Búsqueda y recuperación de información
La búsqueda y recuperación de información es la ciencia de la búsqueda de información en documentos electrónicos y cualquier tipo de colección documental digital, encargada de la búsqueda dentro de estos mismos, búsqueda de metadatos que describan documentos, o también la búsqueda en bases de datos relacionales, ya sea a través de internet, una intranet, y como objetivo realiza la recuperación en textos, imágenes, sonido o datos de otras características, de manera pertinente y relevante.
La recuperación de información es un estudio interdisciplinario. Cubre tantas disciplinas que eso genera normalmente un conocimiento parcial desde tan solo una u otra perspectiva. Algunas de las disciplinas que se ocupan de estos estudios son la psicología cognitiva, la arquitectura de la información, diseño de la información, inteligencia artificial, lingüística, semiótica, informática, biblioteconomía, archivística y documentación.
Para alcanzar su objetivo de recuperación se sustenta en los sistemas de información, y al ser de carácter multidisciplinario intervienen bibliotecólogos para determinar criterio de búsqueda, la relevancia y pertinencia de los términos, en conjunto con la informática.
Historia
La idea del uso de computadoras para la búsqueda de trozos relevantes de información se popularizó a raíz de un artículo As We May Think de Vannevar Bush en el año 1945.[1] Los primeros sistemas automatizados de recuperación de la información fueron presentados durante la década de 1950 a 1960. Durante 1970 se realizaron pruebas a un grupo de textos como la colección Cranfield para un gran número de distintas técnicas cuyo rendimiento fue bueno.[1] Los sistemas de recuperación a larga escala, como el Sistema de Diálogo Lockheed, comenzaron a utilizarse a principios de 1970.
En 1992, el Departamento de Defensa de los Estados Unidos conjuntamente con el Instituto Nacional de Estándares y Tecnología (NIST por su sigla en inglés), patrocinaron la Conferencia de Recuperación de Texto (TREC) como parte del programa TIPSTER. Esto proveyó ayuda desde la comunidad de recuperación de la información al suministrar la infraestructura necesaria para la evaluación de metodologías de recuperación de texto en una colección a larga escala. La introducción de motores de búsqueda ha elevado aún más la necesidad de sistemas de recuperación con mayor capacidad.
El uso de métodos digitales para almacenar y recuperar información ha desembocado en el denominado fenómeno de la obsolescencia digital, que sucede cuando una fuente digital deja de ser accesible porque sus medio físico, el lector utilizado para la lectura de ese medio o el software que lo controla, ya no se encuentra disponible. La información, inicialmente es más fácil de recuperar en lugar de su fuente en papel, pero dicha información entonces, se pierde definitivamente.
Los buscadores, tales como Google, Google Desktop Search, Lycos y Copernic, son algunas de las aplicaciones más populares para la recuperación de información. Básicamente hay que construir un Vocabulario, que es una lista de términos en lenguaje natural, un algoritmo que incluya las reglas lógicas de la búsqueda {Tabla de verdad} y una valoración de los resultados o cantidad de información lograda o posible. Este motor de búsqueda es pues el que permite plantear una pregunta con no menos de dos términos (en algunos casos pueden ser menos de dos términos) y mostrar los resultados mínimos y el logaritmo natural de las interacciones será alrededor de 789
Algunos de los estudiosos más destacados dentro de esta subdisciplina son Gerard Salton, W Bruce Croft, Karen Spärck Jones, Keith van Rijsbergen y Ricardo Baeza-Yates.
A veces se plantean ciertos problemas a la hora de recuperar información provocados por el uso del lenguaje natural (entre otras razones) como el silencio (debido a la sinonimia), el ruido (debido a la polisemia), homografía, ambigüedad, etc.
Presentación
Un proceso de recuperación de información comienza cuando un usuario hace una consulta al sistema. Una consulta a su vez es una afirmación formal de la necesidad de una información. En la recuperación de información una consulta no identifica únicamente a un objeto dentro de la colección. De hecho varios objetos pueden ser respuesta a una consulta con diferentes grados de relevancia.
Un objeto es una identidad que está representada por información en una base de datos. En dependencia de la aplicación estos objetos pueden ser archivos de texto, imágenes, audio, mapas, videos, etc. Muy a menudo los documentos no están almacenados en el sistema de recuperación de información, sino que están representados lógicamente.
La mayoría de los sistemas de recuperación de información computan un ranking para saber cuán bien cada objeto responde a la consulta, ordenando los objetos de acuerdo a su valor de ranking. Los objetos con mayor ranking son mostrados a los usuarios y el proceso puede tener otras iteraciones si el usuario desea refinar su consulta.
Medidas de rendimiento y correctitud
Muchas medidas han sido propuestas para evaluar el rendimiento de los sistemas de recuperación de información. Las medidas necesitan una colección de documentos y una consulta. A continuación serán descritas algunas medidas comunes, las cuales asumen que: cada documento se sabe que este es relevante o no relevante para una consulta particular. En la práctica pueden haber diferentes matices de relevancia.
Precisión
La precisión es la fracción de documentos recuperados que son relevantes para la necesidad de información del usuario.

La precisión tiene en cuenta todos los documentos recuperados. También puede ser evaluada en un corte determinado del ranking, considerando solamente los primeros resultados obtenidos del sistema.
Nótese que el significado y uso de la "precisión" en el campo de la Recuperación de Información, difiere de las definiciones de exactitud y precisión en otras ramas de la ciencia y la tecnología.
Exhaustividad
La exhaustividad es la fracción de documentos relevantes para una consulta que fueron recuperados.

Resulta trivial obtener un 100% de exhaustividad si se toman como respuesta para cualquier consulta todos los documentos de la colección. Por lo tanto, la exhaustividad sola no es suficiente, sino que se necesita también medir el número de documentos no relevantes, por ejemplo con el cálculo de la precisión.
Proposición de fallo
La proposición de fallo, llamada en inglés fall-out, es la proporción de documentos no relevantes que son recuperados, fuera de todos los documentos relevantes disponibles.

Resulta trivial obtener un 0% de proposición de fallo si no se devuelve ningún documento de la colección para cualquier consulta.
Medida F
La medida F es un balance de la precisión y el recobrado:

Esta es conocida además como la medida , pues el recobrado y la precisión son pesados uniformemente.

La fórmula general para el parámetro real no negativo es:

- .

Otras dos medidas F ampliamente utilizadas son la medida , que pondera el recobrado dos veces por encima de la precisión, y la medida , que pesa la precisión dos veces por encima del recobrado.


La medida F fue obtenida por Van Rijsbergen en 1979. “mide la efectividad de la recuperación respecto a un usuario que atribuye veces más importancia al recobrado que a la precisión”. Está basada en la medida de Van Rijsbergen . La relación entre estas dos medidas es donde .




Precisión Promedio
La Precisión y el recobrado son métricas basadas en toda la lista de documentos retornada por el sistema dada una consulta. Para sistemas que hacen ranking a los documentos retornados para una consulta es deseable considerar además el orden en que los documentos retornados son presentados. Si se computa la precisión y el recobrado en cada posición de la secuencia de documentos con ranking, podemos plotear la curva precisión - recobrado, ploteando la precisión como una función del recobrado . La Precisión Promedio computa el promedio de los valores de sobre la integral desde hasta :





Esta integral es remplazada en la práctica por una suma finita sobre todas las posiciones en la secuencia de documentos con ranking:

donde es el ranking en la secuencia de documentos recuperados, es el número de documentos recuperados, es la precisión del corte en la posición de la lista y es el cambio en el recobrado de los elementos hasta .





Esta suma finita es equivalente a:

donde es un indicador igual a 1 si el ítem en la posición del ranking es relevante al documento, y cero en otro caso. Nótese que el promedio es sobre todos los documentos relevantes y que los documentos relevantes que no son recuperados obtienen una precisión igual a cero.

La Precisión Promedio en ocasiones se refiere geométricamente como el área bajo la curva precisión - recobrado.
Media de la precisión promedio
La media de la precisión promedio (también conocido como La media de Isabel, o MAP: Mean Average Precision por su nombre en inglés), para un conjunto de consultas o queries es el promedio de las puntuaciones medias de precisión para cada consulta.

donde Q es el número de consultas que se están evaluando.
Tipos de Modelos
Para recuperar efectivamente los documentos relevantes por estrategias de recuperación de información, los documentos son transformados en una representación lógica de los mismos. Cada estrategia de recuperación incorpora un modelo específico para sus propósitos de representación de los documentos. La figura a la derecha ilustra la relación entre algunos de los modelos más comunes. Los modelos están categorizados de acuerdo a dos dimensiones: la base matemática y las propiedades de los modelos.
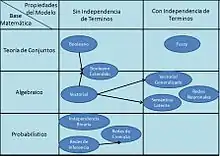
Primera Dimensión: Base Matemática
- Modelos basados en Teoría de Conjuntos: Los documentos se representan como un conjunto de palabras o frases. Los modelos más comunes son:
- Modelo Booleano
- Modelo Booleano Extendido
- Modelo Fuzzy
- Modelos Algebraicos: En estos modelos los documentos y las consultas se representas como vectores, matrices o tuplas. La similitud entre un documento y una consulta se representa por un escalar. Dentro de ellos tenemos:
- Modelos Probabilísticos: Tratan el proceso de recuperación de documentos como una inferencia probabilística. Las similitudes son calculadas como las probabilidades de que un documento sea relevante dada una consulta.
- Modelo de independencia binaria
- Modelo de Relevancia Probabilístico
- Redes de Inferencia
- Redes de Creencia
Segunda Dimensión: Propiedades de los Modelos
- Modelos sin inter-dependencia entre términos: Tratan a los términos como si fueran independientes.
- Modelos con inter-dependencia entre términos: Permiten representar las interdependencias entre términos.
Referencias
- Singhal, Amit (2001). «Modern Information Retrieval: A Brief Overview». Bulletin of the IEEE Computer Society Technical Committee on Data Engineering 24 (4): 35-43.
Bibliografía
- Baeza-Yates, Ricardo; Ribeiro-Neto, Berthier: Modern Information Retrieval. New York : ACM;Harlow, Essex: Addison-Wesley Longman, 1999.
- Salvador Oliván, José A.: Recuperación de Información. Buenos Aires : Alfagrama, 2008.
- Salton, Gerald; McGill, Michael J.: Introduction to Modern Information Retrieval. New York : McGraw-Hill, 1983.
Enlaces externos
- Esta obra contiene una traducción derivada de «Information Retrieval» de Wikipedia en inglés, publicada por sus editores bajo la Licencia de documentación libre de GNU y la Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
| Control de autoridades |
|
|---|
 Datos: Q816826
Datos: Q816826 Multimedia: Information retrieval / Q816826
Multimedia: Information retrieval / Q816826