Aprendizaje automático
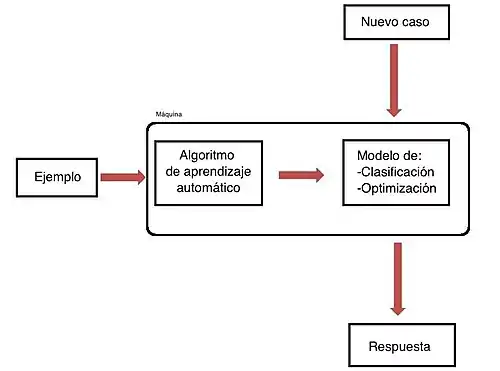
El aprendizaje automático (AA) o aprendizaje automatizado o aprendizaje de máquinas o aprendizaje computacional (del inglés, machine learning) es el subcampo de las ciencias de la computación y una rama de la inteligencia artificial, cuyo objetivo es desarrollar técnicas que permitan que las computadoras aprendan. Se dice que un agente aprende cuando su desempeño mejora con la experiencia y mediante el uso de datos; es decir, cuando la habilidad no estaba presente en su genotipo o rasgos de nacimiento.[1] "En el aprendizaje de máquinas un computador observa datos, construye un modelo basado en esos datos y utiliza ese modelo a la vez como una hipótesis acerca del mundo y una pieza de software que puede resolver problemas".[2]
En muchas ocasiones el campo de actuación del aprendizaje automático se solapa con el de la estadística inferencial, ya que las dos disciplinas se basan en el análisis de datos. Sin embargo, el aprendizaje automático incorpora las preocupaciones de la complejidad computacional de los problemas. Muchos problemas son de clase NP-hard, por lo que gran parte de la investigación realizada en aprendizaje automático está enfocada al diseño de soluciones factibles a esos problemas. El aprendizaje automático también está estrechamente relacionado con el reconocimiento de patrones. El aprendizaje automático puede ser visto como un intento de automatizar algunas partes del método científico mediante métodos matemáticos. Por lo tanto es un proceso de inducción del conocimiento.
El aprendizaje automático tiene una amplia gama de aplicaciones, incluyendo motores de búsqueda, diagnósticos médicos, detección de fraude en el uso de tarjetas de crédito, análisis de mercado para los diferentes sectores de actividad, clasificación de secuencias de ADN, reconocimiento del habla y del lenguaje escrito, juegos y robótica.
Resumen
Algunos sistemas de aprendizaje automático intentan eliminar toda necesidad de intuición o conocimiento experto de los procesos de análisis de datos, mientras otros tratan de establecer un marco de colaboración entre el experto y la computadora. De todas formas, la intuición humana no puede ser reemplazada en su totalidad, ya que el diseñador del sistema ha de especificar la forma de representación de los datos y los métodos de manipulación y caracterización de los mismos. Sin embargo, las computadoras son utilizadas por todo el mundo con fines tecnológicos muy buenos.
Modelos
El aprendizaje automático tiene como resultado un modelo para resolver una tarea dada. Entre los modelos se distinguen[3]
- Los modelos geométricos, construidos en el espacio de instancias y que pueden tener una, dos o múltiples dimensiones. Si hay un borde de decisión lineal entre las clases, se dice que los datos son linealmente separables. Un límite de decisión lineal se define como w * x = t, donde w es un vector perpendicular al límite de decisión, x es un punto arbitrario en el límite de decisión y t es el umbral de la decisión.
- Los modelos probabilísticos, que intentan determinar la distribución de probabilidades descriptora de la función que enlaza a los valores de las características con valores determinados. Uno de los conceptos claves para desarrollar modelos probabilísticos es la estadística bayesiana.
- Los modelos lógicos, que transforman y expresan las probabilidades en reglas organizadas en forma de árboles de decisión.
Los modelos pueden también clasificarse como modelos de agrupamiento y modelos de gradiente. Los primeros tratan de dividir el espacio de instancias en grupos. Los segundos, como su nombre lo indican, representan un gradiente en el que se puede diferenciar entre cada instancia. Clasificadores geométricos como las máquinas de vectores de apoyo son modelos de gradientes.
Tipos de algoritmos

Los diferentes algoritmos de Aprendizaje Automático se agrupan en una taxonomía en función de la salida de los mismos. Algunos tipos de algoritmos son:
- Aprendizaje supervisado
- El algoritmo produce una función que establece una correspondencia entre las entradas y las salidas deseadas del sistema. Un ejemplo de este tipo de algoritmo es el problema de clasificación, donde el sistema de aprendizaje trata de etiquetar (clasificar) una serie de vectores utilizando una entre varias categorías (clases). La base de conocimiento del sistema está formada por ejemplos de etiquetados anteriores. Este tipo de aprendizaje puede llegar a ser muy útil en problemas de investigación biológica, biología computacional y bioinformática.
- Aprendizaje no supervisado
- Todo el proceso de modelado se lleva a cabo sobre un conjunto de ejemplos formado tan solo por entradas al sistema. No se tiene información sobre las categorías de esos ejemplos. Por lo tanto, en este caso, el sistema tiene que ser capaz de reconocer patrones para poder etiquetar las nuevas entradas.
- Aprendizaje semisupervisado
- Este tipo de algoritmos combinan los dos algoritmos anteriores para poder clasificar de manera adecuada. Se tiene en cuenta los datos marcados y los no marcados.
- Aprendizaje por refuerzo
- El algoritmo aprende observando el mundo que le rodea. Su información de entrada es el feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende a base de ensayo-error.
- El aprendizaje por refuerzo es el más general entre las tres categorías. En vez de que un instructor indique al agente qué hacer, el agente inteligente debe aprender cómo se comporta el entorno mediante recompensas (refuerzos) o castigos, derivados del éxito o del fracaso respectivamente. El objetivo principal es aprender la función de valor que le ayude al agente inteligente a maximizar la señal de recompensa y así optimizar sus políticas de modo a comprender el comportamiento del entorno y a tomar buenas decisiones para el logro de sus objetivos formales.
- Los principales algoritmos de aprendizaje por refuerzo se desarrollan dentro de los métodos de resolución de problemas de decisión finitos de Markov, que incorporan las ecuaciones de Bellman y las funciones de valor. Los tres métodos principales son: la Programación Dinámica, los métodos de Monte Carlo y el aprendizaje de Diferencias Temporales.[4]
- Entre las implementaciones desarrolladas está AlphaGo, un programa de IA desarrollado por Google DeepMind para jugar el juego de mesa Go. En marzo de 2016 AlphaGo le ganó una partida al jugador profesional Lee Se-Dol que tiene la categoría noveno dan y 18 títulos mundiales. Entre los algoritmos que utiliza se encuentra el árbol de búsqueda Monte Carlo, también utiliza aprendizaje profundo con redes neuronales. Puede ver lo ocurrido en el documental de Netflix “AlphaGo”.
- Transducción
- Similar al aprendizaje supervisado, pero no construye de forma explícita una función. Trata de predecir las categorías de los futuros ejemplos basándose en los ejemplos de entrada, sus respectivas categorías y los ejemplos nuevos al sistema.
- Aprendizaje multi-tarea
- Métodos de aprendizaje que usan conocimiento previamente aprendido por el sistema de cara a enfrentarse a problemas parecidos a los ya vistos.
El análisis computacional y de rendimiento de los algoritmos de aprendizaje automático es una rama de la estadística conocida como teoría computacional del aprendizaje.
El aprendizaje automático las personas lo llevamos a cabo de manera automática ya que es un proceso tan sencillo para nosotros que ni nos damos cuenta de cómo se realiza y todo lo que implica. Desde que nacemos hasta que morimos los seres humanos llevamos a cabo diferentes procesos, entre ellos encontramos el de aprendizaje por medio del cual adquirimos conocimientos, desarrollamos habilidades para analizar y evaluar a través de métodos y técnicas así como también por medio de la experiencia propia. Sin embargo, a las máquinas hay que indicarles cómo aprender, ya que si no se logra que una máquina sea capaz de desarrollar sus habilidades, el proceso de aprendizaje no se estará llevando a cabo, sino que solo será una secuencia repetitiva.
Técnicas de clasificación
Árboles de decisiones
Este tipo de aprendizaje usa un árbol de decisiones como modelo predictivo. Se mapean observaciones sobre un objeto con conclusiones sobre el valor final de dicho objeto.
Los árboles son estructuras básicas en la informática. Los árboles de atributos son la base de las decisiones. Una de las dos formas principales de árboles de decisiones es la desarrollada por Quinlan de medir la impureza de la entropía en cada rama, algo que primero desarrolló en el algoritmo ID3 y luego en el C4.5. Otra de las estrategias se basa en el índice GINI y fue desarrollada por Breiman, Friedman et alia. El algoritmo de CART es una implementación de esta estrategia.[5]
Reglas de asociación
Los algoritmos de reglas de asociación procuran descubrir relaciones interesantes entre variables. Entre los métodos más conocidos se hallan el algoritmo a priori, el algoritmo Eclat y el algoritmo de Patrón Frecuente.
Algoritmos genéticos
Los algoritmos genéticos son procesos de búsqueda heurística que simulan la selección natural. Usan métodos tales como la mutación y el cruzamiento para generar nuevas clases que puedan ofrecer una buena solución a un problema dado.
Redes neuronales artificiales
Las redes de neuronas artificiales (RNA) son un paradigma de aprendizaje automático inspirado en las neuronas de los sistemas nerviosos de los animales. Se trata de un sistema de enlaces de neuronas que colaboran entre sí para producir un estímulo de salida. Las conexiones tienen pesos numéricos que se adaptan según la experiencia. De esta manera, las redes neurales se adaptan a un impulso y son capaces de aprender. La importancia de las redes neurales cayó durante un tiempo con el desarrollo de los vectores de soporte y clasificadores lineales, pero volvió a surgir a finales de la década de 2000 con la llegada del aprendizaje profundo.
Máquinas de vectores de soporte
Las MVS son una serie de métodos de aprendizaje supervisado usados para clasificación y regresión. Los algoritmos de MVS usan un conjunto de ejemplos de formación clasificada en dos categorías para construir un modelo que prediga si un nuevo ejemplo pertenece a una u otra de dichas categorías.
Algoritmos de agrupamiento
El análisis por agrupamiento (clustering en inglés) es la clasificación de observaciones en subgrupos —clusters— para que las observaciones en cada grupo se asemejen entre sí según ciertos criterios.
Las técnicas de agrupamiento hacen inferencias diferentes sobre la estructura de los datos; se guían usualmente por una medida de similitud específica y por un nivel de compactamiento interno (similitud entre los miembros de un grupo) y la separación entre los diferentes grupos.
El agrupamiento es un método de aprendizaje no supervisado y es una técnica muy popular de análisis estadístico de datos.
Redes bayesianas
Una red bayesiana, red de creencia o modelo acíclico dirigido es un modelo probabilístico que representa una serie de variables de azar y sus independencias condicionales a través de un grafo acíclico dirigido. Una red bayesiana puede representar, por ejemplo, las relaciones probabilísticas entre enfermedades y síntomas. Dados ciertos síntomas, la red puede usarse para calcular las probabilidades de que ciertas enfermedades estén presentes en un organismo. Hay algoritmos eficientes que infieren y aprenden usando este tipo de representación.
Conocimiento
En el aprendizaje automático podemos obtener 3 tipos de conocimiento, que son:
- 1. Crecimiento
- Es el que se adquiere de lo que nos rodea, el cual guarda la información en la memoria como si dejara huellas.
- 2. Reestructuración
- Al interpretar los conocimientos el individuo razona y genera nuevo conocimiento al cual se le llama de reestructuración.
- 3. Ajuste
- Es el que se obtiene al generalizar varios conceptos o generando los propios.
Los tres tipos se efectúan durante un proceso de aprendizaje automático pero la importancia de cada tipo de conocimiento depende de las características de lo que se está tratando de aprender.
El aprendizaje es más que una necesidad, es un factor primordial para satisfacer las necesidades de la inteligencia artificial.
Distinción entre Aprendizaje supervisado y no supervisado
El aprendizaje supervisado se caracteriza por contar con información que especifica qué conjuntos de datos son satisfactorios para el objetivo del aprendizaje. Un ejemplo podría ser un software que reconoce si una imagen dada es o no la imagen de un rostro: para el aprendizaje del programa tendríamos que proporcionarle diferentes imágenes, especificando en el proceso si se trata o no de rostros.
En el aprendizaje no supervisado, en cambio, el programa no cuenta con datos que definan qué información es satisfactoria o no. El objetivo principal de estos programas suele ser encontrar patrones que permitan separar y clasificar los datos en diferentes grupos, en función de sus atributos. Siguiendo el ejemplo anterior un software de aprendizaje no supervisado no sería capaz de decirnos si una imagen dada es un rostro o no pero sí podría, por ejemplo, clasificar las imágenes entre aquellas que contienen rostros humanos, de animales, o las que no contienen. La información obtenida por un algoritmo de aprendizaje no supervisado debe ser posteriormente interpretada por una persona para darle utilidad.
Aplicaciones
- Motores de búsqueda
- Diagnóstico médico
- Detección de fraudes con el uso de tarjetas de crédito
- Análisis del mercado de valores
- Clasificación de secuencias de ADN
- Ingeniería de características
- Reconocimiento del habla
- Robótica
- Minería de datos
- Big Data
- Previsiones de series temporales
Temas del aprendizaje automático
A continuación se muestran una serie de temas que podrían formar parte del temario de un curso sobre aprendizaje automático.
- Modelado de funciones de densidad de probabilidad condicionadas: clasificación y regresión
- Redes neuronales artificiales
- Árboles de decisión: El aprendizaje por árboles de decisión usa un árbol de decisión como modelo predictivo que mapea observaciones a conclusiones sobre el valor de un objeto dado.
- Modelos de regresión múltiple no postulados
- Regresión en procesos Gaussianos
- Análisis de discriminantes lineales
- k-vecinos más próximos
- Perceptrón
- Funciones de base radial
- Máquinas de soporte vectorial
- Modelado de funciones de densidad de probabilidad mediante modelos generativos
- Algoritmo EM
- Modelos gráficos, como las redes bayesianas y los campos aleatorios de Markov
- Mapeado topográfico generativo
- Técnicas de inferencia aproximada
- Optimización: La mayoría de los métodos descritos arriba usan algoritmos de optimización o son por sí mismos instancias de problemas de optimización.
Historia y relación con otros temas
El aprendizaje automático nació de la búsqueda de inteligencia artificial. Ya en los primeros días de la IA como disciplina académica, algunos investigadores se interesaron en hacer que las máquinas aprendiesen. Trataron de resolver el problema con diversos métodos simbólicos, así como lo que ellos llamaron 'redes neurales' que eran en general perceptrones y otros modelos básicamente basados en modelos lineares generalizados como se conocen en las estadísticas.
Software
Muchos lenguajes de programación pueden usarse para implementar algoritmos de aprendizaje automático. Los más populares para 2015 eran R y Python.[6] R es muy usado ante todo en el campo académico, mientras que Python es más popular en la empresa privada.
Entre los paquetes de software que incluyen algoritmos de aprendizaje automatizado, se hallan los siguientes:
Software de código abierto
- TensorFlow: plataforma multilenguaje y multiplataforma desarrollada por Google y licenciada como Apache 2.
- Apache Mahout: plataforma de Java de algoritmos escalables de aprendizaje automático, en especial en las áreas de filtro colaborativo, clustering y clasificación
- dlib: una biblioteca bajo licencia Boost para desarrollar en C++
- ELKI: una plataforma para Java con licencia AGPLv3
- Encog
- H2O
- KNIME
- mlpy
- MLPACK
- MOA
- OpenCV
- Tortilla JS
- OpenNN
- R: lenguaje de programación estadístico con numerosas bibliotecas relacionadas al aprendizaje automático (e1071, rpart, nnet, randomForest, entre otras)
- RapidMiner
- scikit-learn: biblioteca en Python que interactúa con NumPy y SciPy
- Spark MLlib: una librería que forma parte de Apache Spark, una plataforma para computación de grupos
- Weka: una biblioteca en Java
Software comercial
- SPSS Modeler
- Mathematica
- MATLAB
- Microsoft Azure Machine Learning
- Neural Designer
- Oracle Data Mining
- RCASE
- STATISTICA
- SAS
Sesgos
Los algoritmos de aprendizaje automático a menudo pueden verse afectados por el sesgo que puedan tener los datos (Ver sesgo algoritmico). Por ejemplo, no se podrán clasificar todos aquellas entradas de las que no se haya recibido ninguna información en la fase de formación. De hecho, cuando la formación se realiza con datos clasificados por el ser humano el aprendizaje automático tiende a crear los mismos sesgos que hay en la sociedad. Algunos ejemplos de esto son cuando en 2015 el algoritmo de Google photos identificaba algunas personas negras con gorilas, o en 2016 cuando el bot de Twitter de Microsoft desarrollo comportamientos racistas y machistas a base de observar el tráfico de datos en dicha red social. Por este motivo en los últimos años ha habido una tendencia a desarrollar métodos para aumentar la equidad, es decir, para reducir el sesgo en este tipo algoritmos por parte de los expertos en IA. Citando a Fei-fei Li "La IA no tiene nada de especial. Se inspira en personas, es creada por personas, y lo más importante impacta en las personas. Es una herramienta muy poderosa que tan solo hemos comenzado a entender, y esa es una gran responsabilidad" [7]
Véase también
- Aprendizaje automático antagónico
- Aprendizaje profundo
- Dinámica de sistemas
- Inteligencia artificial
- Inteligencia computacional
- Internet de las cosas
- Sistema dinámico
- Reconocimiento de patrones
- Reglas de asociación
- Robot autónomo
- Equidad (aprendizaje automático)
- Ablación (inteligencia artificial)
- OpenAI Codex
- Fawkes (software de encubrimiento de imágenes)
- Red neuronal residual
- Hiperparámetro (aprendizaje automático)
Referencias
- Russell, Stuart; Norvig, Peter (2009). Inteligencia Artificial: Un Enfoque Moderno (3rd edición). p. 229.
- Russell and Norvig (2021). Artificial Intelligence: A Modern Approach (en inglés). Pearson. p. 651. ISBN 9780134610993.
- Flach 2012 Págs. 20-21
- Sutton, Richard S., Barto, Andrew G. Reinforcement Learning: An Introduction. The MIT Press.
- Flach 2012 Págs. 155-156
- Four main languages for analytics and data mining science (KD Nuggets)
- «Fei-Fei Li's Quest to Make Machines Better for Humanity». Wired (en inglés). ISSN 1059-1028. Consultado el 17 de diciembre de 2019.
Bibliografía
- Bishop, Christopher (2008) Pattern Recognition and Machine Learning. Springer Verlag. ISBN=978-0-3873-1073-2.
- Flach, Peter (2012) Machine Learning: The Art and Science of Algorithms that Make Sense of Data. Cambridge University Press. ISBN 978-1-107-42222-3.
- Gollapudi, Sunila (2016) Practical Machine Learning. Packt Publishing. ISBN=978-1-78439-968-4.
- Ian H. Witten and Eibe Frank (2011). Data Mining: Practical machine learning tools and techniques Morgan Kaufmann, 664 pág., ISBN 978-0-12-374856-0.
- Mitchell, T. (1997). Machine Learning, McGraw Hill. ISBN 0-07-042807-7
- Raschka, Sebastian (2015). Python Machine Learning, Packt Open Source. ISBN 978-1-78355-513-0
Enlaces externos
- Ejemplos prácticos de Machine Learning en Español
- Blog sobre Aprendizaje Automático - La biblia del Machine Learning
- El Machine Learning cambiará el mundo
- Machine Learning Development with Perl (en inglés)
- Estudio y aplicación de técnicas de aprendizaje automático orientadas al ámbito médico: estimación y explicación de predicciones individuales. Universidad Autónoma de Madrid
- AlphaGo Archivado el 4 de febrero de 2018 en Wayback Machine.
- Machine Learning explicado (podcast)
- Machine Learning: Selección de métricas de clasificación (en español)
| Control de autoridades |
|
|---|
 Datos: Q2539
Datos: Q2539 Multimedia: Machine learning / Q2539
Multimedia: Machine learning / Q2539