Alfabeto latino
El alfabeto latino o abecedario (en latín: Abecedarium Latinum) es el sistema de escritura alfabético más usado del mundo. Nacido del alfabeto etrusco, que a su vez se basa en una versión del alfabeto griego arcaico, el alfabeto latino se caracteriza por haber añadido letras a lo largo de los siglos para representar otras lenguas y reflejar el cambio fonético de la lenguas romances.
| Alfabeto latino | ||
|---|---|---|
 | ||
| Tipo | Alfabeto bicameral | |
| Idiomas |
| |
| Época | 700 a. C. - actualidad | |
| Antecesores | ||
| Historia | Historia del alfabeto latino | |
| Hermanos | Cirílico, copto, armenio, rúnico | |
| Dio lugar a | Numerosas variantes | |
| Dirección | dextroverso | |
| Letras | A B C D E F G H I J K L M N O P Q R S T U V W X Y Z (más variantes propias de cada idioma) | |
| Unicode | U0000 | |
| ISO 15924 |
Latn, 215 | |
| Mapa de distribución | ||
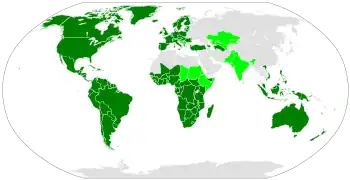
| ||
Se estima que es utilizado por más de 4500 millones de personas como parte de la ortografía de la mayoría de los idiomas de la Unión Europea, América, el África subsahariana y las islas del océano Pacífico.
Actualmente, la expresión alfabeto latino se utiliza para cualquier derivación directa del alfabeto usado por los romanos. Estas variaciones pueden perder letras —como el italiano— o añadir letras —como es el caso del español— con respecto al alfabeto romano clásico. Muchas letras, por otro lado, han cambiado a lo largo de los siglos, como las minúsculas, forma desarrollada en la Edad Media que los romanos no habrían reconocido.
Historia
Su origen legendario aparece en la fábula 277 de Cayo Julio Higino quien cuenta la leyenda de como Carmenta, la sibila cimeria, alteró 15 letras del alfabeto griego para crear el alfabeto latino, y cómo su hijo Evandro lo llevó al Lacio sesenta años antes de la guerra de Troya.[1]
Se sostiene, generalmente, que los latinos adoptaron la variante occidental del alfabeto griego en el siglo VII a. C. de la colonia griega en Cumas (sur de Italia). No lo hicieron directamente, sino a través del antiguo alfabeto etrusco, del que adoptaron 21 de las 26 letras etruscas originales. La expansión del Imperio romano primero y, después, la cristianización de los pueblos de Europa, expandió sucesivamente su uso en el Mediterráneo, Europa del Norte y Central y más tarde los imperios coloniales europeos lo llevaron a los cinco continentes.
Alfabeto latino arcaico

MANIOS MED FHEFHAKED NVMASIOI, «Manios me hizo para Numerio»
El historiador Estrabón remonta la presencia griega en el sur de Italia a la guerra de Troya, pero, descartando explicaciones legendarias, sabemos que fue en los siglos VIII y VII a. C cuando estos se establecieron masivamente en la zona empujados por la sobrepoblación, las guerras y el desarrollo del comercio, dando lugar a la Magna Grecia.[2] El contacto de los griegos con los pueblos indígenas de la península itálica hizo surgir numerosos alfabetos itálicos. Puesto que en este período los etruscos eran la civilización de Italia más avanzada, se asume que todos estos derivan del alfabeto etrusco. Este alfabeto estaba basado en una variante de los alfabetos griegos arcaicos diferente a la del alfabeto griego clásico: la variante Eubea usada en las colonias griegas de Isquia y Cumas, en la bahía de Nápoles. Los latinos, los pueblos itálicos que vivían asentados en Latium estaban fuertemente influidos y los monarcas etruscos reinaban sobre Roma.
Algunas características de este período:
- Los etruscos no tenían el sonido /g/ por lo que usaban C (en griego gamma) igual que K y Q para el sonido /k/. La consonante se elegía según la vocal: C antes de E o I, K antes de A y Q antes de U (no tenían O). Los latinos que sí tenían el sonido /g/ heredarán este uso utilizando Q antes de O o U, K antes de A y C para los otros casos, y usarán estas tres letras también para el sonido /g/, por ejemplo «EQO» (ego), lo que provoca ambigüedad.
- F no hereda el valor que tenía en griego y etrusco (/w/) sino el sonido que los etruscos escribían como FH /f/.
- V se utilizará tanto para la vocal /u/ como la consonante /w/.
- Z se abandonó hacia el siglo V a. C. debido al fenómeno del rotacismo, por el que /z/ pasa a /s/ y luego a /r/.}
- Q diferencia el sonido único /kʷ/ distinto del grupo /kw/, por ejemplo se opone «QVI» /kʷi/ frente a «CVI» /ku̯i/ (con diptongo).
- Se escribe a menudo de derecha a izquierda, igual que el etrusco.
| Antiguo itálico | 𐌀 | 𐌁 | 𐌂 | 𐌃 | 𐌄 | 𐌅 | 𐌆 | 𐌇 | 𐌉 | 𐌊 | 𐌋 | 𐌌 | 𐌍 | 𐌏 | 𐌐 | 𐌒 | 𐌓 | 𐌔 | 𐌕 | 𐌖 | 𐌗 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Latino | A | B | C | D | E | F | Z | H | I | K | L | M | N | O | P | Q | R | S | T | V | X |
Alfabeto latino clásico

Abandono de K e invención de G
La nueva letra G se introdujo en el período del latín antiguo como una variante de la 'C' para poder distinguir la /ɡ/ sonora de la /k/ sorda. Plutarco atribuye esta innovación al liberto Espurio Carvilio Ruga, el primer romano en abrir una escuela de pago, que enseñó alrededor del 230 a. C.[3][4] También se atribuye a Apio Claudio. Autores modernos consideran que existía previamente y Carvilio Ruga solo promovió su uso, siendo su nombre un ejemplo de como la letra G soluciona la confusión al contener ambos sonidos: "ca" y "ga". A pesar del cambio, las abreviaturas de los praenomen Gaius y Gnaeus se mantendrán como C. y Cn. en una muestra de conservadurismo.
En el momento de surgir la G, la K había caído en desgracia por ser superflua, y 'C', que anteriormente había representado tanto /ɡ/ como /k/ antes de vocales abiertas, había llegado a expresar /k/ en todos los entornos. Apenas algunas palabras se mantuvieron utilizando la letra K, como por ejemplo «kalendae» o «kalator». QU solo se mantendría cuando es seguida de una vocal, por ejemplo en «quonian» pero no «curro». El antiguo gramático latino Prisciano etiquetaba a la K como «supervacua» (innecesaria). Posteriormente, según el gramático Quintiliano deberá evitarse siempre excepto cuando representa la abreviatura de una palabra entera como Kaeso, Kalendas o Kaput:[5]
Nam K quidem in nullis verbis utendum puto nisi quae significat etiam si sola ponatur. Hoc eo non omisi quod quidam eam quotiens A sequatur necessariam credunt, cum sit C littera, quae ad omnis vocalis vim suam perferat.En cuanto a K, mi punto de vista es que no debe usarse en ninguna palabra excepto en las que representa por sí misma. Menciono esto porque algunos sostienen que es obligatorio cuando sigue A, aunque poseemos C, que es capaz de transmitir su fuerza a cualquier vocal.Quintiliano. 1, 7, 10
Adopción de Y y Z
La cultura griega era ampliamente admirada por los romanos y tras la conquista de Grecia en el siglo I a. C. se adoptarían las letras griegas Υ y Ζ para representar estos dos sonidos del prestigioso dialecto griego ático. Antes, en su oratoria Quintiliano lamentaba que «carecemos de las dos letras griegas más agradables, una vocal y otra consonante, los sonidos más dulces de su idioma», poniendo como ejemplo que la imposibilidad de escribir palabras como zephyrus.[6]
La Y representaba a la vocal /y/ (como en francés cru (crudo) o alemán grün (verde)) en palabras griegas que antes habían contenido /u/. Puesto que /y/ no era un sonido nativo del latín aquellos que no habían aprendido griego lo pronunciaban como /i/ o como /u/. Algunas palabras latinas de origen itálico también adoptaron la Y, por ejemplo silva ('bosque') se escribía a menudo sylva, por analogía con el cognado griego ὕλη.[7]
La Z tomó el valor de la consonante africada /dz/. Antes de introducirse esta letra los romanos utilizaban una o dos S para transcribir palabras griegas, por ejemplo sōna para ζώνη "cinturón" y trapessita para τραπεζίτης "banquero"
Un intento por el emperador Claudio para introducir tres nuevas letras (letras claudias) duró poco tiempo.
El nuevo alfabeto latino contenía 23 caracteres:
| Letra | A | B | C | D | E | F | G | H | I | K | L | M | N | O | P | Q | R | S | T | V | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nombre | ā | bē | cē | dē | ē | ef | gē | hā | ī | kā | el | em | en | ō | pē | qū | er | es | tē | ū | ix | ī graeca | zēta |
Los nombres latinos de algunas letras son discutidos. La H probablemente tenía otro nombre en el latín hablado: basando en las lenguas romances actuales, este debe haber sido haca, a consecuencia de perder su sonido en épocas tardías del latín, pues era necesario distinguirla de la [a]. En general, de cualquier modo, los romanos no usaban los nombres tradicionales (derivados de los semitas) como en griego: los nombres de las consonantes oclusivas fueron formados añadiendo [eː] al sonido (excepto C, K y Q en las que se necesitaba diferentes vocales para distinguirlas) y los nombres de las fricativas consistieron en, ya sea el sonido en sí, o el sonido precedido de [ɛ]. Cuando se introdujo la letra Y fue, probablemente, llamada hy [hyː] como en griego (el nombre ípsilon no era usado todavía) pero se cambió por i graeca ("i griega") cuando el sonido [i] y [y] se mezclaron en latín. A la Z se le dio su nombre griego, zeta.
Desarrollo medieval y posterior
No fue hasta la Edad Media que se añadió la J (que representaba la I no silábica), y la U y la W (para distinguirlas de V). La W está formada por dos uves (VV) o úes (UU). Fue añadida en tiempos romanos tardíos para representar un sonido germánico. Las letras U y J, de manera similar, se consideraban originalmente como variantes de V e I respectivamente.
El alfabeto usado por los romanos comprendía únicamente las letras mayúsculas. Las minúsculas se desarrollaron, a partir de la grafía cursiva, en la Edad Media, primero como escritura uncial y luego como escritura minúscula. Las antiguas letras romanas se mantuvieron para inscripciones formales y para dar énfasis en documentos escritos. Las lenguas que usan el alfabeto latino, generalmente, usan letras mayúsculas para empezar párrafos y frases y para nombres propios. Las reglas de las mayúsculas han cambiado a lo largo del tiempo y no son las mismas para todos los idiomas.
A diferencia del español, idiomas como el inglés usan la mayúscula inicial para lenguas, nacionalidades y meses, entre otros; el alemán moderno capitaliza todos los sustantivos; el polaco capitaliza los pronombres.
Expansión del alfabeto latino
El alfabeto latino se expandió desde Italia, con la lengua latina, a las tierras alrededor del mar Mediterráneo con la expansión del imperio romano. La parte este del imperio romano, incluyendo Grecia, Asia Menor, Levante y Egipto, continuó usando la lengua griega como lingua franca, pero el latín era ampliamente hablado en la parte oeste del imperio y, del latín, se desarrollaron las lenguas romances occidentales incluyendo el español, francés, catalán, gallego, portugués e italiano, que continuaron usando y adaptando el alfabeto latino. Con la expansión del cristianismo, el alfabeto latino se extendió a los pueblos del norte de Europa que hablaban lenguas germánicas, desplazando sus anteriores alfabetos rúnicos, como también a las lenguas bálticas, como el lituano y el letón, y muchas lenguas no indoeuropeas como las fino-ugrias, más notablemente el húngaro, el finés y el estonio. Durante la Edad Media, el alfabeto latino se empezó a usar entre los hablantes de las lenguas eslavas occidentales, incluidos los ancestros de los polacos, checos, croatas, eslovenos y eslovacos modernos, a medida que adoptaban el catolicismo; los hablantes de las lenguas eslavas orientales, generalmente, adoptaron el cristianismo ortodoxo y el alfabeto cirílico.
Hasta 1492, el alfabeto latino estaba limitado a las lenguas habladas en Europa occidental, norte y central. Los Eslavos Cristianos Ortodoxos del este y sur de Europa, mayormente, usaban el alfabeto cirílico y el alfabeto griego se seguía usando entre los hablantes griegos alrededor del Mediterráneo oriental. El alfabeto árabe se extendió ampliamente entre el Islam, entre naciones árabes y no árabes, como los iranios, indonesios, malayos y los turcos. La mayor parte del resto de Asia usaba una variedad de alfabeto brahmi (devanagari) o escritura china.
A lo largo de los últimos 500 años, el alfabeto latino se ha expandido por todo el mundo. Llegó a América, Australia y a partes de Asia, África y el Pacífico bajo las colonias europeas, de mano de las lenguas española, portuguesa, inglesa, francesa y neerlandesa. En el siglo XVII, los rumanos adoptaron el alfabeto latino; aunque el rumano es una lengua romance, los rumanos eran predominantemente cristianos ortodoxos y, hasta el siglo XIX la Iglesia usaba el alfabeto cirílico. Vietnam, bajo dominio francés, adoptó el alfabeto latino para escribir el idioma vietnamita, que había usado los caracteres chinos con anterioridad. El alfabeto latino se usa también en muchas lenguas austronesias, incluyendo tagalo y otros idiomas de Filipinas, el malayo oficial y el indonesio, que reemplazó a los anteriores alfabetos árabe y brahmi. Otro idioma que adaptó la alfabetización latina fue el rapa nui.
En 1928, como parte de la reforma de Mustafa Kemal Atatürk, Turquía adoptó el alfabeto latino para el turco, reemplazando el alfabeto árabe. La mayoría de los hablantes de las lenguas túrquicas de la antigua Unión Soviética, incluidos los tártaros, los bashkirios, azeríes, los kazajos, los kirguís, etc. usaron el alfabeto túrquico uniforme en los años 1930. En los años 1940 todos esos alfabetos fueron reemplazados por el cirílico. Tras el colapso de la Unión Soviética en 1991, muchas de las recientemente independientes repúblicas de habla túrquica, adoptaron nuevamente el alfabeto latino, reemplazando al cirílico. Azerbaiyán, Uzbekistán y Turkmenistán han adoptado el alfabeto latino para las lenguas azerí, uzbeka y turcomana, respectivamente. Hay proyectos similares en Kazajistán. En los años 1970, la República Popular China desarrolló una transliteración oficial del chino mandarín al alfabeto latino, llamado pinyin, aunque todavía predomina el uso de caracteres chinos.

Las lenguas eslavas occidentales y la mayoría de las del sur, usan el alfabeto latino en vez del cirílico, como reflejo de la religión dominante entre esa gente. Entre ellos, el polaco, usa una variedad de diacríticos y dígrafos para representar valores fonéticos especiales, como también la l con barra (ł) para un sonido similar a la u en posición inicial de diptongo ([w] en AFI, similar a la w inglesa). En checo usa diacríticos como el háček. En croata, esloveno y en la versión latina del serbio también se usan háčeks y acentos agudos como en ć y barras como en đ.
Las lenguas de los eslavos orientales de la Iglesia ortodoxa, generalmente usan cirílico. En serbio se usan los dos. En los Balcanes no utilizan el alfabeto latino solamente Grecia y Bulgaria, aunque las minorías turcas de ambos países lo utilizan oficialmente para su lengua turca.
Recientemente las autoridades secesionistas de etnia albanesa de Kosovo han propuesto el uso exclusivo del alfabeto latino en perjuicio del cirílico, para cancelar todo vestigio de la dominación serbia en la región, de mayoría albanesa. Actualmente en Kazajistán por iniciativa del presidente del país, Nursultán Nazarbáyev, ha decidido que su lengua nacional se escriba en el alfabeto latino, igual que la mayoría de los idiomas túrquicos como parte de la estrategia de desarrollo estatal, abandonando el cirílico.[8][9]
En India recientemente ha sido propuesto el uso del alfabeto latino.
Extensiones
Visión general
El abecedario latino internacional moderno tiene como base al romano, añadiendo J, U, W y sus correspondientes formas minúsculas:
Se pueden formar letras adicionales:
- por ligadura: W era VV, & es igual a ET, Æ viene de AE, Œ de OE, ß de ſ y ʒ (s larga y z con cola), ŋ de NG, Ȣ de OU, Ñ de NN, ä de ae (véase Sütterlin), Ç de la Z visigoda y @ de AD.
- por diacríticos: como Ñ, Å, Č, Ų, Ĉ, Ĝ, Ĥ, Ĵ, Ŝ, Ŭ;
- por dígrafos: como IJ, LL, RR, CH;
- por modificación: como la J que era I, como Ø, eth (Ð), yogh (Ȝ) de G, o schwa (ə) de A o E; o
- pueden ser prestadas de otro alfabeto: como thorn (Þ) y wynn (Ƿ) —eran de la escritura rúnica—.
De todos modos, estos glifos no son siempre considerados letras independientes en el alfabeto. Por ejemplo, en inglés moderno æ se considera una variante gráfica de ae en vez de una letra por separado. También en latín, tanto æ como œ simplemente son variantes de los diptongos ae y oe; por lo tanto, tampoco se consideran letras independientes; mientras que en los alfabetos danés y noruego æ es una letra por sí misma y está situada al final del alfabeto conjuntamente con ø y aa/å. En francés, œ tampoco forma parte del alfabeto, simplemente es variante gráfica del diptongo oe. En español, la ch y la ll se consideraban letras independientes desde la Ortografía de 1754, pero desde la publicación de la Ortografía de 2010 son, oficialmente, dígrafos de c y h y l doble respectivamente. En el catalán y belsetano, existe la l·l geminada.
Con el paso del tiempo, el alfabeto latino ha sido adoptado para el uso de nuevas lenguas, algunas de las cuales tienen fonemas que no habían sido usados en las lenguas que tenían este alfabeto como medio de escritura. Por lo tanto, se crearon extensiones de este alfabeto cuando se necesitaban. Estas toman la forma de símbolos modificados cambiándoles la forma o añadiendo diacríticos, juntando varias letras con ligadura o creando nuevas formas.
A estas nuevas formas se les da un lugar en el alfabeto, como se verá más adelante.
Otras letras
- Por poco tiempo en la historia de Roma, se añadieron tres letras (letras claudias) al alfabeto, pero no tuvieron buena acogida y se eliminaron.
- En español y otras lenguas con relación histórica o cultural con el español se usa la ñ.
- En asturiano se usan la ḷḷ (che vaquera) y la ḥ (hache aspirada).
- El rumano usa la ț y la ș.
- En inglés antiguo fueron añadidas eth ð y las letras rúnicas thorn þ y wynn ƿ. Eth y thorn fueron reemplazadas por th y wynn por la nueva letra w.
- En islandés moderno, eth y thorn se siguen utilizando.
- En alemán se usa la letra ß, que en origen era una ligatura.
- El danés usa la å y la ø;
- En turco moderno las consonantes ç, ğ, ş y las vocales ı, ö, ü forman parte formalmente del alfabeto como letras independientes, mientras que en otras lenguas éstas solo representan letras modificadas por diacríticos como la ç del francés, portugués y catalán, que no forman parte del orden alfabético sino que se consideran una modificación de la c.
- La lengua africana hausa usa tres consonantes adicionales: ɓ, ɗ y ƙ, que son variantes de b, d y g. Y son usadas por lingüistas para representar ciertos sonidos que les son similares.
Ligaduras
Una ligadura es la fusión de dos o más letras ordinarias en un nuevo glifo. Ejemplos de ligaduras son Æ de AE, Œ de OE, ß de ſs, la ij neerlandesa de i y j. Nótese que ij en mayúsculas es IJ (y no Ij). El par ſs es simplemente la doble s arcaica. La primera parte (ſ) es la forma medieval arcaica y la segunda es su forma final (s). El francés usa el dígrafo Œ, como en sœur, bœuf, cœur...
Diacríticos
Los diacríticos son signos que se añaden a letras específicas para modificar su pronunciación. Las características que representan dependen de cada lengua.

- El acento agudo (o tilde en español) se encuentra en portugués, español, asturiano, gallego (á, é, í, ó, ú), en catalán (é, í, ó, ú), en francés (é), irlandés, e italiano (é, ó). Adicionalmente, ý también se usa en guaraní (á, é, í, ó, ú, ý), feroés (á, í, ó, ú, ý), islandés, checo y eslovaco. Cabe aclarar que los diacríticos no son de uso exclusivo en el alfabeto latino, en griego moderno se usa sobre cualquier vocal (ά, έ, ί, ό, ύ, ή, ώ). Tiene usos diferentes: Puede indicar acento tónico como en el caso de español y griego moderno o alargamiento vocálico en el caso de húngaro y checo en contraposición a las vocales simples. En francés modifica el sonido de e. En polaco (ć, ń, ś, ź) que representan letras independientes: ć es [tɕ] (una variante de la ch, que en polaco se escribe cz); ń es idéntica a nuestra ñ; ś es [ɕ] (una variante de la sh inglesa, que en polaco se escribe sz); y ź es [ʑ] (una variante de la j francesa, que en polaco se escribe ż). En vasco se utilizaban antiguamente las letras D́, Ĺ, Ŕ, T́ para sustituir gráficamente a la doble D, L, R y T respectivamente. Normalmente, era solo de aplicación para mayúsculas, observándose en cartelería y toponimia antigua.
- El acento grave en italiano (à, è, ì, ò, ù), en francés (à, è, ù), portugués (à), catalán (à, è, ò) entre otras lenguas.
- El acento circunflejo en francés (â, ê, î, ô, û), portugués (â, ê, ô), rumano (â, î y tienen su lugar en el alfabeto), en turco (â, î, û) y en otras lenguas; en las semivocales ŵ, ŷ en galés y en las consonantes ĉ, ĝ, ĥ, ĵ, ŝ en esperanto.
- La virgulilla, en portugués (ã y õ), en guaraní se consideran letras separadas en el alfabeto y se utilizan en ã, ẽ, ĩ, õ, ũ, ỹ, g̃ y ñ; en estonio (õ). En portugués, era originalmente una pequeña n escrita encima de la letra (marcaba la elisión de una antigua n, ahora marca la nasalización de la letra base). En estonio, õ se considera una letra del alfabeto por separado. En español ñ se considera una letra diferente de n y tiene el valor de sonido de /ɲ/. Representa la antigua grafía –nn– que se transformó al igual que el portugués en tilde suscrita, pero para representar un sonido completamente diferente.
- La diéresis (umlaut en alemán y tréma en francés) se encuentra en varias lenguas. En español, asturiano, gallego, catalán y el portugués de Brasil hasta 2008, ü indica que la u debe pronunciarse. En francés (ë, ï), griego moderno (ϊ) se usa para indicar un hiato, y también en español (en textos poéticos), gallego y catalán, en un uso distinto al caso anterior. En alemán (ä, ö, ü), en albanés y ladino (ë), y en turco moderno (ö y ü). Su finalidad es indicar un sonido diferente a sus homólogas sin diacrítico. En alemán, esta marca se escribía antiguamente con una pequeña e por encima de la vocal afectada. En turco representa los mismos sonidos del alemán. En aimara indica alargamiento vocálico.
- La coma suscrita es usada en rumano (ş y ţ; aconsejadas: ș y ț) a menudo presentada como una cedilla en fuentes tipográficas. También se usa en letón (ķ, ļ, ņ, ŗ) y en el Alfabeto Fonético Internacional.
- La cedilla en ç era originalmente una pequeña z escrita por debajo de la c: en otro tiempo simbolizó /ts/ en lenguas romances, hoy en día le da a c un sonido 'suave' cuando va antes de a, o y u; por ejemplo, /s/ en francés façade, portugués caçar y en catalán caçar. En albanés y turco la "ç" cambia la cualidad del sonido "c" y se pronuncia como "ch". En lengua turca la s con cedilla "ş" cambia el sonido "s" por el sonido "sh".
- El háček en č, š, ž es usado en lenguas bálticas y eslavas para marcar la versión postalveolar del fonema base. Se usa también en checo sobre ř y ě
- El punto sobreescrito en ċ, ġ, ż en maltés, ż en polaco, ė en lituano y ḃ, ċ, ḋ, ḟ, ġ, ṁ, ṗ, ṫ en ortografía tradicional irlandesa denota lenición. Se usaba en griego antiguo.
- El punto suscrito en ạ, ặ, ậ, ẹ, ệ, ị, ọ, ộ, ợ, ụ, ự, ỵ en vietnamita y en ḥ, ḷḷ en asturiano.
- El macrón en ā, ē, ī, ō, ū en letón, maorí, hawaiano, samogitiano (dialecto del lituano), pinyin (fonética del chino mandarín), rōmaji (japonés romanizado) y latín (cuando se indica duración de la vocal).
- El doble acento agudo en ő, ű en húngaro, representa versiones largas de las vocales con umlaut ö y ü.
- El breve en ă en rumano, ğ en turco moderno es para suavizar el sonido de g, y sobre todo para el alargamiento de la vocal anterior , ŭ es usada en esperanto y en el alfabeto łacinka del bielorruso. No se debe confundir con el carón cuya forma es un ángulo en vez de un semicírculo.
- la i sin punto (un "diacrítico negativo") ı se usa en turco.
- el gancho como en ả, ẳ, ẩ, ẻ, ể, ỉ, ỏ, ổ, ở, ủ, ử, ỷ en vietnamita.
- La barra como en đ, en croata, en vietnamita, y la versión con el alfabeto latino en lengua serbia (a, b, v...). Usada también en ŧ del sami septentrional y en ħ del maltés.
Clasificación alfabética con extensiones
Los alfabetos que derivan del latín tienen clasificaciones alfabéticas varias:
- En el alfabeto alemán, las letras con umlaut (Ä, Ö, Ü) son tratadas generalmente como no acentuadas o se escriben la Ä/ä: AE/ae, la Ö/ö: OE/oe, la Ü/ü: UE/ue; ß se clasifica como ss. Esto hace el orden alfabético: Arg, Ärgerlich, Arm, Assistant, Aßlar, Assoziation. En los directorios de teléfono y otras listas de nombres similares, los umlauts se encuentran en donde las combinaciones de letras "ae", "oe", "ue". Esto hace el orden alfabético: Udet, Übelacker, Uell, Ülle, Ueve, Üxküll, Uffenbach.
- En asturiano LL y CH tienen tratamiento de letra, y no está presente la J. Asimismo, existen los diacríticos Ḷḷ (ché vaqueira) y Ḥ (H aspirada). La primera representa variedades dialectales de LL "Ḷḷumi/Llumi" (Lumbre) o "Ḷḷeiti/Lleiti" (Leche) y se pronuncia como "j" en francés y portugués y Ḥ representa un sonido de H aspirada, similar a la H inicial inglesa, para palabras como guaḥe (niño).
- En bretón, no hay "c" pero existen las ligaduras "ch" y "c'h", que son clasificadas entre "b" y "d". Por ejemplo: « buzhugenn, chug, c'hoar, daeraouenn » (lombriz de tierra, zumo, hermana, lágrima).
- En checo y eslovaco, las vocales acentuadas tienen una clasificación secundaria –comparadas a otras letras, son tratadas como la letra base (A-Á, E-É-Ě, I-Í, O-Ó-Ô, U-Ú-Ů, Y-Ý), pero son clasificadas detrás de ésta (por ejemplo, el orden lexicográfíco correcto es baa, baá, báa, bab, báb, bac, bác, bač, báč). Las consonantes acentuadas, tienen clasificación primaria y son situadas inmediatamente después de las consonantes base, con excepción de Ď, Ň y Ť, que tienen un peso secundario. CH se considera una letra separada y va entre H y I. En eslovaco, DZ y DŽ también se consideran letras por separado y se sitúan entre Ď y E (A-Á-Ä-B-C-Č-D-Ď-DZ-DŽ-E-É…).
- En croata y esloveno y las lenguas eslavas familiares, los cinco caracteres acentuados y los tres dígrafos, se clasifican tras el original:..., C, Č, Ć, D, DŽ, Đ, E,..., L, LJ, M, N, NJ, O,..., S, Š, T,..., Z, Ž.
- En los alfabetos danés y noruego, existen las mismas vocales extras que en sueco (ver abajo), pero en diferente orden y con diferentes glifos (..., X, Y, Z, Æ, Ø, Å). Además, "Aa" se clasifica como una equivalencia de "Å". El alfabeto danés ha visto, tradicionalmente, la "W" como una variante de "V", pero hoy día se considera una letra por separado.
- En esperanto, tanto las consonantes con acento circunflejo (ĉ, ĝ, ĥ, ĵ, ŝ), como la ŭ (u con breve), se cuentan como letras separadas y se clasifican separadamente en su alfabeto (a, b, c, ĉ, d, e, f, g, ĝ, h, ĥ, i, j, ĵ... s, ŝ, t, u, ŭ, v, z).
- En estonio õ, ä, ö y ü se consideran letras separadas y se sitúan detrás de la w. Las letras š, z y ž aparecen solo en préstamos y nombres propios extranjeros y siguen a la letra s en su alfabeto que, sino, no se diferencia del alfabeto latino.
- En feroés también se tienen algunas de las letras danesas, noruegas y suecas, como Æ y Ø. Aparte de eso, el alfabeto feroés usa la letra islandesa eth ð, que sigue a la D. Cinco de las seis vocales (A, I, O, U y Y) pueden tener acentos y se sitúan tras la vocal base. Las consonantes C, Q, X, W y Z no aparecen. Por lo tanto, las cinco primeras letras son A, Á, B, D y Ð, y las últimas cinco V, Y, Ý, Æ, Ø.
- En filipino y otras lenguas de Filipinas, la letra Ng se considera una letra por separado. Además, letras derivadas (como Ñ) siguen a la letra base. En filipino también se usan diacríticos, pero no se usan ampliamente, excepto la tilde (~).
- El alfabeto finés y sus normas de clasificación alfabética, son iguales a las del sueco, con excepción de las adicionales Š y Ž, que se consideran variantes de S y Z.
- En el alfabeto francés e inglés, los caracteres con diéresis (ä, ë, ï, ö, ü, ÿ) se tratan normalmente igual que las letras inacentuadas. Si dos palabras difieren solo por un diacrítico en francés, la que lo tiene es mayor. (De todos modos, el libro de Unicode 3.0 enumera reglas más específicas para la clasificación tradicional de las letras acentuadas francesas).
- El galés también tiene reglas complejas: las combinaciones CH, DD, FF, NG, LL, PH, RH y TH se consideran letras simples, y cada una es listada detrás de la primera letra del dígrafo, con la excepción de NG que se lista tras G. De todas maneras, la situación es más complicada ya que estas combinaciones no son siempre letras simples. Un ejemplo del orden es: LAWR, LWCUS, LLONG, LLOM, LLONGYFARCH: la última de éstas palabras es una yuxtaposición de LLON y GYFARCH, y, contrariamente a LLONG, no contiene la letra NG.
- Las vocales húngaras tienen acentos, umlauts y doble acentos, mientras que las consonantes se escriben solas o en dígrafos. En la clasificación, las vocales acentuadas siguen a las no acentuadas y los dígrafos siguen a la letra simple original. El orden alfabético húngaro es: A, Á, B, C, CS, D, E, É, F, G, GY, H, I, Í, J, K, L, LY, M, N, NY, O, Ó, Ö, Ő, P, Q, R, S, SZ, T, TY, U, Ú, Ü, Ű, V, W, X, Y, Z, ZS. (Por ejemplo, el orden lexicográfico correcto es baa, baá, bab, bac, bacs,..., baz, bazs, báa, báá, báb, bác, bács).
- En islandés se añade Þ, y a D la sigue Ð. Cada vocal (A, E, I, O, U, Y) está seguida por su correspondiente con acento agudo: Á, É, Í, Ó, Ú, Ý. No hay Z, y Þ, Æ, Ö se sitúan tras Ý.
- En neerlandés, la combinación IJ (IJ), fue antiguamente situada como Y (o a veces, como una letra separada Y < IJ < Z), pero, actualmente, se clasifica como dos letras (II < IJ < IK). Los directorios de teléfono son excepciones; IJ se sitúa siempre como Y ya que en muchos apellidos se usa Y cuando la ortografía moderna hubiera requerido IJ. Nótese, que las palabras que empiezan con « ij » capitalizan ambas letras, como por ejemplo la ciudad de IJmuiden (Velsen) y el río IJssel.
- En polaco, los caracteres con acento agudo, ogonek o con punto se sitúan tras la letra base: A, Ą, B, C, Ć, D, E, Ę,..., L, Ł, M, N, Ń, O, Ó, P,..., S, Ś, T,..., Z, Ż, Ź. Esto es ya que representan diferentes sonidos, no solo variaciones de un mismo fonema (en polaco coloquial E y Ę se diferencian solo de su rasgo de oralidad-nasalidad, aunque tradicionalmente se hubieran diferenciado en más; Ó representa el sonido idéntico a U, vocal que también es usada en la lengua). Todas excepto las que tienen ogonek, pueden perderlo según el caso en el que están. Cuando esto sucede, se añade, generalmente, i detrás de la letra o r delante en el caso de Ż. En estos casos, son tratados como dos letras por separado. También tienen dígrafos como sz o rz que son tratados como dos letras, también.
- En rumano, los caracteres especiales derivados del alfabeto latino se sitúan tras los originales: A, Ă, Â,..., I, Î,..., S, Ş, T, Ţ,..., Z.
- En el alfabeto sueco, "W" es una variante de "V" y no una letra por separado. De todos modos, se mantiene en nombres como "William". El alfabeto también tiene tres vocales extra que se sitúan al final (..., X, Y, Z, Å, Ä, Ö).
- El abecedario español está hoy formado por las veintisiete letras siguientes: a, b, c, d, e, f, g, h, i, j, k, l, m, n, ñ, o, p, q, r, s, t, u, v, w, x, y, z. Asimismo, se emplean también cinco dígrafos para representar otros tantos fonemas: «ch», «ll», «rr», «gu» y «qu», considerados estos dos últimos como variantes posicionales para los fonemas /g/ y /k/.[10] Los dígrafos ch y ll tienen valores fonéticos específicos, por lo que en la Ortografía de la lengua española de 1754[11] comenzó a considerárseles como letras del alfabeto español y a partir de la publicación de la cuarta edición del Diccionario de la lengua española en 1803[12][13] se ordenaron separadamente de c y l,[14] y fue durante el X Congreso de la Asociación de Academias de la Lengua Española celebrado en Madrid en 1994, y por recomendación de varios organismos, que se acordó reordenar los dígrafos ch y ll en el lugar que el alfabeto latino universal les asigna, aunque todavía seguían formando parte del abecedario.[15] Con la publicación de la Ortografía de la lengua española de 2010, ambas dejaron de considerarse letras del abecedario.[16]
- En tártaro y turco, hay 9 letras adicionales. 5 de ellas son vocales, emparejadas con las letras originales como dura-suave: a-ä, o-ö, u-ü, í-i, ı-e. Las cuatro que quedan: ş es la sh inglesa, ç es ch, ñ es ng y ğ es gh.
El algoritmo de situación alfabética de Unicode puede ser usado para obtener cualquiera de las secuencias descritas aquí:
| Letra | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N.º | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 4A | 4B | 4C | 4D | 4E | 4F | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 5A |
| Letra | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| N.º | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 6A | 6B | 6C | 6D | 6E | 6F | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 7A |
Véase también
Referencias
- «Hyginus, Fabulae 200 - 277». (Mary Grant, trad.). Theoi Classical Texts Library (en inglés). Archivado desde el original el 4 de marzo de 2016. Consultado el 16 de julio de 2021.
- Cerchiai, Luca; Jannelli, Lorena; Longo, Fausto (2004). The Greek Cities of Magna Graecia and Sicily (en inglés). Getty Publications. pp. 14-18. ISBN 978-0-89236-751-1.
- Plutarco. Cuestiones.
- Gnanadesikan, Amalia E. (13 de septiembre de 2011). The Writing Revolution: Cuneiform to the Internet (en inglés). John Wiley & Sons. ISBN 9781444359855.
- «QUINTILIAN, The Orator's Education».
- «Appius Claudius Caecus and the Letter Z».
- Oxford English Dictionary Second edition, 1989; online version June 2011, s.v. 'sylva'
- Aragonés, Gonzalo (21 de abril de 2017). «Kazajistán se pasa al alfabeto latino». La Vanguardia. Consultado el 16 de julio de 2021.
- «Kazajistán adoptará el alfabeto latino para 2025». Agencia EFE. 12 de abril de 2017. Consultado el 16 de julio de 2021.
- Real Academia Española y Asociación de Academias de la Lengua Española (2010). Ortografía de la lengua española. Madrid: Espasa Calpe. p. 64. ISBN 978-6-070-70653-0.
5.4.1.1 Letras y dígrafos: el estatus de ch y ll
- Como ya se ha explicado (v. § 5.2), solo son propiamente letras los grafemas, esto es, los signos gráficos simples. Por esta razón, no deben formar parte del abecedario las secuencias de grafemas que se emplean para representar ciertos fonemas.
- En español, además de las veintisiete letras arriba indicadas, existen cinco dígrafos o combinaciones de dos letras, que se emplean para representar gráficamente los siguientes fonemas:
- a) El dígrafo ch representa el fonema /ch/: chapa, abochornar.
- b) El dígrafo ll representa el fonema /ll/ (o el fonema /y/ en hablantes yeístas): lluvia, rollo.
- c) El dígrafo gu representa el fonema /g/ ante e, i: pliegue, guiño.
- d) El dígrafo qu representa el fonema /k/ ante e, i: queso, esquina.
- e) El dígrafo rr representa el fonema /rr/ en posición intervocálica: arroz, tierra.
- «Desde la segunda edición de la ortografía académica, publicada en 1754, venían considerándose letras del abecedario español los dígrafos ch y ll (con los nombres respectivos de che y elle), seguramente porque cada uno de ellos se usaba para representar de forma exclusiva y unívoca un fonema del español (antes que la extensión del yeísmo alcanzara los niveles actuales y diera lugar a que hoy el dígrafo ll represente dos fonemas distintos, según que el hablante sea o no yeísta). Es cierto que se diferenciaban en esto de los demás dígrafos, que nunca han representado en exclusiva sus respectivos fonemas: el fonema /g/ lo representa también la letra g ante a, o, u (gato, goma, gula); el fonema /k/ se escribe además con c ante a, o, u y con k (cama, cola, cuento, kilo, Irak); y el fonema /rr/ se representa con r en posición inicial de palabra o detrás de consonante con la que no forma sílaba (rama, alrededor, enredo).
Sin embargo, este argumento no es válido desde la moderna consideración de las letras o grafemas como las unidades mínimas distintivas del sistema gráfico, con independencia de que representen o no por sí solas una unidad del sistema fonológico. Por lo tanto, a partir de este momento, los dígrafos ch y ll dejan de ser considerados letras del abecedario español, lo cual no significa, naturalmente, que desaparezcan de su sistema gráfico; es decir, estas combinaciones seguirán utilizándose como hasta ahora en la escritura de las palabras españolas. El cambio consiste, simplemente, en reducir el alfabeto a sus componentes básicos, ya que los dígrafos no son sino combinaciones de dos letras, ya incluidas de manera individual en el inventario. Con ello, el español se asimila al resto de las lenguas de escritura alfabética, en las que solo se consideran letras del abecedario los signos simples, aunque en todas ellas existen combinaciones de grafemas para representar algunos de sus fonemas.». Citado en RAE y ASALE (2010). Ortografía de la lengua española. Madrid: Espasa Calpe. pp. 64-65. ISBN 978-6-070-70653-0. - Ch, en el Diccionario de la lengua española de la Real Academia Española
- Ll, en el Diccionario de la lengua española de la Real Academia Española
- «Debido a su anterior consideración de letras del abecedario, los dígrafos ch y ll tuvieron un apartado propio en el diccionario académico desde su cuarta edición (1803) hasta la vigesimoprimera (1992), de modo que las palabras que comenzaban por esos dígrafos o los contenían se ordenaban alfabéticamente aparte, es decir, después de completarse la serie de palabras con c y l. En el X Congreso de la Asociación de Academias de la Lengua Española, celebrado en Madrid en 1994, sin dejar de considerar aún los dígrafos ch y ll como letras del abecedario, se acordó no tenerlos en cuenta como signos independientes a la hora de ordenar alfabéticamente las palabras del diccionario. Así, en la vigesimosegunda edición del DRAE (2001), primera publicada con posterioridad a dicho congreso, las palabras que incluían esos dígrafos ya se alfabetizaron en el lugar que les correspondía dentro de la c y de la l, respectivamente.». Citado en RAE y ASALE (2010). Ortografía de la lengua española. Madrid: Espasa Calpe. p. 65. ISBN 978-6-070-70653-0.
- Diccionario panhispánico de dudas, Santillana Ediciones Generales, ISBN 958-704-368-5, pág. 5-6
- Real Academia Española, ed. (2010). «Exclusión de los dígrafos ch y ll del abecedario». Consultado el 30 de noviembre de 2014.
| Control de autoridades |
|
|---|
 Datos: Q8229
Datos: Q8229 Multimedia: Latin alphabet / Q8229
Multimedia: Latin alphabet / Q8229