Distribución χ²
En teoría de la probabilidad y en estadística, la distribución ji al cuadrado (también llamada distribución de Pearson o distribución ) con grados de libertad es la distribución de la suma del cuadrado de variables aleatorias independientes con distribución normal estándar. La distribución chi cuadrada es un caso especial de la distribución gamma y es una de las distribuciones de probabilidad más usadas en Inferencia Estadística, principalmente en pruebas de hipótesis y en la construcción de intervalos de confianza.



| Distribución χ² (ji al cuadrado) | ||
|---|---|---|
 Función de densidad de probabilidad | ||
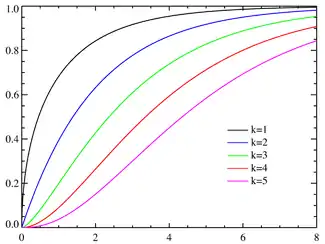 Función de distribución de probabilidad | ||
| Parámetros | grados de libertad | |
| Dominio | ||
| Función de densidad (pdf) | ||
| Función de distribución (cdf) | ||
| Media | ||
| Mediana | aproximadamente | |
| Moda | si | |
| Varianza | ||
| Coeficiente de simetría | ||
| Curtosis | ||
| Entropía | ||
| Función generadora de momentos (mgf) | para | |
| Función característica | ||















La distribución chi-cuadrado se utiliza en las pruebas chi-cuadrado comunes de bondad de ajuste de una distribución observada a una teórica, la independencia de dos criterios de clasificación de datos cualitativos, y en la estimación del intervalo de confianza para una desviación estándar poblacional de una distribución normal a partir de una desviación estándar muestral. Muchas otras pruebas estadísticas también utilizan esta distribución, como la análisis de varianza por rangos de Friedman.
Introducción
La distribución chi-cuadrado se utiliza principalmente en las pruebas de hipótesis, y en menor medida para los intervalos de confianza para la varianza de la población cuando la distribución subyacente es normal. A diferencia de otras distribuciones más conocidas como la distribución normal y la distribución exponencial, la distribución chi-cuadrado no se aplica tan a menudo en la modelización directa de fenómenos naturales. Surge en las siguientes pruebas de hipótesis, entre otras:
- Prueba de chi-cuadrado de independencia en tablas de contingencia
- Prueba ji-cuadrado de bondad de ajuste de datos observados a distribuciones hipotéticas
- Prueba de razón de verosimilitud para modelos anidados
- Prueba de Mantel–Cox en análisis de supervivencia
- Cochran-Mantel-Haenszel test para tablas de contingencia estratificadas
- Prueba de Wald
- Prueba de puntuación
También es un componente de la definición de la t-distribution y la F-distribution utilizadas en pruebas t, análisis de varianza y análisis de regresión.
La razón principal por la que la distribución chi-cuadrado se utiliza ampliamente en las pruebas de hipótesis es su relación con la distribución normal. Muchas pruebas de hipótesis utilizan un estadístico de prueba, como el t-estadístico en una prueba t. Para estas pruebas de hipótesis, a medida que aumenta el tamaño de la muestra, n, la distribución muestral del estadístico de prueba se aproxima a la distribución normal (teorema del límite central). Dado que el estadístico de prueba (como t) se distribuye asintóticamente con normalidad, siempre que el tamaño de la muestra sea suficientemente grande, la distribución utilizada para el contraste de hipótesis puede aproximarse mediante una distribución normal. La comprobación de hipótesis utilizando una distribución normal se entiende bien y es relativamente fácil. La distribución chi-cuadrado más sencilla es el cuadrado de una distribución normal estándar. Por lo tanto, siempre que se pueda utilizar una distribución normal para una prueba de hipótesis, se puede utilizar una distribución chi-cuadrado.
Supongamos que es una variable aleatoria muestreada de la distribución normal estándar, donde la media es y la varianza es : . Consideremos ahora la variable aleatoria . La distribución de la variable aleatoria es un ejemplo de distribución chi-cuadrado: . El subíndice 1 indica que esta distribución chi-cuadrado particular se construye a partir de sólo 1 distribución normal estándar. Se dice que una distribución chi-cuadrado construida elevando al cuadrado una única distribución normal estándar tiene 1 grado de libertad. Por lo tanto, a medida que aumenta el tamaño de la muestra para una prueba de hipótesis, la distribución de la estadística de la prueba se aproxima a una distribución normal. Al igual que los valores extremos de la distribución normal tienen baja probabilidad (y dan valores p pequeños), los valores extremos de la distribución chi-cuadrado tienen baja probabilidad.






Una razón adicional por la que la distribución chi-cuadrado se utiliza ampliamente es que aparece como la distribución de muestras grandes de la pruebas de razón de verosimilitud generalizada (LRT).[1] Las LRT tienen varias propiedades deseables; en particular, las LRT simples suelen proporcionar la mayor potencia para rechazar la hipótesis nula (lema de Neyman-Pearson) y esto conduce también a propiedades de optimalidad de las LRT generalizadas. Sin embargo, las aproximaciones normal y chi-cuadrado sólo son válidas asintóticamente. Por este motivo, es preferible utilizar la distribución t en lugar de la aproximación normal o la aproximación chi-cuadrado para un tamaño de muestra pequeño. Del mismo modo, en los análisis de tablas de contingencia, la aproximación chi-cuadrado será pobre para un tamaño de muestra pequeño, y es preferible utilizar la prueba exacta de Fisher. Ramsey demuestra que la prueba binomial exacta es siempre más potente que la aproximación normal.[2]
Lancaster muestra las conexiones entre las distribuciones binomial, normal y chi-cuadrado, como sigue.[3] De Moivre y Laplace establecieron que una distribución binomial podía ser aproximada por una distribución normal. Específicamente demostraron la normalidad asintótica de la variable aleatoria

donde es el número observado de éxitos en ensayos, donde la probabilidad de éxito es , y .




Elevando al cuadrado ambos lados de la ecuación se obtiene

Utilizando , , y , esta ecuación puede reescribirse como



La expresión de la derecha es de la forma que Karl Pearson generalizaría a la forma

donde
= estadístico de prueba acumulativo de Pearson, que se aproxima asintóticamente a una distribución ; = el número de observaciones de tipo ; = la frecuencia esperada (teórica) del tipo , afirmada por la hipótesis nula de que la fracción del tipo en la población es ; y = el número de celdas de la tabla.





En el caso de un resultado binomial (lanzar una moneda al aire), la distribución binomial puede aproximarse mediante una distribución normal (para suficientemente grande). Dado que el cuadrado de una distribución normal estándar es la distribución chi-cuadrado con un grado de libertad, la probabilidad de un resultado como 1 cara en 10 intentos puede aproximarse utilizando directamente la distribución normal o la distribución chi-cuadrado para la diferencia normalizada al cuadrado entre el valor observado y el esperado. Sin embargo, muchos problemas implican más de los dos resultados posibles de una binomial y, en su lugar, requieren 3 o más categorías, lo que da lugar a la distribución multinomial. Al igual que de Moivre y Laplace buscaron y encontraron la aproximación normal a la binomial, Pearson buscó y encontró una aproximación normal multivariante degenerada a la distribución multinomial (los números de cada categoría suman el tamaño total de la muestra, que se considera fijo). Pearson demostró que la distribución chi-cuadrado surgía de dicha aproximación normal multivariante a la distribución multinomial, teniendo muy en cuenta la dependencia estadística (correlaciones negativas) entre los números de observaciones en diferentes categorías.[3]
Definición
Como la suma de normales estándar
Sean variables aleatorias independientes tales que para entonces la variable aleatoria definida por





tiene una distribución chi cuadrada con grados de libertad.
Notación
Si la variable aleatoria continua tiene una distribución Chi Cuadrada con grados de libertad entonces escribiremos o .


Función de densidad
Si entonces la función de densidad de la variable aleatoria es

para donde es la función gamma.


Función de distribución acumulada
Si entonces su función de distribución está dada por

donde es la función gamma incompleta.

En particular cuando entonces esta función toma la forma


Propiedades
Si entonces la variable aleatoria satisface algunas propiedades.
![{\displaystyle \operatorname {E} [X]=k}](../I/a8be88fc71e3b0523ea2e85edf276e61bfdb6daf.svg)



Teorema
Sea una muestra aleatoria proveniente de una población con distribución entonces


- y el vector son independientes.
- y son independientes.
- .
- y .




![{\displaystyle \operatorname {E} [S^{2}]=\sigma ^{2}}](../I/60b991e76d21d27a2eaa961002c06c4722174a51.svg)

donde

y

son la media y varianza de la muestra aleatoria respectivamente.
Intervalos de confianza para muestras de la distribución normal
Intervalo para la varianza
Sean una muestra aleatoria proveniente de una población con distribución donde y son desconocidos.


Se tiene que
Sean tales que

![{\displaystyle \operatorname {P} [\chi _{n-1,\alpha /2}<Y<\chi _{n-1,1-\alpha /2}]=1-\alpha }](../I/ee5b5ac99b32f1cf69be5ed96a86b8d9e4c94dc5.svg)
siendo entonces

![{\displaystyle {\begin{aligned}&\operatorname {P} \left[\chi _{n-1,\alpha /2}<{\frac {(n-1)S^{2}}{\sigma ^{2}}}<\chi _{n-1,1-\alpha /2}\right]=1-\alpha \\&\operatorname {P} \left[{\frac {1}{\chi _{n-1,\alpha /2}}}>{\frac {\sigma ^{2}}{(n-1)S^{2}}}>{\frac {1}{\chi _{n-1,1-\alpha /2}}}\right]=1-\alpha \\&\operatorname {P} \left[{\frac {(n-1)S^{2}}{\chi _{n-1,1-\alpha /2}}}<\sigma ^{2}<{\frac {(n-1)S^{2}}{\chi _{n-1,\alpha /2}}}\right]=1-\alpha \end{aligned}}}](../I/4e165a680994da44b96cc6f47d7e2e0c6678f7fb.svg)
por lo tanto un intervalo de de confianza para está dado por


Distribuciones relacionadas
- La distribución con grados de libertad es un caso particular de la distribución gamma pues si

- entonces .
- Cuando k es suficientemente grande, como consecuencia del teorema del límite central, puede aproximarse por una distribución normal:

Aplicaciones
La distribución χ² tiene muchas aplicaciones en inferencia estadística. La más conocida es la denominada prueba χ², utilizada como prueba de independencia y como prueba de buen ajuste y en la estimación de varianzas. Pero también está involucrada en el problema de estimar la media de una población normalmente distribuida y en el problema de estimar la pendiente de una recta de regresión lineal, a través de su papel en la distribución t de Student.
Aparece también en todos los problemas de análisis de varianza por su relación con la distribución F de Snedecor, que es la distribución del cociente de dos variables aleatorias independientes con distribución χ².
Véase esto también
Métodos computacionales
Tabla de valores χ2 vs valores p
El valor p es la probabilidad de observar un estadístico de prueba "al menos" como extremo en una distribución de ji-cuadrado. Por lo tanto, dado que la función de distribución acumulativa (CDF) para los grados de libertad apropiados (df, del inglés degree of freedom) da la probabilidad de haber obtenido un valor menos extremo que este punto, restando el valor de CDF de 1 da el valor p. Un valor p bajo, por debajo del nivel de significación elegido, indica significación estadística, es decir, evidencia suficiente para rechazar la hipótesis nula. Un nivel de significancia de 0.05 se usa a menudo como el punto de corte entre resultados significativos y no significativos.
La siguiente tabla da un número de valores p que coinciden con para los primeros 10 grados de libertad.
| Grados de libertad (df) | valor [4] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.004 | 0.02 | 0.06 | 0.15 | 0.46 | 1.07 | 1.64 | 2.71 | 3.84 | 6.63 | 10.83 |
| 2 | 0.10 | 0.21 | 0.45 | 0.71 | 1.39 | 2.41 | 3.22 | 4.61 | 5.99 | 9.21 | 13.82 |
| 3 | 0.35 | 0.58 | 1.01 | 1.42 | 2.37 | 3.66 | 4.64 | 6.25 | 7.81 | 11.34 | 16.27 |
| 4 | 0.71 | 1.06 | 1.65 | 2.20 | 3.36 | 4.88 | 5.99 | 7.78 | 9.49 | 13.28 | 18.47 |
| 5 | 1.14 | 1.61 | 2.34 | 3.00 | 4.35 | 6.06 | 7.29 | 9.24 | 11.07 | 15.09 | 20.52 |
| 6 | 1.63 | 2.20 | 3.07 | 3.83 | 5.35 | 7.23 | 8.56 | 10.64 | 12.59 | 16.81 | 22.46 |
| 7 | 2.17 | 2.83 | 3.82 | 4.67 | 6.35 | 8.38 | 9.80 | 12.02 | 14.07 | 18.48 | 24.32 |
| 8 | 2.73 | 3.49 | 4.59 | 5.53 | 7.34 | 9.52 | 11.03 | 13.36 | 15.51 | 20.09 | 26.12 |
| 9 | 3.32 | 4.17 | 5.38 | 6.39 | 8.34 | 10.66 | 12.24 | 14.68 | 16.92 | 21.67 | 27.88 |
| 10 | 3.94 | 4.87 | 6.18 | 7.27 | 9.34 | 11.78 | 13.44 | 15.99 | 18.31 | 23.21 | 29.59 |
| Valor p (probabilidad) | 0.95 | 0.90 | 0.80 | 0.70 | 0.50 | 0.30 | 0.20 | 0.10 | 0.05 | 0.01 | 0.001 |
Estos valores se pueden calcular evaluando la función cuantil (también conocida como "FDC inversa" o "ICDF") de la distribución ji-cuadrado;[5] por ejemplo, el χ2 ICDF de p = 0.05 y df = 7 rinde 2.1673 ≈ 2.17 como en la tabla anterior, observando que 1 – p es el valor p de la tabla.
Historia
Esta distribución fue descrita por primera vez por el geodésico y estadístico alemán Friedrich Robert Helmert en artículos de 1875–6,[6][7] donde calculó la distribución muestral de la varianza muestral de una población normal. Así, en alemán, esto se conocía tradicionalmente como Helmert'sche ("Helmertiano") o "distribución de Helmert".
La distribución fue redescubierta de forma independiente por el matemático inglés Karl Pearson en el contexto de la bondad de ajuste, para lo cual desarrolló su prueba de ji-cuadrado de Pearson, publicada en 1900, con una tabla calculada de valores publicados en (Elderton, 1902), recogida en (Pearson, 1914, Table XII). El nombre "ji-cuadrado" deriva en última instancia de la abreviatura de Pearson para el exponente en una distribución normal multivariada con la letra griega ji, escribiendo −½χ2 por lo que aparecería en la notación moderna como −½xTΣ−1x (Σ siendo la matriz de covarianza).[8] Sin embargo, la idea de una familia de "distribuciones de ji-cuadrado" no se debe a Pearson, sino que surgió como un desarrollo posterior debido a Fisher en la década de 1920.[6]
Véase también
Referencias
- Westfall, Peter H. (2013). Understanding Advanced Statistical Methods. Boca Raton, FL: CRC Press. ISBN 978-1-4665-1210-8.
- Ramsey, PH (1988). «Evaluación de la aproximación normal a la prueba binomial». Journal of Educational Statistics 13 (2): 173-82. JSTOR 1164752.
- Lancaster, H.O. (1969), La distribución chi-cuadrado, Wiley.
- Chi-Squared Test Archivado el 18 de noviembre de 2013 en Wayback Machine. Table B.2. Dr. Jacqueline S. McLaughlin at The Pennsylvania State University. In turn citing: R. A. Fisher and F. Yates, Statistical Tables for Biological Agricultural and Medical Research, 6th ed., Table IV. Two values have been corrected, 7.82 with 7.81 and 4.60 with 4.61
- R Tutorial: Chi-squared Distribution
- Hald, 1998, 27. Sampling Distributions under Normality.
- F. R. Helmert, "Ueber die Wahrscheinlichkeit der Potenzsummen der Beobachtungsfehler und über einige damit im Zusammenhange stehende Fragen", Zeitschrift für Mathematik und Physik 21, 1876, pp. 192–219
- R. L. Plackett, Karl Pearson and the Chi-Squared Test, International Statistical Review, 1983, 61f. See also Jeff Miller, Earliest Known Uses of Some of the Words of Mathematics.
Bibliografía
- Hald, Anders (1998). A history of mathematical statistics from 1750 to 1930. New York: Wiley. ISBN 978-0-471-17912-2.
- Elderton, William Palin (1902). «Tables for Testing the Goodness of Fit of Theory to Observation». Biometrika 1 (2): 155-163. doi:10.1093/biomet/1.2.155.
- Hazewinkel, Michiel, ed. (2001), «Chi-squared distribution», Encyclopaedia of Mathematics (en inglés), Springer, ISBN 978-1556080104.
- Pearson, Karl (1914). «On the probability that two independent distributions of frequency are really samples of the same population, with special reference to recent work on the identity of Trypanosome strains». Biometrika 10: 85-154. doi:10.1093/biomet/10.1.85.
Enlaces externos
- Calculadora e la probabilidad de una distribución de Pearson con R (lenguaje de programación)
- DynStats Archivado el 30 de marzo de 2018 en Wayback Machine.: Laboratorio estadístico en línea con calculadora de funciones de distribución
 Datos: Q243462
Datos: Q243462 Multimedia: Chi-square distribution / Q243462
Multimedia: Chi-square distribution / Q243462