Worst Case Execution Time
Le WCET ou Worst Case Execution Time, en français pire cas de temps d’exécution, équivaut au plus long temps d’exécution d’un programme informatique.
Aujourd’hui, cette information est indispensable pour l’intégrité des systèmes embarqués voués à la sécurité comme un ABS ou un coussin gonflable de sécurité (« airbag ») dans une voiture, les systèmes de contrôle aérien et tout autre système informatique critique. Ces systèmes doivent réagir en temps réel de manière fiable, ce qui implique à la fois d’être sûr du résultat produit par le programme mais aussi de connaître absolument le temps qu’il prendra pour s’exécuter. Pour garantir cela, le plus long temps d’exécution a besoin d’être connu le plus précisément possible. Toutefois, un programme ne se comporte pas toujours de manière identique, son temps d’exécution peut varier en fonction du type de tâche à réaliser mais aussi du type de l’appareil sur lequel il s’exécute. Par conséquent, les caractéristiques du code du programme et les caractéristiques matérielles ont besoin d’être considérées.
Pour déterminer le WCET, plusieurs pratiques existent. La première, utilisée couramment dans l’industrie, s’appuie sur les mesures: c’est la méthode dynamique. Cette méthode a pour principe d’exécuter un certain nombre de fois le programme avec des données d’entrées différentes considérées comme celles provoquant la durée d’exécution la plus longue. Toutefois, les mesures ne donnent pas toutes les garanties que le plus long temps ait été rencontré, ce qui entraîne des erreurs. Une deuxième méthode fonctionne par analyse du programme sans même l’exécuter: c’est la méthode statique. Cette technique alternative dérive par abstraction les propriétés que le programme aurait pour toutes ses exécutions possibles. Son résultat donne un temps qui est garanti pour être plus large que le (ou égal au) plus long temps d’exécution du programme. Elle a donc tendance à surestimer le WCET. Pour réduire ce phénomène, l’analyse a besoin d’être effectuée tant au niveau haut du code qu’au niveau bas. La prise en compte des données micro architecturales telles que les comportements processeurs et mémoires est de plus en plus importante surtout depuis le développement des usages de processeurs à plusieurs cœurs dans les systèmes embarqués. Une troisième méthode tente d’améliorer les calculs du WCET en combinant les techniques dynamiques et statiques: c’est la méthode hybride. Ces différentes méthodes sont disponibles sous forme d’outils issus à la fois du monde universitaire, industriel et commercial.
Motivations
Les systèmes temps réel doivent satisfaire des contraintes temporelles strictes, qui sont dérivées des systèmes qu'ils contrôlent. En général, le calcul du WCET[note 1] est nécessaire pour montrer la satisfaction de ces contraintes. L'obtention systématique des limites supérieures des temps d'exécution des programmes pourrait complètement résoudre le problème de l'arrêt du programme. Cependant, les systèmes temps réel utilisent seulement une forme restreinte de programmation, ce qui garantit que les programmes se terminent toujours[1]. Ainsi, les secteurs tels que l'industrie spatiale et l'aviation acceptent les coûts élevés et les efforts nécessaires pour obtenir un WCET le plus précis possible. D'autre part, le coût élevé pour re-valider le logiciel en cas de changements même mineurs est une problématique importante à prendre en considération[2]. Par exemple, dans les secteurs de production de masse où les coûts sont optimisés, les coûts de production sont plus importants que les coûts de développement. Le développeur devra, pour garantir les délais, prendre en compte le WCET des programmes afin de sélectionner le moins cher et celui qui sera suffisamment puissant pour répondre aux besoins[2]. Pour les systèmes où le temps d’exécution est moins critique, les estimations du WCET ne sont pas toujours nécessaires, seulement des parties limitées du logiciel du système sont critiques[3].
Historique
Bien que l'analyse de l’ordonnancement d'un programme soit l'un des domaines traditionnels de recherches, les premières recherches sur l'analyse du WCET ont démarré à la fin des années 1980 (Kligerman et Stoyenko en 1986[4], Mok et al en 1989[5], Puschner et Koza en 1989[6] et Shaw en 1989[7]). Dans les années 1990, de nombreux scientifiques ont mis l'accent sur l'analyse du WCET, par conséquent, de nombreux progrès ont été effectués dans cette décennie[8].
Le début des années 2000 a vu naître des outils d'automatisation de l'estimation du WCET. Le WCET Challenge 2006 a été le premier événement qui a comparé différents outils de WCET en utilisant le même ensemble de critères[9]. Deux équipes de développement d'outils commerciaux, AIT[note 2] et Bound-T[note 3], et trois de prototypes d'outils de recherches, MTime, SWEET, et Chronos[note 4] y ont participé. D'autres groupes de développeurs n'ont pu y participer pour cause de délai de préparation trop court tel que les développeurs d'OTAWA[note 5], RapiTime[note 6], SYMTA/P[note 7] et Heptane[note 8],[10]. Les critères de références utilisés ont été ceux définis par Jan Gustafsson de l'université de Mälardalen[11]. Un assistant de recherches externe et les équipes de développements ont fait les tests réels des outils suivant ces critères[10]. D'autres Challenges ont eu lieu également en 2008[12] et 2011[13].
Par ailleurs un groupe de travail est organisé annuellement sur ce thème en conjonction avec la Conférence des Systèmes Temps Réels[note 9]. Cet événement permet d'observer les dernières tendances en termes d'obtention du WCET[14], à l'image de la conférence de Göteborg en 2014[note 10] ou celle de Paris en 2013[note 11].
Estimations du WCET
L'analyse du WCET permet de calculer les limites supérieures pour les temps d'exécution de morceaux de code pour une application donnée où le temps d'exécution d'un morceau de code est défini comme le temps qu'il faut au processeur pour exécuter ce morceau de code[15].

Une tâche peut avoir une certaine variation de temps d’exécution en fonction des données d'entrée ou en fonction des différences d'environnement. Le plus court temps d'exécution est appelé « Best Case Execution Time[note 12] » (BCET), le pire temps d’exécution du programme est appelé « Worst Case Execution Time » (WCET). Dans la plupart des cas, l'espace d'état est trop grand pour explorer de manière exhaustive toutes les exécutions possibles et déterminer ainsi les temps d'exécution BCET et WCET de manière exacte[1].
Aujourd'hui, les trois méthodes suivantes sont utilisées pour l'analyse du WCET[3] :
- La méthode d'analyse dynamique consiste à mesurer le temps d’exécution du programme sur le matériel cible;
- La méthode d'analyse statique évite l'exécution du programme;
- La méthode d'analyse hybride combine l'analyse dynamique et l'analyse statique.
Avant de choisir une méthode d'obtention du WCET, il est nécessaire de tenir compte des conditions suivantes[16]:
- Si une estimation fiable est souhaitée: il faudra probablement choisir une méthode d'analyse statique;
- Si une estimation approximative est suffisante: ce peut être le cas, si le système est un système temps réel souple, ou si le système peut tolérer des dépassements occasionnels. Dans ce cas, les valeurs d'estimation basées sur des mesures peuvent être suffisantes. Les méthodes hybrides sont une autre option, donnant parfois des informations plus détaillées sur le résultat obtenu;
- Si d'autres informations sont souhaitées : les outils statiques et hybrides d'aujourd'hui fournissent des informations supplémentaires utiles, par exemple l'identification des goulets d'étranglement, et les informations sur le plus long chemin d’exécution.
Méthode dynamique
Les méthodes dynamiques consistent à exécuter le programme dont on veut estimer le WCET (sur un système réel ou sur un simulateur) et à mesurer son temps d’exécution. Des jeux de tests pour l’exécution, qu’ils soient explicites ou symboliques sont indispensables dans ce type de méthode. Pour mesurer le temps d’exécution au pire cas, il faut fournir le jeu de test qui conduit au temps d’exécution maximum[17].
Jeux de tests explicites
Une des principales difficulté est la possibilité de générer de manière automatique et systématique des jeux de tests suffisant pour l'estimation du WCET[18]. Plusieurs solutions sont envisageables[17] :
- Mesurer le temps d’exécution du programme pour tous les jeux d’entrées possibles ; la durée du processus est en général rédhibitoire;
- Laisser le soin à l’utilisateur de définir le jeu de test pire cas ; sa parfaite connaissance du programme peut lui permettre d’identifier ce jeu de test sans erreur;
- Générer automatiquement un jeu de test (ou un ensemble de jeux de test) qui conduit au temps d’exécution maximum.
Quelques travaux basés sur des algorithmes évolutionnistes ont été menés dans ce sens.
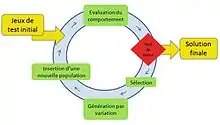
L’algorithme commence par une population initiale de paramètres (par exemple les données d’essais en cas de test évolutionnaire). Les membres de la population sont ensuite évalués en fonction de leur comportement. Dans le cas du WCET, la valeur de ces paramètres est remise en cause en fonction de la durée d’exécution du programme. Après cette évaluation, si les conditions sont remplies l’algorithme aura défini des paramètres permettant une estimation du WCET plus précise[19]. L'algorithme génétique, qui est un type d'algorithme évolutionniste, est le plus souvent utilisé dans le cadre des méthodes dynamiques[20]. Frank Mueller et Joachim Wegener ont développé une nouvelle approche pour tester le comportement temporel des systèmes temps réels. Grâce à leurs tests évolutionnaires, les jeux de données optimisés sont obtenus automatiquement et permettent de vérifier si les contraintes temporelles spécifiées pour le système sont dépassées[21]. Amine Marref a également développé un programme génétique pour proposer une alternative aux méthodes d'obtention de jeux de paramètres pour l'analyse du WCET. Les paramètres de test sont capturés automatiquement par le programme génétique à la suite de l'exécution de bout en bout du programme sous analyse[22]. Un autre travail proposant un framework de génération de jeux de tests généralisés basé sur une technique d'optimisation a également été publié[23]. Ces méthodes de génération automatique sont dans certaines publications considérées comme méthodes semi-dynamiques ou méthodes hybrides[24]. Le développement de ces techniques principalement basées sur des algorithmes génétiques entraine un regain d’intérêt des méthodes autres que statiques[25]. Cet intérêt est d’autant plus fort du fait de l’utilisation principale des méthodes dynamiques par les industriels[26].
Jeux de tests symboliques
Le principe de cette méthode est de poser l’hypothèse que les données en entrée sont inconnues et d’étendre le jeu d’instructions du processeur cible de sorte qu’il puisse réaliser des calculs à partir d'une ou plusieurs valeurs inconnues. Elle utilise la sémantique d'instructions alternatives pour traiter les opérandes inconnus. La méthode peut exclure de nombreux chemins du programme impossibles (ou non-exécutables) et peut calculer les paramètres du chemin, comme des limites du nombre d'itérations d'une boucle, sans nécessité d'annotations manuelles du programme[27],[28],[29].
Méthodes de mesures
De nombreuses méthodes existent pour mesurer le temps d'exécution, chaque technique est un compromis entre plusieurs attributs, tels que la résolution, la précision, la granularité et la difficulté de mise en œuvre[30]. Voici les principales techniques de mesure :
- Stop watch[31],[32]
- La méthode consiste à utiliser un chronomètre pour mesurer le temps d’exécution du programme.
- Commande date et time (UNIX)[31],[32]
- La commande
dateest utilisée comme un chronomètre, sauf qu'elle utilise l'horloge intégrée de l'ordinateur au lieu d'un chronomètre externe. Cette méthode est plus précise que le chronomètre mais a la même granularité de mesure. Pour la commandetime, la mesure du temps d'exécution est déclenchée par le préfixe « time » dans la ligne de commande. Cette commande ne mesure pas seulement le temps entre le début et la fin du programme, mais elle calcule également le temps d'exécution utilisé par les programmes spécifiques. - Prof et Gprof (UNIX)[31],[33]
- Les méthodes prof et gprof sont similaires (la méthode gprof fournit plus d’informations), elles sont généralement utilisées pour mesurer les temps d’exécution des fonctions (nombre minime d’instructions). Ces méthodes peuvent être utilisées pour optimiser du code.
- Clock[34]
- Bien que les méthodes prof et gprof fournissent des informations plus détaillées que les premières méthodes présentées, il est souvent nécessaire de mesurer le temps d'exécution avec une granularité plus fine. Ainsi, les fonctions sont découpées en segments pour permettre, grâce à la commande
clock, de mesurer chacun d'eux. - Analyseur logiciel[34],[35]
- Un analyseur logiciel est un analyseur qui à l’instar des méthodes précédemment définies (prof et gprof) ne se limite pas seulement à mesurer le temps d’exécution d’une fonction mais peut également être utilisé dans des analyses temporelles à plus petite échelle. Exemple : les boucles ou les petits segments de code qui peuvent se limiter à une seule instruction.
- Timer et compteur[36]
- Des timers/compteurs dans les systèmes embarqués sont souvent disponibles. Ils pourront être utilisés pour obtenir des mesures très fines et très précises des temps d’exécutions de petits segments de code. Le temps d’exécution du segment de code est obtenu en calculant la différence entre les valeurs lues dans le timer/compteur au début et à la fin de l’exécution.
La mise bout à bout de mesures de sous-ensembles de programme est possible pour produire une estimation du temps d'exécution et une idée du pire cas d'exécution de son programme, mais elle ne permet pas de trouver de manière précise et certaine ses limites de temps d'exécution. La garantie que les limites de sécurité soient tenues ne peuvent être données que pour les architectures simples. Ces méthodes peuvent être utilisées pour les applications qui n'ont pas de nécessité de garantie de temps d'exécution, typiquement les systèmes temps réel non stricts[37].
Méthode statique
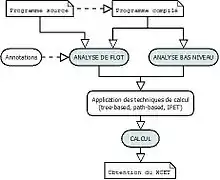
La méthode statique a pour principe d’analyser la structure du programme sans réellement l'exécuter, puis de calculer le WCET à partir de cette structure. À l’inverse de la méthode dynamique, aucune donnée d’entrée n’est connue. Elle est composée de trois phases principales :
- L'analyse de flot détermine les chemins d’exécutions possibles. Pour cela elle exploite :
- une représentation du flot de contrôle (ou Reconstruction du flot de contrôle),
- une évaluation du flot de contrôle;
- L'analyse bas niveau détermine le temps d’exécution d’une séquence d’instructions sur une architecture donnée. Elle repose sur :
- une analyse des caches (analyse globale),
- une analyse des pipelines (analyse locale),
- une analyse des branchements ;
- Le calcul du WCET peut alors être mené en s’appuyant sur les résultats obtenus lors des deux phases précédentes et en utilisant :
- une technique par graphe de flots (path based) ou,
- une technique par arbre syntaxique (tree based) ou,
- une technique par énumération implicite des chemins (IPET).
On retrouve cette architecture type d'analyse statique de temps dans de très nombreux travaux[38],[39],[40],[41],[42] ou outils[43],[44],[45].
Les représentations du flot de contrôle (ou Reconstruction du flot de contrôle)
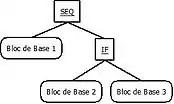
- Représentation en blocs de base
- Une première étape consiste à analyser le programme en le découpant en blocs de base. Ces blocs de base sont en fait des séquences de code contigües, autrement dit des ensembles d’instructions avec uniquement un point d’entrée et un point de sortie. Ils s’exécutent sans interruption et ne contiennent pas d’instruction de branchement[46].
- Représentation en arbre syntaxique
- L’étape suivante est relative à la description structurelle du code du programme. Elle est réalisée au travers d’une analyse de langage haut niveau en représentant un arbre syntaxique ayant pour feuilles les blocs de base ou les appels de fonction (CALL), et pour nœuds les séquences (SEQ), les conditions (IF), et les boucles (LOOP) d’instructions.
Les premières représentations de programme en arbre syntaxique sont données dès 1989 par Puschner et Koza[6], ou encore par Shaw[7]. - Représentation en graphe de flot de contrôle
- Cette étape va montrer à l’aide d’un graphe les divers enchaînements des blocs de bases entre eux et représenter tous les chemins d’exécution que le programme peut emprunter. Elle est généralement issue d’une analyse du code bas niveau (code compilé). Le graphe est composé de nœuds représentés par les blocs de base, et d’arcs représentant les enchaînements entre chaque nœud. Cette représentation, relative à la théorie des graphes, est visible dans beaucoup de travaux, par exemple[47],[48].
Les évaluations du flot de contrôle
- L’analyse de valeur
- L'analyse de valeur essaye de déterminer statiquement les valeurs stockées dans les registres et les blocs mémoires. Une telle information est nécessaire à la fois pour l’analyse des bornes de boucle, mais aussi pour déterminer le temps d’exécution des instructions arithmétiques dont leur temps dépend des valeurs de leurs opérandes, ou encore pour une bonne approximation des adresses des données du programme utile à l’analyse de bas niveau[49]. Le problème principal de l’analyse de valeur est l’indécidabilité; souvent plusieurs valeurs sont possibles à un même point du programme quand le contrôle passe par ce point plusieurs fois[50],[51].
- L’analyse de borne de boucle
- L'analyse de borne de boucle détermine le poids des extrémités du graphe. Elle identifie les boucles dans le programme et essaye de déterminer des bornes sur le nombre de boucle itératives et récursives. Les difficultés rencontrées sont au niveau des calculs des compteurs de boucle et des conditions de sortie de boucle, tout comme des dépendances entre compteurs de boucle dans les boucles imbriquées. Voir les travaux de Chu et Jaffar[52].
- L’analyse de flot de contrôle
- L’analyse de flot de contrôle, aussi appelée analyse de chemin infaisable, détermine l’ensemble des chemins possibles au travers du programme de manière à resserrer plus précisément les bornes de temps. Ce point est abordé dans le chapitre du calcul path-based. Cette technique permet de pondérer les nœuds et les boucles, mais aussi de fournir les contraintes des chemins. Une optimisation de celle-ci a été démontrée en utilisant le paradigme des chemins invariants par Lokuciejewski, Gedikli et Marwedel[53].
Toutes ces analyses fournissent des informations complémentaires utiles pour le calcul du WCET. La connaissance de données d’entrée d’un nœud peut contribuer à accroître la précision de l’analyse[54]. En effet, ces données peuvent avoir un impact important sur le conditionnement d’une branche, donc le choix du chemin à prendre dans le programme. Toutes ces informations peuvent alors être fournies de deux façons, soit sous forme d’annotations par l’utilisateur[5], ou soit par dérivation automatique. Pour cette dernière, des méthodes d’interprétations abstraites ont été proposées par Gustafson[55]. L’interprétation abstraite est en fait une théorie d’abstraction et d’approximation de structures mathématiques utilisées dans une description formelle de systèmes complexes et une déduction de leurs propriétés combinatoires ou indécidables. Un résumé des différentes interprétations abstraites (paradigmes, méthodes, algorithmes) a été réalisé par Cousot[56]. Un nouvel algorithme appelé “analyse de propagation minimum” (MPA) est notamment proposé par Bygde, Ermedhal et Lisper[57] pour effectuer le calcul paramétrique des programmes. Celui-ci est significativement plus efficace à la fois au niveau vitesse et mémoire que la méthode généralement employée de programmation d’entier paramétrique (PIP) introduite par Feautrier[58]. Cet algorithme est prévu pour être implémenté dans l’outil Sweet afin d’améliorer son analyse de flot.
Analyse bas niveau (ou microarchitecturale)
Cette étape est très complexe mais ses mécanismes de spéculation font preuve d’une perspicacité toujours croissante depuis quelques années car sans cesse en évolution. La précision de l’estimation du WCET en est considérablement améliorée[59]. Pour ce faire, elle utilise l’interprétation abstraite pour calculer les invariants pour chaque point du programme qui caractérisent l’ensemble de tous les états que l’architecture peut rencontrer quand le contrôle atteint ce point. Ces invariants décrivent de manière fiable l’information au sujet des contenus des caches, de l’état du pipeline incluant les contenus de toutes ses queues et mémoires tampon autant que l’occupation de ses unités, ainsi que l’état des bus, des mémoires, et des périphériques. Les invariants calculés sont utilisés pour exclure les transitions dans l’architecture. Par exemple, une transition de cache absent peut être exclue si l’invariant lié à l’état du cache lui permet de prédire un accès cache.
Si pour les architectures simples, les instructions sont séquentielles et leur temps d’exécution dépend essentiellement des opérations qu’elles doivent réaliser, pour les architectures complexes, les instructions peuvent être parallélisées grâce à l’usage de pipeline, et leur temps d’exécution varier en fonction de leur contexte par le biais de cache[60]. Cela rend donc l’analyse de temps beaucoup plus difficile. Ces effets sur le temps d’exécution peuvent avoir deux portées différentes: une portée locale dans le cas d’effet de parallélisme comme celui induit par les pipelines car il n’impacte le temps d’exécution que d’instructions proches l’une de l’autre, ou une portée globale dans le cas d’effet de variations de temps comme celui induit par les caches car il impacte cette fois l’ensemble des instructions du flot[61].
Analyse des caches (analyse globale)
Cette analyse catégorise les instructions en fonction de leur comportement dans le cache mémoire, à savoir si elles sont chargées ou non lors de l’appel processeur, et si elles affectent les autres instructions. L’objectif est d’identifier les instructions susceptibles de provoquer une perte de temps liée à un appel processeur qui ne trouve pas de donnée, soit en fait un conflit de cache mémoire[62]. Quatre catégories sont considérées :
- Always hit : l’accès à l’instruction en cache mémoire est toujours bon (cache hit)
- Always miss : l’accès à l’instruction en cache mémoire est toujours en défaut (cache miss)
- First miss : l’accès à l’instruction en cache mémoire est en défaut seulement à la première exécution de l’instruction
- Conflict : l’accès à l’instruction en cache mémoire est en conflit
La catégorisation se fait en deux phases. La première calcule pour chaque instruction (ou nœud ou bloc de base) tous les contenus du cache mémoire avant et après son exécution. Ces contenus sont nommés états abstraits de cache. Le principe est de trouver les instructions générant un conflit de cache mémoire menant au pire cas. La deuxième phase catégorise les instructions vis-à-vis de l’état abstrait de cache pour être utilisé lors de l’étape de calcul du WCET.
Cette méthode est par exemple utilisé par de nombreux outils d’analyse tels que Heptane[63],[note 8], AIT[64],[note 2], mais aussi détaillée dans les travaux de Lundqvist, Stenström[65] ou encore Puaut[66].
Analyse des pipelines (analyse locale)
.jpeg.webp)
Le pipeline permet la parallélisation des instructions dans le but d’accroître les performances du processeur. Grâce à plusieurs étages dans le pipeline, les instructions peuvent se chevaucher ce qui induit que le temps d’exécution d’un ensemble d’instructions ne peut pas être égal à la somme des temps de chacune de ces instructions. Le calcul du WCET des instructions se fait via une représentation de l’occupation du pipeline par le remplissage de tables de réservation pendant l’exécution de ces instructions simulant ainsi les l’états d’occupation des étages du pipeline. Une étude de Metzlaff montre et quantifie l'impact des anomalies mémoires sur le calcul[67]. Comme pour l'analyse des caches, on peut retrouver cette méthode dans beaucoup d'outils[68],[69] et travaux[70],[71],[72]. Un cas d'anomalie de timing est illustré ci-contre dans le schéma "Anomalie causée par ordonnancement (pipeline)". Dans cette illustration, considérons que les instructions A, D et E ne peuvent s’exécuter que sur la ressource processeur 1, et que les instructions B et C ne peuvent s’exécuter que sur la ressource processeur 2. Le premier ordonnancement se montre optimal car C peut enchaîner avec les instructions D et E avant que l’instruction A n’enchaîne avec l’instruction B. Dans le deuxième ordonnancement, l’instruction A, exécutée sur la ressource processeur 1 et se terminant avant que la ressource C ne soit prête, va alors enchaîner sur l’instruction B sur la ressource processeur 2. Mais cette dernière instruction va bloquer le départ de l’instruction C car elle aussi ne peut s’exécuter que sur la ressource processeur 2 décalant ainsi le départ des instructions D et E suivantes sur la ressource processeur 1. L’ordonnancement est par conséquent plus long.
Analyse des branchements
.jpeg.webp)
Cette analyse optionnelle peut s’avérer utile pour des architectures munies d’un prédicteur de branchement. La prédiction de branchement optimise l’usage du pipeline. Mais son mécanisme de spéculation peut engendrer des erreurs d’anticipation de chargement d’instruction et donc de la perte de temps. La technique est identique à celle utilisée pour l’analyse des caches. Un classement des instructions de branchement conditionnel est donc réalisé. Une méthode basée sur la technique BBIP (block based instruction prefetching) est proposée par Ni[73]. Des techniques d'optimisation ont aussi été comparées par Plazar en employant un algorithme génétique ou une programmation linéaire en nombres entiers[74],[75].Un cas d'anomalie due à la prédiction de branchement est illustré ci-contre dans le schéma « Anomalie causée par spéculation (cache) ». De mauvaises surprises peuvent se révéler allant à l’encontre de l’intérêt du cache mémoire prévu pour accélérer le traitement des instructions. En effet, dans le premier cas, l’instruction A se termine avant la condition de branchement. Le processeur engage alors une spéculation qui peut s’avérer être mauvaise, décalant alors le départ de l’instruction C attendue à cause du temps de chargement de l’instruction B dans le cache. Tandis que dans le cas de l’absence de prédiction, le traitement des instructions se fait finalement plus rapidement.
Calcul de WCET par graphe de flots (path based)
Cette technique tente de borner le plus long chemin d’exécution dans le graphe de flot, et donc de déduire le WCET[76]. La pratique courante pour y arriver est de travailler sur des petits ensembles de chemins en utilisant l’algorithmique des graphes et considérant les WCET des nœuds connus individuellement. Les chemins infaisables n’ayant aucun intérêt dans la recherche du WCET puisque ne se réalisant jamais, elle va consister à les éliminer du graphe. La borne haute pour une tâche est déterminée en calculant les bornes pour les différents chemins de la tâche, et en cherchant le chemin global ayant le temps d’exécution le plus long. La caractéristique principale de cette technique est que les chemins possibles sont représentés explicitement. Cette approche est valable dans une itération de boucle unique, mais pose des problèmes avec des flots s’étendant à travers des boucles à plusieurs niveaux. Le nombre de chemin étant exponentiel par rapport au nombre de points de ramification, il faut alors utiliser des méthodes de recherche heuristique de chemin[77]. La technique est parfaitement illustrée dans la publication « Overview WCET »[78].
Calcul de WCET par arbre syntaxique tree based
La représentation en arbre syntaxique du programme déjà obtenue en début d'analyse permet d’en découler un arbre de temps. En considérant que l’architecture matérielle n’utilise pas de cache, cet arbre fait la description du code source de la structure syntaxique du programme, des contraintes d’exécution exprimées par le développeur, et des temps d’exécution des différents blocs de base. Il révèle ainsi les WCET à chacun de ses nœuds. La technique consiste à parcourir l’arbre à l’envers en appliquant des formules mathématiques à chaque nœud afin de définir le chemin le plus long, et à chaque bloc de base pour calculer son WCET[79],[78].
Calcul de WCET par énumération implicite des chemins (IPET)
Pour cette étape, les temps d’exécution des blocs de bases sont des informations venant de l’analyse bas niveau. La technique s’appuie sur le graphe de flot. Son principe est de faire correspondre au graphe un ensemble de contraintes à respecter basées sur la programmation linéaire en nombre entier (ILP – Integer linear programming). Falk présente par exemple une méthode ILP basée sur l'allocation de registre[80]. À savoir que :
- Des variables d’entier modélisent le nombre de chemin des nœuds et des extrémités
- Un ensemble de contraintes modélise les flots du programme en utilisant la loi de Kirchhoff (la somme des flots entrants à un nœud doit égaler la somme des flots sortant)
- Un autre ensemble de contraintes modélise les nombres maximums d’itérations de boucle et autres contraintes de chemin déterminés par l’analyse de flot.
- La fonction objective est le produit scalaire des nombres de chemins et des poids des nœuds.
Pour calculer le WCET du plus long chemin, la fonction objective est maximisée. Pascal Raymond explique de manière générale la technique en la détaillant par plusieurs exemples[81].
Méthode hybride
Il existe traditionnellement deux types de méthodes pour le calcul du WCET, les méthodes dynamique et statique. Le désavantage de la méthode dynamique est qu'il est impossible de garantir que tous les chemins de flot de contrôle aient été couverts, de sorte que le résultat ne donne qu'une estimation approximative du WCET[82]. Pour ce qui concerne les méthodes statiques incluant une analyse haut et bas niveau, la complexité croissante des architectures des processeurs rendent l’estimation du WCET trop pessimiste[83]. Pour s’en affranchir, sont donc apparues des méthodes hybrides combinant les techniques d'analyses statiques haut-niveau du WCET et les analyses dynamiques du code[84].
D’une manière générique, les méthodes hybrides incluent les cinq étapes suivantes[82] :
- Analyse statique du code du programme : Il s’agit de l’analyse haut niveau défini dans la section 3.2.
- Identification des segments : Il s’agit, à partir des éléments analysés lors de la phase 1, de déterminer les différents segments à traiter.
- Application des chemins : Il s’agit d’une méthode permettant d’identifier tous les chemins infaisables afin de simplifier et de minimaliser les segments à mesurer.
- Mesure des temps d’exécutions de chaque segment.
- Calcul du WCET.
De nombreuses recherches ont été effectuées afin de faire progresser ces techniques hybrides et permettre de définir un cadre pouvant être utilisé par les milieux industriels. Ces méthodes mettent en jeu différentes techniques vu précédemment, comme l'utilisation de l’analyse statique, ou d'algorithmes évolutionnistes permettant la génération de jeux de test pour les méthodes de mesures dynamiques, afin de consolider le résultat du WCET obtenu[85],[86],[87],[88].
- Analyse temporelle basée sur la mesure

Voici la description d'une techniques d’analyse hybride du WCET : L’analyse temporelle basée sur la mesure (MBTA[note 13]).
- La première opération est donc l’analyse et la décomposition du programme en de multiples segments[89],[90]. La taille des séquences ainsi que leur faisabilité est à définir afin de garantir leur bon traitement lors de la phase de mesure[91]. De plus, la mesure de toutes ces séquences est généralement intraitable de manière exhaustive car tout simplement trop nombreuses. Par conséquent, la réduction du nombre de segments est cruciale.
Afin d’effectuer des mesures durant leur exécution, les techniques de décomposition du programme (bloc de base, graphe de flot) impliquent d’utiliser des techniques heuristiques pour sélectionner des jeux de test représentatifs[90]. - Une fois que le programme est décomposé, le temps d'exécution est mesuré pour chaque segment. Les temps d'exécutions sont mesurées sur le matériel cible, ce qui permet de prendre en considération les caractéristiques du matériel sans effectuer d’analyse statique bas-niveau[89],[90]. Cette phase introduit la notion de calcul optimiste : le temps maximal observé pour chaque segment est supposé être le véritable WCET[89].
- Les temps d'exécutions obtenus et les informations recueillies lors de l’analyse statique sont combinés pour calculer un WCET consolidé final[91].
Outils d'obtention de WCET
Quelques études recensent et comparent des outils d’obtention du WCET[43],[9]. Parmi tous les outils existants, voici trois exemples issus du monde universitaire et trois autres du monde du commerce.
HEPTANE
Heptane[note 8](Hades Embedded Processor Timing ANalysEr) est un outil d’analyse statique open source sous licence GPL. Il a été conçu au début des années 2000 avec Isabelle Puaut et Antoine Colin. Cet outil[92] déduit le WCET de programmes en langage C en utilisant deux méthodes de calcul, une première basée sur l’arbre syntaxique et une deuxième basée sur la méthode IPET. L’utilisateur doit toutefois lui fournir des annotations symboliques sur le programme source afin de borner les boucles d’itération. L’analyse micro architecturale est par ailleurs assurée via des mécanismes d’analyse de cache, de pipeline et de prédiction de branchement intégrant la méthode de simulation de cache statique de Frank Mueller[93].
OTAWA
OTAWA[note 5] (Open Tool for Adaptative Wcet Analysis) est un outil d’analyse statique open source sous licence LGPL. Développé à l’Institut de recherche de Toulouse, il est issu de la collaboration de Clément Ballabriga, Hugues Cassé, Christine Rochange et Pascal Sainrat. Cet outil[94], utilisable sous la forme d’une bibliothèque C++, calcule le WCET par analyse statique basée sur IPET. La manipulation du code binaire est facilitée (graphe de flot de contrôle, détection de boucle…) et sa conception modulaire peut supporter différentes architectures telles que PowerPC, ARM, Sparc ou M68HCS.
SWEET
SWEET[note 14](SWEdish Execution Time analysis tool) est un outil d’analyse de flot et de calcul BCET/WCET (meilleur et pire cas de temps d’exécution). Il est développé en Suède depuis 2001 par l’équipe de recherche de Västerås et maintenant de Mälardalen. Sweet utilise un langage de programme intermédiaire spécialement conçu pour l’analyse de flot et travaillant au format « ALF ». Il peut analyser les programmes sources ou compilés, et exporter son travail pour le rendre exploitable dans les outils AIT ou Rapitime. Sa principale fonction est d’analyser le flot de contrôle le plus précisément et automatiquement possible en se basant sur trois méthodes différentes : path-based, IPET, ou hybride[95],[69].
AIT (AbsInt)
AIT[note 2] (AbsInt’s Tool) est un outil développé par AbsInt Company et spécialisé pour le calcul WCET des systèmes embarqués[64],[96]. Il répond en particulier aux exigences de l’aéronautique. Basé sur l’interprétation abstraite et s’appuyant sur les méthodes d’analyse de Wilhelm, Ferdinand, Thesing, Langenbach et Theiling[97],[98],[99], AIT fonctionne sur le principe de construction d’un graphe de flot sur lequel des analyses de cache et de pipeline sont effectuées afin de calculer le pire chemin d’exécution par technique ILP. Il est aussi capable de supporter de très nombreuses architectures.
RAPITIME
RapiTime[note 6] est un outil de la société Anglaise Rapita Systems Ltd[note 15] conçu pour les systèmes embarqués de l'industrie automobile, de télécommunication ou aéronautique. Son origine est le prototype pWCET[100] développé par Bernat, Colin et Petters. L’outil fonctionne sur la méthode hybride en combinant des mesures dynamiques et des analyses statiques de type tree-based.
Bound-T
Bound-T[note 3] est un outil développé à l’origine par Space Systems Finland Ltd[note 16] sous contrat de l’Agence Spatiale Européenne (ESA)[note 17] pour les besoins de vérifications des systèmes embarqués spatiaux. Il examine le programme compilé en calculant le WCET via les méthodes d’analyses de flot de contrôle, de boucles d’itération, et d’annotations éventuelles données par l’utilisateur. Bound-T supporte la plupart des plateformes et processeurs.
| Méthode d'analyse | Considération de l'architecture | |
|---|---|---|
| HEPTANE | IPET, Tree-based | Abstraction |
| OTAWA | IPET | Abstraction |
| SWEET | IPET, Path-based, Hybride | Mesure |
| AIT | IPET | Abstraction |
| RAPITIME | Tree-based, Hybride | Mesure |
| BOUND-T | IPET | Abstraction |
Recherches / Prototypes
MERASA
MERASA[note 18] (Multi-Core Execution of Hard Real-Time Applications Supporting Analysability) est un projet de recherche spécifique faisant partie du septième programme de développement informatique de la commission européenne. Conduit par l’université de Augsburg[note 19] (Professeur Ungerer)[101], il est le fruit d’une collaboration entre le centre de super calcul de Barcelonne[note 20], l’université de Toulouse (IRIT[note 21]), et les entreprises Rapita[note 15] et Honeywell[note 22]. Le projet s’est déroulé entre 2007 et 2010. Son objectif était de tenter d’influer sur la conception de matériel temps réel et de son logiciel en développant un nouveau processeur multicœurs (de 2 à 16 cœurs) et des techniques pour garantir un calcul fiable du WCET. Il s’inscrit dans le besoin croissant de l’industrie d’utiliser ces architectures pour augmenter les performances de leurs systèmes embarqués liés à la sécurité, mais aussi dans la nécessité de répondre aux contraintes d’impossibilité de prédire et d’analyser leur comportement sans amener à un fort pessimisme sur le calcul du WCET. Pour réaliser sa tâche, MERASA s'est appuyé sur deux outils d’analyses statiques existants : Otawa et Rapitime.
Méthodes d'affinage (WCET squeezing)
De nombreuses études tentent d’améliorer le calcul WCET.
Un exemple est donné par Lokuciejewski, Falk, Schwarzer, Marwedel et Theiling[102] en utilisant des procédures de clonage sur le code source pour réduire la surestimation du WCET. Celles-ci rendent le code mieux analysable et plus prévisible à partir de fonctions spécialisées qui permettent une définition explicite des bornes de boucles et optimisent les détections de chemins infaisables. La réduction mesurée avec l'outil de test Mibench-Suite[103] est comprise entre 12 et 95%.
Un deuxième exemple révèle une amélioration du calcul WCET avec un impact faible sur son coût[104]. Il consiste à combiner une exécution de programme symbolique avec la technique d’énumération de chemins implicites (IPET). Cette opération est réalisée en post traitement à tout analyseur incluant IPET. Elle correspond à un algorithme qui peut être stoppé à tout instant sans impact sur la fiabilité du calcul et qui ajoute un cadre de contraintes de temps pour affiner le WCET. Son implémentation a été réalisée dans la chaîne d’outillage r-TuBound[105].
Un troisième exemple apporte de nouvelles approches d’affinage WCET en optimisant l’utilisation des ressources dans un système multiprocesseurs[106]. Celles-ci visent l’ordonnancement des instructions en tenant compte autant des valeurs de TDMA (time division multiple access), autrement dit tranche de temps par processeur, que de la PD (priority division) qui est la priorité de la TDMA[107]. Elles utilisent une optimisation évolutionniste[108] sur le paramétrage de l’ordonnancement des ressources partagées, ainsi qu’une planification d’instruction qui restructure les programmes d’entrée pour accroître leur performance.
Perspectives
Les récents progrès technologiques et les tendances du marché tendent à faire converger l’informatique de haute performance (HPC) et l’informatique des systèmes embarqués (EC)[109]. En effet, le domaine HPC est réservé pour les traitements de volumes de données très élevés. À l’inverse, le domaine EC est focalisé sur l’exigence de connaitre avec sureté le temps d’exécution des systèmes temps réels. Mais aujourd’hui, l’énorme quantité de données à considérer pour de nombreuses applications embarquées fait que la prévisibilité et la performance deviennent des préoccupations communes. Le défi futur va donc être de prédire avec précision le temps d’exécution sur les prochaines architectures à plusieurs processeurs, en tenant compte aussi des contraintes jusqu’alors propres à chaque domaine tels que l’économie d’énergie, la flexibilité et la performance[110],[111]. L’usage de processeur standard devrait aussi permettre de réduire les coûts industriels mais sa non spécificité à un ensemble de tâches comme il est encore courant pour les systèmes embarqués va rendre le calcul du WCET plus difficile. Toute cette complexité a fait l’objet d’une réflexion[112] menée par un groupe de chercheurs du centre de recherche de Porto[note 23], de l’université de Modène[note 24], du centre de super calcul de Barcelone[note 20] et de l’université de Zürich[note 25].
D'autre part, la programmation de systèmes embarqués de sécurité temps réels nécessitant une attention particulière au niveau de la justesse logicielle mais aussi de l’utilisation des ressources, les techniques de conception avancées utilisent de plus en plus des méthodes de développement basées sur le modèle (ou application)[113],[114],[115]. Dans ce cas, l’application existe sur plusieurs niveaux de description équivalent aux résultats d’une suite de transformations. Une solution courante est d’utiliser la conception basée sur le modèle doté de trois composants: un langage de synchronisation pour développer l’application[116], un compilateur[117], et un outil de simulation[118]. Le langage haut niveau permet le développement modulaire, il possède une sémantique formelle et a la capacité de générer du code impératif. Du point de vue de l'analyse WCET, il permet des annotations au niveau conception à l’opposé d’une instrumentation lourde de bas niveau, et le code impératif qui en découle permet une bonne traçabilité car il adhère à certains critères de certification. Comme ce code impératif est systématiquement construit, il ouvre de nouvelles possibilités d’appliquer une découverte spécifique, d’exprimer et transférer les propriétés du flot vers le niveau de l'analyse WCET du code binaire. L’écart entre le haut niveau axé flot MBD (Model Based Design) et le bas niveau axé analyse de flot WCET nécessite un transfert bi directionnel de la sémantique de programmation[114]. Cette technique s’avère très intéressante pour les domaines de l’avionique et de l’automobile car elle affine efficacement le calcul du WCET[119],[120].
Notes et références
Notes
- WCET pour Worst Case Execution Time qui pourrait être traduit par cas du pire temps d'exécution.
- Outil AIT consultable sur le site AIT
- Outil Bound-T consultable sur le site Bound-T
- Outil Chronos consultable sur le site Chronos
- Outil OTAWA consultable sur le site OTAWA
- Outil RapiTime consultable sur le site Rapitime
- Outil SYMTA/P consultable sur le site SYMTA/P
- Outil Heptane consultable sur le site Heptane
- Conférence des systèmes temps réel en traduction de Euromicro Conference on Real Time Systems
- Conférence des systèmes temps réel de Göteborg 2014
- Conférence des systèmes temps réel de Paris 2013
- Best Case Execution Time pourrait être traduit par cas du meilleur temps d'exécution.
- MBTA pour Measurement-Based Timing Analysis, peut se traduire en Analyse temporelle basée sur la mesure
- Outil SWEET consultable sur le site MRTC
- Société Rapita consultable sur le site Rapita
- Société Space Systems Finland Ltd consultable sur le site SSF
- Agence Spatiale Européenne consultable sur le site ESA
- Projet MERASA consultable sur le site MERASA
- Université de Augsburg UNIA consultable sur le site UNIA
- Centre de supercalcul de Barcelonne consultable sur le site BSC
- Université de Toulouse IRIT consultable sur le site IRIT
- Société Honeywell consultable sur le site Honeywell
- Université de technologie de Porto INESC consultable sur le site INESC
- Université de Modène UNIMORE consultable sur le site UNIMORE
- Université de Zürich ETH consultable sur le site ETH
Références
- Wilhelm 2008, p. 2
- Kirner 2008, p. 334
- Gustafsson 2008, p. 346
- Kligerman 1986, p. 941-949
- Mok 1989
- Puschner 1989, p. 159-176
- Shaw 1989, p. 875-889
- Puschner 2000, p. 1
- Gustafsson 2008, p. 348
- Gustafsson 2006, p. 233
- Gustafsson 2006, p. 234
- Holsti 2008, p. 1
- Wilhelm 2011, p. 1
- Puaut 2005, p. 174
- Puschner 2000, p. 2
- Gustafsson 2008, p. 349
- Puaut 2005, p. 166
- Kirner 2008, p. 338
- Kirner 2005, p. 6
- Kirner 2005, p. 7
- Mueller 1998, p. 144
- Marref 2012, p. 103-115
- Tracey 1998, p. 169--180
- Kirner 2004, p. 7
- Latiu 2012, p. 1
- Wegener 1997, p. 127
- Lundqvist 1999, p. 183
- Păsăreanu 2009, p. 339
- Coen-Porisini 2001, p. 142
- Stewart 2006, p. 1
- Stewart 2006, p. 3
- Benhamamouch 2011, p. 2
- Benhamamouch 2011, p. 3
- Stewart 2006, p. 4
- Benhamamouch 2011, p. 4
- Stewart 2006, p. 5
- Wilhelm 2008, p. 8
- Cousot 1977, p. 238-252
- Nielson 1999, p. 37-44
- Gustafsson 2008, p. 347
- Gustafsson 2008, p. 351
- Wilhelm 2014, p. 97-100
- Wilhelm 2008, p. 19-37
- Colin 2001, p. 37
- Ballabriga 2010, p. 35
- Theiling 2000, p. 24-25
- Malik 1997, p. 150
- Stappert 2000, p. 350
- Wilhelm 2008, p. 11-12
- Wilhelm 2014, p. 97
- Kirner 2008, p. 334-338
- Chu 2011, p. 319-328
- Lokuciejewski 2009, p. 13-17
- Blanchet 2003, p. 197
- Gustafson 2001, p. 257-259
- Cousot 2014
- Bydge 2009, p. 20
- Feautrier 1988, p. 243-268
- Wilhelm 2014, p. 97-98
- Chattopadhyay 2014, p. 101-105
- Wilhelm 2008, p. 38-41
- Healy 1999
- Colin 2001, p. 39-41
- Ferdinand 2008, p. 341
- Lundqvist 1999, p. 255
- Hardy 2013, p. 37
- Metzlaff 2012, p. 1442-1449
- Ballabriga 2010, p. 39-40
- MRTC project
- Guan 2013, p. 297
- Lundqvist 1999, p. 16
- Hardy 2013, p. 37-38
- Ni 2013, p. 459
- Plazar 2011, p. 168-170
- Plazar 2012, p. 47-48
- Stappert 2000, p. 349-350
- Heiko 2009, p. 727
- Engblom 2008, p. 15
- Kirner 2010, p. 96-98
- Falk 2011, p. 13-22
- Raymond 2014, p. 2-4
- Kirner 2005, p. 10
- Bunte 2011, p. 204
- Kirner 2005, p. 2
- Wenzel 2005, p. 10
- Wenzel 2008, p. 444
- Bunte 2011, p. 211
- Kirner 2005, p. 18
- Bunte 2011, p. 205
- Zolda 2011, p. 145
- Wenzel 2008, p. 432
- Colin 2001, p. 37-44
- Mueller 2000, p. 217-247
- Ballabriga 2010, p. 35-46
- Bjorn 2014, p. 482-485
- Schlickling 2010, p. 67-76
- Ferdinand 1999, p. 131-181
- Langenbach 2002, p. 294-309
- Theiling 2000, p. 157-159
- Bernat 2003, p. 1-18
- Ungerer 2010, p. 66-75
- Lokuciejewski 2007
- Guthaus 2001, p. 3-14
- Knoop 2013, p. 161-170
- Knoop 2012, p. 435-444
- Kelter 2014, p. 67-74
- Wandeler 2006, p. 479-484
- Hamann 2005, p. 312-317
- Chattopadhyay 2014
- Paolieri 2009, p. 57
- Wilhelm 2014, p. 102
- Nélis 2014, p. 63-72
- Cruz 2008, p. 308-314
- Asavoae 2013, p. 32-41
- Axer 2014, p. 23-26
- Halbwachs 2005, p. 2
- Puaut 2014, p. 11-20
- Halbwachs 2005, p. 4
- Wilhelm 2014, p. 100-101
- Bylhin 2005, p. 249-250
Voir aussi
Bibliographie
- (en) S. Bydge, A. Ermedhal et B. Lisper, « An Efficient Algorithm for Parametric WCET Calculation », IEEE International Conference on, Beijing, , p. 13-21 (ISBN 978-0-7695-3787-0, DOI 10.1109/RTCSA.2009.9)
- (en) Reinhard Wilhelm, Jakob Engblom, Andreas Ermedahl, Niklas Holsti, Stephan Thesing, David Whalley, Guillem Bernat, Christian Ferdinand, Reinhold Heckmann, Tulika Mitra, Frank Mueller, Isabelle Puaut, Peter Puschner, Jan Staschulat et Per Stenström, « The worst-case execution-time problem—overview of methods and survey of tools », Journal ACM Transactions on Embedded Computing Systems (TECS), Volume 7, Issue 3, New York, (DOI 10.1145/1347375.1347389)
- (en) J. Gustafsson, « Usability Aspects of WCET Analysis », 2008 11th IEEE International Symposium on, Orlando, FL, , p. 346 - 352 (ISBN 978-0-7695-3132-8, DOI 10.1109/ISORC.2008.55)
- (en) C. Ferdinand et R. Heckmann, « Worst-Case Execution Time - A Tool Provider's Perspective », 2008 11th IEEE International Symposium, Orlando, FL, , p. 340-345 (ISBN 978-0-7695-3132-8, DOI 10.1109/ISORC.2008.16)
- (en) R. Kirner et P. Puschner, « Obstacles in Worst-Case Execution Time Analysis », 2008 11th IEEE International Symposium, Orlando, FL, , p. 333-339 (ISBN 978-0-7695-3132-8, DOI 10.1109/ISORC.2008.65)
- (en) Bruno Blanchet, Patrick Cousot, Radhia Cousot, Jérome Feret, Laurent Mauborgne, Antoine Miné, David Monniaux et Xavier Rival, « A static analyzer for large safety-critical software », Newsletter ACM SIGPLAN Notices, Volume 38, Issue 5, New York, , p. 196-207 (ISBN 1-58113-662-5, DOI 10.1145/780822.781153)
- (en) Sascha Plazar, Jan C. Kleinsorge, Peter Marwedel et Heiko Falk, « WCET-aware static locking of instruction caches », CGO '12 Proceedings of the Tenth International Symposium on Code Generation and Optimization, New York, , p. 44-52 (ISBN 978-1-4503-1206-6, DOI 10.1145/2259016.2259023)
- (en) Sudipta Chattopadhyay, Lee Kee Chong, Abhik Roychoudhury, Peter Marwedel et Heiko Falk, « A Unified WCET analysis framework for multicore platforms », ACM Transactions on Embedded Computing Systems (TECS) - Special Issue on Real-Time and Embedded Technology and Applications, Domain-Specific Multicore Computing, Cross-Layer Dependable Embedded Systems, and Application of Concurrency to System Design (ACSD'13), Volume 13 Issue 4s, Article No. 124, New York, , p. 99-108 (DOI 10.1145/2584654)
- (en) Theo Ungerer, Francisco Cazorla, Pascal Seinrat, Guillem Bernat, Zlatko Petrov, Christine Rochange, Eduardo Quinones, Mike Gerdes, Marco Paolieri, julian Wolf, Hugues Casse, Sascha Uhrig, Irakli Guliashvili, Mickael Houston, Floria Kluge, Stefan Metzlaff et Jorg Mische, « Merasa: Multicore Execution of Hard Real-Time Applications Supporting Analyzability », Journal IEEE Micro Volume 30 Issue 5, Los Alamitos, , p. 66-75 (DOI 10.1109/MM.2010.78)
- (en) Philip Axer, Rolf Ernst, Heiko Falk, Alain Girault, Daniel Grund, Nan Guan, Bengt Jonsson, Peter Marwedel, Jan Reineke, Christine Rochange, Maurice Sebastian, Reinhard Von Hanxleden et Reinhard Wilhelm, « Building timing predictable embedded systems », ACM Transactions on Embedded Computing Systems (TECS), Volume 13 Issue 4, Article No. 82, New York, , p. 1-37 (DOI 10.1145/2560033)
- (en) Paul Lokuciejewski, Heiko Falk, Martin Schwarzer, Peter Marwedel et Henrik Theiling, « Influence of procedure cloning on WCET prediction », CODES+ISSS '07 Proceedings of the 5th IEEE/ACM international conference on Hardware/software codesign and system synthesis, New York, , p. 137-142 (ISBN 978-1-59593-824-4, DOI 10.1145/1289816.1289852)
- (en) Huping Ding, Yun Liang et Tulika Mitra, « WCET-centric partial instruction cache locking », DAC '12 Proceedings of the 49th Annual Design Automation Conference, New York, , p. 412-420 (ISBN 978-1-4503-1199-1, DOI 10.1145/2228360.2228434)
- (en) Heiko Falk, « WCET-aware register allocation based on graph coloring », DAC '09 Proceedings of the 46th Annual Design Automation Conference, New York, , p. 726-731 (ISBN 978-1-60558-497-3, DOI 10.1145/1629911.1630100)
- (en) Marref A., « Evolutionary Techniques for Parametric WCET Analysis », 12th International Workshop on Worst-Case Execution Time Analysis, Pise, , p. 103--115 (ISBN 978-3-939897-41-5, DOI 10.4230/OASIcs.WCET.2012.103, lire en ligne)
- (en) Sascha Plazar, Jan Kleinsorge, Heiko Falk et Peter Marwedel, « WCET-driven branch prediction aware code positioning », CASES '11 Proceedings of the 14th international conference on Compilers, architectures and synthesis for embedded systems, , p. 165-174 (ISBN 978-1-4503-0713-0, DOI 10.1145/2038698.2038724)
- (en) Archana Ravindar et Y.N. Srikant, « Estimation of probabilistic bounds on phase CPI and relevance in WCET analysis », EMSOFT '12 Proceedings of the tenth ACM international conference on Embedded software, , p. 165-174 (ISBN 978-1-4503-1425-1, DOI 10.1145/2380356.2380388)
- (en) Thomas Lundqvist et Per Stenström, « An Integrated Path and Timing Analysis Method based on Cycle-Level Symbolic Execution », Real-Time Systems, Volume 17 Issue 2-3, Norwell, , p. 1-27 (DOI 10.1023/A:1008138407139)
- (en) Edu Metz, Raimondas Lencevicius et Teofilo F. Gonzalez, « Performance data collection using a hybrid approach », Proceedings of the 10th European software engineering conference held jointly with 13th ACM SIGSOFT international symposium on Foundations of software engineering, Volume 30 Issue 5, New-York, , p. 126-135 (ISBN 1-59593-014-0, DOI 10.1145/1081706.1081729)
- (en) Guillem Bernat, Antoine Colin et Stefan M. Petters, « WCET Analysis of Probabilistic Hard Real-Time Systems », RTSS '02 Proceedings of the 23rd IEEE Real-Time Systems Symposium, Washington, , p. 279-288 (ISBN 0-7695-1851-6, DOI 10.1109/REAL.2002.1181582)
- (en) Thomas Lundqvist et Per Stenström, « A Method to Improve the Estimated Worst-Case Performance of Data Caching », RTCSA '99 Proceedings of the Sixth International Conference on Real-Time Computing Systems and Applications, Washington, , p. 255 (ISBN 0-7695-0306-3)
- (en) Francisco J. Cazorla, Eduardo Quinones, Tullio Vardanega, Liliana Cucu, Benoit Triquet, Guillem Bernat, Emery Berger, Jaume Abella, Franck Wartel, Mickael Houston, Luca Santinelli, Leonidas Kosmidis, Code Lo et Dorin Maxim, « PROARTIS: Probabilistically Analyzable Real-Time Systems », ACM Transactions on Embedded Computing Systems (TECS) - Special Section on Probabilistic Embedded Computing, Volume 12 Issue 2s, Article No. 94, New-York, (DOI 10.1145/2465787.2465796, lire en ligne)
- (en) Guillem Bernat, Antoine Colin et Stefan Petters, « pWCET: a Tool for Probabilistic Worst-Case Execution Time Analysis of Real-Time Systems », Real-Time Systems Research Group University of York. England, UK, Techical Report YCS-2003-353, York, , p. 1-18 (lire en ligne)
- (en) Damien Hardy et Isabelle Puaut, « Static probabilistic worst case execution time estimation for architectures with faulty instruction caches », Proceedings of the 21st International conference on Real-Time Networks and Systems, New-York, , p. 35-44 (ISBN 978-1-4503-2058-0, DOI 10.1145/2516821.2516842)
- (en) Antoine Colin et Isabelle Puaut, « A Modular & Retargetable Framework for Tree-Based WCET Analysis », ECRTS '01 Proceedings of the 13th Euromicro Conference on Real-Time Systems, Washington, , p. 37-44 (ISBN 0-7695-1221-6, lire en ligne)
- (en) Patrick Cousot et Radhia Cousot, « Abstract interpretation: past, present and future », Proceedings of the Joint Meeting of the Twenty-Third EACSL Annual Conference on Computer Science Logic (CSL) and the Twenty-Ninth Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), Article No. 2, New-York, (ISBN 978-1-4503-2886-9, DOI 10.1145/2603088.2603165)
- (en) Marc Schlickling et Markus Pister, « Semi-automatic derivation of timing models for WCET analysis », ACM SIGPLAN Notices - LCTES '10 Volume 45 Issue 4, New-York, , p. 67-76 (DOI 10.1145/1755951.1755899)
- (en) Reinhard Wilhelm et Daniel Grund, « Computation takes time, but how much? », Magazine "Communications of the ACM", Volume 57 Issue 2, New-York, , p. 94-103 (DOI 10.1145/2500886)
- (en) Clément Ballabriga, Hugues Cassé, Christine Rochange et Pascal Sainrat, « OTAWA: an open toolbox for adaptive WCET analysis », SEUS'10 Proceedings of the 8th IFIP WG 10.2 international conference on Software technologies for embedded and ubiquitous systems, Berlin, , p. 35-46 (ISBN 978-3-642-16256-5)
- (en) Fan Ni, Xiang Long, Han Wan et Xiaopeng Gao, « Using Basic Block Based Instruction Prefetching to Optimize WCET Analysis for Real-Time Applications », Parallel and Distributed Computing, Applications and Technologies (PDCAT), 2012 13th International Conference on, Beijing, , p. 459 - 466 (DOI 10.1109/PDCAT.2012.133)
- (en) T. Kelter, H. Borghorst et P. Marwedel, « WCET-aware scheduling optimizations for multi-core real-time systems », Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS XIV), 2014 International Conference on, Agios Konstantinos, , p. 67-74 (DOI 10.1109/SAMOS.2014.6893196)
- (en) Nan Guan, Ximping Yang et Mingsong Lv, « FIFO cache analysis for WCET estimation: A quantitative approach », Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, , p. 296-301 (ISBN 978-1-4673-5071-6, DOI 10.7873/DATE.2013.073)
- (en) Andre Maroneze, Sandrine Blazy, David Pichardie et Isabelle Puaut, « A Formally Verified WCET Estimation Tool », 14th International Workshop on Worst-Case Execution Time Analysis, Madrid, , p. 11-20 (ISBN 978-3-939897-69-9, DOI 10.4230/OASIcs.WCET.2014.11, lire en ligne)
- (en) Vincent Nélis, Patrick Yomsi, Luís Miguel Pinho, José Carlos Fonseca, Marko Bertogna, Eduardo Quiñones, Roberto Vargas et Andrea Marongiu, « The Challenge of Time-Predictability in Modern Many-Core Architectures », 14th International Workshop on Worst-Case Execution Time Analysis, Madrid, , p. 63-72 (ISBN 978-3-939897-69-9, DOI 10.4230/OASIcs.WCET.2014.63, lire en ligne)
- (en) Jakob Zwirchmayr, Pascal Sotin, Armelle Bonenfant, Denis Claraz et Philippe Cuenot, « Identifying Relevant Parameters to Improve WCET Analysis », 14th International Workshop on Worst-Case Execution Time Analysis, Madrid, , p. 93-102 (ISBN 978-3-939897-69-9, DOI 10.4230/OASIcs.WCET.2014.93, lire en ligne)
- (en) Stefan Metzlaff et Theo Ungerer, « Impact of Instruction Cache and Different Instruction Scratchpads on the WCET Estimate », IEEE 9th International Conference on Embedded Software and Systems (HPCC-ICESS), Liverpool, , p. 1442 - 1449 (ISBN 978-1-4673-2164-8, DOI 10.1109/HPCC.2012.211)
- (en) Heiko Falk, Norman Schmitz et Florian Schmoll, « WCET-aware Register Allocation Based on Integer-Linear Programming », Real-Time Systems (ECRTS), 2011 23rd Euromicro Conference on, Porto, , p. 13-22 (ISBN 978-1-4577-0643-1, DOI 10.1109/ECRTS.2011.10)
- (en) F. Mueller et J. Wegener, « A comparison of static analysis and evolutionary testing for the verification of timing constraints », Real-Time Technology and Applications Symposium, 1998. Proceedings. Fourth IEEE, Denver, , p. 144-154 (ISBN 0-8186-8569-7, DOI 10.1109/RTTAS.1998.683198)
- (en) Jens Knoop, Laura Kovacs et Jakob Zwirchmayr, « WCET squeezing: on-demand feasibility refinement for proven precise WCET-bounds », Proceedings of the 21st International conference on Real-Time Networks and Systems, New-York, , p. 161-170 (ISBN 978-1-4503-2058-0, DOI 10.1145/2516821.2516847)
- (en) Duc-Hiep Chu et Joxan Jaffar, « Symbolic simulation on complicated loops for WCET path analysis », EMSOFT '11 Proceedings of the ninth ACM international conference on Embedded software, New-York, , p. 319-328 (ISBN 978-1-4503-0714-7, DOI 10.1145/2038642.2038692)
- (en) Paul Lokuciejewski, Fatih Gedikli et Peter Marwedel, « Accelerating WCET-driven optimizations by the invariant path paradigm: a case study of loop unswitching », Proceedings of th 12th International Workshop on Software and Compilers for Embedded Systems, New-York, , p. 11-20 (ISBN 978-1-60558-696-0)
- (en) Peter Puschner et Christian Koza, « Calculating the maximum, execution time of real-time programs », Journal Real-Time Systems, Volume 1, Issue 2, Norwell, , p. 159-176 (DOI 10.1007/BF00571421)
- (en) Raimund Kirner, Peter Puschner et Adrian Prantl, « Transforming flow information during code optimization for timing analysis », Journal Real-Time Systems, Volume 45, Issue 1-2, Norwell, , p. 72-105 (DOI 10.1007/s11241-010-9091-8)
- (en) « Mälardalen Real-Time Research Center », Internet Site "The Worst-Case Execution Time (WCET) analysis project", (lire en ligne)
- (en) Bjorn Lisper, « SWEET – a Tool for WCET Flow Analysis », 6th International Symposium On Leveraging Applications of Formal Methods, Verification and Validation, , p. 482-485 (DOI 10.1007/978-3-662-45231-8_38, lire en ligne)
- (en) Jan Gustafsson, « The Worst Case Execution Time Tool Challenge 2006 », Leveraging Applications of Formal Methods, Verification and Validation, 2006. ISoLA 2006. Second International Symposium on, Paphos, , p. 233-240 (ISBN 978-0-7695-3071-0, DOI 10.1109/ISoLA.2006.72)
- (en) Peter Puschner et Alan Burns, « A Review of Worst-Case Execution-Time Analysis », Real-Time Systems, vol. Volume 18, (ISSN 0922-6443, DOI 10.1023/A:1008119029962)
- (en) Reinhard Wilhelm, Jan Gustafsson, Bjorn Lisper, Reinhard von Hanxleden, Niklas Holsti, Erhard Ploedereder, Armelle Bonenfant et Christine Rochange, « WCET Tool Challenge 2011 : Report », Procs 11th Int Workshop on Worst-Case Execution Time (WCET) Analysis, (lire en ligne)
- Isabelle Puaut, « Méthodes de calcul de WCET (Worst-Case Execution Time) Etat de l’art », Ecole d'été Temps Réel 2005 - 4e edition, Nancy, , p. 165-176 (lire en ligne)
- (en) David B. Stewart, « Measuring Execution Time and Real-Time Performance », Embedded Systems Conference, Boston, , p. 1-15 (lire en ligne)
- (en) Frank Mueller et Joachim Wegener, « A comparison of static analysis and evolutionary testing for the verification of timing constraints », Real-Time Technology and Applications Symposium.. Fourth IEEE, Denver, , p. 144-154 (ISBN 0-8186-8569-7, DOI 10.1109/RTTAS.1998.683198)
- (en) Amine Marref, « Evolutionary Techniques for Parametric WCET Analysis », 12th International Workshop on Worst-Case Execution Time (WCET) Analysis, Pise, vol. 23, , p. 103-115 (ISBN 978-3-939897-41-5, ISSN 2190-6807, DOI 10.4230/OASIcs.WCET.2012.i, lire en ligne)
- (en) Nigel Tracey, John Clark et Keith Mander, « The way forward for unifying dynamic test case generation: The optimisation-based approach », International Workshop on Dependable Computing and Its Applications, Heslington, York, , p. 169--180 (lire en ligne)
- (en) Thomas Lundqvist et Per Stenström, « An Integrated Path and Timing Analysis Method based on Cycle-Level Symbolic Execution », Real-Time Systems, vol. 17, , p. 183-207 (ISSN 0922-6443, DOI 10.1023/A:1008138407139)
- (en) Alberto Coen-Porisini, Giovanni Denaro, Carlo Ghezzi et Mauro Pezzè, « Using Symbolic Execution for Verifying Safety-Critical Systems », Proceedings of the 8th European software engineering conference held jointly with 9th ACM SIGSOFT international symposium on Foundations of software engineering, , p. 142-151 (ISBN 1-58113-390-1, DOI 10.1145/503209.503230)
- (en) Corina S. Păsăreanu et Willem Visser, « A survey of new trends in symbolic execution for software testing and analysis », International Journal on Software Tools for Technology Transfer, vol. Volume 11, , p. 339-353 (ISBN 1-58113-390-1, DOI 10.1007/s10009-009-0118-1)
- Bilel Benhamamouch, « Calcul du pire temps d’exécution : Méthode d’analyse formelle s’adaptant à la sophistication croissante des architectures matérielles », These, Grenoble, , p. 1-135 (lire en ligne)
- (en) Flemming Nielson, Hanne R. Nielson et Chris Hankin, « Principles of Program Analysis », Book Principles of Program Analysis, New-York, (ISBN 3540654100)
- (en) Patrick Cousot et Radhia Cousot, « Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints », POPL '77 Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages, New-York, , p. 238-252 (DOI 10.1145/512950.512973)
- (en) A.C. Shaw, « Reasoning about time in higher-level language software », Software Engineering, IEEE Transactions on (Volume:15 , Issue: 7), Seattle, , p. 875-889 (DOI 10.1109/32.29487)
- (en) H. Theiling, « Extracting safe and precise control flow from binaries », Real-Time Computing Systems and Applications, 2000. Proceedings., Cheju Island, , p. 23-30 (ISBN 0-7695-0930-4, DOI 10.1109/RTCSA.2000.896367)
- (en) Friedhelm Stappert et Peter Altenbernd, « Complete worst-case execution time analysis of straight-line hard real-time programs », Journal of Systems Architecture: the EUROMICRO Journal - Special issue on real-time systems, New-York, , p. 339-355 (DOI 10.1016/S1383-7621(99)00010-7)
- (en) Sharad Malik, Margaret Martonosi et Yau-Tsun Steven Li, « Static Timing Analysis of Embedded Software », DAC '97 Proceedings of the 34th annual Design Automation Conference, New-York, , p. 147-152 (ISBN 0-89791-920-3, DOI 10.1145/266021.266052)
- (en) Jan Gustafsson et Andreas Ermedahl, « Automatic derivation of path and loop annotations in object-oriented real-time programs », Engineering of distributed control systems, New-York, , p. 81-98 (ISBN 1-59033-102-8)
- (en) A. Mok, P. Amerasinghe, M. Chen et K. Tantisirivat, « Evaluating tight execution time bounds of programs by annotations », IEEE Real-Time Systems Newsletter, Volume 5 Issue 2-3, Washington, , p. 74-80
- (en) Christopher A. Healy, Robert D. Arnold, Franck Mueller, Marion G. Harmon et David b. Walley, « Bounding Pipeline and Instruction Cache Performance », IEEE Transactions on Computers archive, Volume 48 Issue 1, Washington, , p. 53-70 (DOI 10.1109/12.743411)
- (en) Pascal Raymond, « A general approach for expressing infeasibility in implicit path enumeration technique », Proceedings of the 14th International Conference on Embedded Software, Article No. 8, New-York, , p. 1-9 (ISBN 978-1-4503-3052-7, DOI 10.1145/2656045.2656046)
- (en) Frank Mueller, « Timing Analysis for Instruction Caches », Real-Time Systems - Special issue on worst-case execution-time analysis, Volume 18 Issue 2/3, Norwell, , p. 217-247 (DOI 10.1023/A:1008145215849)
- (en) Christian Ferdinand et Reinhard Wilhelm, « Efficient and Precise Cache Behavior Prediction for Real-TimeSystems », Real-Time Systems, Volume 17 Issue 2-3, Norwell, , p. 131-181 (DOI 10.1023/A:1008186323068)
- (en) Marc Langenbach, Stephan Thesing et Reinhold Heckmann, « Pipeline Modeling for Timing Analysis », SAS '02 Proceedings of the 9th International Symposium on Static Analysis, Londres, , p. 294-309 (ISBN 3-540-44235-9)
- (en) Henrik Theiling, Christian Ferdinand et Reinhard Wilhelm, « Fast and Precise WCET Prediction by Separated Cache andPath Analyses », Real-Time Systems - Special issue on worst-case execution-time analysis, Volume 18 Issue 2/3, , p. 157-179 (DOI 10.1023/A:1008141130870)
- (en) Paul Feautrier, « Parametric Integer Programming », RAIRO Recherche Operationnelle, volume 22, no. 3, , p. 243-268 (DOI 10.1051/ro/1988220302431)
- (en) Marco Paolieri, Eduardo Quinones, Francisco J. Cazorla, Guillem Bernat et Mateo Valero, « Hardware support for WCET analysis of hard real-time multicore systems », Proceedings of the 36th annual international symposium on Computer architecture, New-York, , p. 57-68 (ISBN 978-1-60558-526-0, DOI 10.1145/1555754.1555764)
- (en) Raimund Kirner, Peter Puschner et Ingomar Wenzel, « Measurement-based worst-case execution time analysis using automatic test-data generation », Proc. IEEE Workshop on Software Tech. for Future Embedded and Ubiquitous Systs, , p. 7-10 (lire en ligne)
- (en) Fabiano Cruz, Raimundo Barreto et Lucas Cordeiro, « Towards a model-driven engineering approach for developing embedded hard real-time software », Proceedings of the 2008 ACM symposium on Applied computing, New-York, , p. 308-314 (ISBN 978-1-59593-753-7, DOI 10.1145/1363686.1363765)
- (en) S. Byhlin, A. Ermedahl, J. Gustafsson et B. Lisper, « Applying static WCET analysis to automotive communication software », Real-Time Systems, 2005. (ECRTS 2005). Proceedings. 17th Euromicro Conference on, , p. 249-258 (ISBN 0-7695-2400-1, DOI 10.1109/ECRTS.2005.7)
- (en) Milhail Asavoae, Claire Maiza et Pascal Raymond, « Program Semantics in Model-Based WCET Analysis: A State of the Art Perspective », 13th International Workshop on Worst-Case Execution Time Analysis, Paris, , p. 32-41 (DOI 10.4230/OASIcs.WCET.2013.32)
- (en) N. Halbwachs, « A synchronous language at work: the story of Lustre », MEMOCODE '05 Proceedings of the 2nd ACM/IEEE International Conference on Formal Methods and Models for Co-Design, Washington, , p. 3-11 (ISBN 0-7803-9227-2, DOI 10.1109/MEMCOD.2005.1487884)
- (en) Jens Knoop, Laura Kovacs et Jakob Zwirchmayr, « r-TuBound: loop bounds for WCET analysis (tool paper) », LPAR'12 Proceedings of the 18th international conference on Logic for Programming, Artificial Intelligence, and Reasoning, Berlin, , p. 435-444 (ISBN 978-3-642-28716-9, DOI 10.1007/978-3-642-28717-6_34)
- (en) Ernesto Wandeler et Lothar Thiele, « Optimal TDMA time slot and cycle length allocation for hard real-time systems », ASP-DAC '06 Proceedings of the 2006 Asia and South Pacific Design Automation Conference, , p. 479-484 (ISBN 0-7803-9451-8, DOI 10.1145/1118299.1118417)
- (en) A. Hamann et R. Ernst, « TDMA time slot and turn optimization with evolutionary search techniques », Design, Automation and Test in Europe, 2005. Proceedings, , p. 312-317 (ISBN 0-7695-2288-2, DOI 10.1109/DATE.2005.299)
- (en) Raimund Kirner, Ingomar Wenzel, Bernhard Rieder et Peter Puschner, « Using Measurements as a Complement to Static Worst-Case Execution Time Analysis », Intelligent Systems at the Service of Mankind, vol. 2, , p. 1-22 (lire en ligne)
- (en) Sven Bünte, Michael Zolda et Raimund Kirner, « Let's get less optimistic in measurement-based timing analysis », Industrial Embedded Systems (SIES), 6th IEEE International Symposium on, Vasteras, , p. 204-212 (ISBN 978-1-61284-818-1, DOI 10.1109/SIES.2011.5953663)
- (en) Ingomar Wenzel, Raimund Kirner, Bernhard Rieder et Peter Puschner, « Measurement-based timing analysis », In Proc. 3rd International Symposium on Leveraging Applications of Formal Methods, Verification and Validation, Porto Sani, vol. 17, , p. 430-444 (ISBN 978-3-540-88478-1, ISSN 1865-0929, DOI 10.1007/978-3-540-88479-8_30)
- (en) Michael Zolda, Sven Bünte, Michael Tautschnig et Raimund Kirner, « Improving the Confidence in Measurement-Based Timing Analysis », Object/Component/Service-Oriented Real-Time Distributed Computing (ISORC), 2011 14th IEEE International Symposium on, Newport Beach, , p. 144-151 (ISBN 978-1-61284-433-6, DOI 10.1109/ISORC.2011.27)
- (en) Ingomar Wenzel, Raimund Kirner, Bernhard Rieder et Peter Puschner, « Measurement-based worst-case execution time analysis », Software Technologies for Future Embedded and Ubiquitous Systems, 2005. SEUS 2005. Third IEEE Workshop on, , p. 7-10 (ISBN 0-7695-2357-9, DOI 10.1109/SEUS.2005.12)
- (en) E Kligerman et Alexander David Stoyenko, « Real-Time Euclid: A language for reliable real-time systems », Software Engineering, IEEE Transactions on, vol. 12, no 9, , p. 941-949 (ISSN 0098-5589, DOI 10.1109/TSE.1986.6313049)
- (en) Niklas Holsti, Jan Gustafsson, Guillem Bernat, Clément Ballabriga, Armelle Bonenfant, Roman Bourgade, Hugues Cassé, Daniel Cordes, Albrecht Kadlec, Raimund Kirner, Jens Knoop, Paul Lokuciejewski, Nicholas Merriam, Marianne de Michiel, Adrian Prantl, Bernhard Rieder, Christine Rochange, Pascal Sainrat et Markus Schordan, « 8th International Workshop on Worst-Case Execution Time Analysis (WCET'08) », proceedings of the WCET Workshop 2008, , p. 1-23 (ISBN 978-3-939897-10-1, ISSN 2190-6807, DOI 10.4230/OASIcs.WCET.2008.1663, lire en ligne)
- (en) Joachim Wegener, Harmen Sthamer, Bryan F. Jones et David E. Eyres, « Testing real-time systems using genetic algorithms », Software Quality Journal, vol. 6, no 2, , p. 127-135 (ISSN 0963-9314, DOI 10.1023/A:1018551716639)
- (en) G. I. Latiu, O. A. Cret et L. Vacariu, « Emerging Intelligent Data and Web Technologies », Automatic Test Data Generation for Software Path Testing Using Evolutionary Algorithms, Bucharest, , p. 1-8 (ISBN 978-1-4673-1986-7, DOI 10.1109/EIDWT.2012.25)
- (en) M.R. Guthaus, J.S. Ringenberg, D. Ernst, T.M. Austin, T. Mudge et R.B. Brown, « MiBench: A free, commercially representative embedded benchmark suite », WWC '01 Proceedings of the Workload Characterization, 2001. WWC-4. 2001 IEEE International Workshop, Washington, , p. 3-14 (ISBN 0-7803-7315-4, DOI 10.1109/WWC.2001.15)
 Portail de l’informatique
Portail de l’informatique  Portail de l'informatique théorique
Portail de l'informatique théorique