ARN mensajero
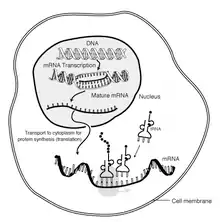
El ARN mensajero o ARNm es el ácido ribonucleico que transfiere el código genético procedente del ADN del núcleo celular a un ribosoma en el citoplasma, es decir, el que determina el orden en que se unirán los aminoácidos de una proteína y actúa como plantilla o patrón para la síntesis de dicha proteína.[1] Se trata de un ácido nucleico monocatenario, al contrario del bicatenario ADN.
A pesar de que la mayoría de los ARNm eucarióticos son monocistrónicos, es decir, contienen información para una sola cadena polipeptídica, algunos estudios han demostrado que ciertos genes eucarióticos organizados en grupos se transcriben como policistrónicos, al igual que en los organismos procariotas. Los ARNm policistrónicos codifican más de una proteína.[2]
Procesamiento del ARN mensajero
El ARN mensajero obtenido después de la transcripción se conoce como ARN transcrito primario o ARN precursor o pre-ARN, que en la mayoría de los casos no se libera del complejo de transcripción en forma totalmente activa, sino que ha de sufrir modificaciones antes de ejercer su función (procesamiento o maduración del ARN). Entre esas modificaciones se encuentran la eliminación de fragmentos (splicing), la adición de otros no codificados en el ADN y la modificación covalente de ciertas bases nitrogenadas.[3]
Procesamiento en células eucariotas
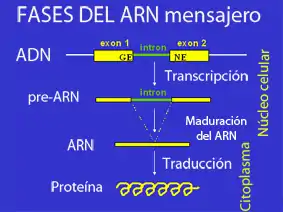
Concretamente, el procesamiento del ARN en eucariotas comprende diferentes fases:
Protección por la CAP
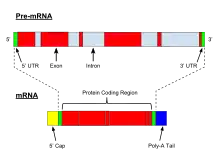
El proceso se inicia con la adición al extremo 5' de la estructura denominada «caperuza» o «casquete», que es un nucleótido modificado de guanina, la 7-metilguanosina trifosfato, que se añade al extremo 5' de la cadena del ARNm transcrito primario (ubicado aún en el núcleo celular) mediante un enlace trifosfato 5'-5', en lugar del enlace 3',5'-fosfodiéster habitual.[2] Esta caperuza es necesaria para el proceso normal de traducción del ARN y para mantener su estabilidad. Esto es fundamental para el reconocimiento y el acceso apropiado del ribosoma.[4]
Señal de poliadenilación
Luego se da el proceso de poliadenilación, que consiste en la adición al extremo 3' de una cola poli-A, una secuencia larga de poliadenilato, es decir, un tramo de ARN cuyas bases son todas adenina. Su adición está mediada por una secuencia o señal de poliadenilación (AAAAAA), situada unos 11-30 nucleótidos antes del extremo 3' original (Figura 2). Esta cola protege al ARNm de la degradación, y aumenta su vida media en el citosol, de modo que se puede sintetizar mayor cantidad de proteína.[3]
Señal de empalme
En la mayoría de los casos, el ARN mensajero sufre la eliminación de secuencias internas, no codificantes, llamadas intrones. Esto no ocurre en células procariontes, ya que estas no poseen intrones en su ADN. El proceso de retirada de los intrones y conexión o empalme de los exones se llama ayuste o corte y empalme (en inglés, splicing). A veces un mismo transcrito primario o pre-ARNm se puede ajustar de diversas maneras, y permite que con un solo gen se obtengan varias proteínas diferentes; a este fenómeno se le llama ayuste alternativo. Ciertas enzimas parecen estar involucradas en la edición del ARN antes de su exportación fuera del núcleo, intercambiando o eliminando nucleótidos erróneos. Por esta razón, es posible decir que el plegamiento que sufre el ARNm momentos antes de la eliminación de los intrones le confiere una estructura secundaria que perderá, a su vez, en el momento en el que esos intrones sean eliminados.[5]
Proceso final
El ARN mensajero maduro es trasladado al citosol de la célula, en el caso de los organismos eucariontes, a través de poros de la envoltura nuclear. Una vez en el citoplasma, se acoplan al ARNm los ribosomas, que son la maquinaria encargada de la síntesis proteica. En procariontes, la unión de los ribosomas ocurre mientras la cadena de ARNm está siendo sintetizada. Después de cierta cantidad de tiempo, el ARNm se degrada en sus nucleótidos componentes, generalmente con la ayuda de ribonucleasas.[5]
Procesamiento en células procariotas
El proceso de transcripción y el de traducción se realizan de manera similar que en las células eucariotas. La diferencia fundamental está en que, en las procariotas, el ARN mensajero no pasa por un proceso de maduración y, por lo tanto, no se le añade caperuza ni cola ni se le quitan intrones. Además, no tiene que salir del núcleo como en las eucariotas, porque en las células procariotas no hay un núcleo definido.[2]
ARN mensajeros monocistrónicos y policistrónicos
- ARNm monocistrónico: solo tiene un codón de inicio AUG, que es reconocido por los ribosomas para iniciar la traducción, por lo que solo da lugar a una proteína. Se dice que lleva la información de un único gen. Es habitual en eucariotas.[1]
- ARNm policistrónico: tiene varios codones de inicio AUG (por lo que también harán falta varios codones de paro para detenerlos, a menos que tengan solapado el código de lectura y vayan de 3 en 3, en cuyo caso un solo codón de paro podría detenerlos todos), por lo que da lugar a varias proteínas. Se dice que lleva información de varios genes. Es habitual en procariotas.[1]
El ARNm de secuencia se descodifica en conjuntos de tres nucleótidos
Una vez que se ha producido un ARNm, por transcripción y el procesamiento de la información presente en sus nucleótidos de secuencia se usa para sintetizar una proteína. La transcripción es sencilla de entender como un medio de transferencia de información: desde ADN y ARN son química y estructuralmente similares, el ADN actúa como una plantilla directa para la síntesis de ARN por complementariedad de bases. Con el término de transcripción se significa que consiste en como si un mensaje escrito a mano se convierte, por ejemplo, en un texto escrito a máquina. El lenguaje en sí mismo y la forma del mensaje no cambian, y los símbolos que se utilizan están estrechamente relacionados.[5]
Transporte de ARN mensajero en lugar de proteínas
El transporte del ARNm en lugar de proteínas presenta varias ventajas significativas para una célula:[4]
- Los costos de transporte se reducen, ya que varias moléculas de proteínas pueden ser traducidas a partir de una sola de ARNm.
- El transporte del ARNm puede impedir que las proteínas actúen ectópicamente antes de que lleguen al sitio apropiado, lo que es importante en el caso de los determinantes maternos, ya que una expresión inapropiada alteraría el patrón embrionario.
- La traducción localizada puede facilitar la incorporación de proteínas en complejos macromoleculares mediante la generación de altas concentraciones de proteínas locales y la co-traducción de diferentes subunidades.
- La proteínas nacientes pueden tener propiedades distintas de las proteínas preexistentes, en virtud de modificaciones postraduccionales o mediante vías de plegado ayudado por las proteínas chaperonas.
- Se puede afinar la expresión génica en el espacio y el tiempo.
Como ejemplo se encuentran la orientación de diferentes empalmes a distintos comportamientos celulares y la activación de la traducción localizada del ARNm específicamente en su destino, en respuesta a señales tales como señales de guía, liberación de neurotransmisores o fertilización.[6]
Correlación entre la cantidad de ARN mensajero y proteína
Mediante experimentaciones se ha determinado la relación entre el ARNm y los niveles de expresión de proteínas de genes seleccionados que se expresan en la levadura Saccharomyces cerevisiae[7]. Para este proceso se realizó un lisiado total de las levaduras y mediante electroforesis bidimensional de alta resolución se separó el contenido proteico. Gracias a estas investigaciones se ha podido identificar que la correlación entre el ARNm y los niveles de proteínas son insuficientes para predecir cuantitativamente los niveles de expresión de ARNm para generar la proteína. una observación interesante.[7] Datos interesantes obtenidos es que un sesgo de los codones no son predictores para determinar los niveles de proteína o de ARNm.
Regulación de la estabilidad del ARN mensajero en células de mamíferos
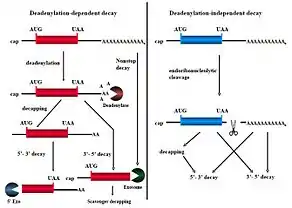
Normalmente, la célula coordina la degradación o estabilización de varios subconjuntos funcionales de los ARNm que codifican las proteínas necesarias para el metabolismo biológico de los mamíferos. También se pueden dar estímulos, tanto intrínsecos como extrínsecos, los cuales activan vías de transducción de señales que modifican los distintos mecanismos de descomposición del ARNm (Figura 3).
Las tasas de degradación del ARN mensajero cambian a menudo como respuesta a un estímulo, con lo que rápidamente aumenta o disminuye la cantidad de ARNm para satisfacer las necesidades de una célula en función de las proteínas individuales que se codifican. Existen muchas proteínas implicadas en la degradación del ARN mensajero las cuales se concentran en lugares estratégicos del citoplasma y se denominan cuerpos de procesamiento (P-bodies) las transcripciones enteras de P-bodies pueden salir del citoplasma y volver a los polirribosomas para la traducción.[8]
Existen numerosas vías de señalización que regulan la degradación del ARN mensajero. Una de las principales es la AUF1 la cual es una vía que se encuentra sujeta a la fosforilación de tirosina por acción de la enzima NPM-ALK quinasa (cinasa del linfoma anaplásico, una proteína expresada en un subconjunto de linfosomas). La hiperfosforilación de AUF1 contribuye a una mayor estabilidad de los ARNm que codifican numerosas ciclinas as como la oncoproteína MYC.[8]
Se ha visto que ARNs no codificantes se ven inmersos en procesos de la degradación del ARN mensajero. Un ejemplo claro son micro ARN y ARN de interferencia los cuales forman aproximadamente el 3 % de todos los genes humanos y que se encargan de regular la expresión génica mediante el control de la traducción y degradación del ARNm.
Patologías
Enfermedades por splicings crípticos y ARNm
Considerando la importancia fundamental del proceso de splicing para la expresión génica en organismos complejos y la prevalencia y función biológica de la regulación del splicing alternativo, no es de extrañar que alteraciones en estos procesos sean causa de enfermedades genéticas. Se ha estimado que alrededor del 15 % de las enfermedades hereditarias tienen su origen en la alteración de las secuencias necesarias para distinguir las fronteras entre los exones e intrones.[9] Estas secuencias se denominan sitios de splicing 5’ (las que definen el final de un exón y el principio del siguiente intrón) y sitios de splicing 3’ (las que definen el final de un intrón y el principio del siguiente exón). Por ejemplo, la mutación de sitios de splicing o la activación de sitios de splicing crípticos en intrones del gen de la beta globina es una causa frecuente de una las primeras enfermedades genéticas identificadas, la beta-talasemia. La activación de sitios crípticos resulta en ARN mensajeros con alteraciones en la pauta de lectura que dan lugar a proteínas truncadas no funcionales.[10]
Otro ejemplo de la activación de sitios de splicing crípticos con consecuencias patológicas se encuentra en la mutación más frecuente encontrada en pacientes con el síndrome de envejecimiento prematuro conocido como progeria de Hutchinson-Gilford. En este caso, la activación de un sitio de splicing 5’ dentro de uno de los exones del gen de la lámina A produce un ARN mensajero cuya traducción produce una proteína con una delección interna de 50 aminoácidos que tiene efectos drásticos sobre la estructura del núcleo celular y la estabilidad cromosómica.[10]
Aplicaciones
Microarrays para medir transcritos de ARN mensajero
El descubrimiento en la última década de la tecnología del "microarray" ha supuesto una revolución en los ensayos llevados a cabo en ARN y ADN. En contraposición con los estudios biológicos tradicionales, los “microarrays” permiten medir los niveles de expresión de miles de transcritos de ARN mensajero (ARNm) para conocer el patrón global de expresión génica en una determinada célula, tejido u órgano. Desde su aparición a final del siglo XX, los análisis de “microarrays” de ARN han constituido una herramienta esencial tanto en estudios biológicos como biomédicos por su gran aplicación en diversos campos, siendo imprescindibles en estudios de enfermedades, en ensayos con animales modelo como Drosophila melanogaster y Caenorhabditis elegans e incluso en plantas. Existen aplicaciones de los “microarrays” de expresión de ARN en varias áreas de estudio biológico y demuestra que se está convirtiendo en una metodología de vanguardia en la biotecnología y biomedicina.[11]
Microarrays de doble canal
Se refieren a menudo como “microarrays” de doble canal o “microarrays” de dos colores, porque dos muestras, cada una marcada con un fluorocromo diferente, son hibridadas en una sola de estas micromatrices. Como resultado de la combinación de dos muestras en un solo dispositivo, los niveles de expresión relativos pueden ser determinados usando este tipo de “microarrays”.[12] Las sondas en estos “microarrays” son oligonucleótidos, ADN complementario (ADNc) o fragmentos de productos de PCR;[13] confiriendo cada tipo propiedades diferentes a la matriz. A pesar de estas diferencias, todos los “microarrays” de oligonucleótidos son similares en términos de construcción del array, preparación de las sondas y análisis de datos.[14]
Aunque actualmente una multitud de “microarrays” están disponibles comercialmente, cada uno diseñado para una especie específica o familia general de organismos. Estas matrices están limitadas por la información disponible en bases de datos genómicas.[15] Sin embargo, solo los genomas de unas pocas especies han sido completamente secuenciados y están disponibles públicamente. Por ejemplo, revisando el sitio web de Affymetrix, una de las principales casas comerciales de “microarrays”, los genomas disponibles para sus “microarrays” son: Bacillus subtilis, Escherichia coli, Pseudomonas aeruginosa, miembros del género Plasmodium, Staphylococcus aureus y miembros del género Saccharomyces.[16] Se pueden diseñar “microarrays”, sin embargo, para muchas especies más siempre que sus secuencias genómicas estén disponibles para ese organismo particular o esa familia de organismos.
Referencias
- Mattei, J.-F. (2001/2002). El genoma humano (Ethical eye: the human genome). Sáez García, M. A.; Chao Crecente, M.; Vázquez, D. A., y Rodríguez-Roda Stuart, J., trad. Colección La Mirada de la Ciencia. Madrid: Council of Europe/Editorial Complutense. Glosario (p. 201). ISBN 84-7491-665-8
- Devlin, T. M. (2004). Bioquímica, 4ª ed. Barcelona: Reverté. ISBN 84-291-7208-4
- «SÍNTESIS DE PROTEÍNAS O TRADUCCIÓN». Desde Mendel hasta las moléculas. 22 de noviembre de 2010. Archivado desde el original el 27 de enero de 2017. Consultado el 25 de enero de 2017.
- Herveg Jean-Pierre (abril del 2006). «La transcripción en los mamíferos». Genemol. Archivado desde el original el 3 de febrero de 2017. Consultado el 24 de enero de 2017.
- «ARNm - Medicina molecular». medmol.es. Archivado desde el original el 2 de febrero de 2017. Consultado el 25 de enero de 2017.
- Medioni, Caroline (2012). «Principles and roles of mRNA localization in animal development». The Company of Biologists Ltd. doi:10.1242/dev.078626. Consultado el 4 de diciembre de 2016.
- STEVEN P. GYGI, YVAN ROCHON, B. ROBERT FRANZA, AND RUEDI AEBERSOLD. «Correlation between Protein and mRNA Abundance in Yeast». MOLECULAR AND CELLULAR BIOLOG.
- Wu, Brewer (2012). «The Regulation of mRNA Stability in Mammalian Cells: 2.0». NCBI.
- Faustino, Nuno André; Cooper, Thomas A. (15 de febrero de 2003). «Pre-mRNA splicing and human disease». Genes & Development (en inglés) 17 (4): 419-437. ISSN 0890-9369. PMID 12600935. doi:10.1101/gad.1048803. Consultado el 5 de diciembre de 2016.
- «Splicing alternativos y enfermedad». Consultado el 5 de diciembre de 2016.
- Juan, Peragón-Sánchez,; Experimental, Universidad de Jaén. Biología (11 de julio de 2014). “Microarrays” de ARN. Consultado el 25 de enero de 2017.
- Brown, Patrick O.; Botstein, David (1 de enero de 1999). «Exploring the new world of the genome with DNA microarrays». Nature Genetics (en inglés) 21 (1s): 33-37. ISSN 1546-1718. doi:10.1038/4462. Consultado el 2 de abril de 2018.
- Xiang, Zhaoying; Yang, Yaning; Ma, Xiaojing; Ding, Wei (May 2003). «Microarray expression profiling: analysis and applications». Current Opinion in Drug Discovery & Development 6 (3): 384-395. ISSN 1367-6733. PMID 12833672. Consultado el 2 de abril de 2018.
- Li, Xinmin; Gu, Weikuan; Mohan, Subburaman; Baylink, David J. (January 2002). «DNA microarrays: their use and misuse». Microcirculation (New York, N.Y.: 1994) 9 (1): 13-22. ISSN 1073-9688. PMID 11896556. doi:10.1038/sj/mn/7800118. Consultado el 2 de abril de 2018.
- Quackenbush, John (2001/06). «Computational analysis of microarray data». Nature Reviews Genetics (en inglés) 2 (6): 418-427. ISSN 1471-0064. doi:10.1038/35076576. Consultado el 2 de abril de 2018.
- Simon, Richard; Radmacher, Michael D.; Dobbin, Kevin (June 2002). «Design of studies using DNA microarrays». Genetic Epidemiology 23 (1): 21-36. ISSN 0741-0395. PMID 12112246. doi:10.1002/gepi.202. Consultado el 2 de abril de 2018.
Enlaces externos
 Wikcionario tiene definiciones y otra información sobre ARN mensajero.
Wikcionario tiene definiciones y otra información sobre ARN mensajero.