UTF-8
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode Transformation Format – 8-bit.[1]
| Standard | Unicode Standard |
|---|---|
| Classification | Unicode Transformation Format, extended ASCII, variable-length encoding |
| Extends | ASCII |
| Transforms / Encodes | ISO/IEC 10646 (Unicode) |
| Preceded by | UTF-1 |
UTF-8 is capable of encoding all 1,112,064[lower-alpha 1] valid Unicode code points using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more frequently, are encoded using fewer bytes. It was designed for backward compatibility with ASCII: the first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single byte with the same binary value as ASCII, so that valid ASCII text is valid UTF-8-encoded Unicode as well.
UTF-8 was designed as a superior alternative to UTF-1, a proposed variable-length encoding with partial ASCII compatibility which lacked some features including self-synchronization and fully ASCII-compatible handling of characters such as slashes. Ken Thompson and Rob Pike produced the first implementation for the Plan 9 operating system in September 1992.[2][3] This led to its adoption by X/Open as its specification for FSS-UTF,[4] which would first be officially presented at USENIX in January 1993[5] and subsequently adopted by the Internet Engineering Task Force (IETF) in RFC 2277 (BCP 18)[6] for future internet standards work, replacing Single Byte Character Sets such as Latin-1 in older RFCs.
UTF-8 results in fewer internationalization issues[7][8] than any alternative text encoding, and it has been implemented in all modern operating systems, including Microsoft Windows, and standards such as JSON, where, as is increasingly the case, it is the only allowed form of Unicode.
UTF-8 is the dominant encoding for the World Wide Web (and internet technologies), accounting for 98.0% of all web pages, 99.0% of the top 10,000 pages, and up to 100% for many languages, as of 2023.[9] Virtually all countries and languages have 95% or more use of UTF-8 encodings on the web.
Naming
The official name for the encoding is UTF-8, the spelling used in all Unicode Consortium documents. Most standards officially list it in upper case as well, but all that do are also case-insensitive and utf-8 is often used in code.
Some other spellings may also be accepted by standards, e.g. web standards (which include CSS, HTML, XML, and HTTP headers) explicitly allow utf8 (and disallow "unicode") and many aliases for encodings.[10] Spellings with a space e.g. "UTF 8" should not be used. The official Internet Assigned Numbers Authority also lists csUTF8 as the only alias,[11] which is rarely used.
In Windows, UTF-8 is codepage 65001[12] (i.e. CP_UTF8 in source code).
In MySQL, UTF-8 is called utf8mb4[13] (with utf8mb3, and its alias utf8, being a subset encoding for characters in the Basic Multilingual Plane[14]). In HP PCL, the Symbol-ID for UTF-8 is 18N.[15]
In Oracle Database (since version 9.0), AL32UTF8[16] means UTF-8. See also CESU-8 for an almost synonym with UTF-8 that rarely should be used.
UTF-8-BOM and UTF-8-NOBOM are sometimes used for text files which contain or do not contain a byte order mark (BOM), respectively. In Japan especially, UTF-8 encoding without a BOM is sometimes called UTF-8N.[17][18]
Encoding
UTF-8 encodes code points in one to four bytes, depending on the value of the code point. In the following table, the x characters are replaced by the bits of the code point:
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 | [lower-alpha 2]U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
The first 128 code points (ASCII) need one byte. The next 1,920 code points need two bytes to encode, which covers the remainder of almost all Latin-script alphabets, and also IPA extensions, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N'Ko alphabets, as well as Combining Diacritical Marks. Three bytes are needed for the remaining 61,440 code points of the Basic Multilingual Plane (BMP), including most Chinese, Japanese and Korean characters. Four bytes are needed for the 1,048,576 code points in the other planes of Unicode, which include emoji (pictographic symbols), less common CJK characters, various historic scripts, and mathematical symbols.
A "character" can take more than 4 bytes because it is made of more than one code point. For instance a national flag character takes 8 bytes since it is "constructed from a pair of Unicode scalar values" both from outside the BMP.[19][lower-alpha 3]
Encoding process
In these examples, red, green, and blue digits indicate how bits from the code point are distributed among the UTF-8 bytes. Additional bits added by the UTF-8 encoding process are shown in black.
- The Unicode code point for the euro sign € is U+20AC.
- As this code point lies between U+0800 and U+FFFF, this will take three bytes to encode.
- Hexadecimal 20AC is binary 0010 0000 1010 1100. The two leading zeros are added because a three-byte encoding needs exactly sixteen bits from the code point.
- Because the encoding will be three bytes long, its leading byte starts with three 1s, then a 0 (1110...)
- The four most significant bits of the code point are stored in the remaining low order four bits of this byte (11100010), leaving 12 bits of the code point yet to be encoded (...0000 1010 1100).
- All continuation bytes contain exactly six bits from the code point. So the next six bits of the code point are stored in the low order six bits of the next byte, and 10 is stored in the high order two bits to mark it as a continuation byte (so 10000010).
- Finally the last six bits of the code point are stored in the low order six bits of the final byte, and again 10 is stored in the high order two bits (10101100).
The three bytes 11100010 10000010 10101100 can be more concisely written in hexadecimal, as E2 82 AC.
The following table summarizes this conversion, as well as others with different lengths in UTF-8.
| Character | Binary code point | Binary UTF-8 | Hex UTF-8 | |
|---|---|---|---|---|
| $ | U+0024 | 010 0100 | 00100100 | 24 |
| £ | U+00A3 | 000 1010 0011 | 11000010 10100011 | C2 A3 |
| И | U+0418 | 100 0001 1000 | 11010000 10011000 | D0 98 |
| ह | U+0939 | 0000 1001 0011 1001 | 11100000 10100100 10111001 | E0 A4 B9 |
| € | U+20AC | 0010 0000 1010 1100 | 11100010 10000010 10101100 | E2 82 AC |
| 한 | U+D55C | 1101 0101 0101 1100 | 11101101 10010101 10011100 | ED 95 9C |
| 𐍈 | U+10348 | 0 0001 0000 0011 0100 1000 | 11110000 10010000 10001101 10001000 | F0 90 8D 88 |
Example
In these examples, colored digits indicate multi-byte sequences used to encode characters beyond ASCII, while digits in black are ASCII.
As an example, the Vietnamese phrase Mình nói tiếng Việt (𨉟呐㗂越, "I speak Vietnamese") is encoded as follows:
| Character | M | ì | n | h | n | ó | i | t | i | ế | n | g | V | i | ệ | t | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code point | 4D | EC | 6E | 68 | 20 | 6E | F3 | 69 | 20 | 74 | 69 | 1EBF | 6E | 67 | 20 | 56 | 69 | 1EC7 | 74 | ||||||
| Hex UTF-8 | C3 | AC | C3 | B3 | E1 | BA | BF | E1 | BB | 87 | |||||||||||||||
| Character | 𨉟 | 呐 | 㗂 | 越 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code point | 2825F | 5450 | 35C2 | 8D8A | |||||||||
| Hex UTF-8 | F0 | A8 | 89 | 9F | E5 | 91 | 90 | E3 | 97 | 82 | E8 | B6 | 8A |
Codepage layout
The following table summarizes usage of UTF-8 code units (individual bytes or octets) in a code page format. The upper half is for bytes used only in single-byte codes, so it looks like a normal code page; the lower half is for continuation bytes and leading bytes and is explained further in the legend below.
| UTF-8 | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | +0 | +1 | +2 | +3 | +4 | +5 | +6 | +7 | +8 | +9 | +A | +B | +C | +D | +E | +F |
| 9x | +10 | +11 | +12 | +13 | +14 | +15 | +16 | +17 | +18 | +19 | +1A | +1B | +1C | +1D | +1E | +1F |
| Ax | +20 | +21 | +22 | +23 | +24 | +25 | +26 | +27 | +28 | +29 | +2A | +2B | +2C | +2D | +2E | +2F |
| Bx | +30 | +31 | +32 | +33 | +34 | +35 | +36 | +37 | +38 | +39 | +3A | +3B | +3C | +3D | +3E | +3F |
| Cx | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Dx | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Ex | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| Fx | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 6 | 6 | ||
Overlong encodings
In principle, it would be possible to inflate the number of bytes in an encoding by padding the code point with leading 0s. To encode the euro sign € from the above example in four bytes instead of three, it could be padded with leading 0s until it was 21 bits long – 000 000010 000010 101100, and encoded as 11110000 10000010 10000010 10101100 (or F0 82 82 AC in hexadecimal). This is called an overlong encoding.
The standard specifies that the correct encoding of a code point uses only the minimum number of bytes required to hold the significant bits of the code point. Longer encodings are called overlong and are not valid UTF-8 representations of the code point. This rule maintains a one-to-one correspondence between code points and their valid encodings, so that there is a unique valid encoding for each code point. This ensures that string comparisons and searches are well-defined.
Invalid sequences and error handling
Not all sequences of bytes are valid UTF-8. A UTF-8 decoder should be prepared for:
- invalid bytes
- an unexpected continuation byte
- a non-continuation byte before the end of the character
- the string ending before the end of the character (which can happen in simple string truncation)
- an overlong encoding
- a sequence that decodes to an invalid code point
Many of the first UTF-8 decoders would decode these, ignoring incorrect bits and accepting overlong results. Carefully crafted invalid UTF-8 could make them either skip or create ASCII characters such as NUL, slash, or quotes. Invalid UTF-8 has been used to bypass security validations in high-profile products including Microsoft's IIS web server[26] and Apache's Tomcat servlet container.[27] RFC 3629 states "Implementations of the decoding algorithm MUST protect against decoding invalid sequences."[23] The Unicode Standard requires decoders to "...treat any ill-formed code unit sequence as an error condition. This guarantees that it will neither interpret nor emit an ill-formed code unit sequence."
Since RFC 3629 (November 2003), the high and low surrogate halves used by UTF-16 (U+D800 through U+DFFF) and code points not encodable by UTF-16 (those after U+10FFFF) are not legal Unicode values, and their UTF-8 encoding must be treated as an invalid byte sequence. Not decoding unpaired surrogate halves makes it impossible to store invalid UTF-16 (such as Windows filenames or UTF-16 that has been split between the surrogates) as UTF-8,[28] while it is possible with WTF-8.
Some implementations of decoders throw exceptions on errors.[29] This has the disadvantage that it can turn what would otherwise be harmless errors (such as a "no such file" error) into a denial of service. For instance early versions of Python 3.0 would exit immediately if the command line or environment variables contained invalid UTF-8.[30]
Since Unicode 6[31] (October 2010), the standard (chapter 3) has recommended a "best practice" where the error is either one byte long, or ends before the first byte that is disallowed. In these decoders E1,A0,C0 is two errors (2 bytes in the first one). This means an error is no more than three bytes long and never contains the start of a valid character, and there are 21,952 different possible errors.[32] The standard also recommends replacing each error with the replacement character "�" (U+FFFD).
These recommendations are not often followed. It is common to consider each byte to be an error, in which case E1,A0,C0 is three errors (each 1 byte long). This means there are only 128 different errors, and it is also common to replace them with 128 different characters, to make the decoding "lossless".[33]
Byte order mark
If the Unicode byte order mark (BOM, U+FEFF) character is at the start of a UTF-8 file, the first three bytes will be 0xEF, 0xBB, 0xBF.
The Unicode Standard neither requires nor recommends the use of the BOM for UTF-8, but warns that it may be encountered at the start of a file trans-coded from another encoding.[34] While ASCII text encoded using UTF-8 is backward compatible with ASCII, this is not true when Unicode Standard recommendations are ignored and a BOM is added. A BOM can confuse software that isn't prepared for it but can otherwise accept UTF-8, e.g. programming languages that permit non-ASCII bytes in string literals but not at the start of the file. Nevertheless, there was and still is software that always inserts a BOM when writing UTF-8, and refuses to correctly interpret UTF-8 unless the first character is a BOM (or the file only contains ASCII).[35]
Adoption
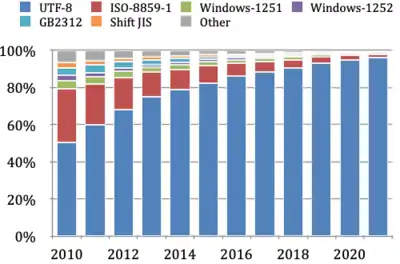
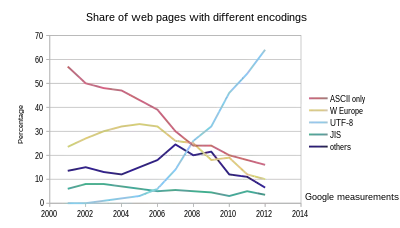
UTF-8 has been the most common encoding for the World Wide Web since 2008.[37] As of October 2023, UTF-8 is used by 98.0% of surveyed web sites.[9][lower-alpha 5] Although many pages only use ASCII characters to display content, few websites now declare their encoding to only be ASCII instead of UTF-8.[38] Over 50% of the languages tracked have 100% UTF-8 use.
Many standards only support UTF-8, e.g. JSON exchange requires it (without a byte order mark (BOM)).[39] UTF-8 is also the recommendation from the WHATWG for HTML and DOM specifications, and stating "UTF-8 encoding is the most appropriate encoding for interchange of Unicode"[8] and the Internet Mail Consortium recommends that all e‑mail programs be able to display and create mail using UTF-8.[40][41] The World Wide Web Consortium recommends UTF-8 as the default encoding in XML and HTML (and not just using UTF-8, also declaring it in metadata), "even when all characters are in the ASCII range ... Using non-UTF-8 encodings can have unexpected results".[42]
Lots of software has the ability to read/write UTF-8. It may though require the user to change options from the normal settings, or may require a BOM (byte order mark) as the first character to read the file. Examples of software supporting UTF-8 include Microsoft Word,[43][44][45] Microsoft Excel (2016 and later),[46][47] Google Drive, LibreOffice and most databases.
However for local text files UTF-8 usage is less prevalent, where legacy single-byte (and a few CJK multi-byte) encodings remain in use. The primary cause for this are outdated text editors that refuse to read UTF-8 unless the first bytes of the file encode a byte order mark character (BOM).[48]
Some recent software can only read and write UTF-8 or at least do not require a BOM.[49] Windows Notepad, in all currently supported versions of Windows, defaults to writing UTF-8 without a BOM (a change from the outdated/unsupported Windows 7), bringing it into line with most other text editors.[50] Some system files on Windows 11 require UTF-8[51] with no requirement for a BOM, and almost all files on macOS and Linux are required to be UTF-8 without a BOM. Java 18 defaults to reading and writing files as UTF-8,[52] and in older versions (e.g. LTS versions) only the NIO API was changed to do so. Many other programming languages default to UTF-8 for I/O, including Ruby 3.0[53][54] and R 4.2.2.[55] All currently supported versions of Python support UTF-8 for I/O, even on Windows (where it is opt-in for the open() function[56]), and plans exist to make UTF-8 I/O the default in Python 3.15 on all platforms.[57][58] C++23 adopts UTF-8 as the only portable source code file format (surprisingly there was none before).[59]
Usage of UTF-8 in memory is much lower than in other areas, UTF-16 is often used instead. This occurs particularly in Windows, but also in JavaScript, Python,[lower-alpha 6] Qt, and many other cross-platform software libraries. Compatibility with the Windows API is the primary reason for this, that choice was initially done due to the belief that direct indexing of the BMP would improve speed. Translating from/to external text which is in UTF-8 slows software down, and more importantly introduces bugs when different pieces of code do not do the exact same translation.
Back-compatibility is a serious impediment to changing code to use UTF-8 instead of a 16-bit encoding, but this is happening. The default string primitive in Go,[61] Julia, Rust, Swift 5,[62] and PyPy[63] uses UTF-8 internally in all cases, while Python, since Python 3.3, uses UTF-8 internally in some cases (for Python C API extensions);[60][64] a future version of Python is planned to store strings as UTF-8 by default;[65][66] and modern versions of Microsoft Visual Studio use UTF-8 internally.[67] Microsoft's SQL Server 2019 added support for UTF-8, and using it results in a 35% speed increase, and "nearly 50% reduction in storage requirements."[68]
All currently supported Windows versions support UTF-8 in some way (including Xbox);[7] partial support has existed since at least Windows XP. As of May 2019, Microsoft has reversed its previous position of only recommending UTF-16; the capability to set UTF-8 as the "code page" for the Windows API was introduced; and Microsoft recommends programmers use UTF-8,[69] and even states "UTF-16 [..] is a unique burden that Windows places on code that targets multiple platforms."[7]
History
The International Organization for Standardization (ISO) set out to compose a universal multi-byte character set in 1989. The draft ISO 10646 standard contained a non-required annex called UTF-1 that provided a byte stream encoding of its 32-bit code points. This encoding was not satisfactory on performance grounds, among other problems, and the biggest problem was probably that it did not have a clear separation between ASCII and non-ASCII: new UTF-1 tools would be backward compatible with ASCII-encoded text, but UTF-1-encoded text could confuse existing code expecting ASCII (or extended ASCII), because it could contain continuation bytes in the range 0x21–0x7E that meant something else in ASCII, e.g., 0x2F for '/', the Unix path directory separator, and this example is reflected in the name and introductory text of its replacement. The table below was derived from a textual description in the annex.
| Number of bytes | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+009F | 00–9F | ||||
| 2 | U+00A0 | U+00FF | A0 | A0–FF | |||
| 2 | U+0100 | U+4015 | A1–F5 | 21–7E, A0–FF | |||
| 3 | U+4016 | U+38E2D | F6–FB | 21–7E, A0–FF | 21–7E, A0–FF | ||
| 5 | U+38E2E | U+7FFFFFFF | FC–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF |
In July 1992, the X/Open committee XoJIG was looking for a better encoding. Dave Prosser of Unix System Laboratories submitted a proposal for one that had faster implementation characteristics and introduced the improvement that 7-bit ASCII characters would only represent themselves; all multi-byte sequences would include only bytes where the high bit was set. The name File System Safe UCS Transformation Format (FSS-UTF) and most of the text of this proposal were later preserved in the final specification.[70][71][72][73]
FSS-UTF
| Number of bytes | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+007F | 0xxxxxxx | ||||
| 2 | U+0080 | U+207F | 10xxxxxx | 1xxxxxxx | |||
| 3 | U+2080 | U+8207F | 110xxxxx | 1xxxxxxx | 1xxxxxxx | ||
| 4 | U+82080 | U+208207F | 1110xxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | |
| 5 | U+2082080 | U+7FFFFFFF | 11110xxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx |
In August 1992, this proposal was circulated by an IBM X/Open representative to interested parties. A modification by Ken Thompson of the Plan 9 operating system group at Bell Labs made it self-synchronizing, letting a reader start anywhere and immediately detect character boundaries, at the cost of being somewhat less bit-efficient than the previous proposal. It also abandoned the use of biases and instead added the rule that only the shortest possible encoding is allowed; the additional loss in compactness is relatively insignificant, but readers now have to look out for invalid encodings to avoid reliability and especially security issues. Thompson's design was outlined on September 2, 1992, on a placemat in a New Jersey diner with Rob Pike. In the following days, Pike and Thompson implemented it and updated Plan 9 to use it throughout, and then communicated their success back to X/Open, which accepted it as the specification for FSS-UTF.[72]
| Number of bytes | First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+007F | 0xxxxxxx | |||||
| 2 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||||
| 3 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 4 | U+10000 | U+1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 5 | U+200000 | U+3FFFFFF | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 6 | U+4000000 | U+7FFFFFFF | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
UTF-8 was first officially presented at the USENIX conference in San Diego, from January 25 to 29, 1993. The Internet Engineering Task Force adopted UTF-8 in its Policy on Character Sets and Languages in RFC 2277 (BCP 18) for future internet standards work, replacing Single Byte Character Sets such as Latin-1 in older RFCs.[6]
In November 2003, UTF-8 was restricted by RFC 3629 to match the constraints of the UTF-16 character encoding: explicitly prohibiting code points corresponding to the high and low surrogate characters removed more than 3% of the three-byte sequences, and ending at U+10FFFF removed more than 48% of the four-byte sequences and all five- and six-byte sequences.
Standards
There are several current definitions of UTF-8 in various standards documents:
- RFC 3629 / STD 63 (2003), which establishes UTF-8 as a standard internet protocol element
- RFC 5198 defines UTF-8 NFC for Network Interchange (2008)
- ISO/IEC 10646:2014 §9.1 (2014)[74]
- The Unicode Standard, Version 15.0.0 (2022)[75]
They supersede the definitions given in the following obsolete works:
- The Unicode Standard, Version 2.0, Appendix A (1996)
- ISO/IEC 10646-1:1993 Amendment 2 / Annex R (1996)
- RFC 2044 (1996)
- RFC 2279 (1998)
- The Unicode Standard, Version 3.0, §2.3 (2000) plus Corrigendum #1 : UTF-8 Shortest Form (2000)
- Unicode Standard Annex #27: Unicode 3.1 (2001)[76]
- The Unicode Standard, Version 5.0 (2006)[77]
- The Unicode Standard, Version 6.0 (2010)[78]
They are all the same in their general mechanics, with the main differences being on issues such as allowed range of code point values and safe handling of invalid input.
Comparison with other encodings
Some of the important features of this encoding are as follows:
- Backward compatibility: Backward compatibility with ASCII and the enormous amount of software designed to process ASCII-encoded text was the main driving force behind the design of UTF-8. In UTF-8, single bytes with values in the range of 0 to 127 map directly to Unicode code points in the ASCII range. Single bytes in this range represent characters, as they do in ASCII. Moreover, 7-bit bytes (bytes where the most significant bit is 0) never appear in a multi-byte sequence, and no valid multi-byte sequence decodes to an ASCII code-point. A sequence of 7-bit bytes is both valid ASCII and valid UTF-8, and under either interpretation represents the same sequence of characters. Therefore, the 7-bit bytes in a UTF-8 stream represent all and only the ASCII characters in the stream. Thus, many text processors, parsers, protocols, file formats, text display programs, etc., which use ASCII characters for formatting and control purposes, will continue to work as intended by treating the UTF-8 byte stream as a sequence of single-byte characters, without decoding the multi-byte sequences. ASCII characters on which the processing turns, such as punctuation, whitespace, and control characters will never be encoded as multi-byte sequences. It is therefore safe for such processors to simply ignore or pass-through the multi-byte sequences, without decoding them. For example, ASCII whitespace may be used to tokenize a UTF-8 stream into words; ASCII line-feeds may be used to split a UTF-8 stream into lines; and ASCII NUL characters can be used to split UTF-8-encoded data into null-terminated strings. Similarly, many format strings used by library functions like "printf" will correctly handle UTF-8-encoded input arguments.
- Fallback and auto-detection: Only a small subset of possible byte strings are a valid UTF-8 string: several bytes cannot appear; a byte with the high bit set cannot be alone; and further requirements mean that it is extremely unlikely that a readable text in any extended ASCII is valid UTF-8. Part of the popularity of UTF-8 is due to it providing a form of backward compatibility for these as well. A UTF-8 processor which erroneously receives extended ASCII as input can thus "auto-detect" this with very high reliability. A UTF-8 stream may simply contain errors, resulting in the auto-detection scheme producing false positives; but auto-detection is successful in the vast majority of cases, especially with longer texts, and is widely used. It also works to "fall back" or replace 8-bit bytes using the appropriate code-point for a legacy encoding when errors in the UTF-8 are detected, allowing recovery even if UTF-8 and legacy encoding is concatenated in the same file.
- Prefix code: The first byte indicates the number of bytes in the sequence. Reading from a stream can instantaneously decode each individual fully received sequence, without first having to wait for either the first byte of a next sequence or an end-of-stream indication. The length of multi-byte sequences is easily determined by humans as it is simply the number of high-order 1s in the leading byte. An incorrect character will not be decoded if a stream ends mid-sequence.
- Self-synchronization: The leading bytes and the continuation bytes do not share values (continuation bytes start with the bits 10 while single bytes start with 0 and longer lead bytes start with 11). This means a search will not accidentally find the sequence for one character starting in the middle of another character. It also means the start of a character can be found from a random position by backing up at most 3 bytes to find the leading byte. An incorrect character will not be decoded if a stream starts mid-sequence, and a shorter sequence will never appear inside a longer one.
- Sorting order: The chosen values of the leading bytes means that a list of UTF-8 strings can be sorted in code point order by sorting the corresponding byte sequences.
Single-byte
- UTF-8 can encode any Unicode character, avoiding the need to figure out and set a "code page" or otherwise indicate what character set is in use, and allowing output in multiple scripts at the same time. For many scripts there have been more than one single-byte encoding in usage, so even knowing the script was insufficient information to display it correctly.
- The bytes 0xFE and 0xFF do not appear, so a valid UTF-8 stream never matches the UTF-16 byte order mark and thus cannot be confused with it. The absence of 0xFF (0377) also eliminates the need to escape this byte in Telnet (and FTP control connection).
- UTF-8 encoded text is larger than specialized single-byte encodings except for plain ASCII characters. In the case of scripts which used 8-bit character sets with non-Latin characters encoded in the upper half (such as most Cyrillic and Greek alphabet code pages), characters in UTF-8 will be double the size. For some scripts, such as Thai and Devanagari (which is used by various South Asian languages), characters will triple in size. There are even examples where a single byte turns into a composite character in Unicode and is thus six times larger in UTF-8. This has caused objections in India and other countries.
- It is possible in UTF-8 (or any other multi-byte encoding) to split or truncate a string in the middle of a character. If the two pieces are not re-appended later before interpretation as characters, this can introduce an invalid sequence at both the end of the previous section and the start of the next, and some decoders will not preserve these bytes and result in data loss. Because UTF-8 is self-synchronizing this will however never introduce a different valid character, and it is also fairly easy to move the truncation point backward to the start of a character.
- If the code points are all the same size, measurements of a fixed number of them is easy. Due to ASCII-era documentation where "character" is used as a synonym for "byte" this is often considered important. However, by measuring string positions using bytes instead of "characters" most algorithms can be easily and efficiently adapted for UTF-8. Searching for a string within a long string can for example be done byte by byte; the self-synchronization property prevents false positives.
Other multi-byte
- UTF-8 can encode any Unicode character. Files in different scripts can be displayed correctly without having to choose the correct code page or font. For instance, Chinese and Arabic can be written in the same file without specialized markup or manual settings that specify an encoding.
- UTF-8 is self-synchronizing: character boundaries are easily identified by scanning for well-defined bit patterns in either direction. If bytes are lost due to error or corruption, one can always locate the next valid character and resume processing. If there is a need to shorten a string to fit a specified field, the previous valid character can easily be found. Many multi-byte encodings such as Shift JIS are much harder to resynchronize. This also means that byte-oriented string-searching algorithms can be used with UTF-8 (as a character is the same as a "word" made up of that many bytes), optimized versions of byte searches can be much faster due to hardware support and lookup tables that have only 256 entries. Self-synchronization does however require that bits be reserved for these markers in every byte, increasing the size.
- Efficient to encode using simple bitwise operations. UTF-8 does not require slower mathematical operations such as multiplication or division (unlike Shift JIS, GB 2312 and other encodings).
- UTF-8 will take more space than a multi-byte encoding designed for a specific script. East Asian legacy encodings generally used two bytes per character yet take three bytes per character in UTF-8.
UTF-16
- Byte encodings and UTF-8 are represented by byte arrays in programs, and often nothing needs to be done to a function when converting source code from a byte encoding to UTF-8. UTF-16 is represented by 16-bit word arrays, and converting to UTF-16 while maintaining compatibility with existing ASCII-based programs (such as was done with Windows) requires every API and data structure that takes a string to be duplicated, one version accepting byte strings and another version accepting UTF-16. If backward compatibility is not needed, all string handling still must be modified.
- Text encoded in UTF-8 will be smaller than the same text encoded in UTF-16 if there are more code points below U+0080 than in the range U+0800..U+FFFF. This is true for all modern European languages. It is often true even for languages like Chinese, due to the large number of spaces, newlines, digits, and HTML markup in typical files.
- Most communication (e.g. HTML and IP) and storage (e.g. for Unix) was designed for a stream of bytes. A UTF-16 string must use a pair of bytes for each code unit:
- The order of those two bytes becomes an issue and must be specified in the UTF-16 protocol, such as with a byte order mark.
- If an odd number of bytes is missing from UTF-16, the whole rest of the string will be meaningless text. Any bytes missing from UTF-8 will still allow the text to be recovered accurately starting with the next character after the missing bytes.
Derivatives
The following implementations show slight differences from the UTF-8 specification. They are incompatible with the UTF-8 specification and may be rejected by conforming UTF-8 applications.
CESU-8
Unicode Technical Report #26[79] assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8. CESU-8 encoding treats each half of a four-byte UTF-16 surrogate pair as a two-byte UCS-2 character, yielding two three-byte UTF-8 characters, which together represent the original supplementary character. Unicode characters within the Basic Multilingual Plane appear as they would normally in UTF-8. The Report was written to acknowledge and formalize the existence of data encoded as CESU-8, despite the Unicode Consortium discouraging its use, and notes that a possible intentional reason for CESU-8 encoding is preservation of UTF-16 binary collation.
CESU-8 encoding can result from converting UTF-16 data with supplementary characters to UTF-8, using conversion methods that assume UCS-2 data, meaning they are unaware of four-byte UTF-16 supplementary characters. It is primarily an issue on operating systems which extensively use UTF-16 internally, such as Microsoft Windows.
In Oracle Database, the UTF8 character set uses CESU-8 encoding, and is deprecated. The AL32UTF8 character set uses standards-compliant UTF-8 encoding, and is preferred.[80][81]
CESU-8 is prohibited for use in HTML5 documents.[82][83][84]
MySQL utf8mb3
In MySQL, the utf8mb3 character set is defined to be UTF-8 encoded data with a maximum of three bytes per character, meaning only Unicode characters in the Basic Multilingual Plane (i.e. from UCS-2) are supported. Unicode characters in supplementary planes are explicitly not supported. utf8mb3 is deprecated in favor of the utf8mb4 character set, which uses standards-compliant UTF-8 encoding. utf8 is an alias for utf8mb3, but is intended to become an alias to utf8mb4 in a future release of MySQL.[14] It is possible, though unsupported, to store CESU-8 encoded data in utf8mb3, by handling UTF-16 data with supplementary characters as though it is UCS-2.
Modified UTF-8
Modified UTF-8 (MUTF-8) originated in the Java programming language. In Modified UTF-8, the null character (U+0000) uses the two-byte overlong encoding 11000000 10000000 (hexadecimal C0 80), instead of 00000000 (hexadecimal 00).[85] Modified UTF-8 strings never contain any actual null bytes but can contain all Unicode code points including U+0000,[86] which allows such strings (with a null byte appended) to be processed by traditional null-terminated string functions. All known Modified UTF-8 implementations also treat the surrogate pairs as in CESU-8.
In normal usage, the language supports standard UTF-8 when reading and writing strings through InputStreamReader and OutputStreamWriter (if it is the platform's default character set or as requested by the program). However it uses Modified UTF-8 for object serialization[87] among other applications of DataInput and DataOutput, for the Java Native Interface,[88] and for embedding constant strings in class files.[89]
The dex format defined by Dalvik also uses the same modified UTF-8 to represent string values.[90] Tcl also uses the same modified UTF-8[91] as Java for internal representation of Unicode data, but uses strict CESU-8 for external data.
WTF-8
In WTF-8 (Wobbly Transformation Format, 8-bit) unpaired surrogate halves (U+D800 through U+DFFF) are allowed.[92] This is necessary to store possibly-invalid UTF-16, such as Windows filenames. Many systems that deal with UTF-8 work this way without considering it a different encoding, as it is simpler.[93]
The term "WTF-8" has also been used humorously to refer to erroneously doubly-encoded UTF-8[94][95] sometimes with the implication that CP1252 bytes are the only ones encoded.[96]
PEP 383
Version 3 of the Python programming language treats each byte of an invalid UTF-8 bytestream as an error (see also changes with new UTF-8 mode in Python 3.7[97]); this gives 128 different possible errors. Extensions have been created to allow any byte sequence that is assumed to be UTF-8 to be losslessly transformed to UTF-16 or UTF-32, by translating the 128 possible error bytes to reserved code points, and transforming those code points back to error bytes to output UTF-8. The most common approach is to translate the codes to U+DC80...U+DCFF which are low (trailing) surrogate values and thus "invalid" UTF-16, as used by Python's PEP 383 (or "surrogateescape") approach.[33] Another encoding called MirBSD OPTU-8/16 converts them to U+EF80...U+EFFF in a Private Use Area.[98] In either approach, the byte value is encoded in the low eight bits of the output code point.
These encodings are very useful because they avoid the need to deal with "invalid" byte strings until much later, if at all, and allow "text" and "data" byte arrays to be the same object. If a program wants to use UTF-16 internally these are required to preserve and use filenames that can use invalid UTF-8;[99] as the Windows filesystem API uses UTF-16, the need to support invalid UTF-8 is less there.[33]
For the encoding to be reversible, the standard UTF-8 encodings of the code points used for erroneous bytes must be considered invalid. This makes the encoding incompatible with WTF-8 or CESU-8 (though only for 128 code points). When re-encoding it is necessary to be careful of sequences of error code points which convert back to valid UTF-8, which may be used by malicious software to get unexpected characters in the output, though this cannot produce ASCII characters so it is considered comparatively safe, since malicious sequences (such as cross-site scripting) usually rely on ASCII characters.[99]
See also
- Alt code
- Comparison of email clients § Features
- Comparison of Unicode encodings
- GB 18030, a Chinese encoding that fully supports Unicode
- UTF-EBCDIC, a rarely used encoding, even for mainframes it was made for
- Iconv
- Percent-encoding § Current standard
- Specials (Unicode block)
- Unicode and email
- Unicode and HTML
Notes
- 17 planes times 216 code points per plane, minus 211 technically-invalid surrogates.
- There are enough x bits to encode up to 0x1FFFFF, but the current RFC 3629 §3 limits UTF-8 encoding to code point U+10FFFF, to match the limits of UTF-16. The obsolete RFC 2279 allowed UTF-8 encoding up to (then legal) code point U+7FFFFFF.
- Some complex emoji characters can take even more than this; the transgender flag emoji (🏳️⚧️), which consists of the five-codepoint sequence U+1F3F3 U+FE0F U+200D U+26A7 U+FE0F, requires sixteen bytes to encode, while that for the flag of Scotland (🏴) requires a total of twenty-eight bytes for the seven-codepoint sequence U+1F3F4 U+E0067 U+E0062 U+E0073 U+E0063 U+E0074 U+E007F.
- For example, cell 9D says +1D. The hexadecimal number 9D in binary is 10011101, and since the 2 highest bits (10) are reserved for marking this as a continuation byte, the remaining 6 bits (011101) have a hexadecimal value of 1D.
- W3Techs.com survey[9] is based on the encoding as declared in the server's response, see https://w3techs.com/forum/topic/22994
- Python uses a number of encodings for what it calls "Unicode", however none of these encodings are UTF-8. Python 2 and early version 3 used UTF-16 on Windows and UTF-32 on Unix. More recent implementations of Python 3 use three fixed-length encodings: ISO-8859-1, UCS-2, and UTF-32, depending on the maximum code point needed.[60]
References
- "Chapter 2. General Structure". The Unicode Standard (6.0 ed.). Mountain View, California, US: The Unicode Consortium. ISBN 978-1-936213-01-6.
- Pike, Rob (30 April 2003). "UTF-8 history".
- Pike, Rob; Thompson, Ken (1993). "Hello World or Καλημέρα κόσμε or こんにちは 世界" (PDF). Proceedings of the Winter 1993 USENIX Conference.
- "File System Safe UCS - Transformation Format (FSS-UTF) - X/Open Preliminary Specification" (PDF). unicode.org.
- "USENIX Winter 1993 Conference Proceedings". usenix.org.
- Alvestrand, Harald T. (January 1998). IETF Policy on Character Sets and Languages. IETF. doi:10.17487/RFC2277. BCP 18. RFC 2277.
- "UTF-8 support in the Microsoft Game Development Kit (GDK) - Microsoft Game Development Kit". learn.microsoft.com. Retrieved 2023-03-05.
By operating in UTF-8, you can ensure maximum compatibility [..] Windows operates natively in UTF-16 (or WCHAR), which requires code page conversions by using MultiByteToWideChar and WideCharToMultiByte. This is a unique burden that Windows places on code that targets multiple platforms. [..] The Microsoft Game Development Kit (GDK) and Windows in general are moving forward to support UTF-8 to remove this unique burden of Windows on code targeting or interchanging with multiple platforms and the web. Also, this results in fewer internationalization issues in apps and games and reduces the test matrix that's required to get it right.
- "Encoding Standard". encoding.spec.whatwg.org. Retrieved 2020-04-15.
- "Usage Survey of Character Encodings broken down by Ranking". W3Techs. Retrieved 2023-10-01.
- "Encoding Standard § 4.2. Names and labels". WHATWG. Retrieved 2018-04-29.
- "Character Sets". Internet Assigned Numbers Authority. 2013-01-23. Retrieved 2013-02-08.
- Liviu (2014-02-07). "UTF-8 codepage 65001 in Windows 7 - part I". Retrieved 2018-01-30.
Previously under XP (and, unverified, but probably Vista, too) for loops simply did not work while codepage 65001 was active
- "MySQL :: MySQL 8.0 Reference Manual :: 10.9.1 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)". MySQL 8.0 Reference Manual. Oracle Corporation. Retrieved 2023-03-14.
- "MySQL :: MySQL 8.0 Reference Manual :: 10.9.2 The utf8mb3 Character Set (3-Byte UTF-8 Unicode Encoding)". MySQL 8.0 Reference Manual. Oracle Corporation. Retrieved 2023-02-24.
- "HP PCL Symbol Sets | Printer Control Language (PCL & PXL) Support Blog". 2015-02-19. Archived from the original on 2015-02-19. Retrieved 2018-01-30.
- "Database Globalization Support Guide". docs.oracle.com. Retrieved 2023-03-16.
- "BOM". suikawiki (in Japanese). Archived from the original on 2009-01-17.
- Davis, Mark. "Forms of Unicode". IBM. Archived from the original on 2005-05-06. Retrieved 2013-09-18.
- "String". Apple Developer. Retrieved 2021-03-15.
- "Chapter 3" (PDF), The Unicode Standard, p. 54
- "Chapter 3" (PDF), The Unicode Standard, p. 55
- "Chapter 3" (PDF), The Unicode Standard, p. 55
- Yergeau, F. (November 2003). UTF-8, a transformation format of ISO 10646. IETF. doi:10.17487/RFC3629. STD 63. RFC 3629. Retrieved August 20, 2020.
- "Chapter 3" (PDF), The Unicode Standard, p. 54
- "Chapter 3" (PDF), The Unicode Standard, p. 55
- Marin, Marvin (2000-10-17). "Malware FAQ: Windows NT UNICODE Vulnerability Analysis | Web Server Folder Traversal MS00-078". SANS Institute. Archived from the original on Aug 27, 2014.
- "CVE-2008-2938". National Vulnerability Database.
- "PEP 529 -- Change Windows filesystem encoding to UTF-8". Python.org. Retrieved 2022-05-10.
This PEP proposes changing the default filesystem encoding on Windows to utf-8, and changing all filesystem functions to use the Unicode APIs for filesystem paths. [..] can correctly round-trip all characters used in paths (on POSIX with surrogateescape handling; on Windows because str maps to the native representation). On Windows bytes cannot round-trip all characters used in paths
- "DataInput (Java Platform SE 8)". docs.oracle.com. Retrieved 2021-03-24.
- "Non-decodable Bytes in System Character Interfaces". python.org. 2009-04-22. Retrieved 2014-08-13.
- "Unicode 6.0.0".
- 128 1-byte, (16+5)×64 2-byte, and 5×64×64 3-byte. There may be somewhat fewer if more precise tests are done for each continuation byte.
- von Löwis, Martin (2009-04-22). "Non-decodable Bytes in System Character Interfaces". Python Software Foundation. PEP 383.
- "Chapter 2" (PDF), The Unicode Standard - Version 15.0.0, p. 39
- "UTF-8 and Unicode FAQ for Unix/Linux".
- Davis, Mark (2012-02-03). "Unicode over 60 percent of the web". Official Google blog. Archived from the original on 2018-08-09. Retrieved 2020-07-24.
- Davis, Mark (2008-05-05). "Moving to Unicode 5.1". Official Google Blog. Retrieved 2023-03-13.
- "Usage statistics and market share of ASCII for websites, October 2021". W3Techs. Retrieved 2020-10-01.
- Bray, Tim (December 2017). Bray, T. (ed.). The JavaScript Object Notation (JSON) Data Interchange Format. IETF. doi:10.17487/RFC8259. RFC 8259. Retrieved 16 February 2018.
- "Usage of Internet mail in the world characters". washingtonindependent.com. 1998-08-01. Retrieved 2007-11-08.
- "Encoding Standard". encoding.spec.whatwg.org. Retrieved 2018-11-15.
- "Specifying the document's character encoding". HTML 5.2 (Report). World Wide Web Consortium. 14 December 2017. Retrieved 2018-06-03.
- "Choose text encoding when you open and save files". support.microsoft.com. Retrieved 2021-11-01.
- "utf 8 - Character encoding of Microsoft Word DOC and DOCX files?". Stack Overflow. Retrieved 2021-11-01.
- "Exporting a UTF-8 .txt file from Word".
- "excel - Are XLSX files UTF-8 encoded by definition?". Stack Overflow. Retrieved 2021-11-01.
- "How to open UTF-8 CSV file in Excel without mis-conversion of characters in Japanese and Chinese language for both Mac and Windows?". answers.microsoft.com. Retrieved 2021-11-01.
- "How can I make Notepad to save text in UTF-8 without the BOM?". Stack Overflow. Retrieved 2021-03-24.
- Galloway, Matt (October 2012). "Character encoding for iOS developers. Or, UTF-8 what now?". www.galloway.me.uk. Retrieved 2021-01-02.
in reality, you usually just assume UTF-8 since that is by far the most common encoding.
- "Windows 10 Notepad is getting better UTF-8 encoding support". BleepingComputer. Retrieved 2021-03-24.
Microsoft is now defaulting to saving new text files as UTF-8 without BOM, as shown below.
- "Customize the Windows 11 Start menu". docs.microsoft.com. Retrieved 2021-06-29.
Make sure your LayoutModification.json uses UTF-8 encoding.
- "JEP 400: UTF-8 by default". openjdk.java.net. Retrieved 2022-03-30.
- "Feature #16604: Set default for Encoding.default_external to UTF-8 on Windows". bugs.ruby-lang.org. Ruby master – Ruby Issue Tracking System. Retrieved 2022-08-01.
- "Feature #12650: Use UTF-8 encoding for ENV on Windows". bugs.ruby-lang.org. Ruby master – Ruby Issue Tracking System. Retrieved 2022-08-01.
- "New features in R 4.2.0". The Jumping Rivers Blog. R bloggers. 2022-04-01. Retrieved 2022-08-01.
- "PEP 540 – add a new UTF-8 mode". peps.python.org. Retrieved 2022-09-23.
- "PEP 686 – Make UTF-8 mode default | peps.python.org". peps.python.org. Retrieved 2023-07-26.
- "PEP 597 – add optional EncodingWarning". Python.org. Retrieved 2021-08-24.
- "Support for UTF-8 as a portable source file encoding" (PDF).
- "PEP 393 – Flexible String Representation". Python.org. Retrieved 2022-05-18.
As interaction with other libraries will often require some sort of internal representation, the specification chooses UTF-8 as the recommended way of exposing strings to C code. [..] The data and utf8 pointers point to the same memory if the string uses only ASCII characters (using only Latin-1 is not sufficient). [..] The recommended way to create a Unicode object is to use the function PyUnicode_New [..] A new function PyUnicode_AsUTF8 is provided to access the UTF-8 representation.
- "Source code representation". The Go Programming Language Specification. golang.org (Report). Retrieved 2021-02-10.
- Tsai, Michael J. (21 March 2019). "UTF-8 string in Swift 5" (blog). Retrieved 2021-03-15.
Switching to UTF-8 fulfills one of string's long-term goals, to enable high-performance processing, [...] also lays the groundwork for providing even more performant APIs in the future.
- "PyPy v7.1 released; now uses UTF-8 internally for Unicode strings". Mattip. PyPy status blog. 2019-03-24. Retrieved 2020-11-21.
- "Unicode Objects and Codecs". Python documentation. Retrieved 2023-08-19.
UTF-8 representation is created on demand and cached in the Unicode object.
- "PEP 623 – remove wstr from Unicode". Python.org. Retrieved 2020-11-21.
Until we drop [the] legacy Unicode object, it is very hard to try other Unicode implementation[s], like UTF-8 based implementation in PyPy.
- Wouters, Thomas (2023-07-11). "Python Insider: Python 3.12.0 beta 4 released". Python Insider. Retrieved 2023-07-26.
The deprecated wstr and wstr_length members of the C implementation of unicode objects were removed, per PEP 623.
- "/validate-charset (validate for compatible characters)". docs.microsoft.com. Retrieved 2021-07-19.
Visual Studio uses UTF-8 as the internal character encoding during conversion between the source character set and the execution character set.
- "Introducing UTF-8 support for SQL Server". techcommunity.microsoft.com. 2019-07-02. Retrieved 2021-08-24.
For example, changing an existing column data type from NCHAR(10) to CHAR(10) using an UTF-8 enabled collation, translates into nearly 50% reduction in storage requirements. [..] In the ASCII range, when doing intensive read/write I/O on UTF-8, we measured an average 35% performance improvement over UTF-16 using clustered tables with a non-clustered index on the string column, and an average 11% performance improvement over UTF-16 using a heap.
- "Use the Windows UTF-8 code page – UWP applications". docs.microsoft.com. Retrieved 2020-06-06.
As of Windows version 1903 (May 2019 update), you can use the ActiveCodePage property in the appxmanifest for packaged apps, or the fusion manifest for unpackaged apps, to force a process to use UTF-8 as the process code page. [...]
CP_ACPequates toCP_UTF8only if running on Windows version 1903 (May 2019 update) or above and the ActiveCodePage property described above is set to UTF-8. Otherwise, it honors the legacy system code page. We recommend usingCP_UTF8explicitly. - "Appendix F. FSS-UTF / File System Safe UCS Transformation format" (PDF). The Unicode Standard 1.1. Archived (PDF) from the original on 2016-06-07. Retrieved 2016-06-07.
- Whistler, Kenneth (2001-06-12). "FSS-UTF, UTF-2, UTF-8, and UTF-16". Archived from the original on 2016-06-07. Retrieved 2006-06-07.
- Pike, Rob (2003-04-30). "UTF-8 history". Retrieved 2012-09-07.
- Pike, Rob (2012-09-06). "UTF-8 turned 20 years old yesterday". Retrieved 2012-09-07.
- ISO/IEC 10646:2014 §9.1, 2014.
- The Unicode Standard, Version 15.0 §3.9 D92, §3.10 D95, 2021.
- Unicode Standard Annex #27: Unicode 3.1, 2001.
- The Unicode Standard, Version 5.0 §3.9–§3.10 ch. 3, 2006.
- The Unicode Standard, Version 6.0 §3.9 D92, §3.10 D95, 2010.
- McGowan, Rick (2011-12-19). "Compatibility Encoding Scheme for UTF-16: 8-Bit (CESU-8)". Unicode Consortium. Unicode Technical Report #26.
- "Character Set Support". Oracle Database 19c Documentation, SQL Language Reference. Oracle Corporation.
- "Supporting Multilingual Databases with Unicode § Support for the Unicode Standard in Oracle Database". Database Globalization Support Guide. Oracle Corporation.
- "8.2.2.3. Character encodings". HTML 5.1 Standard. W3C.
- "8.2.2.3. Character encodings". HTML 5 Standard. W3C.
- "12.2.3.3 Character encodings". HTML Living Standard. WHATWG.
- "Java SE documentation for Interface java.io.DataInput, subsection on Modified UTF-8". Oracle Corporation. 2015. Retrieved 2015-10-16.
- "The Java Virtual Machine Specification, section 4.4.7: "The CONSTANT_Utf8_info Structure"". Oracle Corporation. 2015. Retrieved 2015-10-16.
- "Java Object Serialization Specification, chapter 6: Object Serialization Stream Protocol, section 2: Stream Elements". Oracle Corporation. 2010. Retrieved 2015-10-16.
- "Java Native Interface Specification, chapter 3: JNI Types and Data Structures, section: Modified UTF-8 Strings". Oracle Corporation. 2015. Retrieved 2015-10-16.
- "The Java Virtual Machine Specification, section 4.4.7: "The CONSTANT_Utf8_info Structure"". Oracle Corporation. 2015. Retrieved 2015-10-16.
- "ART and Dalvik". Android Open Source Project. Archived from the original on 2013-04-26. Retrieved 2013-04-09.
- "UTF-8 bit by bit". Tcler's Wiki. 2001-02-28. Retrieved 2022-09-03.
- Sapin, Simon (2016-03-11) [2014-09-25]. "The WTF-8 encoding". Archived from the original on 2016-05-24. Retrieved 2016-05-24.
- Sapin, Simon (2015-03-25) [2014-09-25]. "The WTF-8 encoding § Motivation". Archived from the original on 2020-08-16. Retrieved 2020-08-26.
- "WTF-8.com". 2006-05-18. Retrieved 2016-06-21.
- Speer, Robyn (2015-05-21). "ftfy (fixes text for you) 4.0: changing less and fixing more". Archived from the original on 2015-05-30. Retrieved 2016-06-21.
- "WTF-8, a transformation format of code page 1252". Archived from the original on 2016-10-13. Retrieved 2016-10-12.
- "PEP 540 -- Add a new UTF-8 Mode". Python.org. Retrieved 2021-03-24.
- "RTFM optu8to16(3), optu8to16vis(3)". www.mirbsd.org.
- Davis, Mark; Suignard, Michel (2014). "3.7 Enabling Lossless Conversion". Unicode Security Considerations. Unicode Technical Report #36.
External links
- Original UTF-8 paper (or pdf) for Plan 9 from Bell Labs
- History of UTF-8 by Rob Pike
- UTF-8 test pages:
- Andreas Prilop Archived 2017-11-30 at the Wayback Machine
- Jost Gippert
- World Wide Web Consortium
- Unix/Linux: UTF-8/Unicode FAQ, Linux Unicode HOWTO, UTF-8 and Gentoo
- Characters, Symbols and the Unicode Miracle on YouTube
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |