Fréquence d'apparition des lettres
La fréquence d'apparition des lettres est une donnée statistique utilisée en linguistique, en typographie et en cryptographie liée au fait que les utilisateurs de la langue écrite n'utilisent pas les lettres disponibles au hasard, mais selon l'ordonnancement de la langue, du langage et de la parole.
Bien que l'alphabet ne soit pas hiérarchisé, les lettres écrites ne sont pas utilisées à la même fréquence, en français comme dans les autres langues. Ainsi, si l'on prend un texte en français composé de 100 lettres, on n'aura pas 100 lettres différentes mais environ 12 fois la lettre E, 7 fois la lettre A, 7 fois la lettre I, 7 fois la lettre S, etc., selon une loi de distribution qu'il n'est pas facile à déterminer.
Base statistique de calcul : le corpus
Le calcul de la fréquence d'apparition des lettres en français se fait après avoir constitué un corpus de textes (ensemble cohérent et systématique de documents textuels). Le choix des documents est crucial.
Le dictionnaire est parfois utilisé comme corpus. Or la fréquence des lettres dans la liste des mots d’un dictionnaire diffère de celle dans un texte usuel. En effet, très peu de mots apparaissent au pluriel dans un dictionnaire, ce qui conduit la lettre s à y être moins fréquente. De plus, les lettres accentuées à et ù apparaissent dans un nombre très limité de mots, mais dont certains sont d'usage fréquent (à, où), ce qui contribue à modifier la fréquence relative de ces lettres.
La fréquence d'apparition des lettres en français est souvent calculé sur un corpus de textes littéraires disponible sur le Net, par exemple sur le site de l’Association des bibliophiles universels (ABU). On peut alors faire des analyses de fréquence de lettres chez un auteur en particulier.
De même, on peut calculer la fréquence d'apparition des lettres en français sur le corpus de Wikipédia en français. En 2008, le laboratoire CLLE-ERSS de l'Université de Toulouse en a tiré une table de fréquence[1].
| Rang | Caractère | Nombre d'occurrences | Pourcentage | |
|---|---|---|---|---|
| 1 | e | 115 024 205 | 12.10% | |
| 2 | a | 67 563 628 | 7.11% | |
| 3 | i | 62 672 992 | 6.59% | |
| 4 | s | 61 882 785 | 6.51% | |
| 5 | n | 60 728 196 | 6.39% | |
| 6 | r | 57 656 209 | 6.07% | |
| 7 | t | 56 267 109 | 5.92% | |
| 8 | o | 47 724 400 | 5.02% | |
| 9 | l | 47 171 247 | 4.96% | |
| 10 | u | 42 698 875 | 4.49% | |
| 11 | d | 34 914 685 | 3.67% | |
| 12 | c | 30 219 574 | 3.18% | |
| 13 | m | 24 894 034 | 2.62% | |
| 14 | p | 23 647 179 | 2.49% | |
| 15 | é | 18 451 937 | 1.94% | |
| 17 | g | 11 684 140 | 1.23% | |
| 18 | b | 10 817 171 | 1.14% | |
| 19 | v | 10 590 858 | 1.11% | |
| 20 | h | 10 583 562 | 1.11% | |
| 21 | f | 10 579 192 | 1.11% | |
| 22 | q | 6 140 307 | 0.65% | |
| 23 | y | 4 351 953 | 0.46% | |
| 24 | x | 3 588 990 | 0.38% | |
| 25 | j | 3 276 064 | 0.34% | |
| 26 | è | 2 969 466 | 0.31% | |
| 27 | à | 2 966 029 | 0.31% | |
| 28 | k | 2 747 547 | 0.29% | |
| 29 | w | 1 653 435 | 0.17% | |
| 30 | z | 1 433 913 | 0.15% | |
| 31 | ê | 802 211 | 0.08% | |
| 32 | ç | 544 509 | 0.06% | |
| 33 | ô | 357 197 | 0.04% | |
| 34 | â | 320 837 | 0.03% | |
| 35 | î | 280 201 | 0.03% | |
| 36 | û | 164 516 | 0.02% | |
| 37 | ù | 151 236 | 0.02% | |
| 38 | ï | 138 221 | 0.01% | |
| 39 | á | 73 751 | 0.01% | |
| 79 | ü | 55 172 | 0.01% | |
| 82 | ë | 53 862 | 0.01% | |
| 83 | ö | 51 020 | 0.01% | |
| 84 | í | 48 391 | 0.01% | |
- Lettres absentes de la langue française, mais présentes dans le corpus
Dans d'autres langues
[réf. nécessaire]
| Lettre | Anglais | Français[3] | Allemand[4] | Espagnol[5] | Portugais[6] | Espéranto[7] | Italien[8] | Turc[9] | Suédois[10] | Polonais[11] | Néerlandais[12] | Danois[13] | Islandais[14] | Finnois[15] | Tchèque | Lituanien[16] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 8.167% | 7.636% | 6.516% | 11.525% | 14.634% | 12.117% | 11.745% | 11.920% | 9.383% | 8.910% | 7.486% | 6.025% | 10.110% | 12.217% | 8.421% | 11,1912 |
| b | 1.492% | 0.901% | 1.886% | 2.215% | 1.043% | 0.980% | 0.927% | 2.844% | 1.535% | 1.470% | 1.584% | 2.000% | 1.043% | 0.281% | 0.822% | 1,4842 |
| c | 2.782% | 3.260% | 2.732% | 4.019% | 3.882% | 0.776% | 4.501% | 0.963% | 1.486% | 3.960% | 1.242% | 0.565% | 0 | 0.281% | 0.740% | 0,6019 |
| d | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.044% | 3.736% | 4.706% | 4.702% | 3.250% | 5.933% | 5.858% | 1.575% | 1.043% | 3.475% | 2,5802 |
| e | 12.702% | 14.715% | 16.396% | 12.181% | 12.570% | 8.995% | 11.792% | 8.912% | 10.149% | 7.660% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% | 5,6205 |
| f | 2.228% | 1.066% | 1.656% | 0.692% | 1.023% | 1.037% | 1.153% | 0.461% | 2.027% | 0.300% | 0.805% | 2.406% | 3.013% | 0.194% | 0.084% | 0,3468 |
| g | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1.171% | 1.644% | 1.253% | 2.862% | 1.420% | 3.403% | 4.077% | 4.241% | 0.392% | 0.092% | 1,7946 |
| h | 6.094% | 0.737% | 4.577% | 0.703% | 0.781% | 0.384% | 0.636% | 1.212% | 2.090% | 1.080% | 2.380% | 1.621% | 1.871% | 1.851% | 1.356% | 0,2760 |
| i | 6.966% | 7.529% | 6.550% | 6.247% | 6.186% | 10.012% | 10.143% | 8.600%* | 5.817% | 8.210% | 6.499% | 6.000% | 7.578% | 10.817% | 6.073% | 12,9593 |
| j | 0.153% | 0.613% | 0.268% | 0.493% | 0.397% | 3.501% | 0.011% | 0.034% | 0.614% | 2.280% | 1.46% | 0.730% | 1.144% | 2.042% | 1.433% | 2,3380 |
| k | 0.772% | 0.074% | 1.417% | 0.011% | 0.015% | 4.163% | 0.009% | 4.683% | 3.140% | 3.510% | 2.248% | 3.395% | 3.314% | 4.973% | 2.894% | 4,1708 |
| l | 4.025% | 5.456% | 3.437% | 4.967% | 2.779% | 6.104% | 6.510% | 5.922% | 5.275% | 2.100% | 3.568% | 5.229% | 4.532% | 5.761% | 3.802% | 3,5019 |
| m | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.994% | 2.512% | 3.752% | 3.471% | 2.800% | 2.213% | 3.237% | 4.041% | 3.202% | 2.446% | 3,5790 |
| n | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 7.955% | 6.883% | 7.487% | 8.542% | 5.520% | 10.032% | 7.240% | 7.711% | 8.826% | 6.468% | 5,1441 |
| o | 7.507% | 5.796% | 2.594% | 8.683% | 9.735% | 8.779% | 9.832% | 2.476% | 4.482% | 7.750% | 6.063% | 4.636% | 2.166% | 5.614% | 6.695% | 6,7429 |
| p | 1.929% | 2.521% | 0.670% | 2.510% | 2.523% | 2.755% | 3.056% | 0.886% | 1.839% | 3.130% | 1.57% | 1.756% | 0.789% | 1.842% | 1.906% | 2,7344 |
| q | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0 | 0.505% | 0 | 0.020% | 0.140% | 0.009% | 0.007% | 0 | 0.013% | 0.001% | 0,0054 |
| r | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 5.914% | 6.367% | 6.722% | 8.431% | 4.690% | 6.411% | 8.956% | 8.581% | 2.872% | 4.799% | 5,6689 |
| s | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 6.092% | 4.981% | 3.014% | 6.590% | 4.320% | 3.73% | 5.805% | 5.630% | 7.862% | 5.212% | 7,8811 |
| t | 9.056% | 7.244% | 6.154% | 4.632% | 4.336% | 5.276% | 5.623% | 3.314% | 7.691% | 3.980% | 6.79% | 6.862% | 4.953% | 8.750% | 5.727% | 5,3323 |
| u | 2.758% | 6.311% | 4.166% | 2.927% | 3.639% | 3.183% | 3.011% | 3.235% | 1.919% | 2.500% | 1.99% | 1.979% | 4.562% | 5.008% | 2.160% | 4,5860 |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 1.904% | 2.097% | 0.959% | 2.415% | 0.040% | 2.85% | 2.332% | 2.437% | 2.250% | 5.344% | 2,6557 |
| w | 2.360% | 0.049% | 1.921% | 0.017% | 0.037% | 0 | 0.033% | 0 | 0.142% | 4.650% | 1.52% | 0.069% | 0 | 0.094% | 0.016% | 0,0368 |
| x | 0.150% | 0.427% | 0.034% | 0.215% | 0.253% | 0 | 0.003% | 0 | 0.159% | 0.020% | 0.036% | 0.028% | 0.046% | 0.031% | 0.027% | 0,0733 |
| y | 1.974% | 0.128% | 0.039% | 1.008% | 0.006% | 0 | 0.020% | 3.336% | 0.708% | 3.760% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% | 1,4325 |
| z | 0.074% | 0.326% | 1.134% | 0.467% | 0.470% | 0.494% | 1.181% | 1.500% | 0.070% | 5.640% | 1.39% | 0.034% | 0 | 0.051% | 1.599% | 0,3454 |
| à | ~0% | 0.486% | 0 | 0 | 0.072% | 0 | 0.635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| â | ~0% | 0.051% | 0 | 0 | 0.562% | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| á | 0 | 0 | 0 | 0.502% | 0.118% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.799% | 0 | 0.867% | 0,0024 |
| å | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.338% | 0 | 0 | 1.190% | 0 | 0.003% | 0 | |
| ä | 0 | 0 | 0.578% | 0 | 0 | 0 | 0 | 0 | 1.797% | 0 | 0 | 0 | 0 | 3.577% | 0 | |
| ã | 0 | 0 | 0 | 0 | 0.733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ą | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.990% | 0 | 0 | 0 | 0 | 0 | 0,5418 |
| æ | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.872% | 0.867% | 0 | 0 | |
| œ | ~0% | 0.018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ç | ~0% | 0.085% | 0 | 0 | 0.530% | 0 | 0 | 1.156% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0.657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.400% | 0 | 0 | 0 | 0 | 0 | |
| č | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.462% | 0,4303 |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.015% | |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.393% | 0 | 0 | |
| è | ~0% | 0.271% | 0 | 0 | 0 | 0 | 0.263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| é | ~0% | 1.504% | 0 | 0.433% | 0.337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.647% | 0 | 0.633% | 0,0038 |
| ê | 0 | 0.218% | 0 | 0 | 0.450% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ë | ~0% | 0.008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ė | 1,6643 | |||||||||||||||
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.110% | 0 | 0 | 0 | 0 | 0 | 0,1721 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.222% | |
| ĝ | 0 | 0 | 0 | 0 | 0 | 0.691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ğ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ĥ | 0 | 0 | 0 | 0 | 0 | 0.022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| î | 0 | 0.045% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ì | 0 | 0 | 0 | 0 | 0 | 0 | (0.030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| í | 0 | 0 | 0 | 0.725% | 0.132% | 0 | 0.030% | 0 | 0 | 0 | 0 | 0 | 1.570% | 0 | 1.643% | 0,0015 |
| ï | ~0% | 0.005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ı | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5.114% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| į | 0,4848 | |||||||||||||||
| ĵ | 0 | 0 | 0 | 0 | 0 | 0.055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.820% | 0 | 0 | 0 | 0 | 0 | |
| ñ | ~0% | 0 | 0 | 0.311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.200% | 0 | 0 | 0 | 0 | 0 | |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.007% | |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0.002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ö | ~0% | 0 | 0.443% | 0 | 0 | 0 | 0 | 0.777% | 1.305% | 0 | 0 | 0 | 0.777% | 0.444% | 0 | 0,0014 |
| ô | ~0% | 0.023% | 0 | 0 | 0.635% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ó | 0 | 0 | 0 | 0.827% | 0.296% | 0 | ~0% | 0 | 0 | 0.850% | 0 | 0 | 0.994% | 0 | 0.024% | 0,0018 |
| õ | 0 | 0 | 0 | 0 | 0.040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939% | 0 | 0 | 0 | |
| ř | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.380% | |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0.385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ś | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.660% | 0 | 0 | 0 | 0 | 0 | |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.688% | 1,1339 |
| ß | 0 | 0 | 0.307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.006% | |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.455% | 0 | 0 | |
| ù | 0 | 0.058% | 0 | 0 | 0 | 0 | (0.166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ú | 0 | 0 | 0 | 0.168% | 0.207% | 0 | 0.166% | 0 | 0 | 0 | 0 | 0 | 0.613% | 0 | 0.045% | |
| û | ~0% | 0.060% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0.520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| ü | ~0% | 0 | 0.995% | 0.012% | 0.026% | 0 | 0 | 1.854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,0013 |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.204% | |
| ų | 1,2602 | |||||||||||||||
| ū | 0,4079 | |||||||||||||||
| ý | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.228% | 0 | 0.995% | |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.060% | 0 | 0 | 0 | 0 | 0 | |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.830% | 0 | 0 | 0 | 0 | 0 | |
| ž | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.721% | 0,7965 |
*See Dotted and dotless I.
Diagramme comparatif de la fréquence des lettres dans 11 langues.
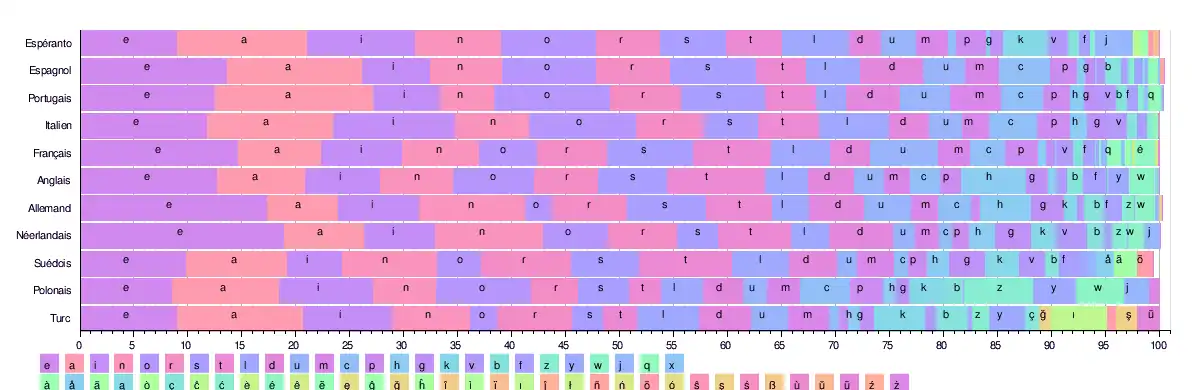
Biais dans le calcul de la fréquence d'apparition
Le calcul de la fréquence des lettres dans une langue est difficile et soumis à interprétation. On compte la fréquence des lettres d’un texte arbitrairement long, mais un certain nombre de paramètres influencent les résultats :
- Le style narratif : s’il y a beaucoup de verbes à la 2e personne du pluriel (le vouvoiement, présent dans beaucoup de dialogues), il y aura significativement plus de « Z ».
- Le vocabulaire spécifique du document : si l’on parle de chemins de fer, il y aura beaucoup plus de « W » (wagon) ; si l’un des protagonistes se dénomme Loïc, le nombre d'« Ï » s’en ressentira.
- Le type de document : des petites annonces en France présenteront souvent le symbole Euro (€), qui est absent de la plupart des autres documents.
- La langue d'origine du texte : les noms propres restant généralement les mêmes entre sa version originale et sa version traduite, certaines variations de fréquences de lettres rares en français peuvent se faire ressentir. Dans un texte d'un auteur anglais par exemple, les noms propres auront tendance à faire augmenter les fréquences de lettres relativement communes dans cette langue, telles que le H, le W ou le Y.
- L'époque à laquelle le texte a été rédigé : un texte français du dix-huitième siècle ne contiendra pas ou peu de W, car cette lettre était à cette époque beaucoup moins utilisée qu'aujourd'hui.
- Les paramètres techniques : on peut facilement calculer des statistiques sur des textes informatisés, mais souvent ceux-ci ne comportent pas de majuscules accentuées (car difficiles à entrer sur certains ordinateurs) et il arrive aux auteurs d'oublier des accents. La graphie de l’e-dans-l’o (œ) est impossible à représenter dans le codage latin-1 qui est souvent utilisé pour les textes en français. C'est un problème parce que « œ » n'est pas une ligature esthétique (optionnelle) mais une ligature linguistique (obligatoire), elle se prononce différemment de la suite de voyelles « oe » . Par exemple, « œ » va se prononcer [ɛ] dans œsophage alors que « oe » va se prononcer [ɔ.ɛ] dans coexistence.
- La présence de caractères non alphabétiques (symboles de ponctuation, chiffres, parenthèses et accolades, symboles mathématiques courants…) peut ou non être prise en compte ; la virgule, le point ou l’apostrophe sont par exemple plus fréquents que plus de la moitié des lettres[réf. souhaitée].
Si ces paramètres ont un impact spectaculaire sur les symboles les moins fréquents (la fréquence du œ varie entre 0,002 % et 0,09 % pour trois textes pris au hasard)[réf. nécessaire], elle est également sensible même pour les lettres les plus fréquentes (l’ordre de fréquence des lettres A, S, I, T et N, qui sont les plus fréquentes à part E, fluctue d’un texte à l’autre).
Histoire et usage
Le calcul de la fréquence d'apparition des lettres remonte au mathématicien arabe Al-Kindi (vers 801-873 de notre ère), qui l'utilise dans le but de casser des codes secrets, bien qu'on ait parlé du code César utilisé par Jules César au Ier siècle avant notre ère[réf. souhaitée]. L'analyse de la fréquence des lettres prend de l'importance en Europe avec le développement des caractères mobiles en 1450 de notre ère, parce qu'il est nécessaire d'anticiper la quantité de caractères nécessaires pour imprimer les textes. Depuis le XXe siècle, les linguistes utilisent également la fréquence des lettres une première identification des langues perdues : elle est particulièrement efficace pour indiquer si un système d'écriture inconnu est alphabétique, syllabique ou idéographique.
La fréquence d'apparition des lettres joue un rôle fondamental dans les cryptogrammes et dans plusieurs jeux liés à la manipulation des lettres, tels que le pendu, le Scrabble, le Wordle et le jeu télévisé La roue de la fortune. En littérature, Edgar Allan Poe, dans Le Scarabée d'or (1843), se sert de la connaissance de la fréquence des lettres anglaises pour lire un cryptogramme qui contient l'emplacement du trésor caché du capitaine Kidd.
En 1840, quand Alfred Vail crée le code américain pour le télégraphe électrique de Morse, il se fonde sur la base des fréquences des lettres en langue anglaise (selon l'ordre « e it san hurdm wgvlfbk opxcz jyq »), et code les lettres les plus fréquentes avec les symboles les plus courts. Le passage au code Morse international a émoussé l'efficacité du procédé.
Références
- CLLE-ERSS, « REDAC : Corpus texte WikipédiaFR2008 » (consulté le )
- « Fréquence des caractères - Disposition de clavier francophone et ergonomique bépo » (consulté le )
- « Corpus de Thomas Tempé » [archive du ] (consulté le )
- Albrecht Beutelspacher, Kryptologie, Wiesbaden, Vieweg, , 7e éd. (ISBN 3-8348-0014-7), p. 10
- Fletcher Pratt, Secret and Urgent: The sstory of codes and ciphers, Garden City, NY, Blue Ribbon Books, , 254–5 p. (OCLC 795065)
- « Frequência da ocorrência de letras no Português » [archive du ] (consulté le )
- « La Oftecoj de la Esperantaj Literoj » (consulté le )
- (it) Simon Singh et Stefano Galli, Codici e Segreti, Milano, Rizzoli, (ISBN 978-8-817-86213-4, OCLC 535461359)
- (20–22 February 2011) « Attacking Turkish Texts Encrypted by Homophonic Cipher » dans Proceedings of the 10th WSEAS International Conference on Electronics, Hardware, Wireless and Optical Communications : 123–126 p..
- « Practical Cryptography » (consulté le )
- https://sjp.pwn.pl/poradnia/haslo/frekwencja-liter-w-polskich-tekstach;7072.html
- « Letterfrequenties », sur Genootschap OnzeTaal (consulté le )
- « Danish letter frequencies », sur Practical Cryptography (consulté le )
- « Icelandic letter frequencies », sur Practical Cryptography (consulté le )
- « Finnish letter frequencies », sur Practical Cryptography (consulté le )
- (lt) Gintautas Grigas et Anita Juškevičienė, « Letter Frequency Analysis of Lithuanian and Other Languages Using the Latin Alphabet », Coactivity: Philology, Educology / Santalka: Filologija, Edukologija, vol. 23, no 2, , p. 81–91 (ISSN 2335-7711, DOI 10.3846/cpe.2015.271, lire en ligne, consulté le )