DNA polymerase I
DNA polymerase I (or Pol I) is an enzyme that participates in the process of prokaryotic DNA replication. Discovered by Arthur Kornberg in 1956,[1] it was the first known DNA polymerase (and the first known of any kind of polymerase). It was initially characterized in E. coli and is ubiquitous in prokaryotes. In E. coli and many other bacteria, the gene that encodes Pol I is known as polA. The E. coli Pol I enzyme is composed of 928 amino acids, and is an example of a processive enzyme — it can sequentially catalyze multiple polymerisation steps without releasing the single-stranded template.[2] The physiological function of Pol I is mainly to support repair of damaged DNA, but it also contributes to connecting Okazaki fragments by deleting RNA primers and replacing the ribonucleotides with DNA.
| DNA polymerase I | |||||||
|---|---|---|---|---|---|---|---|
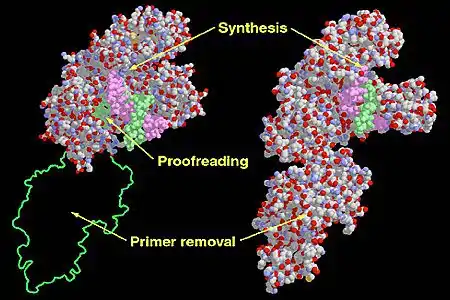 Functional domains in the Klenow Fragment (left) and DNA Polymerase I (right). | |||||||
| Identifiers | |||||||
| Organism | |||||||
| Symbol | polA | ||||||
| Entrez | 948356 | ||||||
| PDB | 1DPI | ||||||
| RefSeq (Prot) | NP_418300.1 | ||||||
| UniProt | P00582 | ||||||
| Other data | |||||||
| EC number | 2.7.7.7 | ||||||
| Chromosome | genome: 4.04 - 4.05 Mb | ||||||
| |||||||
Discovery
In 1956, Arthur Kornberg and colleagues discovered Pol I by using Escherichia coli (E. coli) extracts to develop a DNA synthesis assay. The scientists added 14C-labeled thymidine so that a radioactive polymer of DNA, not RNA, could be retrieved. To initiate the purification of DNA polymerase, the researchers added streptomycin sulfate to the E. coli extract. This separated the extract into a nucleic acid-free supernatant (S-fraction) and nucleic acid-containing precipitate (P-fraction). The P-fraction also contained Pol I and heat-stable factors essential for the DNA synthesis reactions. These factors were identified as nucleoside triphosphates, the building blocks of nucleic acids. The S-fraction contained multiple deoxynucleoside kinases.[3] In 1959, the Nobel Prize in Physiology or Medicine was awarded to Arthur Kornberg and Severo Ochoa "for their discovery of the mechanisms involved in the biological synthesis of Ribonucleic acid and Deoxyribonucleic Acid."[4]

Structure and function
General structure
Pol I mainly functions in the repair of damaged DNA. Structurally, Pol I is a member of the alpha/beta protein superfamily, which encompasses proteins in which α-helices and β-strands occur in irregular sequences. E. coli DNA Pol I consists of multiple domains with three distinct enzymatic activities. Three domains, often referred to as thumb, finger and palm domain work together to sustain DNA polymerase activity.[5] A fourth domain next to the palm domain contains an exonuclease active site that removes incorrectly incorporated nucleotides in a 3' to 5' direction in a process known as proofreading. A fifth domain contains another exonuclease active site that removes DNA or RNA in a 5' to 3' direction and is essential for RNA primer removal during DNA replication or DNA during DNA repair processes.
E. coli bacteria produces 5 different DNA polymerases: DNA Pol I, DNA Pol II, DNA Pol III, DNA Pol IV, and DNA Pol V. Eukaryotic cells contain 5 different DNA polymerases: α, β, γ, δ, and ε.[6] Eukaryotic DNA polymerase β is most similar to E. coli DNA Pol I because its main function is associated with DNA repair, rather than replication. DNA polymerase β is mainly used in base-excision repair and nucleotide-excision repair.[7] A total of 15 human DNA polymerases have been identified.[8]
Structural and functional similarity to other polymerases
In DNA replication, the leading DNA strand is continuously extended in the direction of replication fork movement, whereas the DNA lagging strand runs discontinuously in the opposite direction as Okazaki fragments.[9] DNA polymerases also cannot initiate DNA chains so they must be initiated by short RNA or DNA segments known as primers.[5] In order for DNA polymerization to take place, two requirements must be met. First of all, all DNA polymerases must have both a template strand and a primer strand. Unlike RNA, DNA polymerases cannot synthesize DNA from a template strand. Synthesis must be initiated by a short RNA segment, known as RNA primer, synthesized by Primase in the 5' to 3' direction. DNA synthesis then occurs by the addition of a dNTP to the 3' hydroxyl group at the end of the preexisting DNA strand or RNA primer. Secondly, DNA polymerases can only add new nucleotides to the preexisting strand through hydrogen bonding.[6] Since all DNA polymerases have a similar structure, they all share a two-metal ion-catalyzed polymerase mechanism. One of the metal ions activates the primer 3' hydroxyl group, which then attacks the primary 5' phosphate of the dNTP. The second metal ion will stabilize the leaving oxygen's negative charge, and subsequently chelates the two exiting phosphate groups.[10]
The X-ray crystal structures of polymerase domains of DNA polymerases are described in analogy to human right hands. All DNA polymerases contain three domains. The first domain, which is known as the "fingers domain", interacts with the dNTP and the paired template base. The "fingers domain" also interacts with the template to position it correctly at the active site.[11] Known as the "palm domain", the second domain catalyses the reaction of the transfer of the phosphoryl group. Lastly, the third domain, which is known as the "thumb domain", interacts with double stranded DNA.[12] The exonuclease domain contains its own catalytic site and removes mispaired bases. Among the seven different DNA polymerase families, the "palm domain" is conserved in five of these families. The "finger domain" and "thumb domain" are not consistent in each family due to varying secondary structure elements from different sequences.[11]
Function
Pol I possesses four enzymatic activities:
- A 5'→3' (forward) DNA-dependent DNA polymerase activity, requiring a 3' primer site and a template strand
- A 3'→5' (reverse) exonuclease activity that mediates proofreading
- A 5'→3' (forward) exonuclease activity mediating nick translation during DNA repair.
- A 5'→3' (forward) RNA-dependent DNA polymerase activity. Pol I operates on RNA templates with considerably lower efficiency (0.1–0.4%) than it does DNA templates, and this activity is probably of only limited biological significance.[13]
In order to determine whether Pol I was primarily used for DNA replication or in the repair of DNA damage, an experiment was conducted with a deficient Pol I mutant strain of E. coli. The mutant strain that lacked Pol I was isolated and treated with a mutagen. The mutant strain developed bacterial colonies that continued to grow normally and that also lacked Pol I. This confirmed that Pol I was not required for DNA replication. However, the mutant strain also displayed characteristics which involved extreme sensitivity to certain factors that damaged DNA, like UV light. Thus, this reaffirmed that Pol I was more likely to be involved in repairing DNA damage rather than DNA replication.[6]
Mechanism
In the replication process, RNase H removes the RNA primer (created by primase) from the lagging strand and then polymerase I fills in the necessary nucleotides between the Okazaki fragments (see DNA replication) in a 5'→3' direction, proofreading for mistakes as it goes. It is a template-dependent enzyme—it only adds nucleotides that correctly base pair with an existing DNA strand acting as a template. It is crucial that these nucleotides are in the proper orientation and geometry to base pair with the DNA template strand so that DNA ligase can join the various fragments together into a continuous strand of DNA. Studies of polymerase I have confirmed that different dNTPs can bind to the same active site on polymerase I. Polymerase I is able to actively discriminate between the different dNTPs only after it undergoes a conformational change. Once this change has occurred, Pol I checks for proper geometry and proper alignment of the base pair, formed between bound dNTP and a matching base on the template strand. The correct geometry of A=T and G≡C base pairs are the only ones that can fit in the active site. However, it is important to know that one in every 104 to 105 nucleotides is added incorrectly. Nevertheless, Pol I can fix this error in DNA replication using its selective method of active discrimination.[5]
Despite its early characterization, it quickly became apparent that polymerase I was not the enzyme responsible for most DNA synthesis—DNA replication in E. coli proceeds at approximately 1,000 nucleotides/second, while the rate of base pair synthesis by polymerase I averages only between 10 and 20 nucleotides/second. Moreover, its cellular abundance of approximately 400 molecules per cell did not correlate with the fact that there are typically only two replication forks in E. coli. Additionally, it is insufficiently processive to copy an entire genome, as it falls off after incorporating only 25–50 nucleotides. Its role in replication was proven when, in 1969, John Cairns isolated a viable polymerase I mutant that lacked the polymerase activity.[14] Cairns' lab assistant, Paula De Lucia, created thousands of cell free extracts from E. coli colonies and assayed them for DNA-polymerase activity. The 3,478th clone contained the polA mutant, which was named by Cairns to credit "Paula" [De Lucia].[15] It was not until the discovery of DNA polymerase III that the main replicative DNA polymerase was finally identified.
Research applications
DNA polymerase I obtained from E. coli is used extensively for molecular biology research. However, the 5'→3' exonuclease activity makes it unsuitable for many applications. This undesirable enzymatic activity can be simply removed from the holoenzyme to leave a useful molecule called the Klenow fragment, widely used in molecular biology. In fact, the Klenow fragment was used during the first protocols of polymerase chain reaction (PCR) amplification until Thermus aquaticus, the source of a heat-tolerant Taq Polymerase I, was discovered in 1976.[17] Exposure of DNA polymerase I to the protease subtilisin cleaves the molecule into a smaller fragment, which retains only the DNA polymerase and proofreading activities.
References
- Lehman IR, Bessman MJ, Simms ES, Kornberg A (July 1958). "Enzymatic synthesis of deoxyribonucleic acid. I. Preparation of substrates and partial purification of an enzyme from Escherichia coli". The Journal of Biological Chemistry. 233 (1): 163–70. doi:10.1016/S0021-9258(19)68048-8. PMID 13563462.
- Voet D, Voet JG, Pratt CW (1999). Fundamentals of Biochemistry. New York: Wiley.
- Lehman IR (September 2003). "Discovery of DNA polymerase". The Journal of Biological Chemistry. 278 (37): 34733–8. doi:10.1074/jbc.X300002200. PMID 12791679.
- "The Nobel Prize in Physiology or Medicine 1959". www.nobelprize.org. Retrieved 2016-11-08.
- Cox MM, Doudna J (2015). Molecular Biology (2nd ed.). New York: W.H. Freeman.
- Cooper, Geoffrey M. Geoffrey (2000-01-01). "DNA Replication".
{{cite journal}}: Cite journal requires|journal=(help) - Wood RD, Shivji MK (April 1997). "Which DNA polymerases are used for DNA-repair in eukaryotes?". Carcinogenesis. 18 (4): 605–10. doi:10.1093/carcin/18.4.605. PMID 9111189.
- Biertümpfel C, Zhao Y, Kondo Y, Ramón-Maiques S, Gregory M, Lee JY, Masutani C, Lehmann AR, Hanaoka F, Yang W (June 2010). "Structure and mechanism of human DNA polymerase eta". Nature. 465 (7301): 1044–8. Bibcode:2010Natur.465.1044B. doi:10.1038/nature09196. PMC 2899710. PMID 20577208.
- Hübscher U, Spadari S, Villani G, Maga G (2010). DNA Polymerases. doi:10.1142/7667. ISBN 978-981-4299-16-9.
- "DNA Polymerase I: Enzymatic Reactions".
- "MBIO.4.14.5". bioscience.jbpub.com. Retrieved 2017-05-14.
- Loeb LA, Monnat RJ (August 2008). "DNA polymerases and human disease". Nature Reviews Genetics. 9 (8): 594–604. doi:10.1038/nrg2345. PMID 18626473. S2CID 3344014.
- Ricchetti M, Buc H (February 1993). "E. coli DNA polymerase I as a reverse transcriptase". The EMBO Journal. 12 (2): 387–96. doi:10.1002/j.1460-2075.1993.tb05670.x. PMC 413221. PMID 7679988.
- De Lucia P, Cairns J (December 1969). "Isolation of an E. coli strain with a mutation affecting DNA polymerase". Nature. 224 (5225): 1164–6. Bibcode:1969Natur.224.1164D. doi:10.1038/2241164a0. PMID 4902142. S2CID 4182917.
- Friedberg EC (February 2006). "The eureka enzyme: the discovery of DNA polymerase". Nature Reviews Molecular Cell Biology. 7 (2): 143–7. doi:10.1038/nrm1787. PMID 16493419. S2CID 39605644.
- EMBL-EBI. "EMBL European Bioinformatics Institute". www.ebi.ac.uk. Retrieved 2016-11-08.
- van Pelt-Verkuil E, van Belkum A, Hays JP (2008). "Taq and Other Thermostable DNA Polymerases". Principles and Technical Aspects of PCR Amplification. pp. 103–18. doi:10.1007/978-1-4020-6241-4_7. ISBN 978-1-4020-6240-7.