Unicode
Unicode es un estándar de codificación de caracteres diseñado para facilitar el tratamiento informático, transmisión, y visualización de textos de numerosos idiomas y disciplinas técnicas, además de textos clásicos de lenguas muertas. El término Unicode proviene de los tres objetivos perseguidos: universalidad, uniformidad, y unicidad.[1]



Unicode define cada carácter o símbolo mediante un nombre e identificador numérico, el punto de código (code point). Además incluye otras informaciones para el uso correcto de cada carácter, como sistema de escritura, categoría, direccionalidad, mayúsculas y otros atributos. Unicode trata los caracteres alfabéticos, ideográficos y símbolos de forma equivalente, lo que significa que se pueden mezclar en un mismo texto sin utilizar marcas o caracteres de control.[2]
Este estándar es mantenido por el Unicode Technical Committee (UTC), integrado en el Consorcio Unicode, del que forman parte con distinto grado de implicación empresas como: Microsoft, Apple, Adobe, IBM, Oracle, SAP, Google o Facebook, instituciones como la Universidad de Berkeley, o el Gobierno de la India y profesionales y académicos a título individual.[3] El Unicode Consortium mantiene estrecha relación con ISO/IEC, con la que mantiene desde 1991 el acuerdo de sincronizar sus estándares que contienen los mismos caracteres y puntos de código.[4]
La creación de Unicode ha sido un proyecto de gran relevancia con el objetivo de reemplazar los esquemas de codificación de caracteres existentes, los cuales presentaban limitaciones significativas en tamaño y compatibilidad con entornos plurilingües. Unicode se ha convertido en el esquema de codificación de caracteres más completo y extenso, siendo el dominante en la internacionalización y adaptación local del software informático. Este estándar ha sido ampliamente adoptado en diversas tecnologías recientes, como XML, Java y sistemas operativos modernos.
La descripción exhaustiva del estándar y las tablas de caracteres están disponibles en el sitio web oficial de Unicode. Cada vez que se finaliza una nueva versión principal, se publica una referencia completa en formato de libro, también está disponible en su versión digital de manera gratuita. Las revisiones y adiciones se publican de manera independiente.
Alcance del estándar
Unicode engloba todos los caracteres de uso común en la actualidad. La versión 15.0, por ejemplo, cuenta con 149.186 caracteres provenientes de diversos alfabetos, sistemas ideográficos y colecciones de símbolos, como aquellos utilizados en matemáticas, tecnología, música e iconografía. Esta cifra continúa aumentando en cada nueva versión.[5]
Unicode abarca una amplia gama de sistemas de escritura modernos, como el alfabeto latino, así como escrituras históricas extintas, utilizadas con fines académicos, tales como el cuneiforme y el rúnico. Además de los caracteres alfabéticos, Unicode también incluye una variedad de caracteres no alfabéticos, como símbolos musicales y matemáticos, fichas de juegos como el dominó, flechas, iconos, etc.
Además, Unicode incluye los signos diacríticos como caracteres individuales que pueden combinarse con otros caracteres, también ofrece versiones predefinidas de la mayoría de las letras con símbolos diacríticos utilizados en la actualidad, como las vocales acentuadas del español.
Unicode es un estándar en constante evolución, y se agregan nuevos caracteres de forma continua. Sin embargo, también se descartan ciertos alfabetos propuestos por diversas razones, como es el caso del alfabeto klingon.[6]
Relación con otros estándares
Unicode está sincronizado con el estándar ISO/IEC conocido como UCS o Juego de Caracteres Universal. Desde un punto de vista técnico, Unicode incluye o es compatible con codificaciones previas como ASCII7 o ISO 8859-1, así como con estándares nacionales como ANSI Z39.64, KS X 1001, JIS X 0208, JIS X 0212, JIS X 0213, GB 2312, GB 18030, HKSCS y CNS 11643, codificaciones particulares de fabricantes de software como Apple, Adobe, Microsoft, IBM, etc. Además, Unicode reserva espacio para que los fabricantes de software puedan crear extensiones para su propio uso.[7]
Repertorio de caracteres
El elemento básico del estándar Unicode es el carácter. Se considera un carácter al elemento más pequeño de un sistema de escritura con significado. El estándar Unicode codifica los caracteres esenciales ―grafemas― definiéndolos de forma abstracta y deja la representación visual (tamaño, dimensión, fuente o estilo) al software que lo trate, como procesadores de texto o navegadores web. Se incluyen letras, signos diacríticos, caracteres de puntuación, ideogramas, caracteres silábicos, caracteres de control y otros símbolos. Los caracteres se agrupan en alfabetos o sistemas de escritura. Se considera que son diferentes los caracteres de alfabetos distintos, aunque compartan forma y significación.
Los caracteres se identifican mediante un número o punto de código y su nombre o descripción. Cuando se ha asignado un código a un carácter, se dice que dicho carácter está codificado. El espacio para códigos tiene 1.114.112 posiciones posibles (0x10FFFF). Los puntos de código se representan utilizando notación hexadecimal agregando el prefijo U+. El valor hexadecimal se completa con ceros hasta 4 dígitos hexadecimales cuando es necesario; si es de longitud mayor que 4 dígitos no se agregan ceros.
Tipos de caracteres

Los bloques del espacio de códigos contienen puntos con la siguiente información:[8]
- Caracteres gráficos: letras, signos diacríticos, cifras, caracteres de puntuación, símbolos y espacios.
- Caracteres de formato: caracteres invisibles que afectan al proceso del texto próximo. Ejemplos: U+2028 salto de línea, U+2029 salto de párrafo, U+00A0 espacio duro, etc.
- Códigos de control: 65 códigos definidos por compatibilidad con ISO/IEC 2022. Son los caracteres entre los rangos [U+0000,U+001F], U+007F y [U+0080..U+009F]. Interpretarlos es responsabilidad de protocolos superiores.
- Caracteres privados: reservados para el uso fuera del estándar por fabricantes de software.
- Caracteres reservados: códigos reservados para su uso por Unicode. Son posiciones no asignadas.
- Suplentes inferiores o superiores: Unicode reserva los puntos de código de U+D800 a U+DFFF para su uso como códigos subrogados en UTF-16, en la representación de caracteres suplementarios.
- No caracteres: son códigos reservados permanentemente para uso interno por Unicode. Los dos últimos puntos de cada plano U+FFFE y U+FFFF.
Composición de caracteres y secuencias
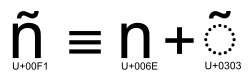
Unicode incluye un mecanismo para formar caracteres y así extender el repertorio de compatibilidad con los símbolos existentes. Un carácter base se complementa con marcas: signos diacríticos, de puntuación o marcos. El tipo de cada carácter y sus atributos definen el papel que pueden jugar en una combinación. Por este motivo, puede haber varias opciones que representen el mismo carácter. Para facilitar la compatibilidad con codificaciones anteriores, se proporcionan caracteres precompuestos; en la definición de dichos caracteres se hace constar qué caracteres intervienen en la composición.
Un grupo de caracteres consecutivos, independientemente de su tipo, forma una secuencia. En caso de que varias secuencias representen el mismo conjunto de caracteres esenciales, el estándar no define una de ellas como 'correcta', sino que las considera equivalentes. Para poder identificar dichas equivalencias, Unicode define los mecanismos de equivalencia canónica y de equivalencia de compatibilidad basados en la obtención de formas normalizadas de las cadenas a comparar.
Repertorio unificado chino, coreano y japonés
En el estándar Unicode, los ideogramas de Asia oriental (popularmente llamados «caracteres chinos») se denominan «ideogramas han». Estos ideogramas se desarrollaron en China y fueron adaptados por culturas próximas para su propio uso.[9][10] Japón, Corea y Vietnam desarrollaron sus propios sistemas alfabéticos o silábicos para usar en combinación con los símbolos chinos: hiragana y katakana (en Japón), hangul (en Corea) y yi (en Vietnam). La evolución natural de los sistemas de escritura y los distintos momentos de entrada de los caracteres en las distintas culturas han marcado diferencias en los ideogramas utilizados. Unicode considera las distintas versiones de los ideogramas como variantes de un mismo carácter abstracto, es decir, como resultado de la aplicación de un tipo de letra diferente en cada caso y considera las variantes nacionales como pertenecientes a un mismo sistema de escritura. La versión original del estándar se desarrolló a partir de los estándares industriales existentes en los países afectados.
El organismo encargado de desarrollar el repertorio de caracteres es el Ideographic Rapporteur Group (IRG). IRG es un grupo de trabajo integrado en ISO/IEC JTC1/SC2/WG2, incluyendo a China, Hong Kong, Macao, Taipei Computer Association, Singapur, Japón, Corea del Sur, Corea del Norte, Vietnam y Estados Unidos de América.[9]
La base de datos de caracteres CJK se denomina Unihan y contiene, además, información auxiliar sobre significado, conversiones, datos necesarios para utilizarlos en los diferentes lenguajes que los utilizan. A continuación se muestran los bloques que describen este repertorio. IRG define los caracteres de los siete grupos unificados; los dos grupos siguientes contienen caracteres para compatibilidad con estándares anteriores.
| Bloque | Plano | Rango | Caracteres | Comentarios |
|---|---|---|---|---|
| Ideogramas unificados CJK | 0 BMP | 4E00–9FFF | 20,992 | Ideogramas de uso común. |
| Ideogramas unificados CJK - Extensión A | 0 BMP | 3400–4DBF | 6,592 | Ideogramas de uso poco habitual. |
| Ideogramas unificados CJK - Extensión B | 2 SIP | 20000–2A6DF | 42,720 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión C | 2 SIP | 2A700–2B73F | 4,154 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión D | 2 SIP | 2B740–2B81F | 222 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión E | 2 SIP | 2B820–2CEAF | 5,762 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión F | 2 SIP | 2CEB0–2EBEF | 7,473 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión G | 3 TIP | 30000–3134F | 4,939 | Ideogramas de uso poco habitual e históricos. |
| Ideogramas unificados CJK - Extensión H | 3 TIP | 31350–323AF | 4,192 | Ideogramas de uso poco habitual e históricos. |
| Suplemento de radicales CJK | 0 BMP | 2E80–2EFF | 115 | Variantes y componentes de los radicales Kangxi. |
| Radicales Kangxi | 0 BMP | 2F00–2FDF | 214 | Radicales Kangxi. |
| Caracteres de descripción ideográfica | 0 BMP | 2FF0–2FFF | 12 | Composición de ideogramas. |
| Símbolos y puntuación CJK | 0 BMP | 3000–303F | 64 | Caracteres CJK especiales y signos de puntuación CJK. |
| Trazos CJK | 0 BMP | 31C0–31EF | 36 | Trazos mínimos de los ideogramas. |
| Compatibilidad CJK | 0 BMP | 3300–33FF | 256 | Caracteres CJK especiales. |
| Ideogramas de compatibilidad CJK | 0 BMP | F900–FAFF | 472 | Duplicados, variantes unificables y caracteres corporativos. |
| Formatos de compatibilidad CJK | 0 BMP | FE30–FE4F | 32 | Signos de puntuación para escritura vertical. |
| Suplemento de ideogramas de compatibilidad CJK | 2 SIP | 2F800–2FA1F | 542 | Variantes unificables. |
Secuencias de descripción ideográfica
Se admite que nunca se podrá finalizar la tarea de incluir ideogramas en el estándar debido, principalmente, a que la creación de nuevos ideogramas continúa. A fin de suplir eventuales carencias, Unicode ofrece un mecanismo que permite la representación de los símbolos que faltan denominado «secuencias de descripción ideográfica». Se basa en que en la práctica, la totalidad de los ideogramas se puede descomponer en piezas más pequeñas que, a su vez, son ideogramas. Aunque sea posible la representación de un símbolo mediante una secuencia, el estándar especifica que siempre que exista una versión codificada su uso debe ser preferente. No hay un método para la «descomposición canónica» de ideogramas ni algoritmos de equivalencia por lo que las operaciones sobre el texto, como búsqueda u ordenación, pueden fallar.
Unicode define 12 caracteres de control para la descripción de ideogramas representando distintas posibilidades de combinación espacial de otros caracteres han.
Elementos del estándar Unicode
Principios de diseño
El estándar fue diseñado con los siguientes objetivos:
- Universalidad: Un repertorio suficientemente amplio que albergue a todos los caracteres probables en el intercambio de texto multlingüe.
- Eficiencia: Las secuencias generadas deben ser fáciles de tratar.
- No ambigüedad: Un código dado siempre representa el mismo carácter.
Base de datos de caracteres
El conjunto de caracteres codificados por Unicode, es la UCD (unicode character database: base de datos de caracteres Unicode). Además de nombre y punto de código, incluye más información: alfabeto al que pertenece, nombre, clasificación, mayúsculas, orientación y otras formas de uso, variantes estandarizadas, reglas de combinación, etc.
Formalmente la base de datos se divide en planos y estos a su vez en áreas y bloques. Con excepciones, los caracteres codificados se agrupan en el espacio de códigos siguiendo categorías como alfabeto o sistema de escritura, de forma que caracteres relacionados se encuentren cerca en las tablas de codificación.
Planos
Por conveniencia se ha dividido el espacio de códigos en grandes grupos denominados planos. Cada plano contiene un máximo de 65 536 caracteres. Dado un punto de código expresado en hexadecimal, los 4 últimos dígitos determinan la posición del carácter en el plano.
- Plano básico multilingüe: BMP o plano 0. Contiene la mayor parte de los alfabetos modernos, incluidos los caracteres más comunes del sistema CJK, otros caracteres históricos o poco habituales y 64 reservadas para uso privado.
- Plano suplementario multilingüe: SMP o plano 1. Alfabetos históricos de menor uso y sistemas de uso técnico u otros usos.
- Plano suplementario ideográfico: SIP o plano 2. Contiene los caracteres del sistema CJK que no se incluyen en el plano 0. La mayoría son caracteres muy raros o de interés histórico.
- Plano de propósito especial: SSP o plano 14. Área para caracteres de control que no se han introducido en el plano 0.
- Planos de uso privado: planos 15 y 16. Reservados para uso privado por fabricantes de software.
Áreas y bloques
Los distintos planos se dividen en áreas de direccionamiento en función de los tipos generales que incluyen. Esta división es convencional, no reglada y puede variar con el tiempo. Las áreas se dividen, a su vez, en bloques. Los bloques están definidos normativamente y son rangos consecutivos del espacio de códigos. Los bloques se utilizan para formar las tablas impresas de caracteres pero no deben tomarse como definiciones de grupos significativos de caracteres.
Tratamiento de la información
Formas de codificación
Los puntos de código de Unicode se identifican por un número entero. Según su arquitectura, un ordenador utilizará unidades de 8, 16 o 32 bits para representar dichos enteros. Las formas de codificación de Unicode reglamentan la forma en que los puntos de código se transformarán en unidades tratables por el computador.
Unicode define tres formas de codificación bajo el nombre UTF (Unicode transformation format: formato de transformación Unicode):[11]
- UTF-8: codificación orientada a byte con símbolos de longitud variable.
- UTF-16: codificación de 16 bits de longitud variable optimizada para la representación del plano básico multilingüe (BMP).
- UTF-32: codificación de 32 bits de longitud fija, y la más sencilla de las tres.
Las formas de codificación se limitan a describir el modo en que se representan los puntos de código en formato inteligible por la máquina. A partir de las 3 formas identificadas se definen 7 esquemas de codificación.
Esquemas de codificación
Los esquemas de codificación tratan de la forma en que se serializa la información codificada.[11] La seguridad en los intercambios de información entre sistemas heterogéneos requiere la implementación de sistemas que permitan determinar el orden correcto de los bits y bytes y garantizar que la reconstrucción de la información es correcta. Una diferencia fundamental entre procesadores es el orden de disposición de los bytes en palabras de 16 y 32 bits, lo que se denomina endianness. Los esquemas de codificación deben garantizar que los extremos de una comunicación saben cómo interpretar la información recibida. A partir de las 3 formas de codificación se definen 7 esquemas. A pesar de que comparten nombres, no debe confundirse esquemas y formas de codificación.
| Esquema de codificación | Endianness | Admite BOM |
| UTF-8 | No aplicable | Sí |
| UTF-16 | Big-endian o Little-endian | Sí |
| UTF-16BE | Big-endian | No |
| UTF-16LE | Little-endian | No |
| UTF-32 | Big-endian o Little-endian | Sí |
| UTF-32BE | Big-endian | No |
| UTF-32LE | Little-endian | No |
Unicode define una marca especial, la marca de orden de bytes (BOM, Byte Order Mark), al inicio de un fichero o una comunicación para hacer explícita la ordenación de bytes. Cuando un protocolo superior especifica el orden de bytes, la marca no es necesaria y puede omitirse dando lugar a los esquemas de la lista anterior con sufijo BE o LE. En los esquemas UTF-16 y UTF-32, que admiten BOM, si este no se especifica se asume que la ordenación de bytes es big-endian.
La unidad de codificación en UTF-8 es el byte por lo que no necesita una indicación de orden de byte. El estándar ni requiere ni recomienda la utilización de BOM, pero lo admite como marca de que el texto es Unicode o como resultado de la conversión de otros esquemas.
Historia
El proyecto Unicode se inició a finales de 1987, tras conversaciones entre Joe Becker, Lee Collins y Mark Davis (ingenieros de las empresas Apple y Xerox).[12] Como resultado de su colaboración, en agosto de 1988 se publicó el primer borrador de Unicode bajo el nombre de Unicode88.[13] En esta primera versión se consideraba que solo se codificarían los caracteres necesarios para el uso moderno, por lo que se utilizaron códigos de 16 bits.
Durante el año 1989 se sumaron colaboradores de otras compañías como Microsoft o Sun Microsystems. El 3 de enero de 1991 se formó el Consorcio Unicode, y en octubre de 1991 se publicó la primera versión del estándar. La segunda versión, que ya incluía la escritura ideográfica han se publicó en junio de 1992. A continuación se muestra una tabla con las distintas versiones del Estándar Unicode con sus adiciones o modificaciones más importantes.
| Versión | Fecha | Publicación | Edición ISO/IEC 10646 asociada | Escrituras | Caracteres | |
|---|---|---|---|---|---|---|
| # | Adiciones notables | |||||
| 1.0 | octubre de 1991 | ISBN 0-201-56788-1 (Vol. 1). | 24 | 7161 | El repertorio inicial cubre los alfabetos: árabe, armenio, bengalí, bopomofo, cirílico, devanagari, georgiano, griego/copto, guyaratí, gurmukhi, hangul, hebreo, hiragana, kannada, katakana, lao, latino, malayalam, oriya, támil, télugu, thai, y tibetano.[14] | |
| 1.0.1 | junio de 1992 | ISBN 0-201-60845-6 (Vol.2). | 25 | 28 359 | Definido el primer conjunto de 20 902 ideogramas CJK unificados.[14] | |
| 1.1 | junio de 1993 | ISO/IEC 10646-1:1993 | 24 | 34 233 | Se agregan 4306 caracteres hangul, más al conjunto original de 2350. Se elimina el alfabeto tibetano.[14] | |
| 2.0 | julio de 1996 | ISBN 0-201-48345-9 | ISO/IEC 10646-1:1993 con enmiendas 5, 6 y 7 | 25 | 38 950 | Eliminado el conjunto original de caracteres hangul; se agrega un nuevo conjunto de 11 172 caracteres hangul en una nueva ubicación. Se reincorpora el alfabeto tibetano en una nueva ubicación y con un juego de caracteres diferente. Se define el sistema de códigos subrogados y se crean los planos 15 y 16 de caracteres para uso privado.[14] |
| 2.1 | mayo de 1998 | ISO/IEC 10646-1:1993 con enmiendas 5, 6 y 7, y dos caracteres de la enmienda 18 | 25 | 38 952 | Se agrega el símbolo del euro.[14] | |
| 3.0 | septiembre de 1999 | ISBN 0-201-61633-5 | ISO/IEC 10646-1:2000 | 38 | 49 259 | Ideogramas cheroqui. Escrituras etíope, jemer, mongol, Myanmar, ogham, alfabeto rúnico, cingalés, siríaco, thaana, silabario unificado de los indígenas canadienses, y yi además de los patrones braille.[14] |
| 3.1 | marzo de 2001 | ISO/IEC 10646-1:2000
ISO/IEC 10646-2:2001 |
41 | 94 205 | Se agregan los alfabetos deseret, gótico y etrusco, y los símbolos de notación musical moderna, música bizantina, y 42 711 ideogramas de CJK unificado.[15] | |
| 3.2 | marzo de 2002 | ISO/IEC 10646-1:2000 con la enmienda 1
ISO/IEC 10646-2:2001 |
45 | 95 221 | Agregadas las escrituras filipinas: buhid, hanunó'o, tagalo, y tagbanwa.[15] | |
| 4.0 | abril de 2003 | ISBN 0-321-18578-1 | ISO/IEC 10646:2003 | 52 | 96 447 | Se agrega el silabario chipriota, limbu, lineal B, osmanya, shaviano, tai le, y ugarítico, y los hexagramas I Ching.[15] |
| 4.1 | marzo de 2005 | ISO/IEC 10646:2003 con enmienda 1 | 59 | 97 720 | Agregados buginés, glagolítico, kharoshthi, new tai lue, persa antiguo, syloti nagri, y nifinagh. Se separa el copto del alfabeto griego. Símbolos griegos antiguos para música y numeración.[15] | |
| 5.0 | julio de 2006 | ISBN 0-321-48091-0 | ISO/IEC 10646:2003 con enmiendas 1 y 2 y cuatro caracteres de la enmienda 3 | 64 | 99 089 | Agregados: balinés, cuneiforme, n'ko (mandé), phags-pa, y fenicio.[15] |
| 5.1 | abril de 2008 | ISO/IEC 10646:2003 más enmiendas 1, 2, 3 y 4 | 75 | 100 713 | Agregados: escritura caria, cham, kayah li, escritura lepcha, alfabeto licio, alfabeto lidio, alfabeto ol chiki, rejang, saurashtra, sundanés, y el silabario vai. Los jeroglíficos del disco de Festos, fichas de mahjong y de dominó. Adiciones importantes para el birmano, letras y abreviaturas de amanuense utilizadas en manuscritos medievales y la adición de la ß mayúscula.[16] | |
| 5.2 | octubre de 2009 | ISBN 978-1-936213-00-9 | ISO/IEC 10646:2003 más enmiendas de 1 a 6 | 90 | 107 361 | Agregados: bamúm, javanés, lisu, meetei mayek, samaritano, tai tham, y tai viet. Se ha ampliado el devanagari con la adición del alfabeto sánscrito. Ampliaciones importantes para abjasio, el silabario unificado de los indígenas canadienses, copto, khamti shan, malayo, myanmar. También se agregan símbolos y caracteres históricos como los jeroglíficos egipcios de Gardiner, arameo imperial, avéstico, kaithi, antiguo árabe del Sur y turco antiguo.[17] |
| 6.0 | octubre de 2010 | ISBN 978-1-936213-01-6 | ISO/IEC 10646:2011 | 93 | 109 449 |
La versión 6.0 es la primera versión principal del estándar publicada exclusivamente en soporte electrónico. Agregados mandeo, batak y brahmi, ampliaciones de lenguajes africanos como tifinagh, etíope y bamúm. Otras adiciones importantes son: 222 ideogramas CJK, 1000 símbolos incluyendo los pictogramas emoji, el nuevo símbolo oficial para la rupia y símbolos alquímicos además de ampliaciones de los atributos de los caracteres y otras modificaciones normativas y algorítmicas.[18] |
| 6.1 | 2012 | ISBN 978-1-936213-02-3 | ISO/IEC 10646:2012 | 110 116 | Incluye extensiones de varios alfabetos existentes; son significativas las adiciones al alfabeto árabe que incluyen 143 símbolos matemáticos alfabéticos, y los alfabetos Pollard Miao, Sorang Sompeng, escritura meroítica, Chakma, Alfabeto sharada y 13 emoticonos. | |
| 6.2 | 2012 | ISBN 978-1-936213-07-8 | ISO/IEC 10646:2012 más símbolo de la lira turca. | 110 117 | Publicación especial para la introducción de la Lira turca | |
| 6.3 | 2013 | ISBN 978-1-936213-08-5 | ISO/IEC 10646:2012 con adiciones | 110 122 | Revisión del algoritmo de texto bidireccional con la adición de 5 caracteres especiales. El nuevo algoritmo bidireccional mejora la representación conjunta de textos de diferentes fuentes respetando el orden correcto de los caracteres. | |
| 7.0 | 2014 | ISBN 978-1-936213-09-2 | ISO/IEC 10646:2012 con adiciones y signo del rublo | 112 956 | Agrega 23 nuevos sistemas de escritura. | |
| 8.0 | 2015 | ISBN 978-1-936213-10-8 | ||||
| 9.0 | 2016 | ISBN 978-1-936213-13-9 | ||||
| 10.0 | 2017 | ISBN 978-1-936213-16-0 | 139 | 136 690 | Entre otros se agrega el símbolo de Bitcoin, 56 caracteres emoji y los sistemas de escritura: Masaram Gondi, Nü Shu, Soyombo y la escritura mongola cuadrada de Zanabazar. Se introduce la extensión F de caracteres unificados CJK. | |
| 11.0 | 5 de junio de 2018 | ISBN 978-1-936213-19-1 | 137 374 | Dogra, letras capitales de Georgian Mtavruli, Gunjala Gondi, Hanifi Rohingya, Makasar, Medefaidrin, Old Sogdian, Sogdian, y varios símbolos (5 nuevos ideogramas unificados CJK, 66 emoji adicionales, copyleft, media estrella, símbolos astrológicos adicionales y de ajedrez chino Xiangqi) | ||
| 12.0 | 5 de marzo de 2019 | ISBN 978-1-936213-22-1 | 150 | 137 928 | Elimaico[19] | |
| 12.1 | 7 de mayo de 2019 | ISBN 978-1-936213-25-2 | 137 929 | Añade un único carácter para la Era Reiwa[20] | ||
| 13.0 | 10 de marzo de 2020 | ISBN 978-1-936213-26-9 | 154 | 143.859 | Añade 4 nuevos alfabetos Corasmio, Dhives Akuru, Idioma kitán[21] | |
| 14.0 | 14 de septiembre de 2021 | 144 697 | Toto, Cypro-Minoan, Vithkuqi, Old Uyghur, Tangsa, adiciones de escritura latina en bloques SMP (Ext-F, Ext-G) para usar en IPA extendido, adiciones de escritura árabe para usar en idiomas de África y en Irán, Pakistán , Malasia, Indonesia, Java y Bosnia, y para escribir honoríficos, adiciones para uso coránico, otras adiciones para admitir idiomas en América del Norte, Filipinas, India y Mongolia, adición del símbolo de moneda som de Kirguistán, soporte para Znamenny notación musical y 37 emojis. | |||
| 15.0 | 13 de septiembre de 2022 | 149 186 | Kawi y Mundari, varias letras nuevas que incluyen 20 emojis, 4192 ideogramas CJK y caracteres de control de jeroglíficos egipcios | |||
Véase también
Referencias
- «Resumen histórico». Unicode, Inc. Consultado el 21 de mayo de 2009.
- «About the Unicode Standard». Unicode, Inc. Consultado el 21 de mayo de 2009.
- «The Unicode Consortium Members». Unicode, Inc. Consultado el 15 de mayo de 2012.
- The Unicode Consortium (octubre de 2006). «Appendix C. Relationship to ISO/IEC10646». En Julie D. Allen, Joe Becker (et al.), ed. Unicode 5.0 standard (en inglés). Addisson-Wesley. ISBN 0-321-48091-0.
- «Unicode 15.0.0» (en inglés). 2022 September.
- «Archive of Notices of Non-Approval». Unicode, Inc. Archivado desde el original el 3 de marzo de 2016. Consultado el 21 de mayo de 2009.
- The Unicode Consortium (octubre de 2006). Julie D. Allen, Joe Becker (et al.), ed. Unicode 5.9 standard (en inglés). Addisson-Wesley. ISBN 0-321-48091-0.
- The Unicode Consortium (octubre de 2006). «16. Special Areas and Format Characters». En Julie D. Allen, Joe Becker (et al.), ed. Unicode 5.0 standard (en inglés). Addisson-Wesley. ISBN 0-321-48091-0.
- «On the Encoding of Latin, Greek, Cyrillic, and Han».
- «12. East Asian Scripts». Unicode 5.0 Standard.
- The Unicode Consortium (octubre de 2006). «2.5 Encoding Forms». En Julie D. Allen, Joe Becker (et al.), ed. Unicode 5.0 standard (en inglés). Addisson-Wesley. ISBN 0-321-48091-0.
- «Chronology of Unicode Version 1.0».
- Becker, Joseph D. (10 de septiembre). Unicode 88 (en inglés). Unicode Consortium. p. 10. Consultado el 29 de mayo de 2009.
- The Unicode Consortium, Joan Aliprand, et al. (enero de 2000). «Appendix D. Changes from Unicode Version 2.0». The Unicode Standard. Version 3.0 standard (en inglés). Addisson-Wesley. ISBN 0-201-61633-5. Archivado desde el original el 17 de noviembre de 2008. Consultado el 28 de julio de 2009.
- The Unicode Consortium (octubre de 2006). «Appendix D. Changes from previous versions». En Julie D. Allen, Joe Becker (et al.), ed. Unicode 5.0 standard (en inglés). Addisson-Wesley. ISBN 0-321-48091-0.
- Archivo de datos de Unicode 5.1
- Unicode 5.2.0
- Unicode 6.0.0
- «Unicode 12.0.0» (en inglés). 5 de marzo de 2019.
- «Unicode 12.1.0» (en inglés). 7 de mayo de 2019.
- «Unicode 13.0.0» (en inglés). 10 de marzo de 2020.
Enlaces externos
- Unicode Consortium, en el sitio web Unicode.org.
- Historia de la unificación han, en el sitio web Unicode.org.
- Catálogo de sistemas de escritura y hojas de caracteres, en el sitio web Unicode.org.
- Emojis y su Unicode
- Todos los caracteres Unicode, emoji y fuentes en Windows 10
| Control de autoridades |
|
|---|