Análisis de sensibilidad (estadística)
Para temas financieros ver Análisis de sensibilidad
El análisis de sensibilidad es el estudio de cómo la incertidumbre en la salida de un modelo matemático o sistema (numérico o de otro tipo) puede dividirse y asignarse a diferentes fuentes de incertidumbre en sus entradas. Una práctica relacionada es el análisis de incertidumbre, que se centra más en la cuantificación de la incertidumbre y la propagación de la incertidumbre; lo ideal es que el análisis de incertidumbre y el de sensibilidad se realicen a la vez.
El proceso de recalcular los resultados con hipótesis alternativas para determinar el impacto de una variable en el análisis de sensibilidad puede ser útil para diversos fines,[1] entre ellos:
- Comprobación de la solidez de los resultados de un modelo o sistema en presencia de incertidumbre.
- Mayor comprensión de las relaciones entre las variables de entrada y salida de un sistema o modelo.
- Reducción de la incertidumbre, mediante la identificación de los datos de entrada del modelo que causan una incertidumbre significativa en el resultado y que, por tanto, deberían ser objeto de atención para aumentar la robustez (tal vez mediante nuevas investigaciones).
- Búsqueda de errores en el modelo (al encontrar relaciones inesperadas entre entradas y salidas).
- Simplificación del modelo: fijación de las entradas del modelo que no afectan al resultado o identificación y eliminación de las partes redundantes de la estructura del modelo.
- Mejorar la comunicación de los modelizadores con los responsables de la toma de decisiones (por ejemplo, haciendo las recomendaciones más creíbles, comprensibles, convincentes o persuasivas).
- Encontrar regiones en el espacio de los factores de entrada para las que el resultado del modelo sea máximo o mínimo o cumpla algún criterio óptimo (véase optimización y filtrado de Montecarlo).
- En caso de calibrar modelos con un gran número de parámetros, una prueba de sensibilidad primaria puede facilitar la fase de calibración centrándose en los parámetros sensibles. No conocer la sensibilidad de los parámetros puede hacer que se invierta tiempo inútilmente en los no sensibles.[2]
- Tratar de identificar conexiones importantes entre las observaciones, los datos de entrada del modelo y las predicciones o previsiones, que conduzcan al desarrollo de mejores modelos.[3][4]
Descripción general
Un modelo matemático (por ejemplo, en biología, cambio climático, economía o ingeniería) puede ser muy complejo y, como consecuencia, sus relaciones entre entradas y salidas pueden ser poco comprensibles. En tales casos, el modelo puede considerarse una caja negra, es decir, el resultado es una función "opaca" de sus entradas. A menudo, algunas o todas las entradas del modelo están sujetas a fuentes de incertidumbre, como errores de medición, ausencia de información y comprensión deficiente o parcial de las fuerzas y mecanismos impulsores. Esta incertidumbre limita nuestra confianza en la respuesta o el resultado del modelo. Además, los modelos pueden tener que hacer frente a la variabilidad intrínseca natural del sistema (aleatoria), como la aparición de sucesos estocásticos.[5]
En los modelos en los que intervienen muchas variables de entrada, el análisis de sensibilidad es un ingrediente esencial de la construcción de modelos y la garantía de calidad. Los organismos nacionales e internacionales que participan en estudios de evaluación de impacto han incluido en sus directrices secciones dedicadas al análisis de sensibilidad. Algunos ejemplos son la Comisión Europea (véanse, por ejemplo, las directrices para la evaluación de impacto),[6] la Oficina de Administración y Presupuesto de la Casa Blanca, el Grupo Intergubernamental de Expertos sobre el Cambio Climático y las directrices de modelización de la Agencia de Protección Ambiental de EE.UU.[7]
Ajustes, limitaciones y temas relacionados
Ajustes y limitaciones
La elección del método de análisis de sensibilidad suele venir dictada por una serie de restricciones o ajustes del problema. Algunas de las más comunes son:
- Gasto computacional: El análisis de sensibilidad casi siempre se realiza ejecutando el modelo un número (posiblemente elevado) de veces, es decir, un enfoque basado en el muestreo.[8] Esto puede suponer un problema importante cuando,
- Una sola ejecución del modelo lleva una cantidad de tiempo considerable (minutos, horas o más). Esto no es inusual con modelos muy complejos.
- El modelo tiene un gran número de entradas inciertas. El análisis de sensibilidad es esencialmente la exploración del espacio multidimensional de entrada, que crece exponencialmente en tamaño con el número de entradas. Véase la maldición de la dimensionalidad.
El gasto computacional es un problema en muchos análisis de sensibilidad prácticos. Algunos métodos para reducir el gasto computacional incluyen el uso de emuladores (para modelos grandes) y métodos de cribado (para reducir la dimensionalidad del problema). Otro método consiste en utilizar un método de análisis de sensibilidad basado en eventos para la selección de variables en aplicaciones con restricciones temporales[9]. Se trata de un método de selección de variables de entrada (IVS) que reúne información sobre la traza de los cambios en las entradas y salidas del sistema utilizando el análisis de sensibilidad para producir una matriz de eventos/desencadenantes de entrada/salida que está diseñada para mapear las relaciones entre los datos de entrada como causas que desencadenan eventos y los datos de salida que describen los eventos reales. La relación causa-efecto entre las causas del cambio de estado, es decir, las variables de entrada, y los parámetros de salida del sistema de efectos determina qué conjunto de entradas tiene un verdadero impacto en una salida determinada. El método tiene una clara ventaja sobre el método IVS analítico y computacional, ya que trata de comprender e interpretar el cambio de estado del sistema en el menor tiempo posible con una sobrecarga computacional mínima.[9][10]
- Entradas correlacionadas: La mayoría de los métodos habituales de análisis de sensibilidad presuponen la independencia entre las entradas del modelo, pero a veces las entradas pueden estar fuertemente correlacionadas. Se trata de un campo de investigación aún inmaduro y todavía no se han establecido métodos definitivos.
- No linealidad: Algunos enfoques de análisis de sensibilidad, como los basados en la regresión lineal, pueden medir de forma inexacta la sensibilidad cuando la respuesta del modelo no es lineal con respecto a sus entradas. En tales casos, las medidas basadas en la varianza son más apropiadas.
- Múltiples salidas: Prácticamente todos los métodos de análisis de sensibilidad consideran una única salida univariante del modelo, pero muchos modelos arrojan un gran número de datos que posiblemente dependen del espacio o del tiempo. Tenga en cuenta que esto no excluye la posibilidad de realizar diferentes análisis de sensibilidad para cada salida de interés. Sin embargo, para los modelos en los que las salidas están correlacionadas, las medidas de sensibilidad pueden ser difíciles de interpretar.
Suposiciones frente a inferencias
En el análisis de incertidumbre y sensibilidad, existe un equilibrio crucial entre la escrupulosidad del analista a la hora de explorar los supuestos de entrada y la amplitud de la inferencia resultante. El econometrista Edward E. Leamer ilustra bien esta cuestión:[11][12]
He propuesto una forma de análisis de sensibilidad organizado que denomino "análisis de sensibilidad global", en el que se selecciona un vecindario de supuestos alternativos y se identifica el correspondiente intervalo de inferencias. Se considera que las conclusiones son sólidas sólo si el vecindario de supuestos es lo suficientemente amplio como para ser creíble y el intervalo de inferencias correspondiente es lo suficientemente estrecho como para ser útil.
Obsérvese que Leamer hace hincapié en la necesidad de "credibilidad" en la selección de los supuestos. La forma más fácil de invalidar un modelo es demostrar que es frágil con respecto a la incertidumbre en los supuestos o demostrar que sus supuestos no se han tomado con la "suficiente amplitud". El mismo concepto expresa Jerome R. Ravetz, para quien modelizar mal es cuando hay que suprimir las incertidumbres en los inputs para que los outputs no se vuelvan indeterminados.[13]
Obstáculos y dificultades
Algunas dificultades habituales en el análisis de sensibilidad son:
- Demasiadas entradas de modelo para analizar. El cribado puede utilizarse para reducir la dimensionalidad. Otra forma de abordar la maldición de la dimensionalidad es utilizar el muestreo basado en secuencias de baja discrepancia.[14]
- El modelo tarda demasiado en ejecutarse. Los emuladores (incluida la Representación de Modelos de Alta Dimensionalidad (HDMR)) pueden reducir el tiempo total acelerando el modelo o reduciendo el número de ejecuciones del modelo necesarias.
- No hay información suficiente para construir distribuciones de probabilidad para las entradas. Las distribuciones de probabilidad pueden construirse a partir de la consulta a expertos, aunque incluso en este caso puede ser difícil construir distribuciones con gran fiabilidad. La subjetividad de las distribuciones o rangos de probabilidad afectará mucho al análisis de sensibilidad.
- Propósito poco claro del análisis. Se aplican diferentes pruebas y medidas estadísticas al problema y se obtienen diferentes clasificaciones de los factores. En su lugar, la prueba debería adaptarse al propósito del análisis, por ejemplo, se utiliza el filtrado Monte Carlo si se está interesado en qué factores son los más responsables de generar valores altos/bajos de la salida.
- Se consideran demasiadas salidas del modelo. Esto puede ser aceptable para garantizar la calidad de los submodelos, pero debe evitarse al presentar los resultados del análisis global.
- Sensibilidad a trozos. Es cuando se realiza el análisis de sensibilidad en un submodelo cada vez. Este enfoque no es conservador, ya que podría pasar por alto las interacciones entre los factores en diferentes submodelos (error de tipo II).
Métodos de análisis de sensibilidad
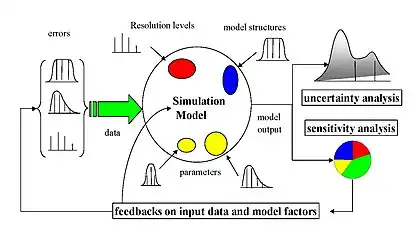
Existe un gran número de enfoques para realizar un análisis de sensibilidad, muchos de los cuales se han desarrollado para abordar una o varias de las limitaciones comentadas anteriormente. También se distinguen por el tipo de medida de sensibilidad, ya sea basada en (por ejemplo) descomposiciones de varianza, derivadas parciales o efectos elementales. En general, sin embargo, la mayoría de los procedimientos se ciñen al esquema siguiente:
- Cuantificar la incertidumbre en cada entrada (por ejemplo, rangos, distribuciones de probabilidad). Tenga en cuenta que esto puede ser difícil y que existen muchos métodos para obtener distribuciones de incertidumbre a partir de datos subjetivos.[15]
- Identificar el resultado del modelo que se va a analizar (lo ideal es que el objetivo de interés tenga una relación directa con el problema abordado por el modelo).
- Ejecutar el modelo varias veces utilizando algún diseño de experimentos,[16] dictado por el método elegido y la incertidumbre de entrada.
- A partir de los resultados del modelo, calcule las medidas de sensibilidad que le interesen.

En algunos casos, este procedimiento se repetirá, por ejemplo en problemas de gran dimensión en los que el usuario tenga que descartar variables sin importancia antes de realizar un análisis de sensibilidad completo.
Los distintos tipos de "métodos básicos" (que se examinan más adelante) se distinguen por las diversas medidas de sensibilidad que se calculan. Estas categorías pueden solaparse de algún modo. Se pueden dar formas alternativas de obtener estas medidas, bajo las restricciones del problema.
Uno a la vez (OAT)
Artículo principal: Método del factor único
Uno de los enfoques más sencillos y comunes es el de cambiar un factor cada vez (OAT), para ver qué efecto produce en el resultado.[17][18][19] El OAT suele implicar:
- moviendo una variable de entrada, manteniendo las demás en sus valores de referencia (nominales), entonces,
- devolviendo la variable a su valor nominal, y repitiendo para cada una de las otras entradas de la misma manera
La sensibilidad puede medirse controlando los cambios en el resultado, por ejemplo, mediante derivadas parciales o regresión lineal. Éste parece un enfoque lógico, ya que cualquier cambio observado en el resultado se deberá inequívocamente a la única variable modificada. Además, al cambiar una variable cada vez, se pueden mantener todas las demás fijas en sus valores centrales o de referencia. Esto aumenta la comparabilidad de los resultados (todos los "efectos" se calculan con referencia al mismo punto central en el espacio) y minimiza las posibilidades de que se bloquee el programa informático, algo más probable cuando se modifican simultáneamente varios factores de entrada. Los modelizadores suelen preferir la OAT por razones prácticas. En caso de fallo del modelo, el modelizador sabe inmediatamente cuál es el factor de entrada responsable del fallo.
Sin embargo, a pesar de su simplicidad, este enfoque no explora completamente el espacio de entrada, ya que no tiene en cuenta la variación simultánea de las variables de entrada. Esto significa que el enfoque OAT no puede detectar la presencia de interacciones entre las variables de entrada y no es adecuado para modelos no lineales.[20]
La proporción de espacio de entrada que queda sin explorar con un enfoque OAT crece superexponencialmente con el número de entradas. Por ejemplo, un espacio de parámetros de 3 variables que se explora de una en una equivale a tomar puntos a lo largo de los ejes x, y y z de un cubo centrado en el origen. El casco convexo que delimita todos estos puntos es un octaedro que tiene un volumen de sólo 1/6 del espacio de parámetros total. Más generalmente, el casco convexo de los ejes de un hiperrectángulo forma un hiperoctaedro que tiene un volumen de . Con 5 entradas, el espacio explorado ya desciende a menos del 1% del espacio total de parámetros. E incluso esto es una sobreestimación, ya que el volumen fuera del eje no se está muestreando en absoluto. Compárese con el muestreo aleatorio del espacio, en el que el casco convexo se aproxima a todo el volumen a medida que se añaden más puntos.[21] Aunque en teoría la escasez de OAT no es un problema para los modelos lineales, la verdadera linealidad es rara en la naturaleza.

Métodos locales basados en derivados
Los métodos basados en la derivada local consisten en tomar la derivada parcial de la salida Y con respecto a un factor de entrada Xi:

donde el subíndice x0 indica que la derivada se toma en un punto fijo del espacio de entrada (de ahí el "local" del nombre de la clase). El modelado adjunto[22][23] y la diferenciación automatizada[24] son métodos de esta clase. Al igual que la OAT, los métodos locales no intentan explorar completamente el espacio de entrada, ya que examinan pequeñas perturbaciones, normalmente una variable cada vez. Es posible seleccionar muestras similares de sensibilidad basada en derivadas mediante Redes Neuronales y realizar la cuantificación de la incertidumbre.
Una de las ventajas de los métodos locales es que es posible hacer una matriz para representar todas las sensibilidades de un sistema, proporcionando así una visión de conjunto que no se puede conseguir con los métodos globales si hay un gran número de variables de entrada y salida.[25]
Análisis de regresión
El análisis de regresión, en el contexto del análisis de sensibilidad, implica ajustar una regresión lineal a la respuesta del modelo y utilizar coeficientes de regresión estandarizados como medidas directas de sensibilidad. La regresión debe ser lineal con respecto a los datos (es decir, un hiperplano, sin términos cuadráticos, etc., como regresores) porque, de lo contrario, es difícil interpretar los coeficientes normalizados. Por lo tanto, este método es más adecuado cuando la respuesta del modelo es lineal; la linealidad puede confirmarse, por ejemplo, si el coeficiente de determinación es grande. Las ventajas del análisis de regresión son su sencillez y su bajo coste computacional.
Métodos basados en la varianza
Artículo principal: Análisis de sensibilidad basado en la varianza
Los métodos basados en la varianza[26] son una clase de enfoques probabilísticos que cuantifican las incertidumbres de entrada y salida como distribuciones de probabilidad, y descomponen la varianza de salida en partes atribuibles a variables de entrada y combinaciones de variables. La sensibilidad de la salida a una variable de entrada se mide por la cantidad de varianza en la salida causada por esa entrada. Pueden expresarse como expectativas condicionales, es decir, considerando un modelo Y = f(X) para X = {X1, X2, ... Xk}, una medida de sensibilidad de la i-ésima variable Xi viene dada por,

donde "Var" y "E" denotan los operadores de varianza y valor esperado respectivamente, y X~i indica el conjunto de todas las variables de entrada excepto Xi. Esta expresión mide esencialmente la contribución de Xi por sí sola a la incertidumbre (varianza) en Y (promediada sobre las variaciones en otras variables), y se conoce como índice de sensibilidad de primer orden o índice de efecto principal. Es importante destacar que no mide la incertidumbre causada por las interacciones con otras variables. Otra medida, conocida como índice de efecto total, da la varianza total en Y causada por Xi y sus interacciones con cualquiera de las otras variables de entrada. Ambas cantidades suelen normalizarse dividiéndolas por Var(Y).
Los métodos basados en la varianza permiten una exploración completa del espacio de entrada, teniendo en cuenta las interacciones y las respuestas no lineales. Por estas razones se utilizan ampliamente cuando es factible calcularlos. Normalmente, este cálculo implica el uso de métodos de Monte Carlo, pero como esto puede implicar muchos miles de ejecuciones del modelo, pueden utilizarse otros métodos (como emuladores) para reducir el gasto computacional cuando sea necesario.
Análisis variográfico de superficies de respuesta (VARS)
Una de las principales deficiencias de los métodos de análisis de sensibilidad anteriores es que ninguno de ellos considera la estructura espacialmente ordenada de la superficie de respuesta/salida del modelo Y=f(X) en el espacio de parámetros. Mediante la utilización de los conceptos de variogramas direccionales y covariogramas, el análisis de variogramas de superficies de respuesta (VARS) aborda esta debilidad mediante el reconocimiento de una estructura de correlación espacialmente continua a los valores de Y, y por lo tanto también a los valores de

Básicamente, cuanto mayor es la variabilidad, más heterogénea es la superficie de respuesta a lo largo de una dirección/parámetro particular, a una escala de perturbación específica. En consecuencia, en el marco VARS, los valores de los variogramas direccionales para una escala de perturbación determinada pueden considerarse como una ilustración completa de la información de sensibilidad, mediante la vinculación del análisis de variogramas a los conceptos de dirección y escala de perturbación. Como resultado, el marco VARS tiene en cuenta el hecho de que la sensibilidad es un concepto dependiente de la escala, y por lo tanto supera el problema de la escala de los métodos tradicionales de análisis de sensibilidad.[29] Más importante aún, VARS es capaz de proporcionar estimaciones relativamente estables y estadísticamente robustas de la sensibilidad de los parámetros con un coste computacional mucho menor que otras estrategias (alrededor de dos órdenes de magnitud más eficientes). [30] Cabe destacar que se ha demostrado que existe un vínculo teórico entre el marco VARS y los enfoques basados en la varianza y en la derivada.
Métodos alternativos
Se han desarrollado varios métodos para superar algunas de las limitaciones comentadas anteriormente, que de otro modo harían inviable la estimación de las medidas de sensibilidad (la mayoría de las veces debido a los gastos de cálculo). En general, estos métodos se centran en el cálculo eficiente de medidas de sensibilidad basadas en la varianza.
Emuladores
Los emuladores (también conocidos como metamodelos, modelos sustitutos o superficies de respuesta) son enfoques de modelado de datos/aprendizaje automático que implican la construcción de una función matemática relativamente sencilla, conocida como emulador, que se aproxima al comportamiento de entrada/salida del propio modelo.[31] En otras palabras, es el concepto de "modelar un modelo" (de ahí el nombre de "metamodelo"). La idea es que, aunque los modelos informáticos pueden ser una serie muy compleja de ecuaciones cuya resolución puede llevar mucho tiempo, siempre pueden considerarse como una función de sus entradas Y = f(X). Ejecutando el modelo en una serie de puntos del espacio de entrada, puede ser posible ajustar un emulador mucho más simple η(X), tal que η(X) ≈ f(X) dentro de un margen de error aceptable.[32] Entonces, las medidas de sensibilidad pueden calcularse a partir del emulador (ya sea con Monte Carlo o analíticamente), lo que tendrá un coste computacional adicional insignificante. Es importante destacar que el número de ejecuciones del modelo necesarias para ajustar el emulador puede ser órdenes de magnitud menores que el número de ejecuciones necesarias para estimar directamente las medidas de sensibilidad a partir del modelo.[33]
Claramente, el quid de un enfoque emulador es encontrar un η (emulador) que sea una aproximación suficientemente cercana al modelo f. Esto requiere los siguientes pasos:
- Muestreo (ejecución) del modelo en una serie de puntos de su espacio de entrada. Esto requiere un diseño de la muestra
- Selección del tipo de emulador (función matemática) que se va a utilizar.
- "Entrenamiento" del emulador a partir de los datos de muestra del modelo: suele consistir en ajustar los parámetros del emulador hasta que éste imite lo mejor posible el modelo real.
El muestreo del modelo puede realizarse a menudo con secuencias de baja discrepancia, como la secuencia de Sobol -debida al matemático Ilya M. Sobol- o el muestreo de hipercubos latinos, aunque también pueden utilizarse diseños aleatorios, con pérdida de cierta eficacia. La selección del tipo de emulador y el entrenamiento están intrínsecamente ligados, ya que el método de entrenamiento dependerá de la clase de emulador. Algunos tipos de emuladores que se han utilizado con éxito para el análisis de sensibilidad son:
- Procesos gaussianos[33] (también conocidos como kriging), en los que se supone que cualquier combinación de puntos de salida se distribuye como una distribución gaussiana multivariante. Recientemente, se han utilizado procesos gaussianos "arbolados" para tratar respuestas heteroscedásticas y discontinuas.[34][35]
- Bosques aleatorios,[31] en los que se entrena un gran número de árboles de decisión y se promedia el resultado.
- Aumento del gradiente,[31] donde se utiliza una sucesión de regresiones simples para ponderar los puntos de datos y reducir secuencialmente el error.
- Expansiones de caos polinómico,[36] que utilizan polinomios ortogonales para aproximar la superficie de respuesta.
- Smoothing splines,[37] utilizados normalmente junto con truncamientos HDMR (véase más abajo).
- Redes bayesianas discretas,[38] junto con modelos canónicos como los modelos ruidosos. Los modelos ruidosos explotan la información sobre la independencia condicional entre variables para reducir significativamente la dimensionalidad.
El uso de un emulador introduce un problema de aprendizaje automático, que puede resultar difícil si la respuesta del modelo es muy poco lineal. En todos los casos, es útil comprobar la precisión del emulador, por ejemplo mediante validación cruzada.
Representaciones de modelos de alta dimensión (HDMR)
Una representación de modelo de alta dimensionalidad (HDMR)[39][40] (el término se debe a H. Rabitz[41]) es esencialmente un enfoque emulador, que consiste en descomponer la salida de la función en una combinación lineal de términos de entrada e interacciones de dimensionalidad creciente. El enfoque HDMR aprovecha el hecho de que el modelo suele poder aproximarse bien despreciando las interacciones de orden superior (de segundo o tercer orden y superiores). Los términos de las series truncadas pueden entonces aproximarse mediante, por ejemplo, polinomios o splines (REFS) y la respuesta puede expresarse como la suma de los efectos principales y las interacciones hasta el orden de truncamiento. Desde esta perspectiva, los HDMR pueden verse como emuladores que desprecian las interacciones de alto orden; la ventaja es que son capaces de emular modelos con mayor dimensionalidad que los emuladores de orden completo.
Prueba de sensibilidad a la amplitud de Fourier (FAST)
La prueba de sensibilidad de amplitud de Fourier (FAST) utiliza la serie de Fourier para representar una función multivariante (el modelo) en el dominio de la frecuencia, utilizando una única variable de frecuencia. Por lo tanto, las integrales necesarias para calcular los índices de sensibilidad pasan a ser univariantes, lo que supone un ahorro computacional.
Otros
Métodos basados en el filtrado Monte Carlo.[42] Estos también se basan en el muestreo y el objetivo aquí es identificar regiones en el espacio de los factores de entrada correspondientes a valores particulares (por ejemplo, alto o bajo) de la salida.
Aplicaciones
Se pueden encontrar ejemplos de análisis de sensibilidad en diversos ámbitos de aplicación, como:
- Ciencias medioambientales
- Negocios
- Ciencias sociales
- Química
- Ingeniería
- Epidemiología
- Metaanálisis
- Toma de decisiones con criterios múltiples
- Toma de decisiones con plazos críticos
- Calibración del modelo
- Cuantificación de la incertidumbre
- Teoría del caos
- En genética de poblaciones - Si una población se volverá caótica cuando reciba un periodo de estocasticidad.[43]
Auditoría de la sensibilidad
Puede ocurrir que un análisis de sensibilidad de un estudio basado en modelos tenga por objeto apuntalar una inferencia y certificar su solidez, en un contexto en el que la inferencia alimenta una política o un proceso de toma de decisiones. En estos casos, el encuadre del propio análisis, su contexto institucional y las motivaciones de su autor pueden adquirir una gran importancia, y un análisis de sensibilidad puro -con su énfasis en la incertidumbre paramétrica- puede considerarse insuficiente. El énfasis en el encuadre puede derivarse, entre otras cosas, de la relevancia del estudio político para diferentes grupos de interés que se caracterizan por normas y valores diferentes y, por tanto, por una historia diferente sobre "cuál es el problema" y, sobre todo, sobre "quién cuenta la historia". En la mayoría de los casos, el marco incluye supuestos más o menos implícitos, que pueden ser políticos (por ejemplo, qué grupo hay que proteger) o técnicos (por ejemplo, qué variable puede tratarse como una constante).
Para tener debidamente en cuenta estas preocupaciones, los instrumentos de la AS se han ampliado para proporcionar una evaluación de todo el proceso de generación de conocimientos y modelos. Este enfoque se ha denominado "auditoría de sensibilidad". Se inspira en el NUSAP,[44] un método utilizado para calificar el valor de la información cuantitativa con la generación de `Pedigrees' de números. La auditoría de sensibilidad se ha diseñado especialmente para un contexto contencioso, en el que no sólo la naturaleza de las pruebas, sino también el grado de certeza e incertidumbre asociado a las mismas, será objeto de intereses partidistas.[45] La auditoría de sensibilidad se recomienda en las directrices de la Comisión Europea para la evaluación de impacto,[6] así como en el informe Consejo Asesor Científico de las Academias Europea.[46]
Conceptos relacionados
El análisis de sensibilidad está estrechamente relacionado con el análisis de incertidumbre; mientras que este último estudia la incertidumbre global en las conclusiones del estudio, el análisis de sensibilidad trata de identificar qué fuente de incertidumbre pesa más en las conclusiones del estudio.
El planteamiento del problema en el análisis de sensibilidad también presenta grandes similitudes con el campo del diseño de experimentos[47]. En un diseño de experimentos, se estudia el efecto de algún proceso o intervención (el "tratamiento") sobre algunos objetos (las "unidades experimentales"). En el análisis de sensibilidad se estudia el efecto de variar las entradas de un modelo matemático sobre la salida del propio modelo. En ambas disciplinas se intenta obtener información del sistema con un mínimo de experimentos físicos o numéricos.
Lectura adicional
- Cannavó, F. (2012). "Sensitivity analysis for volcanic source modeling quality assessment and model selection". Computers & Geosciences. 44: 52–59.
- Fassò A. (2007) "Statistical sensitivity analysis and water quality". In Wymer L. Ed, Statistical Framework for Water Quality Criteria and Monitoring. Wiley, New York.
- Fassò A., Perri P.F. (2002) "Sensitivity Analysis". In Abdel H. El-Shaarawi and Walter W. Piegorsch (eds) Encyclopedia of Environmetrics, Volume 4, pp 1968–1982, Wiley.
- Fassò A., Esposito E., Porcu E., Reverberi A.P., Vegliò F. (2003) "Statistical Sensitivity Analysis of Packed Column Reactors for Contaminated Wastewater". Environmetrics. Vol. 14, n.8, 743–759.
- Haug, Edward J.; Choi, Kyung K.; Komkov, Vadim (1986) Design sensitivity analysis of structural systems. Mathematics in Science and Engineering, 177. Academic Press, Inc., Orlando, FL.
- Pianosi, F.; Beven, K.; Freer, J.; Hall, J.W.; Rougier, J.; Stephenson, D.B.; Wagener, T. (2016). "Sensitivity analysis of environmental models: A systematic review with practical workflow". Environmental Modelling & Software. 79: 214–232.
- Pilkey, O. H. and L. Pilkey-Jarvis (2007), Useless Arithmetic. Why Environmental Scientists Can't Predict the Future. New York: Columbia University Press
- Santner, T. J.; Williams, B. J.; Notz, W.I. (2003) Design and Analysis of Computer Experiments; Springer-Verlag
- Taleb, N. N., (2007) The Black Swan: The Impact of the Highly Improbable, Random House
Referencias
- Pannell, D. J. (1997). «Sensitivity Analysis of Normative Economic Models: Theoretical Framework and Practical Strategies». Agricultural Economics: 139-152. doi:10.1016/S0169-5150(96)01217-0.
- Bahremand, A.; De Smedt, F. (2008). «Distributed Hydrological Modeling and Sensitivity Analysis in Torysa Watershed, Slovakia». Water Resources Management.: 293-408. doi:10.1007/s11269-007-9168-x.
- Hill, Mary C.; Kavetski, Dmitri; Clark, Martyn; Ye, Ming; Arabi, Mazdak; Lu, Dan; Foglia, Laura; Mehl, Steffen (2016-03). «Practical Use of Computationally Frugal Model Analysis Methods». Groundwater (en inglés) 54 (2): 159-170. ISSN 0017-467X. doi:10.1111/gwat.12330. Consultado el 13 de septiembre de 2023.
- Hill, M.; Tiedeman, C. (2007). «Effective Groundwater Model Calibration, with Analysis of Data, Sensitivities, Predictions, and Uncertainty». ohn Wiley & Sons.
- Der Kiureghian, A.; Ditlevsen, O. (2009). «Aleatory or epistemic? Does it matter?». Structural Safety: 105-112. doi:10.1016/j.strusafe.2008.06.020.
- «Better regulation: guidelines and toolbox». commission.europa.eu (en inglés). Consultado el 13 de septiembre de 2023.
- Archived copy. 2009.
- Helton, J. C.; Johnson, J. D.; Salaberry, C. J.; Storlie, C. B. (2006). «Survey of sampling based methods for uncertainty and sensitivity analysis». Reliability Engineering and System Safety: 1175-1209. doi:10.1016/j.ress.2005.11.017.
- Tavakoli, S.; Mousavi, A.; Broomhead, P. (2013). Event tracking for real-time unaware sensitivity analysis (EventTracker) (en inglés). ISSN 1041-4347. doi:10.1109/TKDE.2011.240. Consultado el 13 de septiembre de 2023.
- Tavakoli, S.; Mousavi, A.; Poslad, S. (2013). Input variable selection in time-critical knowledge integration applications: A review, analysis, and recommendation paper (en inglés). ISSN 1474-0346. doi:10.1016/j.aei.2013.06.002. Consultado el 13 de septiembre de 2023.
- Leamer, Edward E. (1983). «Let's Take the Con Out of Econometrics». American Economic Review: 31-43.
- Leamer, Edward E. (1985). «Sensitivity Analyses Would Help». American Economic Review: 308-313.
- Ravetz, J.R. (2007). «No-Nonsense Guide to Science». New Internationalist Publications Ltd.
- Tsvetkova, O.; Ouarda, T.B.M.J. (2019). «Quasi-Monte Carlo technique in global sensitivity analysis of wind resource assessment with a study on UAE». Journal of Renewable and Sustainable Energy. doi:10.1063/1.5120035.
- O'Hagan, Anthony; Buck, Caitlin E.; Daneshkhah, Alireza; Eiser, J. Richard; Garthwaite, Paul H.; Jenkinson, David J.; Oakley, Jeremy E.; Rakow, Tim (30 de agosto de 2006). Uncertain Judgements: Eliciting Experts' Probabilities (en inglés). John Wiley & Sons. ISBN 978-0-470-03330-2. Consultado el 13 de septiembre de 2023.
- Sacks, Jerome; Welch, William J.; Mitchell, Toby J.; Wynn, Henry P. (1989-11). «Design and Analysis of Computer Experiments». Statistical Science 4 (4): 409-423. ISSN 0883-4237. doi:10.1214/ss/1177012413. Consultado el 13 de septiembre de 2023.
- Campbell, J. E.; Carmichael, G. R.; Chai, T.; Mena-Carrasco, M.; Tang, Y.; Blake, D. R.; Blake, N. J.; Vay, S. A. et al. (1 de noviembre de 2008). «Photosynthetic control of atmospheric carbonyl sulfide during the growing season.». Science (New York, N.Y.) (en inglés) 322 (5904): 1085-1088. ISSN 0036-8075. doi:10.1126/science.1164015. Consultado el 14 de septiembre de 2023.
- Bailis, R.; Ezzati, M.; Kammen, D. (2005). «Mortality and Greenhouse Gas Impacts of Biomass and Petroleum Energy Futures in Africa». Science: 98-103. PMID 15802601. doi:10.1126/science.1106881.
- Murphy, J.; et al. (2004). «Quantification of modelling uncertainties in a large ensemble of climate change simulations». Nature: 768-772. PMID 15306806. doi:10.1038/nature02771.
- Czitrom, Veronica (1999). «One-Factor-at-a-Time Versus Designed Experiments». American Statistician: 126-131. doi:10.2307/2685731.
- Gatzouras, D.; Giannopoulos, A. (1 de enero de 2009). «Threshold for the volume spanned by random points with independent coordinates». Israel Journal of Mathematics (en inglés) 169 (1): 125-153. ISSN 1565-8511. doi:10.1007/s11856-009-0007-z. Consultado el 14 de septiembre de 2023.
- Cacuci, Dan G. «Sensitivity and Uncertainty Analysis: Theory». Chapman & Hall.
- Griewank, A. (2000). «Evaluating Derivatives, Principles and Techniques of Algorithmic Differentiation». SIAM.
- Dipu Kabir, H M; Khosravi, Abbas; Nahavandi, Darius; Nahavandi, Saeid (2020-07). «Uncertainty Quantification Neural Network from Similarity and Sensitivity». 2020 International Joint Conference on Neural Networks (IJCNN): 1-8. doi:10.1109/IJCNN48605.2020.9206746. Consultado el 14 de septiembre de 2023.
- Sobol', I (1990). «Sensitivity estimates for nonlinear mathematical models". Matematicheskoe Modelirovanie». Mathematical Modeling & Computational Experiment: 407-414.
- Razavi, Saman; Gupta, Hoshin V. (2016-01). «A new framework for comprehensive, robust, and efficient global sensitivity analysis: 1. Theory». Water Resources Research (en inglés) 52 (1): 423-439. ISSN 0043-1397. doi:10.1002/2015WR017558. Consultado el 15 de septiembre de 2023.
- Razavi, Saman; Gupta, Hoshin V. (2016-01). «A new framework for comprehensive, robust, and efficient global sensitivity analysis: 2. Application». Water Resources Research (en inglés) 52 (1): 440-455. ISSN 0043-1397. doi:10.1002/2015WR017559. Consultado el 15 de septiembre de 2023.
- Haghnegahdar, Amin; Razavi, Saman (2017). «Insights into sensitivity analysis of Earth and environmental systems models: On the impact of parameter perturbation scale». Environmental Modelling & Software.: 115-131. doi:10.1016/j.envsoft.2017.03.031.
- «Sensitivity Analysis in Earth Observation Modelling - 1st Edition». shop.elsevier.com. Consultado el 15 de septiembre de 2023.
- Storlie, C.B.; Swiler, L.P.; Helton, J.C.; Sallaberry, C.J. (2009). «Implementación y evaluación de procedimientos de regresión no paramétrica para el análisis de sensibilidad de modelos computacionalmente exigentes». Reliability Engineering & System Safety: 1735-1763. doi:10.1016/j.ress.2009.05.007.
- Wang, Shangying; Fan, Kai; Luo, Nan; Cao, Yangxiaolu; Wu, Feilun; Zhang, Carolyn; Heller, Katherine A.; You, Lingchong (25 de septiembre de 2019). «Massive computational acceleration by using neural networks to emulate mechanism-based biological models». Nature Communications 10: 4354. ISSN 2041-1723. PMC 6761138. PMID 31554788. doi:10.1038/s41467-019-12342-y. Consultado el 15 de septiembre de 2023.
- Oakley, J.; O'Hagan, A. (2004). «Probabilistic sensitivity analysis of complex models: a Bayesian approach». J. R. Stat. Soc. B.: 751-769. doi:10.1111/j.1467-9868.2004.05304.x.
- Gramacy, R. B.; Taddy, M. A. (2010). «Categorical Inputs, Sensitivity Analysis, Optimization and Importance Tempering with tgp Version 2, an R Package for Treed Gaussian Process Models». Journal of Statistical Software. doi:10.18637/jss.v033.i06.
- Becker, W.; Worden, K.; Rowson, J. (1 de enero de 2013). Bayesian sensitivity analysis of bifurcating nonlinear models. doi:10.1016/j.ymssp.2012.05.010. Consultado el 15 de septiembre de 2023.
- Sudret, B. (2008). «Global sensitivity analysis using polynomial chaos expansions». Reliability Engineering & System Safety. doi:10.1016/j.ress.2007.04.002.
- Ratto, M.; Pagano, A. (2010). «Using recursive algorithms for the efficient identification of smoothing spline ANOVA models». AStA Advances in Statistical Analysis: 367-388. doi:10.1007/s10182-010-0148-8.
- Cardenas, IC (2019). «On the use of Bayesian networks as a meta-modeling approach to analyse uncertainties in slope stability analysis». Assessment and Management of Risk for Engineered Systems and Geohazards: 53-65. doi:10.1080/17499518.2018.1498524.
- Li, G.; Hu, J.; Wang, S.-W.; Georgopoulos, P.; Schoendorf, J.; Rabitz, H. (2006). «Random Sampling-High Dimensional Model Representation (RS-HDMR) and orthogonality of its different order component functions"». Journal of Physical Chemistry A. PMID 16480307. doi:10.1021/jp054148m.
- Li, G. (2002). «Practical approaches to construct RS-HDMR component functions». Journal of Physical Chemistry: 8721-8733. doi:10.1021/jp014567t.
- Rabitz, H (1989). «System analysis at molecular scale». Science: 221-226. PMID 17839016. doi:10.1126/science.246.4927.221.
- Hornberger, G.; Spear, R. (1981). «An approach to the preliminary analysis of environmental systems». Journal of Environmental Management: 7-18.
- Perry, Joe; Smith, Robert; Woiwod, Ian; Morse, David (2000). Perry, Joe N; Smith, Robert H; Woiwod, Ian P; Morse, David R (2000). «Chaos in Real Data : The Analysis of Non-Linear Dynamics from Short Ecological Time Series.». Springer Science+Business Media Dordrecht. pp. ISBN 978-94-010-5772-1. doi:10.1007/978-94-011-4010-2.
- Van der Sluijs, JP; Craye, M; Funtowicz, S; Kloprogge, P; Ravetz, J; Risbey, J (2005). «Combining quantitative and qualitative measures of uncertainty in model based environmental assessment: the NUSAP system». Risk Analysis: 481-492. PMID 15876219. doi:10.1111/j.1539-6924.2005.00604.x.
- Lo Piano, S; Robinson, M (2019). «Nutrition and public health economic evaluations under the lenses of post normal science». Futures. doi:10.1016/j.futures.2019.06.008.
- Consejo Asesor Científico de las Academias Europea. Dar sentido a la ciencia para la política en condiciones de complejidad e incertidumbre, Berlín, 2019
- Box GEP, Hunter WG, Hunter, J. Stuart. «Statistics for experimenters [Internet]». New York: Wiley & Sons.
Enlaces externos
- https://www.sensitivityanalysis.org/conferences/ Sitio web con material de la serie de conferencias SAMO (1995-2025)
- https://ec.europa.eu/jrc/en/samo Centro Común de Investigación de la Comisión Europea
- https://ec.europa.eu/jrc/en/samo/simlab el programa gratuito de análisis de sensibilidad global del Centro Común de Investigación
- http://mucm.ac.uk/index.html Amplios recursos para el análisis de la incertidumbre y la sensibilidad de modelos muy exigentes desde el punto de vista informático.