Wubi method
The Wubizixing input method (simplified Chinese: 五笔字型输入法; traditional Chinese: 五筆字型輸入法; pinyin: wǔbǐ zìxíng shūrùfǎ; lit. 'five-stroke character model input method'), often abbreviated to simply Wubi or Wubi Xing,[1] is a Chinese character input method primarily for inputting simplified Chinese and traditional Chinese text on a computer. Wubi should not be confused with the Wubihua (五笔画) method, which is a different input method that shares the categorization into five types of strokes.
| Wubi method | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simplified Chinese | 五笔字型输入法 | ||||||||||||
| Literal meaning | five-stroke character model input method | ||||||||||||
| |||||||||||||
| Alternative Chinese name | |||||||||||||
| Simplified Chinese | 王码 | ||||||||||||
| Literal meaning | Wang code | ||||||||||||
| |||||||||||||


The method is also known as Wang Ma (simplified Chinese: 王码; traditional Chinese: 王碼; pinyin: Wáng mǎ; lit. 'Wang code'), named after the inventor Wang Yongmin (王永民). There are four Wubi versions that are considered to be standard: Wubi 86, Wubi 98, Wubi 18030 and Wubi New-century (the 3rd-generation Version). The latter three can also be used to input traditional Chinese text, albeit in a more limited way. Wubi 86 is the most widely known and used shape-based input method for full letter keyboards in Mainland China. If it is frequently needed to input traditional Chinese characters as well, other input methods like Cangjie or Zhengma may be better suited to the task, and it is also much more likely to find them on the computer one needs to use.
The Wubi method is based on the structure of characters rather than their pronunciation, making it possible to input characters even when the user does not know the pronunciation, as well as not being too closely linked to any particular spoken variety of Chinese. It is also extremely efficient: nearly every character can be written with at most 4 keystrokes. In practice, most characters can be written with fewer. There are reports of experienced typists reaching 160 characters per minute with Wubi.[2] What this means in the context of Chinese is not entirely the same as it is for English, but it is true that Wubi is extremely fast when used by an experienced typist. The main reason for this is that, unlike with traditional phonetic input methods, one does not have to spend time selecting the desired character from a list of homophonic possibilities: virtually all characters have a unique representation.
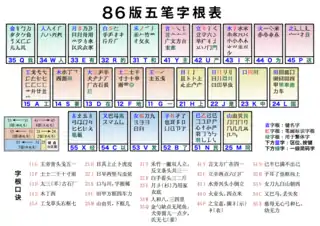
As its name suggests, the keyboard is divided into five regions. The Chinese character 笔 (bǐ), when used in the context of writing Chinese characters, refers to the brush strokes used in Chinese calligraphy. Each region is assigned a certain type of stroke.
- Region 1: horizontal (一)
- Region 2: vertical (丨)
- Region 3: downward right-to-left (丿)
- Region 4: dot strokes or downward left-to-right strokes (丶)
- Region 5: hook (乙)
A major drawback to learning Wubi is its steeper learning curve, since as a more complex system it takes longer to acquire as a skill. Memorization and practice are key factors for proficient usage.
To use Wubi, there are multiple input methods available, including Google Input Tools (used by Google Translate) and keyboard options on Mac devices. Wubi sequences can be looked up for specific characters by using online dictionaries.
In this article, the following convention will be used: character will always mean Chinese character, whereas letter, key and keystroke will always refer to the keys on keyboard.
How it works
Essentially, a character is broken down into components, which are usually (but not always) the same as radicals. These are typed in the order in which they would be written by hand. In order to ensure that extremely complex characters do not require an inordinate number of keystrokes, any character containing more than 4 components is entered by typing the first 3 components written, followed by the last. In this way, each character's data can be entered with no more than 4 keystrokes.
Wubi distributes its characters very evenly and as such the vast majority of characters are uniquely defined by the 4 keystrokes discussed above. One then types a space to move the character from the input buffer onto the screen. In the event that the 4 letter representation of the character is not unique, one would type a digit to select the relevant character (for example, if two characters have the same representation, typing 1 would select the first, and 2 the second). In most implementations, a space can always be typed and simply means 1 in an ambiguous setting. Intelligent software will try to make sure that the character in the default position is the one desired.
Many characters have more than one representation. This sometimes is for ease of use, in case there is more than one obvious way to break down a character. More often though, it is because certain characters have a short representation that is less than 4 letters, as well as a "full" representation.
For characters with fewer than 4 components that do not have a short form representation, one types each component and then "fills up" the representation (that is, types enough extra keystrokes to make the representation 4 keystrokes) by manually typing the strokes of the last component, in the order they would be written. If there are too many strokes, one should write as many as possible, but put the last stroke last (this mirrors the component rule for characters with more than 4 components outlined above).
Once the algorithm is understood, one can type almost any character with a little practice, even if one has not typed it before. Muscle memory ensures that frequent typists using this method do not have to think about how the characters are actually constructed, just as the vast majority of English typists do not think very much about the spelling of words when they write.
Implementation specific details
Many implementations employ further, multiple-word optimizations. Usually, a commonly used digraph (two character word) in which both characters have short form two-keystroke representations can be combined into a single, four keystroke representation which generates two characters rather than one. There are also a few 3-character shortcuts, and even one rather longer, politically motivated one. Some examples of these are provided in the examples section below.
Another common feature is the use of the 'z' key as a wildcard. The Wubi method was actually designed with this feature in mind; this is why no components are assigned to the z key. Basically, one can type a z when unsure what the component should be, and the input method will help complete it. If one knew, for example, that the character ought to start with "kt", but was unsure what the next component should be, typing "ktz" would produce a list of all characters starting with "kt". In practice though, many input method engines use a tabular lookup method for all table based input systems, including for Wubi. This means that they simply have a large table in memory, associating different characters to their respective representations. The input method then simply becomes a table lookup. In such an implementation, the z key breaks the paradigm and as such is not found in much generalized software (although the Wubi input method commonly found in Chinese Windows implements the feature). For this same reason, the multiple character optimization described in the previous paragraph is also relatively rare.
Some input methods, such as xcin (found on many UNIX-like systems), provide a generic wildcard functionality which can be used in all the table based input systems, including pinyin and virtually anything else. Xcin uses '*' for auto-complete and '?' for just one letter, following the conventions pioneered in UNIX file globbing. Other implementations have their own conventions.
Subdivision of the keyboard
The Wubi keyboard assumes a QWERTY-like layout, so users of keyboards implementing a nationalized or alternative layout (such as Dvorak or the French AZERTY) will probably have to do some remapping to make the system sane. Wubi does not position its components arbitrarily: there are far too many of them, and it is only with the introduction of a logical methodology that the system becomes easy to learn.
Basically, the keyboard is divided into 5 zones, each representing a stroke. Those five strokes are falling left, falling right, horizontal, vertical, and hook, and the zones that represent them are QWERT, YUIOP, ASDFG, HJKLM, and XCVBN, respectively. These zones are all laid out horizontally, with the exception of M, which is not in line with the rest of the letters in its zone.
In a general way, the keyboard can be thought of as divided down the center, between T and Y, G and H, and N and M. The keys in each zone are numbered moving away from this dividing line: so we should actually say that in zone QWERT, T is the first letter, R is the second, and E the third; in zone YUIOP, Y is the first, U is the second, I the third, etc. For XCVBN, N is the first, and so on. In HJKLM, consider M to be the last in the series, even though it does not lie on the line.
This is important because components in the first position will have one repetition of the stroke in question (the stroke assigned to the zone in which they belong), those in the second, two, those in the third, three. Those components which are not easily classifiable using this paradigm will be placed on the last letter.
Therefore, one would expect 一 to be located on G, and 二 on F, and 三 on D, and indeed, this is the case. Similarly, one would expect 丨 to be located on H, 刂 to be on J, and 川 to be on K. This pattern holds for all the zones. Furthermore, it extends to most radicals that look as though they are made up of three such strokes, even if in fact they might not be at all. An example of this is 中 on K: while it does not have three downward strokes (two only), it appears to have three. Furthermore, it is written by hand by first writing a mouth radical, 口, and then bisecting it with a vertical downward stroke. The mouth radical lies on 'K', so this makes the assignment doubly logical. And the pinyin romanization of 口, kou3, begins with k, another memory aid encoded into the Wubi keyboard.
Furthermore, each letter of each zone has one component associated with it, its "main component". These are usually a complete character (with the exception of X) in their own right. One can always type this main component by typing the letter it is situated on four times. So, for example, the main component of H is 目, and so one would type it by typing "hhhh".
Each letter also has a shortcut character associated with it. In some cases, this character is the same as the component associated with the key in question, and sometimes not. This shortcut character is the character produced when one types just the letter and nothing else; these are all extremely common characters used when typing Chinese.
It is entirely possible that there are a number of components not listed below, either because of oversight, because they are rarely used, or because no simple Unicode representation for the component exists.
QWERT zone (falling left)
The Q key's main component is 金 and its shortcut character is 我. It is associated with the following components: 金, 钅, 勹, 儿, 夕, as well as the hook at the top of 饣 and 角, the radical 犭 without the lower left-falling stroke (so characters with that radical start with "qt", not just "q"), the criss-cross (such as in the center of 区), the top of 鱼 (i.e., without the horizontal stroke at the bottom), and the three (nearly vertical) "feet" in the bottom right corner of 流.
The W key's main component and shortcut character are both 人. It is associated with the following components: 人, 亻, 八, and the top of 癸. While 人 means person, it is often used by Wubi to construct a roof radical, such as in 会, "wfc". 入 is not governed by W, despite looking similar, and while 餐 has a top that looks vaguely like the top of 癸, the two are not the same (indeed, to type 餐, one must physically type out each component on the top).
The E key's main component is 月, and its shortcut character is 有. It is associated with the following components: 月, 用, 彡, 乃, the bottom of 衣 (i.e., without 亠), the top of 孚 (i.e., without 子), 豕 (hog), the bottom of 良 (i.e., without the 白), and the bottom of 舟 (i.e., without the little dot on the top). In this case, E's shortcut character does not even begin with a left-falling stroke, but merely prominently figures a component belonging to E. 彡 is featured on this character, as it is the third character in the zone (counting from T, see above). A particular distortion that comes up often is the use of E in 且 and in characters containing it: Wubi thinks of this component as 月 + 一.
The R key's main component is 白, and its shortcut character is 的. It is associated with the following components: 白, 手, 扌, 斤 (both with and without the T), 牛 (without the vertical downward stroke), and of course the two left-falling strokes 𰀪 that one would expect from the second key in the zone (see above for an explanation). Watch out for varieties of 手 where the central downward hook is replaced by a left-falling stroke, such as in 看.
The T key's main component is 禾, and its shortcut character is 和. It is associated with the following components: 禾, 竹, 夂, 攵, 彳, and the top of 乞 (i.e., without the 乙). 竹 may also be found in its smaller form (⺮). 丿 is also found on this key, because T is the first key in the zone (see above). This means that if one is typing a component or character stroke by stroke, they would (generally) use T to represent a left-falling stroke. See the section on disambiguation strokes for more information on exceptions to this rule.
YUIOP zone (falling right)
This zone might also be called the dot zone, because its pattern of Y: 讠 U: 冫 I: 氵 and O: 灬 is not actually necessarily built up of right falling strokes. In fact, one could argue that the first stroke in 灬 actually falls left. It is called the falling right zone because the keys in this zone, when used to construct a character by stroke (rather than component), all represent right falling strokes for some character configuration (see the section on disambiguation strokes for more information).
The Y key's main component is 言, and its shortcut character is 主. It is associated with the following components: 言, 讠, 亠, 亠 with a 口 beneath it, 广, 文, 方, and 丶. These components all start with a right-falling stroke. Generally, dots in Chinese characters are actually left falling strokes, and so most of the time, the use of T is more appropriate than Y. Of course, if one can write Chinese characters by hand, they should be able to tell which to choose by recalling how it is written.
The U key's main component is 立, and its shortcut character is 产. It is associated with the following components: 立, 六, 辛, 门, 疒, 丬, 冫, the "antennae" on the top of 单 (just two strokes: 丷), and the antennae plus a horizontal stroke, as found on the top of 兹. Most of these all feature two short diagonal strokes (门 being the obvious exception). This is consistent with U's place as the second letter in the zone (see above for an explanation).
The I key's main component is 水, and its shortcut character is 不. It is associated with the following components: 水, 氵, 小, the three strokes on the top of 学, and the three strokes on the top of 当. Additionally, a component which might be described as two 冫, back to back, is associated with this character.
The O key's main component is 火, and its shortcut character is 为. It is associated with the following components: 火, 米, 灬, and 业 without the bottom horizontal stroke — this allows construction of characters such as 严. This is the 4th key in the falling right zone: hence the inclusion of 灬.
The P key's main component is 之, and its shortcut character is 这. It is associated with the following components: 之, 辶, 廴, 冖, 宀, and 礻. As Wubi components are typed in the order that they would need to be written were one writing by hand, the 辶 and 廴 components are typically typed last.
ASDFG zone (horizontal)
- The A key's shortcut character is 工.
- The S key's main component is 木, and its shortcut character is 要.
- The D key's main component is 大, and its shortcut character is 在.
- The F key's main component is 土, and its shortcut character is 地. The main component's name (earth) correlates to the shortcut character which means earth.
- The G key's main component is 王, and its shortcut character is 一.
HJKLM zone (vertical)
- The H key's main component is 目, and its shortcut character is 上.
- The J key's main component is 日, and its shortcut character is 是.
- The K key's main component is 口, and its shortcut character is 中.
- The L key's main component is 田, and its shortcut character is 国.
- The M key's main component is 山, and its shortcut character is 同.
XCVBN zone (hook)
- The X key's main component is 纟, and its shortcut character is 经.
- The C key's main component is 又, and its shortcut character is 以.
- The V key's main component is 女, and its shortcut character is 发.
- The B key's main component is 子, and its shortcut character is 了.
- The N key's main component is 已, and its shortcut character is 民.
Disambiguation strokes
Strokes of keyboard is divided into 5 zones
| Zone | Keys | Stroke | Shape |
|---|---|---|---|
| 1 | GFDSA | 一 | Left-right (horizontal) |
| 2 | HJKLM | 丨 | Top-bottom (vertical) |
| 3 | TREWQ | 丿 | Falling left |
| 4 | YUIOP | 丶 | Falling right |
| 5 | NBVCX | 乙 | Hook |
Examples
Characters with 4 components or fewer (but no need for strokes)
Example 1: 请 Consists of three components: y (讠, radical #10), g (王*, radical 89), e (月, radical 118) → 请
Characters with more than four components
Example 2: 遗
Consists of five components: k (口), h (丨), g (一), m (贝), p (辶) → khgp → 遗 (it is not necessary to type m)
Characters with fewer than 4 components (needing strokes)
Example 3a: 文: First you type the key with the symbol on it, which happens to be 'Y'. Then you type the first component, which is also 'Y' for the 点 stroke, then a 'G' for the 横 stroke,and since you now already have three strokes, you type the last stroke, which also happens to be a 捺, arriving at the keycode 'YYGY' for the complete character.
Example 3b: 一: The code for this character is 'GGLL'. As before, you type the key for the character first, which is 'G', then the first stroke of that character, which is also a 'G'. Because this is all necessary information, the L is used as a filler until you reach 4 letters.[2] Note that the '一' is also the shortcut character for 'G' (making it one stroke only in practice).
Example 3c: 广: The code for this character is 'YYGT'. At first, you type the key where this character is located, which is a 'Y'. Then, you type a 点 stroke, which is also on 'Y'. The next will be the 横 stroke on 'G', and the last will be the 捺, on 'T'.
Characters requiring disambiguation strokes
Example 4: 等
Consists of three components: t (竹), f (土), f (寸),
Disambiguation strokes: The last stroke is 丶 and the character is with top-bottom structure (42,u) → 等
Poem
A poem was made as a mnemonic for the Wubi keyboard, associating few characters with each key. The first character is the corresponding key main component, while the next ones are components or associated characters.
1986 version
G11王旁青头戋五一
F12土士二干十寸雨
D13大犬三羊古石厂
S14木丁西
A15工戈草头右框七
H21目具上止卜虎皮
J22日早两竖与虫依
K23口与川,字根稀
L24田甲方框四车力
M25山由贝,下框几
T31禾竹一撇双人立,反文条头共三一
R32白手看头三二斤
E33月彡(衫)乃用家衣底
W34人和八,登祭头
Q35金勺缺点无尾鱼,犬旁留义儿一点夕,氏无七
Y41言文方广在四一,高头一捺谁人去
U42立辛两点六门疒(病)
I43水旁兴头小倒立
O44火业头,四点米
P45之宝盖,摘示衣
N51已半巳满不出己,左框折尸心和羽
B52子耳了也框向上
V53女刀九臼山朝西
C54又巴马,丢矢矣
X55慈母无心弓和匕,幼无力
1998 version
G11 王旁青头五夫一
F12 土干十寸未甘雨,不要忘了革字底
D13 大犬戊其古石厂
S14 木丁西甫一四里
A15 工戈草头右框七
H21 目上卜止虎具头
J22 日早两竖与虫依
K23 口流川,码元稀
L24 田甲方框四车里
M25 山由贝骨下框集
T31 禾竹反文双人立
R32 白斤气丘叉手提
E33 月用力豸毛衣臼
W34 人八登头单人几
Q35 金夕鸟儿犭边鱼
Y41 言文方点谁人去
U42 立辛六羊病门里
I43 水族三点鳖头小
O44 火业广鹿四点米
P45 之字宝盖补示衣
N51 已类左框心尸羽
B52 子耳了也乃框皮
V53 女刀九良山西倒
C54 又巴牛入马失蹄
X55 幺母贯头弓和匕
New-century (3rd-generation) version
G11 王旁青头五一提
F12 土士二干十寸雨
D13 大三肆头古石厂
S14 木丁西边要无女
A15 工戈草头右框七
H21 目止具头卜虎皮
J22 日曰两竖与虫依
K23 口中两川三个竖
L24 田框四车甲单底
M25 山由贝骨下框里
T31 禾竹牛旁卧人立
R32 白斤气头叉手提
E33 月舟衣力豕豸臼
W34 人八登祭风头几
Q35 金夕犭儿包头鱼
Y41 言文方点在四一
U42 立带两点病门里
I43 水边一族三点小
O44 火变三态广二米
P45 之字宝盖补示衣
N51 已类左框心尸羽
B52 子耳了也乃齿底
V53 女刀九巡录无水
C54 又巴甬矣马失蹄
X55 幺母绞丝弓三匕
In media
In 2020, the history of Wubi was featured in a Radiolab episode titled "The Wubi Effect".[3]
Notes and references
- This is the name used in Mac OS X
- Wicentowski, Joe (1996), Wubizixing for Speakers of English, archived from the original on 10 July 2015
- Adler, Simon. "The Wubi Effect: Radiolab". WNYC Studios, 14 August 2020.
External links
| Varieties |
| ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard forms | |||||||||||||||||||||||||||||||||||||||
| Phonology | |||||||||||||||||||||||||||||||||||||||
| Grammar | |||||||||||||||||||||||||||||||||||||||
| Idioms | |||||||||||||||||||||||||||||||||||||||
| Input | |||||||||||||||||||||||||||||||||||||||
| History | |||||||||||||||||||||||||||||||||||||||
| Literary forms |
| ||||||||||||||||||||||||||||||||||||||
| Scripts |
| ||||||||||||||||||||||||||||||||||||||