Méthode des moindres carrés
La méthode des moindres carrés, indépendamment élaborée par Legendre et Gauss au début du XIXe siècle, permet de comparer des données expérimentales, généralement entachées d’erreurs de mesure, à un modèle mathématique censé décrire ces données.
| Nature | |
|---|---|
| Sous-classe de | |
| Inventeurs | |
| Décrit par |
The Elements of Statistical Learning (d), Dictionnaire encyclopédique Brockhaus et Efron, Nouveau Dictionnaire encyclopédique (d), encyclopédie Otto (d) |
Ce modèle peut prendre diverses formes. Il peut s’agir de lois de conservation que les quantités mesurées doivent respecter. La méthode des moindres carrés permet alors de minimiser l’impact des erreurs expérimentales en « ajoutant de l’information » dans le processus de mesure.
Présentation de la méthode
Dans le cas le plus courant, le modèle théorique est une famille de fonctions f (x ; θ) d’une ou plusieurs variables muettes x, indexées par un ou plusieurs paramètres θ inconnus. La méthode des moindres carrés permet de sélectionner parmi ces fonctions celle qui reproduit le mieux les données expérimentales. On parle dans ce cas d’ajustement par la méthode des moindres carrés. Si les paramètres θ ont un sens physique, la procédure d’ajustement donne également une estimation indirecte de la valeur de ces paramètres.
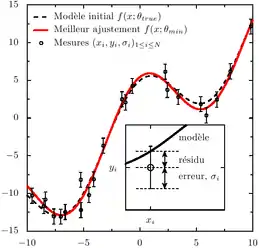
La méthode consiste en une prescription (initialement empirique), qui est que la fonction f (x ; θ) qui décrit « le mieux » les données est celle qui minimise la somme quadratique des déviations des mesures aux prédictions de f (x ; θ). Si, par exemple, nous disposons de N mesures (yi)i = 1,...,N, les paramètres θ « optimaux » au sens de la méthode des moindres carrés sont ceux qui minimisent la quantité :

où les ri(θ) sont les résidus du modèle, i.e. ri(θ) est l'écart entre la mesure yi et la prédiction f (xi ; θ) donnée par le modèle. S(θ) peut être considéré comme une mesure de la distance entre les données expérimentales et le modèle théorique qui prédit ces données. La prescription des moindres carrés commande que cette distance soit minimale.
Si, comme c'est généralement le cas, on dispose d'une estimation de l'écart-type σi du bruit qui affecte chaque mesure yi, on l'utilise pour « pondérer » la contribution de la mesure au χ2. Une mesure aura d'autant plus de poids que son incertitude sera faible :

La quantité wi, inverse de la variance du bruit affectant la mesure yi, est appelée poids de la mesure yi. La quantité ci-dessus est appelée khi carré ou khi-deux. Son nom vient de la loi statistique qu'elle décrit, si les erreurs de mesure qui entachent les yi sont distribuées suivant une loi normale (ce qui est très courant). Dans ce dernier cas, la méthode des moindres carrés permet de plus d’estimer quantitativement l’adéquation du modèle aux mesures, pour peu que l'on dispose d'une estimation fiable des erreurs σi. Si le modèle d’erreur est non gaussien, il faut généralement recourir à la méthode du maximum de vraisemblance, dont la méthode des moindres carrés est un cas particulier.
Son extrême simplicité fait que cette méthode est très couramment utilisée de nos jours en sciences expérimentales. Une application courante est le lissage des données expérimentales par une fonction empirique (fonction linéaire, polynômes ou splines). Cependant son usage le plus important est probablement la mesure de quantités physiques à partir de données expérimentales. Dans de nombreux cas, la quantité que l’on cherche à mesurer n’est pas observable et n’apparaît qu’indirectement comme paramètre θ d’un modèle théorique f (x ; θ). Dans ce dernier cas de figure, il est possible de montrer que la méthode des moindres carrés permet de construire un estimateur de θ, qui vérifie certaines conditions d’optimalité. En particulier, lorsque le modèle f (x ; θ) est linéaire en fonction de θ, le théorème de Gauss-Markov garantit que la méthode des moindres carrés permet d'obtenir l'estimateur non biaisé le moins dispersé. Lorsque le modèle est une fonction non linéaire des paramètres θ l'estimateur est généralement biaisé. Par ailleurs, dans tous les cas, les estimateurs obtenus sont extrêmement sensibles aux points aberrants : on traduit ce fait en disant qu’ils sont non robustes. Plusieurs techniques permettent cependant de rendre plus robuste la méthode.
Histoire

Le jour du Nouvel An de 1801, l'astronome italien Giuseppe Piazzi a découvert l'astéroïde Cérès[1]. Il a alors pu suivre sa trajectoire jusqu'au [2]. Durant cette année, plusieurs scientifiques ont tenté de prédire sa trajectoire sur la base des observations de Piazzi (à cette époque, la résolution des équations non linéaires de Kepler de la cinématique était un problème très difficile). La plupart des prédictions furent erronées ; et le seul calcul suffisamment précis pour permettre à Zach, un astronome allemand, de localiser à nouveau Cérès à la fin de l'année, fut celui de Carl Friedrich Gauss, alors âgé de 24 ans (il avait déjà réalisé l'élaboration des concepts fondamentaux en 1795, lorsqu'il était alors âgé de 18 ans). Mais sa méthode des moindres carrés ne fut publiée qu'en 1809, lorsqu'elle parut dans le tome 2 de ses travaux sur la mécanique céleste, Theoria Motus Corporum Coelestium in sectionibus conicis solem ambientium. Le mathématicien français Adrien-Marie Legendre a développé indépendamment la même méthode en 1805. Le mathématicien américain Robert Adrain a publié en 1808 une formulation de la méthode.
En 1829, Gauss a pu donner les raisons de l'efficacité de cette méthode ; en effet, la méthode des moindres carrés est justement optimale à l'égard de bien des critères. Cet argument est maintenant connu sous le nom de théorème de Gauss-Markov.
Formalisme
Moyenne d'une série de mesures indépendantes
L'exemple le plus simple d'ajustement par la méthode des moindres carrés est probablement le calcul de la moyenne m d'un ensemble de mesures indépendantes (yi)i = 1,...,N entachées d'erreurs gaussiennes. Autrement dit, on veut estimer m dans la relation

pour i = 1,...,N et où εi est un bruit blanc.
La prescription des moindres carrés revient à minimiser la quantité :

où est le poids de la mesure yi. Statistiquement, σi2 s'interprète comme la variance de la variable aléatoire εi. On parle alors de moindres carrés pondérés. Lorsqu'on ne tient pas compte de la pondération, on pose simplement wi = 1 et on parle de moindres carrés ordinaires (MCO).

La quantité χ2(m), ou somme des carrés des résidus, est une forme quadratique définie positive. Son minimum se calcule par différenciation : grad χ2(m) = 0. Cela donne la formule classique :

Autrement dit, l'estimateur par moindres carrés de la moyenne m d'une série de mesures entachées d'erreurs gaussiennes (connues) est leur moyenne pesée (ou pondérée), c'est-à-dire leur moyenne empirique dans laquelle chaque mesure est pondérée par l'inverse du carré de son incertitude. Le théorème de Gauss-Markov garantit qu'il s'agit du meilleur estimateur linéaire non biaisé de m.
La moyenne estimée m fluctue en fonction des séries de mesures yi effectuées. Comme chaque mesure est affectée d'une erreur aléatoire, on conçoit que la moyenne d'une première série de N mesures différera de la moyenne d'une seconde série de N mesures, même si celles-ci sont réalisées dans des conditions identiques. Il importe de pouvoir quantifier l'amplitude de telles fluctuations, car cela détermine la précision de la détermination de la moyenne m. Chaque mesure yi peut être considérée comme une réalisation d'une variable aléatoire Yi, de moyenne yi et d'écart-type σi. L'estimateur de la moyenne obtenu par la méthode des moindres carrés, combinaison linéaire de variables aléatoires, est lui-même une variable aléatoire :

L'écart-type des fluctuations de M est donné par (combinaison linéaire de variables aléatoires indépendantes) :

Sans grande surprise, la précision de la moyenne d'une série de N mesures est donc déterminée par le nombre de mesures, et la précision de chacune de ces mesures. Dans le cas où chaque mesure est affectée de la même incertitude σi = σ la formule précédente se simplifie en :

La précision de la moyenne s’accroît donc comme la racine carrée du nombre de mesures. Par exemple, pour doubler la précision, il faut quatre fois plus de données ; pour la multiplier par 10, il faut 100 fois plus de données.
Régression linéaire
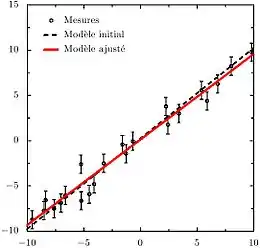
Un autre exemple est l'ajustement d'une loi linéaire du type y = α x + β + ε sur des mesures indépendantes, fonction d'un paramètre connu x. Le terme ε permet de prendre en compte des erreurs de mesure. Lorsque le modèle compte k variables explicatives x1,...,xk, on gagnera à adopter la notation matricielle :

où les matrices y, X, α, ε sont de dimension n × 1, n × k, k × 1, n × 1 resp.
L'utilisation de la régression linéaire se rencontre par exemple lorsque l'on veut étalonner un appareil de mesure simple (ampèremètre, thermomètre) dont le fonctionnement est linéaire. y est alors la mesure instrumentale (déviation d'une aiguille, nombre de pas d'un convertisseur analogique-numérique, …) et x la grandeur physique qu'est censé mesurer l'appareil, généralement mieux connue, si l'on utilise une source d’étalonnage fiable. La méthode des moindres carrés permet alors de mesurer la loi d’étalonnage de l'appareil, d'estimer l'adéquation de cette loi aux mesures d’étalonnage (i.e. dans le cas présent, la linéarité de l'appareil) et de propager les erreurs d’étalonnage aux futures mesures effectuées avec l'appareil étalonné. En général, les erreurs (et les corrélations) portant sur les mesures yi et les mesures xi doivent être prises en compte. Ce cas sera traité dans la section suivante.
La prescription des moindres carrés s'écrit pour ce type de modèle :

Le minimum de cette somme des carrés pondérés est atteint pour grad χ2 = 0, ce qui donne :

ou, plus explicitement :

Là encore, il s'agit d'une estimation par moindres carrés généralisée ou pondérés. La détermination des paramètres « optimaux » (au sens des moindres carrés) αmin et βmin se ramène donc à la résolution d'un système d'équations linéaires. Il s'agit là d'une propriété très intéressante, liée au fait que le modèle lui-même est linéaire. On parle d'ajustement ou de régression linéaire. Dans le cas général, la détermination du minimum du χ2 est un problème plus compliqué, et généralement coûteux en temps de calcul (cf. sections suivantes).
La valeur des paramètres αmin et βmin dépend des mesures yi réalisées. Comme ces mesures sont entachées d'erreur, on conçoit bien que si l'on répète M fois les N mesures d’étalonnage, et que l'on réalise à l'issue de chaque série l'ajustement décrit plus haut, on obtiendra M valeurs numériquement différentes de αmin et βmin. Les paramètres de l'ajustement peuvent donc être considérés comme des variables aléatoires, dont la loi est fonction du modèle ajusté et de la loi des yi.
En particulier, l'espérance du vecteur (αmin ; βmin) est le vecteur des vraies valeurs des paramètres : l'estimation est donc sans-biais. Qui plus est, on montre que la dispersion qui affecte les valeurs de αmin et βmin dépend du nombre de points de mesure, N, et de la dispersion qui affecte les mesures (moins les mesures sont précises, plus αmin et βmin fluctueront). Par ailleurs, αmin et βmin ne sont généralement pas des variables indépendantes. Elles sont généralement corrélées, et leur corrélation dépend du modèle ajusté (nous avons supposé les yi indépendants).
Ajustement d'un modèle linéaire quelconque
Un modèle y = f (x ; θ) est linéaire si sa dépendance en θ est linéaire. Un tel modèle s'écrit :

où les ϕk sont n fonctions quelconques de la variable x. Un tel cas est très courant en pratique : les deux modèles étudiés plus haut sont linéaires. Plus généralement tout modèle polynomial est linéaire, avec ϕk(x) = xk. Enfin, de très nombreux modèles utilisés en sciences expérimentales sont des développements sur des bases fonctionnelles classiques (splines, base de Fourier, bases d'ondelettes, etc.)
Si nous disposons de N mesures, (xi, yi, σi), le χ2 peut être écrit sous la forme :

Nous pouvons exploiter la linéarité du modèle pour exprimer le χ2 sous une forme matricielle plus simple. En effet, en définissant :

on montre facilement que le χ2 s'écrit sous la forme :

La matrice J est appelée matrice jacobienne du problème. C'est une matrice rectangulaire, de dimension N × n, avec généralement N ≫ n. Elle contient les valeurs des fonctions de base ϕk pour chaque point de mesure. La matrice diagonale W est appelée matrice des poids. C'est l'inverse de la matrice de covariance des yi. On montre que si les yi sont corrélés, la relation ci-dessus est toujours valable. W n'est simplement plus diagonale, car les covariances entre les yi ne sont plus nulles.
En différenciant la relation ci-dessus par rapport à chaque θk, on obtient :

et le minimum du χ2 est donc atteint pour θmin égal à :

On retrouve la propriété remarquable des problèmes linéaires, qui est que le modèle optimal peut être obtenu en une seule opération, à savoir la résolution d'un système n × n.
Équations normales
Dans le cas d'équations linéaires surdéterminées à coefficients constants, il existe une solution simple[3]. Si nous disposons d'équations expérimentales surdéterminées sous la forme

nous allons représenter l'erreur commise par le vecteur résidu

La norme du résidu est minimum si et seulement si satisfait les équations normales :



où AT est la transposée de A. Et donc :

Ajustement de modèles non linéaires
Dans de nombreux cas, la dépendance du modèle en θ est non linéaire. Par exemple, si f (x ; θ) = f (x ; (A,ω,ϕ)) = A cos(ω x + ϕ), ou f (x ; θ) = f (x ; τ) = exp(-x/τ). Dans ce cas, le formalisme décrit à la section précédente ne peut pas être appliqué directement. L'approche généralement employée consiste alors à partir d'une estimation de la solution, à linéariser le χ2 en ce point, résoudre le problème linéarisé, puis itérer. Cette approche est équivalente à l'algorithme de minimisation de Gauss-Newton. D'autres techniques de minimisation existent. Certaines, comme l'algorithme de Levenberg-Marquardt, sont des raffinements de l'algorithme de Gauss-Newton. D'autres sont applicables lorsque les dérivées du χ2 sont difficiles ou coûteuses à calculer.
Une des difficultés des problèmes de moindres carrés non linéaires est l'existence fréquente de plusieurs minima locaux. Une exploration systématique de l'espace des paramètres peut alors se révéler nécessaire.
Contraintes linéaires d'égalité
Dans le cas où les contraintes sont linéaires et d'égalité,


l'estimateur peut s'écrire comme un estimateur des moindres carrés corrigé :

Ce résultat peut être obtenu par application des conditions d'optimalité du premier ordre.






Interprétation statistique
Modèle standard : moindres carrés ordinaires
Pour le modèle matriciel
on conserve les hypothèses conventionnelles que et que , où est la matrice d'identité. Dans ce cas, l'estimateur par moindres carrés ordinaire (MCO) est




Une formalisation supplémentaire (on suppose par exemple en plus que les aléas sont normaux) permet d'obtenir les propriétés asymptotiques de l'estimateur :

Les indices 0 indiquent qu'il s'agit de la vraie valeur des paramètres.
Moindres carrés généralisés
Lorsqu'on relâche (un peu) l'hypothèse sur la structure de la matrice de variance-covariance des erreurs, on peut toujours obtenir un estimateur par moindres carrés. On suppose donc que , où cette dernière matrice est connue. L'estimateur par moindres carrés (dit par moindres carrés généralisé, MCG) s'écrit toujours :

Les propriétés asymptotiques changent par rapport au cas standard :

Moindres carrés pondérés
Si l'on connaît parfaitement la matrice de variance-covariance Ω, on peut considérer la méthode des moindres carrés pondérés. Pour cela, on considère la décomposition de Cholesky de cette matrice : PT P = Ω−1 et on prémultiplie chaque membre de la régression par PT, pour obtenir

avec , et . Ainsi transformé, ce modèle vérifie toutes les hypothèses requises par les MCO et l'estimateur en résultant présentera toutes les bonnes propriétés (notamment du point de vue de la matrice de variance-covariance) :




La loi asymptotique sera :

Le critère du χ²
La méthode des moindres carrés se base sur une évaluation des résidus de l'erreur commise par rapport à un modèle. On peut donc comparer la valeur estimée de l'erreur par rapport à une variance :

L'entier ν représente le nombre de degrés de liberté dans notre estimation, soit la différence entre le nombre d'échantillons N et le nombre de paramètres qui caractérisent le modèle. Ainsi, dans le cas du modèle linéaire, puisqu'il faut deux paramètres pour le caractériser, on a ν = n –2.
On considère que l'estimation est bonne si χ2
ν < 1 (trop d'erreur de mesures) et χ2
ν > 0,1 (surestimation des erreurs commises).
Optimalité de la méthode des moindres carrés
Dans la régression linéaire classique,
On suppose généralement que et que , où In est la matrice d'identité. La dernière hypothèse porte sur la structure de variance-covariance des aléas : on suppose que pour tout i, Var(εi) = σ2 (homoscédasticité) et que Cov(εi,εj) = 0 pour i ≠ j (indépendance).
L'estimation par moindres carrés ordinaires (MCO) est
Sous les hypothèses précédentes, cet estimateur est connu pour être le meilleur estimateur linéaire sans biais (voir le théorème de Gauss-Markov) : cela signifie que parmi les estimateurs du type non biaisé, l'estimateur MCO présente une variance minimale.

Enfin, si on suppose de plus que les aléas sont gaussiens, le modèle peut s'estimer par la méthode du maximum de vraisemblance. Cet estimateur se trouve être celui par moindres carrés MCO et atteignant la borne de Cramér-Rao.
Enfin, sous les hypothèses du paragraphe sur les moindres carrés généralisés, l'estimateur reste le meilleur estimateur linéaire non biaisé.
Robustesse
La méthode des moindres carrés gère mal les valeurs aberrantes (ou outliers), qui peuvent « brouiller » les points en sortant de la moyenne. En effet, chercher la solution d'un problème de moindres carrés revient à résoudre une équation sur les résidus ri (θ) :

Or pour une donnée aberrante, le résidu associé est élevé et entraîne une surestimation de cette donnée dans la résolution (effet de masquage ou masking effect) ; à l'inverse, des données correctes peuvent se retrouver négligées par rapport à d'autres (swamping effect)[4],[5].
Plusieurs méthodes existent pour éviter une influence trop forte des valeurs aberrantes :
- modifier le χ2 en ne calculant plus le carré des résidus mais une fonction ρ bien choisie de ceux-ci (méthodes des M-estimateurs)
- remplacer la somme par la médiane, qui contrairement à la moyenne est un estimateur robuste (méthode des moindres carrés médians).
Notes et références
- Georg Wilhelm Friedrich Hegel, Les Orbites des planètes : dissertation de 1801, p. 52.
- CRAS, Volume 3, Gauthier-Villars, 1836, p. 141.
- « 3.6 système surdéterminé » dans Analyse numérique première partie, Professeur F.X. LITT, Centrale des cours de l'AEES (ULg).
- (en) Martin A. Fischler et Robert C. Bolles, « Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography », Communications of the ACM, vol. 24, no 6, (lire en ligne)
- (en) Peter J. Rousseeuw et Mia Hubert, « Robust statistics for outlier detection », WIREs Data Mining Knowledge Discovery, John Wiley & Sons, Inc., vol. 1,
Voir aussi
Bibliographie
- Pierre-André Cornillon et Éric Matzner-Løber, Régression : théorie et applications, Paris, Springer, , 302 p. (ISBN 978-2-287-39692-2).
- Sabine Van Huffel et Joos Vandewalle (préf. Gene H. Golub), The Total Least Squares Problem : Computational Aspects and Analysis, SIAM, coll. « Frontiers in Applied Mathematics » (no 9), , xiii + 300 (ISBN 978-0-89871-275-9, Math Reviews 1118607, présentation en ligne)
Articles connexes
Liens externes
- (histoire des sciences) La méthode des moindres carrés, à partir du texte de Legendre (1805), site Bibnum
- (histoire des sciences) La méthode de Cholesky, 1910 (cf. supra), site Bibnum
- Calcul d'incertitudes Un livre de 198 pages qui traite de la régression linéaire et non-linéaire. Un tableur permet les calculs avec ou sans barres d'erreurs M(xi±Δxi; yi±Δyi).
- Artelys Knitro (logiciel) solveur non-linéaire implémentant les algorithmes de Gauss-Newton et Levenberg-Marquardt, interfaces pour C/C++, Python, Java, C#, MATLAB, et R
- (en) lmfit (logiciel) minimisation selon l'algorithme de Levenberg-Marquardt, pour utilisation dans des programmes en C ou C++
- [PDF] Méthodes des moindres carrés : meilleure approximation linéaire
 Portail des probabilités et de la statistique
Portail des probabilités et de la statistique