Regression analysis
In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable (often called the 'outcome' or 'response' variable, or a 'label' in machine learning parlance) and one or more independent variables (often called 'predictors', 'covariates', 'explanatory variables' or 'features'). The most common form of regression analysis is linear regression, in which one finds the line (or a more complex linear combination) that most closely fits the data according to a specific mathematical criterion. For example, the method of ordinary least squares computes the unique line (or hyperplane) that minimizes the sum of squared differences between the true data and that line (or hyperplane). For specific mathematical reasons (see linear regression), this allows the researcher to estimate the conditional expectation (or population average value) of the dependent variable when the independent variables take on a given set of values. Less common forms of regression use slightly different procedures to estimate alternative location parameters (e.g., quantile regression or Necessary Condition Analysis[1]) or estimate the conditional expectation across a broader collection of non-linear models (e.g., nonparametric regression).
| Part of a series on |
| Regression analysis |
|---|
| Models |
|
|
|
|
|
| Estimation |
|
|
|
|
| Background |
|
|
| Part of a series on |
| Machine learning and data mining |
|---|
 |
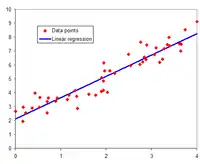
Regression analysis is primarily used for two conceptually distinct purposes.
First, regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning.
Second, in some situations regression analysis can be used to infer causal relationships between the independent and dependent variables. Importantly, regressions by themselves only reveal relationships between a dependent variable and a collection of independent variables in a fixed dataset. To use regressions for prediction or to infer causal relationships, respectively, a researcher must carefully justify why existing relationships have predictive power for a new context or why a relationship between two variables has a causal interpretation. The latter is especially important when researchers hope to estimate causal relationships using observational data.[2][3]
History
The earliest form of regression was the method of least squares, which was published by Legendre in 1805,[4] and by Gauss in 1809.[5] Legendre and Gauss both applied the method to the problem of determining, from astronomical observations, the orbits of bodies about the Sun (mostly comets, but also later the then newly discovered minor planets). Gauss published a further development of the theory of least squares in 1821,[6] including a version of the Gauss–Markov theorem.
The term "regression" was coined by Francis Galton in the 19th century to describe a biological phenomenon. The phenomenon was that the heights of descendants of tall ancestors tend to regress down towards a normal average (a phenomenon also known as regression toward the mean).[7][8] For Galton, regression had only this biological meaning,[9][10] but his work was later extended by Udny Yule and Karl Pearson to a more general statistical context.[11][12] In the work of Yule and Pearson, the joint distribution of the response and explanatory variables is assumed to be Gaussian. This assumption was weakened by R.A. Fisher in his works of 1922 and 1925.[13][14][15] Fisher assumed that the conditional distribution of the response variable is Gaussian, but the joint distribution need not be. In this respect, Fisher's assumption is closer to Gauss's formulation of 1821.
In the 1950s and 1960s, economists used electromechanical desk "calculators" to calculate regressions. Before 1970, it sometimes took up to 24 hours to receive the result from one regression.[16]
Regression methods continue to be an area of active research. In recent decades, new methods have been developed for robust regression, regression involving correlated responses such as time series and growth curves, regression in which the predictor (independent variable) or response variables are curves, images, graphs, or other complex data objects, regression methods accommodating various types of missing data, nonparametric regression, Bayesian methods for regression, regression in which the predictor variables are measured with error, regression with more predictor variables than observations, and causal inference with regression.
Regression model
In practice, researchers first select a model they would like to estimate and then use their chosen method (e.g., ordinary least squares) to estimate the parameters of that model. Regression models involve the following components:
- The unknown parameters, often denoted as a scalar or vector .
- The independent variables, which are observed in data and are often denoted as a vector (where denotes a row of data).
- The dependent variable, which are observed in data and often denoted using the scalar .
- The error terms, which are not directly observed in data and are often denoted using the scalar .





In various fields of application, different terminologies are used in place of dependent and independent variables.
Most regression models propose that is a function of and , with representing an additive error term that may stand in for un-modeled determinants of or random statistical noise:

The researchers' goal is to estimate the function that most closely fits the data. To carry out regression analysis, the form of the function must be specified. Sometimes the form of this function is based on knowledge about the relationship between and that does not rely on the data. If no such knowledge is available, a flexible or convenient form for is chosen. For example, a simple univariate regression may propose , suggesting that the researcher believes to be a reasonable approximation for the statistical process generating the data.




Once researchers determine their preferred statistical model, different forms of regression analysis provide tools to estimate the parameters . For example, least squares (including its most common variant, ordinary least squares) finds the value of that minimizes the sum of squared errors . A given regression method will ultimately provide an estimate of , usually denoted to distinguish the estimate from the true (unknown) parameter value that generated the data. Using this estimate, the researcher can then use the fitted value for prediction or to assess the accuracy of the model in explaining the data. Whether the researcher is intrinsically interested in the estimate or the predicted value will depend on context and their goals. As described in ordinary least squares, least squares is widely used because the estimated function approximates the conditional expectation .[5] However, alternative variants (e.g., least absolute deviations or quantile regression) are useful when researchers want to model other functions .






It is important to note that there must be sufficient data to estimate a regression model. For example, suppose that a researcher has access to rows of data with one dependent and two independent variables: . Suppose further that the researcher wants to estimate a bivariate linear model via least squares: . If the researcher only has access to data points, then they could find infinitely many combinations that explain the data equally well: any combination can be chosen that satisfies , all of which lead to and are therefore valid solutions that minimize the sum of squared residuals. To understand why there are infinitely many options, note that the system of equations is to be solved for 3 unknowns, which makes the system underdetermined. Alternatively, one can visualize infinitely many 3-dimensional planes that go through fixed points.







More generally, to estimate a least squares model with distinct parameters, one must have distinct data points. If , then there does not generally exist a set of parameters that will perfectly fit the data. The quantity appears often in regression analysis, and is referred to as the degrees of freedom in the model. Moreover, to estimate a least squares model, the independent variables must be linearly independent: one must not be able to reconstruct any of the independent variables by adding and multiplying the remaining independent variables. As discussed in ordinary least squares, this condition ensures that is an invertible matrix and therefore that a unique solution exists.






Underlying assumptions
By itself, a regression is simply a calculation using the data. In order to interpret the output of regression as a meaningful statistical quantity that measures real-world relationships, researchers often rely on a number of classical assumptions. These assumptions often include:
- The sample is representative of the population at large.
- The independent variables are measured with no error.
- Deviations from the model have an expected value of zero, conditional on covariates:
- The variance of the residuals is constant across observations (homoscedasticity).
- The residuals are uncorrelated with one another. Mathematically, the variance–covariance matrix of the errors is diagonal.

A handful of conditions are sufficient for the least-squares estimator to possess desirable properties: in particular, the Gauss–Markov assumptions imply that the parameter estimates will be unbiased, consistent, and efficient in the class of linear unbiased estimators. Practitioners have developed a variety of methods to maintain some or all of these desirable properties in real-world settings, because these classical assumptions are unlikely to hold exactly. For example, modeling errors-in-variables can lead to reasonable estimates independent variables are measured with errors. Heteroscedasticity-consistent standard errors allow the variance of to change across values of . Correlated errors that exist within subsets of the data or follow specific patterns can be handled using clustered standard errors, geographic weighted regression, or Newey–West standard errors, among other techniques. When rows of data correspond to locations in space, the choice of how to model within geographic units can have important consequences.[17][18] The subfield of econometrics is largely focused on developing techniques that allow researchers to make reasonable real-world conclusions in real-world settings, where classical assumptions do not hold exactly.
Linear regression
In linear regression, the model specification is that the dependent variable, is a linear combination of the parameters (but need not be linear in the independent variables). For example, in simple linear regression for modeling data points there is one independent variable: , and two parameters, and :





- straight line:

In multiple linear regression, there are several independent variables or functions of independent variables.
Adding a term in to the preceding regression gives:

- parabola:

This is still linear regression; although the expression on the right hand side is quadratic in the independent variable , it is linear in the parameters , and

In both cases, is an error term and the subscript indexes a particular observation.

Returning our attention to the straight line case: Given a random sample from the population, we estimate the population parameters and obtain the sample linear regression model:

The residual, , is the difference between the value of the dependent variable predicted by the model, , and the true value of the dependent variable, . One method of estimation is ordinary least squares. This method obtains parameter estimates that minimize the sum of squared residuals, SSR:



Minimization of this function results in a set of normal equations, a set of simultaneous linear equations in the parameters, which are solved to yield the parameter estimators, .

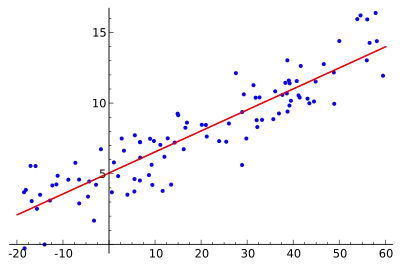
In the case of simple regression, the formulas for the least squares estimates are


where is the mean (average) of the values and is the mean of the values.




Under the assumption that the population error term has a constant variance, the estimate of that variance is given by:

This is called the mean square error (MSE) of the regression. The denominator is the sample size reduced by the number of model parameters estimated from the same data, for regressors or if an intercept is used.[19] In this case, so the denominator is .





The standard errors of the parameter estimates are given by


Under the further assumption that the population error term is normally distributed, the researcher can use these estimated standard errors to create confidence intervals and conduct hypothesis tests about the population parameters.
General linear model
In the more general multiple regression model, there are independent variables:

where is the -th observation on the -th independent variable. If the first independent variable takes the value 1 for all , , then is called the regression intercept.



The least squares parameter estimates are obtained from normal equations. The residual can be written as

The normal equations are

In matrix notation, the normal equations are written as

where the element of is , the element of the column vector is , and the element of is . Thus is , is , and is . The solution is









Diagnostics
Once a regression model has been constructed, it may be important to confirm the goodness of fit of the model and the statistical significance of the estimated parameters. Commonly used checks of goodness of fit include the R-squared, analyses of the pattern of residuals and hypothesis testing. Statistical significance can be checked by an F-test of the overall fit, followed by t-tests of individual parameters.
Interpretations of these diagnostic tests rest heavily on the model's assumptions. Although examination of the residuals can be used to invalidate a model, the results of a t-test or F-test are sometimes more difficult to interpret if the model's assumptions are violated. For example, if the error term does not have a normal distribution, in small samples the estimated parameters will not follow normal distributions and complicate inference. With relatively large samples, however, a central limit theorem can be invoked such that hypothesis testing may proceed using asymptotic approximations.
Limited dependent variables
Limited dependent variables, which are response variables that are categorical variables or are variables constrained to fall only in a certain range, often arise in econometrics.
The response variable may be non-continuous ("limited" to lie on some subset of the real line). For binary (zero or one) variables, if analysis proceeds with least-squares linear regression, the model is called the linear probability model. Nonlinear models for binary dependent variables include the probit and logit model. The multivariate probit model is a standard method of estimating a joint relationship between several binary dependent variables and some independent variables. For categorical variables with more than two values there is the multinomial logit. For ordinal variables with more than two values, there are the ordered logit and ordered probit models. Censored regression models may be used when the dependent variable is only sometimes observed, and Heckman correction type models may be used when the sample is not randomly selected from the population of interest. An alternative to such procedures is linear regression based on polychoric correlation (or polyserial correlations) between the categorical variables. Such procedures differ in the assumptions made about the distribution of the variables in the population. If the variable is positive with low values and represents the repetition of the occurrence of an event, then count models like the Poisson regression or the negative binomial model may be used.
Nonlinear regression
When the model function is not linear in the parameters, the sum of squares must be minimized by an iterative procedure. This introduces many complications which are summarized in Differences between linear and non-linear least squares.
Interpolation and extrapolation
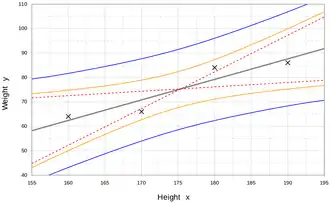
Regression models predict a value of the Y variable given known values of the X variables. Prediction within the range of values in the dataset used for model-fitting is known informally as interpolation. Prediction outside this range of the data is known as extrapolation. Performing extrapolation relies strongly on the regression assumptions. The further the extrapolation goes outside the data, the more room there is for the model to fail due to differences between the assumptions and the sample data or the true values.
It is generally advised that when performing extrapolation, one should accompany the estimated value of the dependent variable with a prediction interval that represents the uncertainty. Such intervals tend to expand rapidly as the values of the independent variable(s) moved outside the range covered by the observed data.
For such reasons and others, some tend to say that it might be unwise to undertake extrapolation.[21]
However, this does not cover the full set of modeling errors that may be made: in particular, the assumption of a particular form for the relation between Y and X. A properly conducted regression analysis will include an assessment of how well the assumed form is matched by the observed data, but it can only do so within the range of values of the independent variables actually available. This means that any extrapolation is particularly reliant on the assumptions being made about the structural form of the regression relationship. Best-practice advice here is that a linear-in-variables and linear-in-parameters relationship should not be chosen simply for computational convenience, but that all available knowledge should be deployed in constructing a regression model. If this knowledge includes the fact that the dependent variable cannot go outside a certain range of values, this can be made use of in selecting the model – even if the observed dataset has no values particularly near such bounds. The implications of this step of choosing an appropriate functional form for the regression can be great when extrapolation is considered. At a minimum, it can ensure that any extrapolation arising from a fitted model is "realistic" (or in accord with what is known).
Power and sample size calculations
There are no generally agreed methods for relating the number of observations versus the number of independent variables in the model. One method conjectured by Good and Hardin is , where is the sample size, is the number of independent variables and is the number of observations needed to reach the desired precision if the model had only one independent variable.[22] For example, a researcher is building a linear regression model using a dataset that contains 1000 patients (). If the researcher decides that five observations are needed to precisely define a straight line (), then the maximum number of independent variables the model can support is 4, because



Other methods
Although the parameters of a regression model are usually estimated using the method of least squares, other methods which have been used include:
- Bayesian methods, e.g. Bayesian linear regression
- Percentage regression, for situations where reducing percentage errors is deemed more appropriate.[23]
- Least absolute deviations, which is more robust in the presence of outliers, leading to quantile regression
- Nonparametric regression, requires a large number of observations and is computationally intensive
- Scenario optimization, leading to interval predictor models
- Distance metric learning, which is learned by the search of a meaningful distance metric in a given input space.[24]
Software
All major statistical software packages perform least squares regression analysis and inference. Simple linear regression and multiple regression using least squares can be done in some spreadsheet applications and on some calculators. While many statistical software packages can perform various types of nonparametric and robust regression, these methods are less standardized. Different software packages implement different methods, and a method with a given name may be implemented differently in different packages. Specialized regression software has been developed for use in fields such as survey analysis and neuroimaging.
See also
- Anscombe's quartet
- Curve fitting
- Estimation theory
- Forecasting
- Fraction of variance unexplained
- Function approximation
- Generalized linear model
- Kriging (a linear least squares estimation algorithm)
- Local regression
- Modifiable areal unit problem
- Multivariate adaptive regression splines
- Multivariate normal distribution
- Pearson correlation coefficient
- Quasi-variance
- Prediction interval
- Regression validation
- Robust regression
- Segmented regression
- Signal processing
- Stepwise regression
- Taxicab geometry
- Trend estimation
References
- Necessary Condition Analysis
- David A. Freedman (27 April 2009). Statistical Models: Theory and Practice. Cambridge University Press. ISBN 978-1-139-47731-4.
- R. Dennis Cook; Sanford Weisberg Criticism and Influence Analysis in Regression, Sociological Methodology, Vol. 13. (1982), pp. 313–361
- A.M. Legendre. Nouvelles méthodes pour la détermination des orbites des comètes, Firmin Didot, Paris, 1805. “Sur la Méthode des moindres quarrés” appears as an appendix.
- Chapter 1 of: Angrist, J. D., & Pischke, J. S. (2008). Mostly Harmless Econometrics: An Empiricist's Companion. Princeton University Press.
- C.F. Gauss. Theoria combinationis observationum erroribus minimis obnoxiae. (1821/1823)
- Mogull, Robert G. (2004). Second-Semester Applied Statistics. Kendall/Hunt Publishing Company. p. 59. ISBN 978-0-7575-1181-3.
- Galton, Francis (1989). "Kinship and Correlation (reprinted 1989)". Statistical Science. 4 (2): 80–86. doi:10.1214/ss/1177012581. JSTOR 2245330.
- Francis Galton. "Typical laws of heredity", Nature 15 (1877), 492–495, 512–514, 532–533. (Galton uses the term "reversion" in this paper, which discusses the size of peas.)
- Francis Galton. Presidential address, Section H, Anthropology. (1885) (Galton uses the term "regression" in this paper, which discusses the height of humans.)
- Yule, G. Udny (1897). "On the Theory of Correlation". Journal of the Royal Statistical Society. 60 (4): 812–54. doi:10.2307/2979746. JSTOR 2979746.
- Pearson, Karl; Yule, G.U.; Blanchard, Norman; Lee,Alice (1903). "The Law of Ancestral Heredity". Biometrika. 2 (2): 211–236. doi:10.1093/biomet/2.2.211. JSTOR 2331683.
- Fisher, R.A. (1922). "The goodness of fit of regression formulae, and the distribution of regression coefficients". Journal of the Royal Statistical Society. 85 (4): 597–612. doi:10.2307/2341124. JSTOR 2341124. PMC 1084801.
- Ronald A. Fisher (1954). Statistical Methods for Research Workers (Twelfth ed.). Edinburgh: Oliver and Boyd. ISBN 978-0-05-002170-5.
- Aldrich, John (2005). "Fisher and Regression". Statistical Science. 20 (4): 401–417. doi:10.1214/088342305000000331. JSTOR 20061201.
- Rodney Ramcharan. Regressions: Why Are Economists Obessessed with Them? March 2006. Accessed 2011-12-03.
- Fotheringham, A. Stewart; Brunsdon, Chris; Charlton, Martin (2002). Geographically weighted regression: the analysis of spatially varying relationships (Reprint ed.). Chichester, England: John Wiley. ISBN 978-0-471-49616-8.
- Fotheringham, AS; Wong, DWS (1 January 1991). "The modifiable areal unit problem in multivariate statistical analysis". Environment and Planning A. 23 (7): 1025–1044. doi:10.1068/a231025. S2CID 153979055.
- Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- Rouaud, Mathieu (2013). Probability, Statistics and Estimation (PDF). p. 60.
- Chiang, C.L, (2003) Statistical methods of analysis, World Scientific. ISBN 981-238-310-7 - page 274 section 9.7.4 "interpolation vs extrapolation"
- Good, P. I.; Hardin, J. W. (2009). Common Errors in Statistics (And How to Avoid Them) (3rd ed.). Hoboken, New Jersey: Wiley. p. 211. ISBN 978-0-470-45798-6.
- Tofallis, C. (2009). "Least Squares Percentage Regression". Journal of Modern Applied Statistical Methods. 7: 526–534. doi:10.2139/ssrn.1406472. SSRN 1406472.
- YangJing Long (2009). "Human age estimation by metric learning for regression problems" (PDF). Proc. International Conference on Computer Analysis of Images and Patterns: 74–82. Archived from the original (PDF) on 2010-01-08.
Further reading
- William H. Kruskal and Judith M. Tanur, ed. (1978), "Linear Hypotheses," International Encyclopedia of Statistics. Free Press, v. 1,
- Evan J. Williams, "I. Regression," pp. 523–41.
- Julian C. Stanley, "II. Analysis of Variance," pp. 541–554.
- Lindley, D.V. (1987). "Regression and correlation analysis," New Palgrave: A Dictionary of Economics, v. 4, pp. 120–23.
- Birkes, David and Dodge, Y., Alternative Methods of Regression. ISBN 0-471-56881-3
- Chatfield, C. (1993) "Calculating Interval Forecasts," Journal of Business and Economic Statistics, 11. pp. 121–135.
- Draper, N.R.; Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley. ISBN 978-0-471-17082-2.
- Fox, J. (1997). Applied Regression Analysis, Linear Models and Related Methods. Sage
- Hardle, W., Applied Nonparametric Regression (1990), ISBN 0-521-42950-1
- Meade, Nigel; Islam, Towhidul (1995). "Prediction intervals for growth curve forecasts". Journal of Forecasting. 14 (5): 413–430. doi:10.1002/for.3980140502.
- A. Sen, M. Srivastava, Regression Analysis — Theory, Methods, and Applications, Springer-Verlag, Berlin, 2011 (4th printing).
- T. Strutz: Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). Vieweg+Teubner, ISBN 978-3-8348-1022-9.
- Stulp, Freek, and Olivier Sigaud. Many Regression Algorithms, One Unified Model: A Review. Neural Networks, vol. 69, Sept. 2015, pp. 60–79. https://doi.org/10.1016/j.neunet.2015.05.005.
- Malakooti, B. (2013). Operations and Production Systems with Multiple Objectives. John Wiley & Sons.
External links
- "Regression analysis", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Earliest Uses: Regression – basic history and references
- What is multiple regression used for? – Multiple regression
- Regression of Weakly Correlated Data – how linear regression mistakes can appear when Y-range is much smaller than X-range
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General |
| ||||||
| Concepts |
| ||||||
| Programming languages | |||||||
| Application | |||||||
| Hardware | |||||||
| Software library |
| ||||||
| Implementation |
| ||||||
| People |
| ||||||
| Organizations |
| ||||||
| Architectures |
| ||||||
| |||||||
Least squares and regression analysis | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Computational statistics |
| ||||||||
| Correlation and dependence |
| ||||||||
| Regression analysis |
| ||||||||
| Regression as a statistical model |
| ||||||||
| Decomposition of variance |
| ||||||||
| Model exploration |
| ||||||||
| Background |
| ||||||||
| Design of experiments |
| ||||||||
| Numerical approximation |
| ||||||||
| Applications |
| ||||||||
| |||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
Public health | |||||||
|---|---|---|---|---|---|---|---|
| General |
| ||||||
| Preventive healthcare |
| ||||||
| Population health |
| ||||||
| Biological and epidemiological statistics | |||||||
| Infectious and epidemic disease prevention |
| ||||||
| Food hygiene and safety management |
| ||||||
| Health behavioral sciences |
| ||||||
| Organizations, education and history |
| ||||||
| |||||||