Algoritmo de propagación de creencias
El algoritmo de propagación de creencias (en inglés: belief propagation algorithm), también conocido como el algoritmo suma-producto, es un algoritmo de paso de mensajes para realizar inferencia sobre modelos gráficos tales como redes bayesianas, campos aleatorios de Markov y factor graph. Es ampliamente utilizado en los campos de inteligencia artificial y teoría de la información y ha mostrado cierto éxito experimental en aplicaciones tan diferentes como: análisis de paridad de códigos,[1] aproximaciones de energía libre,[2] coloreado de grafos[3] y satisfacibilidad booleana.[4]
Las ecuaciones de propagación de creencias han sido redescubiertas varias veces. Fueron desarrolladas por Pearl en 1988 como un algoritmo exacto para realizar inferencia probabilística sobre Redes Bayesianas acíclicas y como una aproximación útil en Redes Bayesianas con ciclos.[5] En los inicios de los 60 Gallager las introdujo como un procedimiento iterativo para la recuperación de códigos de paridad.
Sea un conjunto de variables aleatorias discretas, denotaremos con la realización de la variable aleatoria . Con función de distribución conjunta usualmente escrita como donde .







Es posible expresar como un producto de funciones:

Donde es un índice sobre las funciones en que se descomponen , la función posee como argumento que es un subconjunto de las variables aleatorias .







Entonces la distribución marginal de una variable dada es simplemente la suma de sobre todas las restantes variables.

Este enfoque se vuelve computacionalmente prohibitivo (en sistemas de tamaños relativamente pequeños), suponiendo que y las variables son binarias. Entonces para obtener el valor marginal de computar valores posibles. Explotando la estructura de poliárboles, el algoritmo de propagación de creencias permite el cálculo de los marginales de manera más eficiente en tiempo lineal respecto al tamaño del sistema.[6]




Descripción del algoritmo
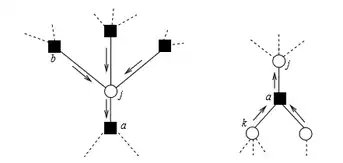
Existen variantes del algoritmo de propagación de creencias para diferentes modelos gráficos (Redes bayesianas, y campos aleatorios de Markov). El modelo gráfico usado en adelante es llamado factor graph, esto no representa ninguna limitación pues estos modelos son equivalentes y es posible la conversión entre estos.[7] Un factor graph es un grafo bipartito con dos tipos de nodos: nodos variables, usualmente denotados por las letras y representados gráficamente con círculos, y nodos factores, usualmente denotados por las letras y representados gráficamente como cuadrados, existe una arista entre un nodo variable y un nodo función si y solo si se encuentra en el argumento de . Llamaremos al conjunto de nodos variables y al conjunto de los nodos factores.





El algoritmo funciona enviando “mensajes” entre los nodos variables y nodos factores. De forma más específica si y el mensaje enviado desde hacia es la evaluación de una función y de forma alterna el mensaje enviado desde hacia es la evaluación de una función . Estos mensajes contiene la influencia de una variable sobre otra. El cálculo de los mensajes posee diferente forma según los nodos emisores y receptores.




Un mensaje enviado desde una variable a un nodo función es el producto de todos los mensajes que recibe la variable de los nodos factores vecinos excepto .donde es el conjunto de los nodos factores vecinos de a excepción del nodo . Si este conjunto es vació entonces distribuye de uniformemente sobre el conjunto de valores posibles de la variable .




Un mensaje enviado desde un nodo factor hacia un nodo variable es el producto de la función evaluada en la vecindad de a excepción de que esta marginalizado al valor .Si es vacío entonces . La suma sobre es la suma sobre todo el conjunto de todos los posibles valores de las variables vecinas de a excepción de que se encuentra marginalizada al valor .




Inicialmente el conjunto de mensajes iniciales se escogen de manera aleatoria, luego siguiendo cierto esquema iterativo de actualización (usualmente tomar un nodo aleatorio y actualizar los mensajes a sus vecinos) con respectos a los mensajes anteriores se computan los nuevos mensajes. Si el modelo gráfico posee forma de árbol, existe un esquema de actualización que garantiza convergencia (ver siguiente sección). Si se cumple que el proceso converge, usualmente que los mensajes dejen de cambiar, que no se garantiza en grafos generales, es posible obtener la distribución marginal computada por la propagación de creencias.
La distribución marginal estimada de cada nodo variable es proporcional al producto de los mensajes de los nodos vecinos.En el caso de los nodos función la distribución conjunta de las variables que son parte de su vecindad es proporcional al mensaje recibido por el nodo.donde y son constantes de normalización






Propagación de creencias sobre árboles

En el caso de que el modelo gráfico sea un árbol, el algoritmo de propagación de creencias computa de manera exacta los marginales, siguiendo un esquema específico de actualización de mensaje, este esquema termina luego de 2 iteraciones. El esquema de actualización se describe a continuación:
Antes de comenzar, es seleccionado un nodo como nodo raíz y cualquier nodo no raíz que se encuentra conectado a un solo nodo es llamado hoja.
En la primera iteración los mensajes son inicialmente computados en las hojas y “suben” en la estructura hasta alcanzar la raíz. La estructura de árbol garantiza que es posible obtener todos los mensajes de los vecinos de cada nodo, excepto de uno de ellos, que será el que recibirá el mensaje.
La segunda iteración se compone de enviar los mensajes de forma contraria, comenzando en la raíz y haciéndolos “descender” hasta las hojas. El algoritmo termina cuando todas las hojas hayan recibido su mensaje.[8]
Como ejemplo concreto del cálculo exacto de los marginales en árboles consideremos la distribución de probabilidad dada en la figura superior. Usando repetidamente las ecuaciones de propagación de creencias encontramos que:






Que es exactamente la definición de probabilidad marginal y su factor de normalización .

Aproximación para grafos generales
El algoritmo de propagación de creencias fue diseñado para modelos gráficos acíclicos (árboles), se ha comprobado que es posible usarlo en grafos generales, este algoritmo usualmente es llamado algoritmo “cíclico” de propagación de creencias debido a que estos grafos contienen ciclos. La inicialización y los esquemas de actualización son diferentes del esquema anterior visto en árboles, debido a que estos grafos pueden no contener hojas. Es necesario establecer un número de iteración mucho mayor que las dos iteraciones necesarias para convergencia en árboles.
La condición general bajo la cual el algoritmo de propagación de creencias puede converger no es totalmente entendida, es conocido que un grafo con un solo ciclo converge en la mayoría de los casos, pero la estimación de los marginales puede ser incorrecta. Existen varias condiciones suficientes, pero no necesarias, sobre la convergencia en un grafo con ciclos; también se conocen grafos en los cuales no resulta posible la convergencia. Técnicas como EXIT Chart pueden proveer una visualización aproximada del progreso de la propagación de creencias para la convergencia.
Existen otros métodos de aproximación para el cálculo de marginales como los métodos Variacionales y los métodos de Monte Carlo. Un método para el computo de marginales en grafos generales es el algoritmo junction tree. Este es la aplicación de Belief Propagation sobre un grafo modificado a través de la eliminación de ciclos agrupándolos en un nodo para obtener la estructura de árbol.[9]
Algoritmos similares y complejidad computacional
Un algoritmo similar al de propagación de creencias es el llamado algoritmo de Viterbi, el cual resuelve el problema de maximización o de explicación más probable. En vez de solucionar el cómputo del marginal, el objetivo radica en el cálculo de los valores que maximiza la función global es decir los valores más probables en una configuración de . La diferencia fundamental radica en reemplazar la suma por la maximización.



La propagación de creencias computa, o en grafos generales aproxima, probabilidades marginales. En algunos problemas, los marginales proveen la solución de manera directa, por ejemplo en corrección de errores en códigos,[10] en el problema de emparejamiento,[11][12] o en modelo de Ising con campo aleatorio a temperatura cero,[13][14] etc.
En los problemas de satisfacción de restricciones, en general, los marginales no brindan de forma directa información acerca de la solución. Por ejemplo en coloreado de grafos, con colores, las ecuaciones de BP siempre convergen a marginales uniformes , esta es la solución correcta pero no brinda ninguna información útil. Un intento por solucionar esto es el algoritmo de propagación de creencias con decimación.


En cada ciclo del algoritmo con decimación, las ecuaciones de propagación de creencias son actualizadas hasta que estas convergen o se alcanza el número máximo de iteraciones. Luego se sigue alguna estrategia de elección de variables, dos de ellas son:
- Decimación uniforme: Escoger una variable con probabilidad uniforme y asignar un valor según la probabilidad estimada por la propagación de creencias.
- Decimación maximal: Encontrar la variable con mayor probabilidad hacia algún estado y asignarle dicho estado.
El algoritmo descrito posee una complejidad cuadrática. En la práctica una cantidad pequeña de variables deben ser decimadas en cada iteración, con el objetivo de reducir esta complejidad a tiempo linear, si el tiempo máximo de convergencia crece como . En el problema de coloreado de grafos con 3 y 4 colores, la propagación de creencias basada en la decimación mejora la estimación de marginales respecto de la propagación de creencias.[15]

El cálculo de marginales pertenece a la clase #P-Completo, esta clase se cree que posee problemas más difícil que la clases NP-Completo,[16] y el de maximización a la clase NP-Completo. Ambos problemas pertenecen a la clase NP-Hard.
Es posible reducir la memoria necesaria, o complejidad espacial, del algoritmo de propagación de creencias a través del uso del algoritmo de Islas, a costo de un pequeño aumento en la complejidad temporal.
Relación con energía libre.
La propagación de creencias está relacionada con el cálculo de la energía libre en termodinámica.[2] Supongamos que es la verdadera distribución de probabilidad de un sistema, y esta cumple la ley de Boltzmann.

y es el inverso de la temperatura.

La energía del estado es:


La energía libre de este sistema es:

La determinación de esta permite el análisis de diferentes características del sistema entre ellas: la energía promedio de una configuración para una temperatura dada. Por esto se han desarrollado varias aplicaciones para la aproximación a este valor.
Supongamos que introducimos una distribución de probabilidad de prueba y su correspondiente energía libre variacional definida por:


Donde es la energía variacional promedio


y es la entropía variacional


Según las definiciones anteriores

Donde

Es la "medida" de Kullback–Leibler entre y . Esta siempre es no negativa y es igual a cero si y solo si . Minimizar la energía libre variacional respecto a la distribución de prueba es un procedimiento exacto para la determinación de . y recuperación de . Cuando el tamaño del sistema posee dimensiones grandes este procedimiento se vuelve intratable. Es posible establecer una cota superior a a través de la minimización de imponiendo una restricción sobre las posibles familias de distribuciones de probabilidad que puede ser . Esta es la idea principal de la aproximación de campo medio.




Una de las elecciones más utilizadas es suponer que es factorizable sobre las variables del sistema:

Donde cada es una función de probabilidad sobre una única variable. Usando esta y la función de energía para el factor graph, es posible computar la energía libre en la aproximación de campo medio.






Es posible considerar el uso de otras familias de funciones más complejas, para reducir la cota superior de la aproximación de campo medio respecto a la energía libre.[2]
Es posible mostrar que los mensajes luego de la convergencia de la propagación de creencias son útiles en la construcción de configuraciones que minimizan la energía libre de dicho sistema, si el modelo gráfico posee estructura de árbol, en caso de tener ciclos el modelo gráfico solo se puede afirmar que es un punto estacionario en la aproximación de energía libre.
Algoritmo generalizado de propagación de creencias
El algoritmo de propagación de creencias se suele representar como un algoritmo de paso de mensaje entre los nodos del modelo gráfico. En el caso de factor graph los mensajes son trasmitidos entre los nodos variables y los nodos funciones. Considerando el envió de mensajes entre regiones (conjuntos que pueden tener más de un nodo) es una forma de generalizar este algoritmo. Existen varias maneras de definir las regiones del modelo gráfico que intercambiaran mensajes; una de ellas plantea que una región es un conjunto de variables y nodos factores tal que si un nodo factor pertenece a una región, entonces las variables en su vecindario también pertenecen a esta región. Uno de estos métodos usa las ideas introducidas por Kikuchi en la literatura física y es conocido como el Método de variación de cluster de Kikuchi.
Los métodos de generalización de propagación de creencias permiten mejorar las aproximaciones y las propiedades de convergencia, a costo de un incremento en la complejidad, según la elección de las regiones.[2][6] La elección de regiones que optimicen la complejidad es un tema de investigación actualmente abierto.
Mejoras en las aproximaciones de propagación de creencias son alcanzables a través de la ruptura de las réplicas en la distribución de los campos (mensajes). Esta generalización permitió la creación de un nuevo tipo de algoritmo llamado Survey Propagation el cual ha probado ser muy útil en problemas en la clase NP-Completos como satisfacibilidad booleana[17] y cubrimiento mínimo en grafos.[18] Es conocido que el algoritmo de propagación de sondeos es la aplicación del algoritmo de propagación de creencias sobre una clase especial de objetos combinatorios llamados covers, en su aplicación al problema de la satisfacibilidad booleana.[19][20]
Propagación de creencias con distribución gaussiana
La propagación de creencias con distribución gaussiana es una variante del algoritmo de propagación de creencias donde las distribuciones de los mensajes son gaussianas. El primer trabajo en analizar este modelo especial fue realizado por Weiss y Freeman.[21]

Donde es una constante de normalización, es matriz simétrica definida positiva y es un vector de desplazamiento.


Equivalentemente puede ser mostrado que usando el modelo gaussiano, la solución al problema de marginalización es equivalente al problema MAP.

Este problema es además equivalente al problema de minimización cuadrática:

Que es a la vez equivalente al sistema de ecuación linear

La convergencia de la propagación de creencias con distribución gaussiana es relativamente más fácil de analizar (respecto al modelo general de propagación de creencias) y existen dos condiciones suficientes de convergencia. La primera de estas fue formulada por Weiss y colaboradores en el 2000, que garantiza la convergencia cuando la matriz A es diagonalmente dominante, y la segunda fue formulada por Johnson y colaboradores en 2006 que asegura la convergencia cuando el radio espectral de la matriz cumple

Donde y es la matriz identidad.


Posteriormente Su y Wu establecieron condiciones necesarias y suficientes.[22]
Es posible vincular el algoritmo de propagación de creencias con distribución gaussiana al dominio de álgebra lineal y fue mostrado como un algoritmo iterativo para la solución de sistemas de ecuaciones lineales . Experimentos muestran que la propagación de creencias con distribución gaussiana converge más rápido que otros métodos iterativos clásicos como el método de Jacobi, el método de Gauss-Seidel[23] y posee buena tolerancia a los problemas numéricos del método del gradiente conjugado de precondición.[24]
Referencias
- G. Gallager, R. (1963). «Low-Density Parity-Chek Codes». MIT Press.
- Yedidia, J.S; Freeman; Weiss, W.T (Julio de 2005). «Constructing free-energy approximations and generalized belief propagation algorithms». www.merl.com.
- Braunstein, Alfredo (2002). «Survey Propagation». PhD Tesis.
- Braunstein, Alfredo; Mezard; Zecchina (2005). «Survey propagation: an algorithm for satisfiability. Random Structures and Algorithms». Random Structures & Algorithms - Wiley Online Library. doi:10.1002/rsa.20057.
- Pearl (1988). «Probabilistic Reasoning in Intelligent Systems». MorganKaufmann. (requiere registro).
- Yedidia; Freeman; Weiss (enero de 2002). «Understanding Belief Propagation and its Generalizations». Book Exploring artificial intelligence in the new millennium Pages 239 - 269 Morgan Kaufmann Publishers Inc. San Francisco, CA, USA ©2003. ISBN 1-55860-811-7.
- Kschischang; Frey; Loeliger (Feb 2001). «Factor graphs and the sum-product algorithm». IEEE Trans. Inf. Theory, vol. 47, no. 2, pp. 498–519.
- Mézard; Montanari (2008). «Information, Physics and Computation». Oxford University Press, Inc. New York, NY, USA ©2009. ISBN 978-0-19-857083-7.
- Ajiand; McEliece (Marzo de 2000). «The generalized distributive law and free energy minimization». Journal IEEE Transactions on Information Theory archive Volume 46 Issue 2, March 2000 Page 325-343.
- Gallager (1968). «Information theory and reliable communication». John Wiley and Sons, New York.
- Bayati; Shah; Sharma (2005). «Maximum weight matching via max product belief propagation». Proc. IEEE Int. Symp. Information Theory.
- Bayati; Shah; Sharma (2006). «A simpler max-product maximum weight matching algorithm and the auction algorithm». Proc. IEEE Int. Symp. Information Theory.
- Kolmogorov; Wainwright (2005). «On the optimality of tree reweighted max-product message passing». In 21st Conference on Uncertainty in Artificial Intelligence (UAI).
- Chertkov (2008). «Exactness of belief propagation for some graphical models with loops». arXiv:0801.0341v1 [cond-mat.stat-mech].
- Zdeborova (2008). «Statistical Physics of Hard Optimization Problems». PhD Tesis.
- Kroc; Sabharwal. «Survey Propagation Revisited». www.cs.cornell.edu.
- Mezard; Parisi; Zecchina (2002). «Analytic and Algorithmic Solution of Random Satisfiability Problems». Science.
- Weigt; Zhou (2008). «Message passing for vertex covers». http://arxiv.org.
- Braunstein; Zecchina (2004). «Survey propagation as local equilibrium equations». http://arXiv.org/.
- Maneva; Mossel; Wainwright (2005). «A new look at survey propagation and its generalizations». www.eecs.berkeley.edu.
- Weiss; Freeman (Octubre de 2001). «Correctness of Belief Propagation in Gaussian Graphical Models of Arbitrary Topology». www.mitpressjournals.org.
- Su; Wu. «On convergence conditions of Gaussian belief propagation». IEEE Trans. Signal Process.
- Bickson; Dolev. «Linear Detection via Belief Propagation». In the 45th Annual Allerton Conference on Communication, Control, and Computing.
- Bickson; Tock (Julio de 2009). «Distributed large scale network utility maximization». In the International symposium on information theory (ISIT).
| Control de autoridades |
|
|---|
 Datos: Q4060686
Datos: Q4060686