Théorie des réseaux
La théorie des réseaux est l'étude de graphes en tant que représentation d'une relation symétrique ou asymétrique entre des objets discrets. Elle s'inscrit dans la théorie des graphes : un réseau peut alors être défini comme étant un graphe où les nœuds (sommets) ou les arêtes (ou « arcs », lorsque le graphe est orienté) ont des attributs, comme une étiquette (tag).
La théorie des réseaux trouve des applications dans diverses disciplines incluant la physique statistique, la physique des particules, l'informatique, le génie électrique, la biologie, l'économie, la finance, la recherche opérationnelle, la climatologie ou les sciences sociales.
Il existe de nombreux types de réseaux : réseau logistique, World Wide Web, Internet, réseau de régulation génétique, réseau métabolique, réseau social, réseau sémantique, réseau de neurones, etc.
Historicité

L'étude des réseaux a émergé dans diverses disciplines afin de permettre l'analyse des données relationnelles complexes. Le plus ancien document connu dans le domaine de l'étude des graphes est celui concernant le problème des sept ponts de Königsberg écrit par Leonhard Euler en 1736. La description mathématique par Euler des sommets et des arêtes fut le fondement de la théorie des graphes, une branche des mathématiques qui étudie les propriétés des relations dyadiques d'une structure en réseau. Le champ de la théorie des graphes a continué à se développer et a trouvé des applications en chimie (Sylvester, 1878).
Dénes Kőnig, un mathématicien et professeur hongrois a écrit en 1936 le premier livre sur la théorie des graphes, intitulé (en version anglophone) : Theory of finite and infinite graph[1].
Dans les années 1930, Jacob Moreno, un psychologue de l'École de Gestalt immigre aux États-Unis. Il y développe le sociogramme qu'il présente au public en avril 1933 lors d'une convention de médecins. Le sociogramme était alors la représentation de la structure sociale d'un groupe d'écoliers d'une école primaire[2]. Les garçons étaient amis avec d'autres garçons, et les filles étaient amies avec d'autres filles, avec l'exception d'un garçon qui a répondu aimer une fille. Mais ce sentiment n'était pas réciproque, ce qui s'observe sur le sociogramme. La représentation d'un réseau de relations sociales fut jugée si intrigante qu'il fut imprimé dans le New York Times (, page 17). Depuis, la sociométrie a trouvé de nombreuses applications et s'est développée au sein du champ de l'analyse des réseaux sociaux.
Les théories probabilistes en analyse de réseaux sont les rejetons de la théorie des graphes, notamment grâce aux 8 articles de Paul Erdős et Alfréd Rényi sur les graphes aléatoires. Pour l'analyse des réseaux sociaux, le modèle probabiliste proposé est le graphe aléatoire exponentiel (ERGMs), où p* est un cadre de notation utilisé pour représenter l'espace des probabilités d'occurrence d'un lien dans le réseau. Un autre exemple de l'utilisation d'outils probabilistes en structure de réseaux est la matrice de probabilité de réseau, qui modélise la probabilité que des liens apparaissent dans un réseau, en fonction de la présence ou de l'absence historique du lien dans un échantillon de réseaux.
Dans les années 1980 de nombreux sociologues travaillent sur l'analyse des réseaux. Émerge notamment en 1992 le livre Identity and control, de Harrison White, qui introduit de nombreux concepts phares (encastrement, découplage, commutation, netdom, pour n'en nommer que quelques-uns). Puis en 1994 parait le fameux Social Network Analysis : Methods and Applications, de Wasserman et Faust, un ouvrage de référence concernant les mesures et méthodes en analyse des réseaux sociaux.
Plus récemment, d'autres travaux en théorie des réseaux se concentrent sur la description mathématique des différentes topologies que présentent les réseaux. Duncan Watts a unifié d'anciennes données empiriques sur les réseaux sociaux en en faisant une représentation mathématique décrivant le petit monde.
Albert-László Barabási et Réka Albert ont développé le réseau invariant d'échelle, défini comme étant une topologie de réseau contenant des sommets concentrateurs avec de nombreuses connexions, ce qui permet de maintenir un rapport constant entre le nombre de connexions de tous les autres nœuds. Bien que de nombreux réseaux, tels qu'Internet, semblent conserver cet aspect, d'autres réseaux ont depuis longtemps des distributions de nœuds ne faisant qu'approximer les ratios sans échelle.
De nos jours, les études sur les réseaux intéressent de nombreux secteurs autant privés que publics, dont le département de la Défense américaine[3].
Types d'analyses de réseaux
Analyse des réseaux sociaux
L'analyse des réseaux sociaux examine la structure des relations entre entités sociales[5]. Ces entités sont souvent des personnes, mais peuvent aussi être des groupes, des organisations, des États-nations, des sites web ou des publications scientifiques. L'étude des réseaux a joué un rôle central en sciences sociales et la plupart des outils mathématiques et statistiques utilisés pour étudier les réseaux ont d'abord été développés en sociologie, par des sociologues[6].
Parmi de nombreuses autres applications, l’analyse des réseaux sociaux a été utilisée pour comprendre la diffusion d’innovations[7], des nouvelles et des rumeurs. De même, elle a été utilisée pour examiner la propagation des maladies et les comportements liés à la santé. Elle a également été appliquée à l’étude des marchés afin d'examiner le rôle de la confiance dans les échanges et dans le processus de fixation des prix[8],[9].
De même, elle a été utilisée pour étudier le recrutement dans les mouvements sociaux et les institutions sociales. Elle a également été utilisée pour conceptualiser les désaccords scientifiques ainsi que le prestige social dans le milieu académique. Plus récemment, l’analyse de réseaux sociaux a été largement utilisée dans le renseignement militaire pour découvrir des réseaux d’insurgés, à la fois hiérarchiques et sans dirigeants.
Analyse dynamique des réseaux sociaux
L’analyse dynamique des réseaux examine l’évolution de la structure des relations entre différentes classes d’entités ayant des effets sur les systèmes sociotechniques complexes et reflète la stabilité sociale ainsi que des changements tels que l’émergence de nouveaux groupes, sujets et dirigeants[10],[11],[12],[13]. L'analyse dynamique des réseaux se concentre sur les méta-réseaux composés de plusieurs types de nœuds (entités) et de plusieurs types de liens (multiplexité). Ces entités peuvent être très variées[14]. Les exemples incluent des personnes, des organisations, des sujets, des ressources, des tâches, des événements, des emplacements et des croyances.
Les techniques d'analyse dynamique de réseaux sont particulièrement utiles pour évaluer les tendances et les changements dans les réseaux au fil du temps, identifier les leaders émergents et examiner la coévolution des personnes et des idées.
Analyse des réseaux biologiques
Avec le développement des bases de données biologiques accessibles au public, l'analyse des réseaux moléculaires[15] a suscité un intérêt considérable[16]. L'analyse des réseaux biologiques est étroitement liée à l'analyse des réseaux sociaux, et se concentre souvent sur les propriétés locales du réseau. Par exemple, les motifs de réseau sont de petits sous-graphes surreprésentés dans le réseau. De manière similaire, les motifs d'activité sont des motifs dans les attributs des nœuds et des arêtes du réseau qui sont surreprésentés compte tenu de la structure du réseau. L'analyse des réseaux biologiques, en ce qui concerne les maladies, a conduit au développement d'une approche réseau des maladies et traitements (network medecine)[17]. Les exemples récents de l'application de la théorie des réseaux en biologie incluent les applications pour comprendre le cycle cellulaire[18]. Les interactions entre les systèmes physiologiques tels que le cerveau, le cœur, les yeux, etc. peuvent être explorées en tant que réseau physiologique[19].
Analyse de réseaux infectieux
Les modèles compartimentaux en épidémiologie sont ces algorithmes connus pour prédire la propagation de pandémies mondiales au sein d'une population infectieuse, et particulièrement le SIR model.
Au-delà des pandémies, ce modèle peut permettre d'appréhender de nombreux phénomènes sociaux de diffusion/transmission (information, propagande, mode, etc).
Analyse des réseaux textuels
Le traitement automatique de corpus a rendu possible l'extraction des acteurs et de leurs réseaux relationnels sur une vaste échelle. Les données relationnelles sont ensuite analysées à l'aide d'outils de la théorie des réseaux afin d'identifier les acteurs clés, les communautés ou les composantes clés, ainsi que des propriétés générales telles que la robustesse, la stabilité structurelle de l'ensemble du réseau, ou de la centralité de certains nœuds dans le réseau[21].
Ceci automatise l'approche introduite par l'analyse de données textuelles quantitative[22] dans lequel les triades (ou triplets) sujet-verbe-objet sont identifiés avec des paires (dyades) d'acteurs liés par une action ou des paires constituées d'acteur-objet[20]. Elle peut être sémantique.
Analyse des réseaux électriques
L’analyse des systèmes électriques peut être réalisée en utilisant la théorie des réseaux[23],[24], selon deux points de vue principaux :
- Une perspective abstraite (graphe), quels que soient les aspects liés à l’énergie électrique (par exemple, les impédances des lignes de transmission). La plupart de ces études se concentrent uniquement sur la structure abstraite du réseau électrique à l’aide de la distribution des degrés de sommets et la distribution d'intermédiarité, ce qui permet de mieux aborder l’évaluation de la vulnérabilité du réseau. Grâce à ces types d’études, le type de structure du réseau électrique pourrait être identifié dans la perspective des systèmes complexes. Cette classification peut aider les ingénieurs des réseaux électriques au stade de la planification ou lors de la mise à niveau de l’infrastructure énergétique (par exemple, l’ajout d’une nouvelle ligne de transmission) pour maintenir un niveau de redondance approprié dans le système de transmission[25].
- En prenant des graphes valués et combinant une compréhension abstraite des théories sur les réseaux complexes aux propriétés des réseaux électriques[26].
Analyse des liens
L'analyse des liens (Link analysis) est une branche de l'analyse de réseaux sociaux, qui explore les associations entre objets d'analyse. Par exemple, il est possible d'examiner les interactions d'un suspect et de ses victimes (numéros de téléphones qui ont été composés, adresses, opérations financières effectuées, dans un temps donné), ainsi que leurs relations familiales, lors d'enquêtes policières et en forensique.
L'analyse des liens procure des informations cruciales concernant les relations et associations entre plusieurs objets de différents types, qui ne sont pas apparentes en tant qu'élément isolé d'information.
Les analyses de liens entièrement ou partiellement automatisés sont de plus en plus utilisées par les banques et compagnies d'assurances, notamment pour détecter des fraudes ; par les opérateurs de télécommunication dans les analyses de réseaux de télécommunication ; dans le secteur médical en épidémiologie et pharmacologie ; dans le maintien de l'ordre, par les moteurs de recherche afin de noter la pertinence (et du coup, par les spammeurs pour le référencement abusif et par les entrepreneurs pour optimiser la visite de leur site web), et partout ailleurs où les relations entre divers objets ont été analysées.
Les liens sont également dérivés de la similarité du comportement temporel de deux nœuds. Les exemples incluent notamment les réseaux climatiques en climatologie où les liens entre deux sites (nœuds) sont déterminés, par exemple, par la similarité des précipitations ou des fluctuations de température sur les deux sites[27],[28],[29].
Analyse des liens web
Plusieurs algorithmes de classement utilisés par les moteurs de recherche Web utilisent des métriques de centralité basées sur les liens, notamment les algorithmes PageRank de Google, l'algorithme HITS, CheiRank et TrustRank. Des analyses de liens sont également menées en sciences de l'information et en sciences de la communication afin de comprendre et d'extraire des informations de réseaux de pages Web. Par exemple, l’analyse pourrait porter sur les liens entre les sites Web ou les blogs de personnalités politiques. Une autre utilisation est de classer les pages en fonction de leur mention dans les autres pages (cooccurrence)[30].
Analyse des réseaux de récurrence
En statistique descriptive et théorie du chaos, un graphe de récurrence (RP) est un graphe montrant, pour un instant donné, les moments auxquels une trajectoire d’espace de phase visite approximativement la même zone de l’espace de phase. La matrice d'un graphe de récurrence peut être considérée comme la matrice d'adjacence d'un réseau non orienté et non pondéré. Cela permet d'analyser les séries chronologiques à l'aide de mesures de réseau. Les applications vont de la détection des changements de régime à la caractérisation des dynamiques, en passant par l'analyse de synchronisation[31],[32],[33].
Analyse des réseaux interdépendants
Un réseau interdépendant est un système de réseaux couplé où les nœuds d'un ou de plusieurs réseaux dépendent des nœuds d'autres réseaux. Dans les réseaux réels, ces dépendances sont renforcées par le développement de la technologie moderne. Les dépendances peuvent entraîner des défaillances en cascade entre les réseaux : une défaillance relativement faible peut entraîner une défaillance catastrophique d'un système plus vaste. Les pannes de courant sont une démonstration du rôle important joué par les dépendances entre réseaux. Une étude récente a développé un cadre d'analyse pour étudier les défaillances en cascade dans un système de réseaux interdépendants[34],[35].
Modèles en théorie des réseaux
Les modèles en théorie des réseaux servent de fondement à la compréhension des interactions au sein de réseaux complexes empiriques. Divers modèles de génération de graphes aléatoires produisent des structures en réseaux qui peuvent être utilisées afin de les comparer aux réseaux complexes du monde réel.
Modèle Erdős–Rényi

Le modèle Erdős–Rényi, nommé ainsi en hommage à Paul Erdős et Alfréd Rényi, est utilisé pour générer un graphe aléatoire dans lequel les arêtes sont définies entre les nœuds avec des probabilités égales. Il peut être employé dans une approche probabiliste afin de démontrer l'existence de graphes satisfaisant à une variété de propriétés, ou encore à procurer une définition rigoureuse de ce qu'implique une propriété pour presque tous les graphes.
Pour générer un modèle Erdős–Rényi deux paramètres doivent être spécifiés : le nombre total de sommets n et la probabilité p qu'une paire aléatoire de sommets soit reliée par une arête.

Le modèle étant généré sans biais pour des nœuds particuliers, la distribution des degrés est binomiale : pour un sommet sélectionné de façon aléatoire,


Dans ce modèle, le coefficient de regroupement est de 0 a.s. Le comportement de peut être divisé en trois régions :
- Souscritique : Toutes les composantes sont simples et vraiment petites, la composante la plus large a une taille ;
- Critique : ;
- Supercritique : où est la solution positive à l'équation .








Une plus grande composante connexe a une grande complexité. Toutes les autres composantes sont simples et petites .

Modèle de configuration
Le modèle de configuration (configuration model, en anglais) prend une " séquence de degrés "[36],[37] ou une distribution de degrés[38] (qui est ensuite utilisée pour générer une séquence de degrés) comme entrée, et produit des graphes connexes de manière aléatoire sous tous les aspects autres que la séquence en degrés.
Ce qui signifie que pour une séquence de degrés donnée, le graphe est sélectionné de manière aléatoire parmi l'ensemble possible des graphes conformes à cette séquence de degrés. Le degré d'un sommet choisi aléatoirement est une variable indépendante et identiquement distribuée à valeur entière. Lorsque , la configuration du graphe contient une composante connexe dite " géante ", ayant une taille infinie[37]. Le reste de ses composantes ont une taille finie, pouvant être quantifiée en usant de la notion de taille de la distribution. La probabilité qu'un sommet échantillonné aléatoirement soit connecté à une composante de taille est donnée par le " pouvoir de convolution " (c'est l'itération de la convolution avec elle-même) de la distribution de degrés[39] :





où indique la distribution de degrés et . La composante géante peut être détruite en supprimant aléatoirement la fraction critique de toutes les arêtes. Ce processus est nommé percolation sur réseaux aléatoires.



Lorsque le second moment de la distribution de degrés est fini, , cette arête critique est donnée par[40] , et la distance moyenne sommet à sommet dans une composante connexe géante s'échelonne de façon logarithimique avec la taille totale du réseau, [38].




Dans une configuration de modèle de graphe orienté, le degré d'un sommet est donné par deux nombres, in-degré et out-degré , et conséquemment, la distribution de degrés est bi-variée. Le nombre attendu des in-arêtes et des out-arêtes coïncide, donc . Le modèle de configuration comportant un graphe orienté contient une composante géante, si et seulement si[41]




À noter que et sont égaux et ainsi donc interchangeables dans la dernière inégalité. La probabilité qu'un sommet choisi de façon aléatoire appartienne à une composante de taille est donnée par[42]:



pour une in-composante, et

pour une out-composante.
Modèle du petit monde de Watts–Strogatz


Le modèle du petit monde proposé par Watts et Strogatz est un modèle de génération de graphes aléatoires qui produit des graphes ayant les propriétés du petit monde.
Un réseau initial est utilisé pour générer un réseau « petit monde ». Chaque sommet d'un réseau est initialement lié à ces voisins les plus proches. Un autre paramètre est spécifié comme probabilité de reconnexion; chaque arête a une probabilité de se retrouver reconnectée au graphe en tant qu'arête aléatoire. Le nombre attendu de reconnexions de liens dans ce modèle est .



Lorsque le modèle de Watts et Strogatz commence par une structure de réseau non aléatoire, il présente un coefficient de regroupement très élevé ainsi qu'une longueur de chemin moyenne élevée. Chaque reconnexion est susceptible de créer un raccourci entre des composantes fortement connectées. À mesure que la probabilité de reconnexion augmente, le coefficient de regroupement décroît plus lentement que la longueur de chemin moyenne. Des valeurs plus élevées de p forcent plus d'arêtes à se reconnecter, ce qui fait du modèle de Watts et Strogatz un réseau aléatoire.
Modèle d'attachement préférentiel de Barabási–Albert (BA)
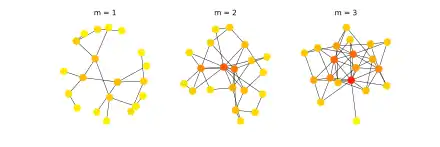
Le modèle de Barabási–Albert est un modèle de réseau aléatoire et sans échelle utilisé pour démontrer l'attachement préférentiel, ou, en d'autres termes, l'effet que « le riche devient plus riche ». Dans ce modèle, une arête a plus de probabilité de se lier à des sommets qui ont un plus haut degré qu'eux, ou encore dit autrement « pourquoi mes amis sont souvent plus populaires que moi ». La modélisation commence par un réseau initial de m0 sommets. m0 ≥ 2 et où le degré de chaque sommet dans le réseau initial devrait être d'au moins 1, sinon il restera toujours déconnecté du reste du réseau (exclu).
Dans le modèle BA, les nouveaux sommets sont ajoutés au réseau un à un. Chaque nouveau sommet est connecté à sommets existants avec une probabilité qui est proportionnelle au nombre de liens que ce sommet a déjà au sein du réseau. Formellement, la probabilité pi que le nouveau sommet soit connecté au sommet i est[43]


où ki est le degré du sommet i. Les sommets fortement liés ("hubs") tendent à rapidement accumuler encore plus de liens, tandis que les sommets ayant peu de liens ont peu de probabilités d'être sélectionnés pour former un nouveau lien. Les nouveaux sommets ont une « préférence » pour se lier eux-mêmes à des sommets fortement liés aux autres.
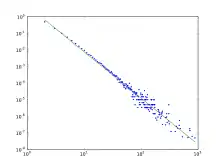
La distribution des degrés résultant du modèle BA est sans échelle, en particulier, il s’agit d’une loi de puissance de la forme :

Les concentrateurs (hubs) présentent une centralité élevée qui permet à de plus courts chemins d’exister entre les sommets. En conséquence, le modèle BA a tendance à avoir des longueurs moyennes de chemin très courtes. Le coefficient de regroupement de ce modèle tend également à 0. Tandis que le diamètre D de plusieurs modèles incluant celui d' Erdős et Rényi ainsi que plusieurs des réseaux « petit monde » est proportionnel au log D, le modèle BA présente D~loglogN (ultrasmall world)[45]. Il est à noter que la distance moyenne varie en fonction de N en tant que diamètre.
Modèle d'attachement préférentiel permettant l'émergence de communautés
Si une communauté est définie au sens strict comme un ensemble d'acteurs et d'éléments sémantiques partagés qui sont interreliés, il suffit de moduler l'attachement préférentiel en fonction d'un degré d'homophilie prédéfini de façon à favoriser les liaisons des sommets fortement similaires sans être identiques, il est possible de voir l'émergence et l'évolution d'une communauté[46],[47],[48].
Modèle d'attachement préférentiel basé sur la médiation (MDA)
Dans le modèle d'attachement préférentiel basé sur la médiation (mediation-driven attachment (MDA) model ) un nouveau sommet arrive avec arêtes, choisit ensuite aléatoirement un sommet déjà connecté au réseau et se connecte, non pas à ce sommet, mais avec de ses voisins, eux aussi choisis aléatoirement. La probabilité que le sommet d'un sommet existant soit choisi est :



Le facteur est l'inverse de la moyenne harmonique (IHM) des degrés des voisins d'un sommet . Des recherches suggèrent que, pour approximativement la valeur moyenne de l'inverse de la moyenne harmonique dans la grande limite devient une constante qui signifie , ce qui implique que plus le sommet a de liens (degré élevé), plus il a de chances d’obtenir encore plus de liens, car ils peuvent être rejoints de multiples façons par le biais de médiateurs qui incarnent essentiellement l’idée d'attachement du modèle Barabasi-Albert (BA). Par conséquent, on peut voir que le réseau MDA suit la règle de l’attachement préférentielle, mais de façon déguisée[49].





Toutefois, décrit que le gagnant prend tout car il s'avère que près de du total des sommets n'ont qu'un degré tandis qu'un sommet est super riche en degré. Alors que la valeur augmente, la disparité entre le super riche et les pauvres décroît et lorsque , il se produit une transition de « le plus riche devient plus riche » à « le riche obtient des liens plus riches ».


Modèle d'adaptabilité (fitness model)
Le fitness model est un modèle de l'évolution d'un réseau, c'est-à-dire qu'il exprime la façon dont les liens entre les sommets évoluent dans le temps et dépendent de la forme des sommets. Les nœuds les mieux adaptés attirent plus de liens aux dépens des moins adaptés, ce qui a été introduit par Caldarelli et al[50].
Dans ce modèle, un lien est créé entre deux sommets avec une probabilité donnée par une fonction relationnelle de l'adaptabilité des sommets impliqués. Le degré d'un sommet est donné par[51] :



Si est une fonction inversible et croissante de , alors la distribution probabiliste est donné par :




En conséquence, si le fitness est distribué tel une loi de puissance, alors les degrés des sommets le seront aussi.

Moins intuitivement, avec une distribution de probabilité décroissante conjointe rapide avet une fonction de liaison


avec une constante et comme fonction Heavyside, nous obtenons également des réseaux sans échelle.


Un tel modèle a été appliqué avec succès afin de décrire les relations commerciales entre pays en utilisant le PIB comme moyen d’adaptation aux divers sommets et une fonction de liaison de ce genre[52],[53].

Modèle SIR en épidémiologie
En 1927, W. O. Kermack and A. G. McKendrick ont créé un modèle épidémiologique dans lequel ils considèrent une population donnée avec seulement trois compartiments (catégories) : sain , infecté, , et remis . Les catégories utilisées dans ce modèle consistent en trois classes :



- est utilisé pour représenter le nombre de cas qui ne sont pas encore infectés par une maladie infectieuse donnée au temps t, ou encore ceux susceptibles de la contracter.
- décrit le nombre de cas ayant été infectés par la maladie (au temps t) et étant aptes à transmettre la maladie à ceux dans la catégorie susceptible de la contracter.
- est la catégorie utilisée pour les cas de rémission (au temps t). Ceux qui sont dans cette catégorie ne peuvent pas être infectés à nouveau, ni transmettre la maladie à d'autres.
Le flux de ce modèle peut être vu ainsi :

Utilisant une population donnée , Kermack et McKendrick en ont dérivé l'équation suivante :


Plusieurs hypothèses ont découlé de cette formulation : premièrement, un individu dans une population doit être considéré comme ayant une probabilité égale aux autres individus de contracter la maladie avec un taux de , ce qui est considéré comme étant le taux d'infection de la maladie. Ainsi, un individu infecté interagit et est capable de transmettre la maladie avec autres par unité de temps et la fraction des contacts par un infecté envers un susceptible de l'être est . Le nombre de nouvelles infections dans une unité de temps donnée est : , selon le taux de nouvelles infections (ou de ceux qui restent dans la catégorie des susceptibles d'être infectés) en tant que (Brauer & Castillo-Chavez, 2001). Pour ce qui est des seconde et troisième équations, on considère la population quittant la catégorie susceptible comme étant égal à la fraction (qui représente le taux moyen de rémission, et la période moyenne de l'affection) le taux d’infectieux qui quittent cette classe par unité de temps, pour entrer dans la classe des guéris. Ces processus qui occurrent simultanément font référence à la loi d'action de masse, une idée largement acceptée selon laquelle le taux de contact entre deux groupes d'une population est proportionnel à la taille de chacun de ces groupes (Daley & Gani, 2005). Finalement, il est tenu pour acquis que le taux d'infection et de rémission est plus rapide que l'échelle de temps des naissances et morts, et qu'ainsi, ces facteurs sont ignorés par ce modèle.







Susceptible d'infecter

La formule ci-dessus décrit la « force » d'infection pour chaque unité susceptible dans une population infectieuse, où β est équivalent au taux de transmission de ladite maladie.
Pour monitorer le changement des personnes vulnérables au sein d'une population infectieuse :

Infecté à remis

Au cours du temps, le nombre des infectés fluctue par : le taux spécifié de rémission, représenté par mais déduit à un sur la période infectieuse moyenne , le nombre d'individus infectieux : , et le changement dans le temps : .




Période infectieuse
À savoir si une pandémie vaincra une population, en ce qui concerne le SIR model, dépend de la valeur de ou de la « moyenne des gens infectés par un individu infecté »


Approche via l'équation maîtresse
Une équation maîtresse peut décrire l'évolution d'un réseau non orienté où, à chaque période donnée, un nouveau sommet est ajouté au réseau, lié à un ancien sommet (choisi aléatoirement sans aucune préférence). Le réseau initial est formé par deux sommets et deux liens entre eux au temps , cette configuration est nécessaire seulement pour simplifier de plus amples calculs, alors au temps le réseau a sommets et liens.


L'équation maîtresse pour ce type de réseau est :

où est la probabilité d'avoir le sommet avec un degré au temps , et est l’intervalle de temps pendant lequel ce sommet a été ajouté au réseau. Il est à noter qu'il n'existe que deux façons pour un ancien sommet d'avoir liens au temps :



- Le sommet a un degré au temps et sera lié au nouveau lien avec une probabilité
- Il a déjà le degré au temps et ne sera pas lié avec un nouveau sommet



Après simplification, la distribution des degrés est : [54]

Sur la base de ce réseau en expansion, un modèle épidémique est développé selon une règle simple : chaque fois que le nouveau sommet est ajouté et après avoir choisi l’ancien sommet à lier, une décision est prise : déterminer si ce nouveau sommet sera infecté. L'équation maîtresse de ce modèle épidémiologique est la suivante :

où représente la décision d'infecter () ou pas (). En résolvant cette équation maîtresse, la solution suivante est obtenue: [55]




Mesures et propriétés
Les réseaux ont généralement des attributs qui peuvent être mesurés afin d'analyser leurs propriétés et caractéristiques. Le comportement de ces propriétés de réseau définit souvent des modèles de réseau et peut être utilisé pour analyser le contraste de certains modèles. Le lexique de la théorie des graphes contient de nombreuses définitions d'autres termes utilisés en science des réseaux.
Taille
La taille d'un réseau peut faire référence au nombre de nœuds ou, moins souvent, à la somme des arêtes qui (pour les graphes connectés sans multi-arêtes) peut aller de (un arbre) à (un graphe complet). Dans le cas d'un graphe simple où au plus une arête existe entre chaque paire de sommets, et où aucun sommet n'est connecté à lui-même, cela donne : ; pour un graphe orienté (sans nœud connecté à lui-même) : ; pour un graphe orienté permettant l'auto-connexion : . Dans le cas d'un graphe où plusieurs arêtes peuvent exister entre les dyades : .







Diamètre
Le diamètre du réseau est la distance la plus courte entre les deux nœuds les plus distants du réseau. En d'autres termes, une fois que la longueur de chemin la plus courte de chaque nœud à tous les autres nœuds est calculée, le diamètre est la plus grande de toutes les longueurs de chemin calculées. Le diamètre est représentatif de la taille linéaire d'un réseau.
Longueur de chemin
La distance moyenne du chemin le plus court est calculée en recherchant le chemin le plus court entre toutes les paires de nœuds et en prenant la moyenne de tous les chemins de la longueur (la longueur correspond au nombre d'arêtes intermédiaires contenues dans le chemin : la distance entre les deux arêtes d'un graphe). Ce qui montre, en moyenne, le nombre d’étapes à franchir pour passer d’un membre du réseau à un autre. Le comportement de la longueur de chemin le plus court moyen attendu (c'est-à-dire la moyenne d'ensemble de la longueur de chemin le plus court moyen) en fonction du nombre de sommets d'un modèle de réseau aléatoire détermine si ce modèle présente l’effet du petit monde ; si elle définit , le modèle génère des réseaux de petit monde. Pour une croissance plus rapide que logarithmique, le modèle ne produit pas de petits mondes. Le cas particulier de est connu sous le nom d'effet d'ultra petit monde.




Densité
La densité d'un réseau, définie en tant que ratio du nombre d'arêtes sur le nombre de liens possibles vers les nœuds dans le réseau, est fournie (dans le cas de graphes simples) par le binomial coefficient , donnant . Une autre équation possible est lorsque les liens sont unidirectionnels (Wasserman & Faust 1994)[56].





Densité de réseau planaire
La densité d'un réseau, lorsqu'il n'y a pas d'intersection entre les arêtes, définie comme étant le ratio du nombre d'arêtes sur le nombre possible d'arêtes vers les nœuds dans un réseau, est fournie par un graphe planaire , giving


Degré moyen
Le degré d'un nœud correspond au nombre d'arêtes qui lui sont connectées. Le degré moyen est étroitement lié à la densité d’un réseau : (ou, dans le cas d'un graphe orienté : ; Le facteur de 2 résultant de chaque arête dans un graphe non orienté contribuant au degré de deux sommets distincts). Dans le ER random graph model (), il est possible de calculer la valeur attendue de (égale à la valeur attendue de d'un nœud arbitraire) : une arête aléatoire a autres arêtes dans le réseau disponible, avec une probabilité d'être connectée à chacun. Ainsi : .




Coefficient de clustering
Le coefficient de regroupement est une mesure de transitivité. Ceci est parfois décrit sous la règle : « les amis de mes amis sont mes amis ». Plus précisément, le coefficient de regroupement d'un nœud est le rapport des liens existants reliant les voisins d'un nœud au nombre maximal possible de tels liens. Le coefficient de regroupement pour l'ensemble du réseau est la moyenne des coefficients de regroupement de tous les nœuds. Un coefficient de clustering élevé pour un réseau est une autre indication d'un petit monde et de cohésion sociale.
Le coefficient de regroupement du 'ième sommet est :

quand est le nombre de voisins du 'ième sommet, et est le nombre de connexions entre ses voisins. Le nombre maximum possible de connexions entre voisins est alors :


D'un point de vue probabiliste, le coefficient de clustering local attendu est la probabilité qu'un lien existe entre deux voisins arbitraires du même nœud.
Connectivité
La façon dont un réseau est connecté joue un rôle important dans la manière dont les réseaux sont analysés et interprétés. Les réseaux sont classés en quatre catégories différentes:
- Clique
- Composante massive
- Composante faiblement connectée
- Composante fortement connectée
Centralité
Des informations sur l’importance relative des nœuds et/ou des arêtes d'un graphe peuvent être obtenues au moyen de mesures de centralité, largement utilisées dans des disciplines telles que la sociologie.
Par exemple, la centralité de vecteurs propres utilise les vecteurs propres de la matrice d'adjacence correspondant à un réseau pour déterminer les nœuds qui ont tendance à être fréquemment visités. Les mesures de centralité formellement établies sont le degré de centralité, la centralité de proximité, la centralité d'intermédiarité, la centralité de vecteur propre, la centralité de sous-graphe et la centralité de Katz. La visée de l'analyse détermine généralement le type de mesure de centralité à utiliser. Par exemple, si l’on s’intéresse à la dynamique des réseaux ou à la robustesse d’un réseau, l’importance dynamique d’un nœud est souvent la mesure la plus pertinente en matière de centralité[57]. Il existe aussi une mesure de centralité basée sur la non-densité du graphe (k-core number)[58].
Les indices de centralité ne sont précis que pour identifier les nœuds les plus centraux. Les mesures sont rarement, voire jamais, utiles pour le reste des nœuds du réseau[59],[60]. En outre, leurs indications ne sont exactes que dans le contexte d'importance supposée et ont tendance à ne pas être fiables dans d'autres contextes[61]. Les limitations aux mesures de centralité ont conduit à l'élaboration de mesures plus générales. L'accessibilité, qui utilise la diversité des marches aléatoires pour mesurer le degré d'accessibilité du reste du réseau à partir d'un nœud de démarrage donné, en est un exemple[62] et la force attendue, dérivée de la valeur attendue de la force d'infection générée par un nœud[59].
Le concept de centralité dans le contexte de réseaux statiques a été étendu, fondé sur des recherches empiriques et théoriques, à la centralité dynamique[14] dans le contexte des réseaux temporels[10],[11],[12].
Assortativité
Ces concepts sont utilisés pour caractériser les préférences de liaison des concentrateurs (hubs) d'un réseau. Les hubs sont des nœuds comportant un grand nombre de liens : des célébrités, des portiers, des grandes institutions, etc. Certains concentrateurs ont tendance à se connecter à d'autres concentrateurs, tandis que d'autres évitent de se connecter à des concentrateurs et préfèrent se connecter à des nœuds peu connectés. Un hub est assortatif lorsqu'il a tendance à se connecter à d'autres hubs. Un hub désassortatif évite de se connecter à d'autres hubs. Si les concentrateurs ont des connexions avec les probabilités aléatoires attendues, ils sont dits neutres. La notion d'assortativité est utilisée en analyse des réseaux sociaux[63] et est similaire à celle d'homophilie. La désassortativité est rare dans le monde social et peut relever d'une stratégie d'optimisation du capital social par la production de trous structuraux.
Contagion/propagation/diffusion
Le contenu d'un réseau complexe peut se répandre via deux méthodes principales : la propagation conservée et la propagation non conservée[64]. En propagation conservée, la quantité totale de contenu entrant dans un réseau complexe reste constante lors de son passage. Le modèle de propagation conservée peut être mieux représenté par un pichet contenant une quantité fixe d’eau versée dans une série d’entonnoirs reliés par des tubes. Ici, le pichet représente la source d’origine et l’eau le contenu à répandre. Les entonnoirs et les tubes de connexion représentent respectivement les nœuds et les connexions entre les nœuds. Lorsque l'eau passe d'un entonnoir à un autre, elle disparaît instantanément de l'entonnoir précédemment exposé à l'eau. Lorsque la propagation est non conservée, la quantité de contenu change à mesure qu’il entre et passe à travers le réseau complexe. Le modèle de propagation non conservée peut être représenté au mieux par un robinet fonctionnant en continu traversant une série d’entonnoirs reliés par des tubes. Ici, la quantité d'eau de la source d'origine est infinie. En outre, tous les entonnoirs qui ont été exposés à l'eau continuent de faire l'expérience de l'eau même lorsqu'elle passe par des entonnoirs successifs. Le modèle non conservé est le plus approprié pour expliquer la transmission de la plupart des maladies infectieuses, l'excitation neuronale, la diffusion de l'information et des rumeurs, etc.
Robustesse d'un réseau
La robustesse structurelle des réseaux est étudiée via la théorie de la percolation[65]. Lorsqu'une fraction critique de nœuds (ou de liens) est supprimée d'un réseau, celui-ci se fragmente en composantes distinctes[66]. Ce processus de percolation représente une transition de phase de type ordre-désordre avec des exposants critiques. La théorie de la percolation permet de prévoir la taille de la composante la plus grande (appelée composante géante), du seuil critique et des exposants critiques.
Optimisation réseau
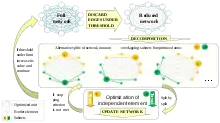
Les problèmes réseaux qui impliquent de chercher une façon optimale de remplir une tâche donnée sont étudiés sous l'appellation d'optimisation combinatoire. Les cas à résoudre comprennent notamment ceux concernant les réseaux de flot, les problèmes de plus court chemin, ceux en théorie du transport, les problèmes de l'emplacement d'installations, les problèmes de couplage, les problèmes d'affectation, les problèmes de compactage, d'empilement, de routage, de chemin critique, et le PERT (Program Evaluation & Review Technique).
Afin de décomposer une tâche d'optimisation du réseau NP-difficile en sous-tâches, le réseau est décomposé en sous-réseaux relativement indépendants[67].
Implémentations
- igraph est une librairie open source en C pour l'analyse de larges réseaux complexes, ayant des interfaces en R, Python and Ruby.
- Gephi est un logiciel libre d'analyse et de visualisation de réseaux, développé en Java et fondé sur la plateforme NetBeans.
- Visone est un logiciel libre permettant d'analyser et visualiser des réseaux sociaux.
- NetworkX est un logiciel libre ayant des modules en Python pour la manipulation et l'analyse statistiques des réseaux.
- Orange est un programme open-source pour le data mining et comportant une suite pour l'analyse de réseaux.
- Pajek est un des plus anciens programmes pour l'analyse de réseaux sociaux, avec UCInet. Il permet la visualisation et plusieurs types d'analyses.
- GraphMatcher est un programme Java pour superposer un ou plusieurs réseaux.
- Tulip est un logiciel libre de data mining et de visualisation de données relationnelles.
- SEMOSS est outil d'analyse contextuelle open source, basé sur le RDF, écrit en Java et utilisant le langage de requête SPARQL.
- GraphStream est une librairie Java pour modéliser et analyser des réseaux dynamiques.
- DataWalk est un programme permettant de mettre en corrélation de grands ensembles de données.
Voir aussi
Liens externes
- (en)Netwiki Un wiki dédié aux systèmes complexe et réseaux.
- (en)Network theory - Marc Samet
Bibliographie complémentaire
- Degenne, Alain, and Michel Forsé. "Les réseaux sociaux." (2004).
- Lazega, Emmanuel. Réseaux sociaux et structures relationnelles:«Que sais-je?» n° 3399. Presses universitaires de France, 2014.
- Harrison C. White, Frédéric Godart, Victor Corona, Produire en contexte d'incertitude : La construction des identités et des liens sociaux dans les marchés. Sciences de la société, Nº. 73, 2008. p. 17-40
- (en) Ahuja, Ravindra K. Network flows: theory, algorithms, and applications. Pearson Education, 2017.
- (en) Granovetter, Mark. "The strength of weak ties: A network theory revisited." Sociological theory (1983): 201-233.
- (en) Borgatti, Stephen P., and Daniel S. Halgin. "On network theory." Organization science 22, no. 5 (2011): 1168-1181.
- (en) Lin, Nan. "Building a network theory of social capital." In Social capital, p. 3-28. Routledge, 2017.
- (en) Borgatti, Stephen P. "Centrality and network flow." Social networks 27, no. 1 (2005): 55-71.
- (en)Girvan, Michelle, and Mark EJ Newman. "Community structure in social and biological networks." Proceedings of the national academy of sciences 99, no. 12 (2002): 7821-7826.
Références
- (Anglais) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Network theory » (voir la liste des auteurs).
- (en) König, Dénes. (Il s'agit d'une réédition de : Kőnig, Dénes (1936), Theorie der endlichen und unendlichen Graphen,), Theory of finite and infinite graphs, Birkhäuser, (ISBN 0817633898, 9780817633899 et 3764333898, OCLC 804038683, lire en ligne)
- (en) « Sociometry | Encyclopedia.com », sur www.encyclopedia.com (consulté le )
- Committee on Network Science for Future Army Applications, Network Science, National Research Council, (ISBN 0-309-65388-6, lire en ligne)
- Martin Grandjean, « La connaissance est un réseau », Les Cahiers du Numérique, vol. 10, no 3, , p. 37–54 (DOI 10.3166/lcn.10.3.37-54, lire en ligne, consulté le )
- Wasserman, Stanley and Katherine Faust. 1994. Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press. Rainie, Lee and Barry Wellman, Networked: The New Social Operating System. Cambridge, MA: MIT Press, 2012.
- Newman, M.E.J. Networks: An Introduction. Oxford University Press. 2010
- Ronald S. Burt, « Innovation as a structural interest: rethinking the impact of network position on innovation adoption », Social Networks, vol. 2, no 4, , p. 327–355 (ISSN 0378-8733, DOI 10.1016/0378-8733(80)90002-7, lire en ligne, consulté le )
- M. E. J. Newman, « The Structure and Function of Complex Networks », SIAM Review, vol. 45, no 2, , p. 167–256 (ISSN 0036-1445 et 1095-7200, DOI 10.1137/s003614450342480, lire en ligne, consulté le )
- Harrison C. White, Markets from Networks : Socioeconomic Models of Production, Princeton University Press, (ISBN 978-0-691-18762-4 et 0691187622, lire en ligne)
- S.A. Hill et D. Braha, « Dynamic Model of Time-Dependent Complex Networks », Physical Review E, vol. 82, , p. 046105 (DOI 10.1103/physreve.82.046105, Bibcode 2010PhRvE..82d6105H, arXiv 0901.4407)
- Gross, T. and Sayama, H. (Eds.). 2009. Adaptive Networks: Theory, Models and Applications. Springer.
- Holme, P. and Saramäki, J. 2013. Temporal Networks. Springer.
- Xanthos, Aris, Pante, Isaac, Rochat, Yannick, Grandjean, Martin (2016). Visualising the Dynamics of Character Networks. In Digital Humanities 2016: Jagiellonian University & Pedagogical University, Kraków, p. 417–419.
- D. Braha et Y. Bar-Yam, « From Centrality to Temporary Fame: Dynamic Centrality in Complex Networks », Complexity, vol. 12, , p. 59–63 (DOI 10.1002/cplx.20156, Bibcode 2006Cmplx..12b..59B, arXiv physics/0611295)
- (en) Iman Habibi, Effat S. Emamian et Ali Abdi, « Quantitative analysis of intracellular communication and signaling errors in signaling networks », BMC Systems Biology, vol. 8, , p. 89 (lire en ligne)
- (en) Iman Habibi, Effat S. Emamian et Ali Abdi, « Advanced Fault Diagnosis Methods in Molecular Networks », PLOS ONE, vol. 9, no 10, (lire en ligne)
- (en) A. L. Barabási, N. Gulbahce et J. Loscalzo, « Network medicine: a network-based approach to human disease », Nature Reviews Genetics, vol. 12, no 1, , p. 56–68 (lire en ligne)
- (en) N. Jailkhani, S. Ravichandran, S. R. Hegde et Z. Siddiqui, « Delineation of key regulatory elements identifies points of vulnerability in the mitogen-activated signaling network », Genome Research, vol. 21, no 12, , p. 2067–2081 (lire en ligne)
- (en) Amir Bashan, Ronny P. Bartsch, Jan. W. Kantelhardt, Shlomo Havlin et Plamen Ch. Ivanov, « Network physiology reveals relations between network topology and physiological function », Nature Communications, vol. 3, , p. 702 (lire en ligne)
- Automated analysis of the US presidential elections using Big Data and network analysis; S Sudhahar, GA Veltri, N Cristianini; Big Data & Society 2 (1), 1–28, 2015
- Network analysis of narrative content in large corpora; S Sudhahar, G De Fazio, R Franzosi, N Cristianini; Natural Language Engineering, 1–32, 2013
- Quantitative Narrative Analysis; Roberto Franzosi; Emory University © 2010
- (en) Mahmoud Saleh, Yusef Esa et Ahmed Mohamed, « Applications of Complex Network Analysis in Electric Power Systems », Energies, vol. 11, no 6, , p. 1381 (lire en ligne)
- (en) Mahmoud Saleh, Yusef Esa et Ahmed Mohamed, « Optimal microgrids placement in electric distribution systems using complex network framework » [PDF]
- (en) Mahmoud Saleh, Yusef Esa et Ahmed Mohamed, « Applications of Complex Network Analysis in Electric Power Systems », Energies, vol. 11, no 6, , p. 1381 (lire en ligne)
- (en-US) Mahmoud Saleh, Yusef Esa et Ahmed Mohamed, « Optimal microgrids placement in electric distribution systems using complex network framework » [PDF] (consulté le )
- Anastasios A. Tsonis, Kyle L. Swanson et Paul J. Roebber, « What Do Networks Have to Do with Climate? », Bulletin of the American Meteorological Society, vol. 87, no 5, , p. 585–595 (ISSN 0003-0007, DOI 10.1175/BAMS-87-5-585, Bibcode 2006BAMS...87..585T)
- K. Yamasaki, A. Gozolchiani et S. Havlin, « Climate Networks around the Globe are Significantly Affected by El Niño », Physical Review Letters, vol. 100, no 22, , p. 228501 (ISSN 0031-9007, PMID 18643467, DOI 10.1103/PhysRevLett.100.228501, Bibcode 2008PhRvL.100v8501Y)
- N. Boers, B. Bookhagen, H.M.J. Barbosa, N. Marwan et J. Kurths, « Prediction of extreme floods in the eastern Central Andes based on a complex networks approach », Nature Communications, vol. 5, , p. 5199 (ISSN 2041-1723, PMID 25310906, DOI 10.1038/ncomms6199, Bibcode 2014NatCo...5E5199B)
- G. Attardi, S. Di Marco et D. Salvi, « Categorization by Context », Journal of Universal Computer Science, vol. 4, no 9, , p. 719–736 (lire en ligne)
- N. Marwan, J.F. Donges, Y. Zou, R.V. Donner et J. Kurths, « Complex network approach for recurrence analysis of time series », Physics Letters A, vol. 373, no 46, , p. 4246–4254 (ISSN 0375-9601, DOI 10.1016/j.physleta.2009.09.042, Bibcode 2009PhLA..373.4246M, arXiv 0907.3368)
- R.V. Donner, J. Heitzig, J.F. Donges, Y. Zou, N. Marwan et J. Kurths, « The Geometry of Chaotic Dynamics – A Complex Network Perspective », European Physical Journal B, vol. 84, , p. 653–672 (ISSN 1434-6036, DOI 10.1140/epjb/e2011-10899-1, Bibcode 2011EPJB...84..653D, arXiv 1102.1853)
- J.H. Feldhoff, R.V. Donner, J.F. Donges, N. Marwan et J. Kurths, « Geometric signature of complex synchronisation scenarios », Europhysics Letters, vol. 102, no 3, , p. 30007 (ISSN 1286-4854, DOI 10.1209/0295-5075/102/30007, Bibcode 2013EL....10230007F, arXiv 1301.0806)
- S. V. Buldyrev, R. Parshani, G. Paul, H. E. Stanley et S. Havlin, « Catastrophic cascade of failures in interdependent networks », Nature, vol. 464, no 7291, , p. 1025–28 (PMID 20393559, DOI 10.1038/nature08932, Bibcode 2010Natur.464.1025B, arXiv 0907.1182, lire en ligne)
- Jianxi Gao, Sergey V. Buldyrev, Shlomo Havlin et H. Eugene Stanley, « Robustness of a Network of Networks », Phys. Rev. Lett., vol. 107, no 19, , p. 195701 (PMID 22181627, DOI 10.1103/PhysRevLett.107.195701, Bibcode 2011PhRvL.107s5701G, arXiv 1010.5829, lire en ligne)
- Edward A Bender et E.Rodney Canfield, « The asymptotic number of labeled graphs with given degree sequences », Journal of Combinatorial Theory, Series A, vol. 24, no 3, , p. 296–307 (ISSN 0097-3165, DOI 10.1016/0097-3165(78)90059-6, lire en ligne)
- (en) Michael Molloy et Bruce Reed, « A critical point for random graphs with a given degree sequence », Random Structures & Algorithms, vol. 6, nos 2-3, , p. 161–180 (ISSN 1042-9832, DOI 10.1002/rsa.3240060204, lire en ligne)
- M. E. J. Newman, S. H. Strogatz et D. J. Watts, « Random graphs with arbitrary degree distributions and their applications », Physical Review E, vol. 64, no 2, , p. 026118 (DOI 10.1103/PhysRevE.64.026118, Bibcode 2001PhRvE..64b6118N, arXiv cond-mat/0007235, lire en ligne)
- Ivan Kryven, « General expression for the component size distribution in infinite configuration networks », Physical Review E, vol. 95, no 5, , p. 052303 (DOI 10.1103/PhysRevE.95.052303, Bibcode 2017PhRvE..95e2303K, arXiv 1703.05413, lire en ligne)
- (en) Ivan Kryven, « Analytic results on the polymerisation random graph model », Journal of Mathematical Chemistry, vol. 56, no 1, , p. 140–157 (ISSN 0259-9791, DOI 10.1007/s10910-017-0785-1, lire en ligne)
- Ivan Kryven, « Emergence of the giant weak component in directed random graphs with arbitrary degree distributions », Physical Review E, vol. 94, no 1, , p. 012315 (DOI 10.1103/PhysRevE.94.012315, Bibcode 2016PhRvE..94a2315K, arXiv 1607.03793, lire en ligne)
- Ivan Kryven, « Finite connected components in infinite directed and multiplex networks with arbitrary degree distributions », Physical Review E, vol. 96, no 5, , p. 052304 (DOI 10.1103/PhysRevE.96.052304, Bibcode 2017PhRvE..96e2304K, arXiv 1709.04283, lire en ligne)
- R. Albert et A.-L. Barabási, « Statistical mechanics of complex networks », Reviews of Modern Physics, vol. 74, , p. 47–97 (DOI 10.1103/RevModPhys.74.47, Bibcode 2002RvMP...74...47A, arXiv cond-mat/0106096, lire en ligne [archive du ])
- Albert-László Barabási & Réka Albert, « Emergence of scaling in random networks », Science, vol. 286, no 5439, , p. 509–512 (PMID 10521342, DOI 10.1126/science.286.5439.509, Bibcode 1999Sci...286..509B, arXiv cond-mat/9910332, lire en ligne [archive du ])
- R. Cohen et S. Havlin, « Scale-free networks are ultrasmall », Phys. Rev. Lett., vol. 90, no 5, , p. 058701 (PMID 12633404, DOI 10.1103/PhysRevLett.90.058701, Bibcode 2003PhRvL..90e8701C, arXiv cond-mat/0205476, lire en ligne)
- Camille Roth, « Coévolution des auteurs et des concepts dans les réseaux épistémiques : le cas de la communauté « zebrafish » », Revue française de sociologie, vol. 49, no 3, , p. 523 (ISSN 0035-2969 et 1958-5691, DOI 10.3917/rfs.493.0523, lire en ligne, consulté le )
- K. Guerrero et J. Finke, « On the formation of community structures from homophilic relationships », 2012 American Control Conference (ACC), IEEE, (ISBN 9781457710964, DOI 10.1109/acc.2012.6315325, lire en ligne, consulté le )
- Camille Roth et Paul Bourgine, « Epistemic Communities: Description and Hierarchic Categorization », Mathematical Population Studies, vol. 12, no 2, , p. 107–130 (ISSN 0889-8480 et 1547-724X, DOI 10.1080/08898480590931404, lire en ligne, consulté le )
- M. K. Hassan, Liana Islam et Syed Arefinul Haque, « Degree distribution, rank-size distribution, and leadership persistence in mediation-driven attachment networks », Physica A, vol. 469, , p. 23–30 (DOI 10.1016/j.physa.2016.11.001, Bibcode 2017PhyA..469...23H, arXiv 1411.3444)
- Caldarelli G., A. Capocci, P. De Los Rios, M.A. Muñoz, Physical Review Letters 89, 258702 (2002)
- Servedio V.D.P., G. Caldarelli, P. Buttà, Physical Review E 70, 056126 (2004)
- Garlaschelli D., M I Loffredo Physical Review Letters 93, 188701 (2004)
- Cimini G., T. Squartini, D. Garlaschelli and A. Gabrielli, Scientific Reports 5, 15758 (2015)
- (en) S N Dorogovtsev et J F F Mendes, Evolution of networks : from biological nets to the Internet and WWW, New York, NY, USA, Oxford University Press, Inc., , 264 p. (ISBN 0-19-851590-1, lire en ligne)
- M Cotacallapa et M O Hase, « Epidemics in networks: a master equation approach », Journal of Physics A, vol. 49, no 6, , p. 065001 (DOI 10.1088/1751-8113/49/6/065001, Bibcode 2016JPhA...49f5001C, arXiv 1604.01049, lire en ligne, consulté le )
- http://psycnet.apa.org/journals/prs/9/4/172/
- Juan Restrepo, E. Ott et B. R. Hunt, « Characterizing the Dynamical Importance of Network Nodes and Links », Phys. Rev. Lett., vol. 97, no 9, , p. 094102 (PMID 17026366, DOI 10.1103/PhysRevLett.97.094102, Bibcode 2006PhRvL..97i4102R, arXiv cond-mat/0606122, lire en ligne)
- S. Carmi, S. Havlin, S. Kirkpatrick, Y. Shavitt et E. Shir, « A model of Internet topology using k-shell decomposition », Proceedings of the National Academy of Sciences, vol. 104, no 27, , p. 11150–11154 (ISSN 0027-8424, PMID 17586683, PMCID 1896135, DOI 10.1073/pnas.0701175104, Bibcode 2007PNAS..10411150C, arXiv cs/0607080)
- Glenn Lawyer, « Understanding the spreading power of all nodes in a network », Scientific Reports, vol. 5, no O8665, , p. 8665 (PMID 25727453, PMCID 4345333, DOI 10.1038/srep08665, Bibcode 2015NatSR...5E8665L, arXiv 1405.6707, lire en ligne)
- Mile Sikic, Alen Lancic, Nino Antulov-Fantulin et Hrvoje Stefancic, « Epidemic centrality -- is there an underestimated epidemic impact of network peripheral nodes? », European Physical Journal B, vol. 86, no 10, , p. 1–13 (DOI 10.1140/epjb/e2013-31025-5, Bibcode 2013EPJB...86..440S, arXiv 1110.2558)
- Stephen P. Borgatti, « Centrality and Network Flow », Elsevier, vol. 27, , p. 55–71 (DOI 10.1016/j.socnet.2004.11.008)
- B. A. N. Travençolo et L. da F. Costa, « Accessibility in complex networks », Physics Letters A, vol. 373, no 1, , p. 89–95 (DOI 10.1016/j.physleta.2008.10.069, Bibcode 2008PhLA..373...89T)
- M. E. J. Newman, « Assortative Mixing in Networks », Physical Review Letters, vol. 89, no 20, (ISSN 0031-9007 et 1079-7114, DOI 10.1103/physrevlett.89.208701, lire en ligne, consulté le )
- Newman, M., Barabási, A.-L., Watts, D.J. [eds.] (2006) The Structure and Dynamics of Networks. Princeton, N.J.: Princeton University Press.
- R. Cohen et S. Havlin, Complex Networks : Structure, Robustness and Function, Cambridge University Press, (lire en ligne)
- A. Bunde et S. Havlin, Fractals and Disordered Systems, Springer, (lire en ligne)
- Ignatov, D.Yu., Filippov, A.N., Ignatov, A.D. et Zhang, X., « Automatic Analysis, Decomposition and Parallel Optimization of Large Homogeneous Networks », Proc. ISP RAS, vol. 28, , p. 141–152 (DOI 10.15514/ISPRAS-2016-28(6)-10, arXiv 1701.06595, lire en ligne)
 Portail de l'informatique théorique
Portail de l'informatique théorique  Portail de la sociologie
Portail de la sociologie  Portail de la biologie
Portail de la biologie