique dans le cas de l'adéquation (ou conformité). Plus cette distance sera grande et moins l'hypothèse nulle H0 sera probable. En règle générale, cette variable de décision s'appuie sur une statistique qui se calcule à partir des observations. Par exemple, la variable de décision pour un test unilatéral correspond à rejeter l'hypothèse nulle si la statistique dépasse une certaine valeur fixée en fonction du risque de première espèce ;
- calcul de la probabilité, en supposant que H0 est vraie, d'obtenir une valeur de la variable de décision au moins aussi grande que la valeur de la statistique que l'on a obtenue avec notre échantillon. Cette probabilité est appelée la valeur p (p-value) ;
- conclusion du test, en fonction d'un risque seuil αseuil, en dessous duquel on est prêt à rejeter H0. Souvent, un risque de 5 % est considéré comme acceptable (c'est-à-dire que dans 5 % des cas quand H0 est vraie, l'expérimentateur se trompera et la rejettera). Mais le choix du seuil à employer dépendra de la certitude désirée et de la vraisemblance des autres choix ;
- si la valeur p est plus petite que α, on rejette l'hypothèse nulle ;
- si la valeur p est plus grande que α, on peut utiliser la puissance 1 – β, si elle est grande, on accepte H0 ; sinon le test est non concluant, ce qui revient à dire que l'on ne peut rien affirmer.
La probabilité pour que H0 soit acceptée alors qu'elle est fausse est β, le risque de deuxième espèce. C'est le risque de ne pas rejeter H0 quand on devrait la rejeter. Sa valeur dépend du contexte, et peut être très difficilement évaluable (voire impossible à évaluer) : c'est pourquoi le risque α est principalement utilisé comme critère de décision, on n'accepte que très rarement H0 et la plupart du temps on conclut à un test non concluant si on ne rejette pas H0.
Le résultat d'un test comprend toujours une dose d'incertitude : on ne sait jamais si on a pris la bonne décision. La valeur p permet d'avoir une vision plus fine que sa simple comparaison avec α. En effet, plus elle est petite, plus l'évènement observé est surprenant sous H0. Ainsi pour α = 0,05, des valeurs p de 10–6 et de 0,035 impliquent le rejet de H0 mais avec des degrés de certitudes différents concernant la décision.
Catégories des tests
Les tests peuvent être classés selon leur finalité, le type et le nombre des variables d’intérêt, l’existence d’hypothèses a priori sur les lois des données, le mode de constitution des échantillons.
Les tests selon leur finalité
La finalité définit l’objectif du test, les hypothèses que l’on veut opposer, l’information que l’on souhaite extraire des données.
Le test de conformité consiste à confronter un paramètre calculé sur l’échantillon à une valeur préétablie. On parle alors de test de conformité à un standard. Les plus connus sont certainement les tests portant sur la moyenne ou sur les proportions. Par exemple, dans un jeu de dés à six faces, on sait que la face 3 a une probabilité de 1/6 d’apparaître. On demande à un joueur de lancer (sans précautions particulières) 100 fois le dé, on teste alors si la fréquence d’apparition de la face 3 est compatible avec la probabilité 1/6. Si ce n’est pas le cas, on peut se poser des questions sur l’intégrité du dé.
Le test d’adéquation (ou d'ajustement) consiste à vérifier la compatibilité des données avec une loi choisie a priori. Le test le plus utilisé dans cette optique est le test d’adéquation à la loi normale. On peut également tester la compatibilité des données avec une famille (paramétrée) de lois.
Le test d’homogénéité (ou de comparaison) consiste à vérifier que K (supérieur à 2) échantillons (groupes) proviennent de la même population ou, cela revient à la même chose, que la loi de la variable d’intérêt est la même dans les K échantillons.
Le test d’association (ou d’indépendance) consiste à éprouver l’existence d’une liaison entre deux variables. Les techniques utilisées diffèrent selon que les variables sont qualitatives nominales, ordinales ou quantitatives.
Les tests selon le type et le nombre de variables
On distingue généralement trois principaux types de variables. Une variable qualitative nominale prend un nombre restreint de valeurs (modalités), il n’y a pas d’ordre entre ces valeurs, l’exemple le plus connu est le sexe, il y a deux valeurs possibles, homme et femme. Une variable qualitative ordinale prend un nombre restreint de valeurs, il y a un ordre entre les valeurs. Un exemple naturel est la préférence ou la satisfaction : peu satisfait, satisfait, très satisfait. Il y a un ordre naturel entre les valeurs, mais nous ne pouvons pas quantifier les écarts. Enfin, une variable quantitative prend théoriquement un nombre infini de valeurs, l’écart entre deux valeurs a un sens. Un exemple simple serait le poids, la différence de poids entre deux personnes est quantifiable, on sait l’interpréter.
Le type de données joue un rôle très important. Il circonscrit le cadre d’application des techniques. Pour un même objectif, selon le type de données, nous serons amenés à mettre en œuvre des tests différents. Par exemple, pour mesurer l’association entre deux variables : si elles sont quantitatives, nous utiliserons plutôt le coefficient de corrélation de Pearson ; si elles sont qualitatives nominales, ce coefficient de corrélation n’a pas de sens, on utilisera plutôt le coefficient de corrélation de Spearman, ou des mesures telles que le V de Cramer ou le t de Tschuprow.
Principalement concernant les tests de conformité et d’homogénéité, on dit que le test est univarié s’il ne porte que sur une variable d’intérêt (ex. comparer la consommation de véhicules selon le type de carburant utilisé), il est multivarié s’il met en jeu simultanément plusieurs variables (ex. la comparaison porte sur la consommation, la quantité de CO2 émise, la quantité de particules émises, etc.).
Constitution des échantillons
Ce point est surtout associé aux tests de comparaison. On parle d’échantillons indépendants lorsque les observations sont indépendantes à l’intérieur des groupes et d’un groupe à l’autre. C’est le cas lorsque l’échantillon provient d’un échantillonnage simple dans la population globale.
Les échantillons appariés en revanche reposent sur un schéma différent. D’un groupe à l’autre, les individus sont liés. C’est le cas lorsque nous procédons à des mesures répétées sur les mêmes sujets. Par exemple, on mesure la fièvre d’un patient avant et après la prise d’un médicament. L’appariement est une procédure complexe qui va au-delà des mesures répétées (ex. les blocs aléatoires complets), elle vise à améliorer la puissance des tests en réduisant l’influence des fluctuations d’échantillonnage.
Tests classiques
Il existe de nombreux tests statistiques classiques parmi lesquels on peut citer :
- le test de Student, qui sert à la comparaison d'une moyenne observée avec une valeur « attendue » pour un échantillon distribué selon une loi normale ;
- le test de Fisher, aussi appelé test de Fisher-Snédécor, qui sert à la comparaison de deux variances observées ;
- l'analyse de la variance ou ANOVA, permet de comparer entre elles plusieurs moyennes observées (pour les groupes étudiés), selon un plan expérimental prédéterminé. Elle se fonde sur une décomposition de la variance en une partie « explicable » (variance inter-groupes) et une partie « erreur » (variance globale intragroupe — ou variance résiduelle), supposée distribuée selon une loi normale. Ce test est particulièrement utilisé en sciences humaines, sciences sociales, sciences cognitives, en médecine et en biologie ;
- le test du χ², également appelé test du χ2 de Pearson, qui sert notamment à la comparaison d'un couple d'effectifs observés, ou à la comparaison globale de plusieurs couples d'effectifs observés, et plus généralement à la comparaison de deux lois observées ;
- le test de Kolmogorov-Smirnov, qui comme le test du χ2 constitue un test d'adéquation entre des échantillons observés et une loi de probabilité. Il compare la fonction de répartition observée et la fonction de répartition attendue. Il est particulièrement utilisé pour les variables aléatoires continues.
En inférence bayésienne, on utilise le psi-test (mesure de distance dans l'espace des possibles) dont on démontre que le test du représente une excellente approximation asymptotique lorsqu'il existe un grand nombre d'observations.

Notes et références
- Cet article est partiellement ou en totalité issu de l'article intitulé « Test d'hypothèse » (voir la liste des auteurs).
- Gilbert Saporta, Probabilités, analyse des données et statistique, Technip Éditions, (ISBN 2-7108-0565-0) [détail des éditions], page 320.
- Cette abréviation d’origine anglophone reste la plus couramment employée, y compris dans l'univers scientifique francophone.
Voir aussi
Bibliographie
![]() : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article.
- P. Dagnelie, Statistique théorique et appliquée, t. 1 : Statistique descriptive et base de l'inférence statistique, Paris et Bruxelles, De Boeck et Larcier, .

- P. Dagnelie, Statistique théorique et appliquée, t. 2 : Inférence statistique à une et à deux dimensions, Paris et Bruxelles, De Boeck et Larcier, .
- G. Millot, Comprendre et réaliser les tests statistiques à l'aide de R 3e édition, De Boeck, Louvain-la-Neuve, 2014.
- J.-J. Droesbecke, Éléments de statistique, Ellipses, Paris, 2001.
- B. Escofier et J. Pages, Initiation aux traitements statistiques : Méthodes, méthodologie, Rennes, Presses universitaires de Rennes, 1997.
- Falissard et Monga, Statistique : concepts et méthodes, Masson, Paris, 1993.
- H. Rouanet, J.-M. Bernard et B. Le Roux, Statistique en sciences humaines : analyse inductive des données, Dunod, Paris, 1990.
- G. Saporta, Probabilité, analyse des données et statistique, Technip, Paris, 1990.
- R. Veysseyre, Statistique et probabilité pour l'ingénieur, Dunod, Paris, 2002.
Articles connexes
Liens externes
- (en) J.D. Leeper, Choosing the Correct Statistical Test, CHS 627: Multivariate Methods in Health Statistics, The University of Alabama.
- (en) J.H. McDonald, Choosing a statistical test, in Handbook of Biological Statistics
- R. Ramousse, M. Le Berre, L. Le Guelte, Introduction aux statistiques, chapitres 1 à 5 (des mêmes auteurs, voir aussi Une approche pragmatique de l'Analyse des données)
- R. Rakotomalala, Comparaison de populations - Tests paramétriques et Comparaison de populations - Tests non paramétriques
- Statisticien.fr Tests de rangs
- INRIA Rhône-Alpes SMEL - Statistique médicale en ligne, en particulier Tests Statistiques
- D. Mouchiroud, Probabilité - Statistique, voir « Probabilités - Statistiques »
- J. Begin, Analyse quantitative en psychologie, voir « Notes de Cours »
- X. Hubaut, Notes pour lycéens (étudiants du secondaire)
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique