Beta distribution
In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or (0, 1) in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
|
Probability density function 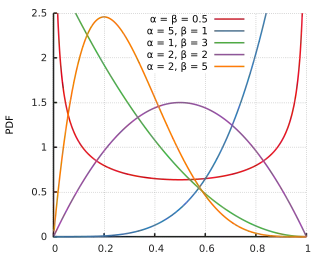 | |||
|
Cumulative distribution function 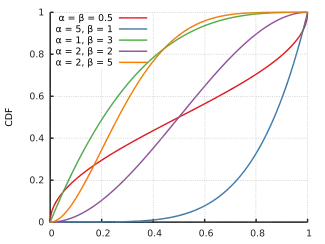 | |||
| Notation | Beta(α, β) | ||
|---|---|---|---|
| Parameters |
α > 0 shape (real) β > 0 shape (real) | ||
| Support | or | ||
|
where and is the Gamma function. | |||
| CDF |
(the regularized incomplete beta function) | ||
| Mean |
| ||
| Median | |||
| Mode |
for α, β > 1 any value in for α, β = 1 {0, 1} (bimodal) for α, β < 1 0 for α ≤ 1, β > 1 1 for α > 1, β ≤ 1 | ||
| Variance |
(see trigamma function and see section: Geometric variance) | ||
| Skewness | |||
| Ex. kurtosis | |||
| Entropy | |||
| MGF | |||
| CF | (see Confluent hypergeometric function) | ||
| Fisher information |
see section: Fisher information matrix | ||
| Method of Moments |
| ||
![{\displaystyle x\in [0,1]\!}](../I/09601f74a28f3e2cad381be1a915ab0c02fe39c6.svg)





![\operatorname{E}[X] = \frac{\alpha}{\alpha+\beta}\!](../I/3905662ceed484cba5580951e29eda96f4d2605e.svg)
![\operatorname{E}[\ln X] = \psi(\alpha) - \psi(\alpha + \beta)\!](../I/de67df996fa33237ab7f415e7edc9fa8e71997a0.svg)
![{\displaystyle \operatorname {E} [X\,\ln X]={\frac {\alpha }{\alpha +\beta }}\,\left[\psi (\alpha +1)-\psi (\alpha +\beta +1)\right]\!}](../I/50106a787db7d72ce3066a5a3238813cffebcc2e.svg)

![\begin{matrix}I_{\frac{1}{2}}^{[-1]}(\alpha,\beta)\text{ (in general) }\\[0.5em]
\approx \frac{ \alpha - \tfrac{1}{3} }{ \alpha + \beta - \tfrac{2}{3} }\text{ for }\alpha, \beta >1\end{matrix}](../I/af887ef0331cde970dad14ad670cf3592334f845.svg)


![\operatorname{var}[X] = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}\!](../I/f90a6ad61b4b436749ca37a6c2a1aa077b032ce3.svg)
![\operatorname{var}[\ln X] = \psi_1(\alpha) - \psi_1(\alpha + \beta)\!](../I/b4941f45412823abd34d3befea7f8fbf544135e4.svg)

![\frac{6[(\alpha - \beta)^2 (\alpha +\beta + 1) - \alpha \beta (\alpha + \beta + 2)]}{\alpha \beta (\alpha + \beta + 2) (\alpha + \beta + 3)}](../I/eea65a8d7c9e00ba6299b727eab679117776f41e.svg)
![{\displaystyle {\begin{matrix}\ln \mathrm {B} (\alpha ,\beta )-(\alpha -1)\psi (\alpha )-(\beta -1)\psi (\beta )\\[0.5em]{}+(\alpha +\beta -2)\psi (\alpha +\beta )\end{matrix}}}](../I/ff4b6cc1848fe96318adb734393b701cb816f88a.svg)


![{\displaystyle {\begin{bmatrix}\operatorname {var} [\ln X]&\operatorname {cov} [\ln X,\ln(1-X)]\\\operatorname {cov} [\ln X,\ln(1-X)]&\operatorname {var} [\ln(1-X)]\end{bmatrix}}}](../I/881f91af0ab1d6bf3809a4ed6ca9e6384544292f.svg)
}{V[X]}}-1\right)E[X]}](../I/d2b596a180ef813a0baa1d6f2063950e20da1f62.svg)
}{V[X]}}-1\right)(1-E[X])}](../I/05ace15e23f6ac9be43eea861f44c018fd3d00de.svg)
The beta distribution has been applied to model the behavior of random variables limited to intervals of finite length in a wide variety of disciplines. The beta distribution is a suitable model for the random behavior of percentages and proportions.
In Bayesian inference, the beta distribution is the conjugate prior probability distribution for the Bernoulli, binomial, negative binomial and geometric distributions.
The formulation of the beta distribution discussed here is also known as the beta distribution of the first kind, whereas beta distribution of the second kind is an alternative name for the beta prime distribution. The generalization to multiple variables is called a Dirichlet distribution.
Definitions
Probability density function
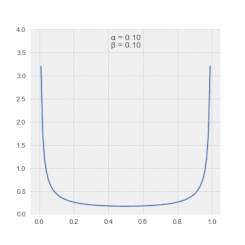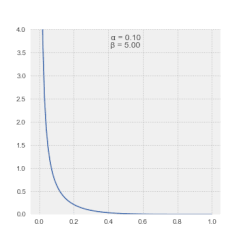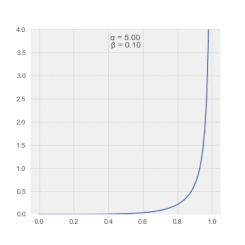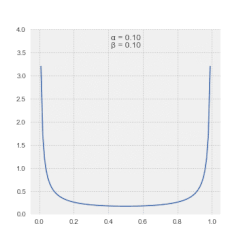
The probability density function (PDF) of the beta distribution, for 0 ≤ x ≤ 1 or 0 < x < 1, and shape parameters α, β > 0, is a power function of the variable x and of its reflection (1 − x) as follows:
![{\displaystyle {\begin{aligned}f(x;\alpha ,\beta )&=\mathrm {constant} \cdot x^{\alpha -1}(1-x)^{\beta -1}\\[3pt]&={\frac {x^{\alpha -1}(1-x)^{\beta -1}}{\displaystyle \int _{0}^{1}u^{\alpha -1}(1-u)^{\beta -1}\,du}}\\[6pt]&={\frac {\Gamma (\alpha +\beta )}{\Gamma (\alpha )\Gamma (\beta )}}\,x^{\alpha -1}(1-x)^{\beta -1}\\[6pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}x^{\alpha -1}(1-x)^{\beta -1}\end{aligned}}}](../I/5fc18388353b219c482e8e35ca4aae808ab1be81.svg)
where Γ(z) is the gamma function. The beta function, , is a normalization constant to ensure that the total probability is 1. In the above equations x is a realization—an observed value that actually occurred—of a random variable X.

Several authors, including N. L. Johnson and S. Kotz,[1] use the symbols p and q (instead of α and β) for the shape parameters of the beta distribution, reminiscent of the symbols traditionally used for the parameters of the Bernoulli distribution, because the beta distribution approaches the Bernoulli distribution in the limit when both shape parameters α and β approach the value of zero.
In the following, a random variable X beta-distributed with parameters α and β will be denoted by:[2][3]

Other notations for beta-distributed random variables used in the statistical literature are [4] and .[5]


Cumulative distribution function

The cumulative distribution function is

where is the incomplete beta function and is the regularized incomplete beta function.


Mean and sample size
The beta distribution may also be reparameterized in terms of its mean μ (0 < μ < 1) and the sum of the two shape parameters ν = α + β > 0([3] p. 83). Denoting by αPosterior and βPosterior the shape parameters of the posterior beta distribution resulting from applying Bayes theorem to a binomial likelihood function and a prior probability, the interpretation of the addition of both shape parameters to be sample size = ν = α·Posterior + β·Posterior is only correct for the Haldane prior probability Beta(0,0). Specifically, for the Bayes (uniform) prior Beta(1,1) the correct interpretation would be sample size = α·Posterior + β Posterior − 2, or ν = (sample size) + 2. For sample size much larger than 2, the difference between these two priors becomes negligible. (See section Bayesian inference for further details.) ν = α + β is referred to as the "sample size" of a Beta distribution, but one should remember that it is, strictly speaking, the "sample size" of a binomial likelihood function only when using a Haldane Beta(0,0) prior in Bayes theorem.
This parametrization may be useful in Bayesian parameter estimation. For example, one may administer a test to a number of individuals. If it is assumed that each person's score (0 ≤ θ ≤ 1) is drawn from a population-level Beta distribution, then an important statistic is the mean of this population-level distribution. The mean and sample size parameters are related to the shape parameters α and β via[3]
- α = μν, β = (1 − μ)ν
Under this parametrization, one may place an uninformative prior probability over the mean, and a vague prior probability (such as an exponential or gamma distribution) over the positive reals for the sample size, if they are independent, and prior data and/or beliefs justify it.
Mode and concentration
Concave beta distributions, which have , can be parametrized in terms of mode and "concentration". The mode, , and concentration, , can be used to define the usual shape parameters as follows:[6]




For the mode, , to be well-defined, we need , or equivalently . If instead we define the concentration as , the condition simplifies to and the beta density at and can be written as:







where directly scales the sufficient statistics, and . Note also that in the limit, , the distribution becomes flat.




Mean and variance
Solving the system of (coupled) equations given in the above sections as the equations for the mean and the variance of the beta distribution in terms of the original parameters α and β, one can express the α and β parameters in terms of the mean (μ) and the variance (var):

This parametrization of the beta distribution may lead to a more intuitive understanding than the one based on the original parameters α and β. For example, by expressing the mode, skewness, excess kurtosis and differential entropy in terms of the mean and the variance:





Four parameters
A beta distribution with the two shape parameters α and β is supported on the range [0,1] or (0,1). It is possible to alter the location and scale of the distribution by introducing two further parameters representing the minimum, a, and maximum c (c > a), values of the distribution,[1] by a linear transformation substituting the non-dimensional variable x in terms of the new variable y (with support [a,c] or (a,c)) and the parameters a and c:

The probability density function of the four parameter beta distribution is equal to the two parameter distribution, scaled by the range (c − a), (so that the total area under the density curve equals a probability of one), and with the "y" variable shifted and scaled as follows:

That a random variable Y is Beta-distributed with four parameters α, β, a, and c will be denoted by:

Some measures of central location are scaled (by (c − a)) and shifted (by a), as follows:
![{\displaystyle {\begin{aligned}\mu _{Y}&=\mu _{X}(c-a)+a\\&=\left({\frac {\alpha }{\alpha +\beta }}\right)(c-a)+a={\frac {\alpha c+\beta a}{\alpha +\beta }}\\[8pt]{\text{mode}}(Y)&={\text{mode}}(X)(c-a)+a\\&=\left({\frac {\alpha -1}{\alpha +\beta -2}}\right)(c-a)+a={\frac {(\alpha -1)c+(\beta -1)a}{\alpha +\beta -2}}\ ,\qquad {\text{ if }}\alpha ,\beta >1\\[8pt]{\text{median}}(Y)&={\text{median}}(X)(c-a)+a\\&=\left(I_{\frac {1}{2}}^{[-1]}(\alpha ,\beta )\right)(c-a)+a\end{aligned}}}](../I/f65af6c528ca47e8838d3d5722a94f9e3f128100.svg)
Note: the geometric mean and harmonic mean cannot be transformed by a linear transformation in the way that the mean, median and mode can.
The shape parameters of Y can be written in term of its mean and variance as

The statistical dispersion measures are scaled (they do not need to be shifted because they are already centered on the mean) by the range (c − a), linearly for the mean deviation and nonlinearly for the variance:



Since the skewness and excess kurtosis are non-dimensional quantities (as moments centered on the mean and normalized by the standard deviation), they are independent of the parameters a and c, and therefore equal to the expressions given above in terms of X (with support [0,1] or (0,1)):

![\text{kurtosis excess}(Y) =\text{kurtosis excess}(X)=\frac{6[(\alpha - \beta)^2 (\alpha +\beta + 1) - \alpha \beta (\alpha + \beta + 2)]}
{\alpha \beta (\alpha + \beta + 2) (\alpha + \beta + 3)}](../I/99ddb3577b02ee0b10163123af23c6d7f728946b.svg)
Properties
Mode
The mode of a Beta distributed random variable X with α, β > 1 is the most likely value of the distribution (corresponding to the peak in the PDF), and is given by the following expression:[1]

When both parameters are less than one (α, β < 1), this is the anti-mode: the lowest point of the probability density curve.[7]
Letting α = β, the expression for the mode simplifies to 1/2, showing that for α = β > 1 the mode (resp. anti-mode when α, β < 1), is at the center of the distribution: it is symmetric in those cases. See Shapes section in this article for a full list of mode cases, for arbitrary values of α and β. For several of these cases, the maximum value of the density function occurs at one or both ends. In some cases the (maximum) value of the density function occurring at the end is finite. For example, in the case of α = 2, β = 1 (or α = 1, β = 2), the density function becomes a right-triangle distribution which is finite at both ends. In several other cases there is a singularity at one end, where the value of the density function approaches infinity. For example, in the case α = β = 1/2, the Beta distribution simplifies to become the arcsine distribution. There is debate among mathematicians about some of these cases and whether the ends (x = 0, and x = 1) can be called modes or not.[8][2]

- Whether the ends are part of the domain of the density function
- Whether a singularity can ever be called a mode
- Whether cases with two maxima should be called bimodal
Median

_for_Beta_distribution_versus_alpha_and_beta_from_0_to_2_-_J._Rodal.jpg.webp)
The median of the beta distribution is the unique real number for which the regularized incomplete beta function . There is no general closed-form expression for the median of the beta distribution for arbitrary values of α and β. Closed-form expressions for particular values of the parameters α and β follow:
![{\displaystyle x=I_{1/2}^{[-1]}(\alpha ,\beta )}](../I/d7510f94efa49f254eb3924678b527a6fd22d0fc.svg)

- For symmetric cases α = β, median = 1/2.
- For α = 1 and β > 0, median (this case is the mirror-image of the power function [0,1] distribution)
- For α > 0 and β = 1, median = (this case is the power function [0,1] distribution[8])
- For α = 3 and β = 2, median = 0.6142724318676105..., the real solution to the quartic equation 1 − 8x3 + 6x4 = 0, which lies in [0,1].
- For α = 2 and β = 3, median = 0.38572756813238945... = 1−median(Beta(3, 2))


The following are the limits with one parameter finite (non-zero) and the other approaching these limits:

A reasonable approximation of the value of the median of the beta distribution, for both α and β greater or equal to one, is given by the formula[9]

When α, β ≥ 1, the relative error (the absolute error divided by the median) in this approximation is less than 4% and for both α ≥ 2 and β ≥ 2 it is less than 1%. The absolute error divided by the difference between the mean and the mode is similarly small:
![Abs[(Median-Appr.)/Median] for Beta distribution for 1 ≤ α ≤ 5 and 1 ≤ β ≤ 5](../I/Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg.webp)
![Abs[(Median-Appr.)/(Mean-Mode)] for Beta distribution for 1≤α≤5 and 1≤β≤5](../I/Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg.webp)
Mean

The expected value (mean) (μ) of a Beta distribution random variable X with two parameters α and β is a function of only the ratio β/α of these parameters:[1]
![\begin{align}
\mu = \operatorname{E}[X]
&= \int_0^1 x f(x;\alpha,\beta)\,dx \\
&= \int_0^1 x \,\frac{x^{\alpha-1}(1-x)^{\beta-1}}{\Beta(\alpha,\beta)}\,dx \\
&= \frac{\alpha}{\alpha + \beta} \\
&= \frac{1}{1 + \frac{\beta}{\alpha}}
\end{align}](../I/e9137834d9d47360ed6c23550c6236fed5fd35f7.svg)
Letting α = β in the above expression one obtains μ = 1/2, showing that for α = β the mean is at the center of the distribution: it is symmetric. Also, the following limits can be obtained from the above expression:

Therefore, for β/α → 0, or for α/β → ∞, the mean is located at the right end, x = 1. For these limit ratios, the beta distribution becomes a one-point degenerate distribution with a Dirac delta function spike at the right end, x = 1, with probability 1, and zero probability everywhere else. There is 100% probability (absolute certainty) concentrated at the right end, x = 1.
Similarly, for β/α → ∞, or for α/β → 0, the mean is located at the left end, x = 0. The beta distribution becomes a 1-point Degenerate distribution with a Dirac delta function spike at the left end, x = 0, with probability 1, and zero probability everywhere else. There is 100% probability (absolute certainty) concentrated at the left end, x = 0. Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

While for typical unimodal distributions (with centrally located modes, inflexion points at both sides of the mode, and longer tails) (with Beta(α, β) such that α, β > 2) it is known that the sample mean (as an estimate of location) is not as robust as the sample median, the opposite is the case for uniform or "U-shaped" bimodal distributions (with Beta(α, β) such that α, β ≤ 1), with the modes located at the ends of the distribution. As Mosteller and Tukey remark ([10] p. 207) "the average of the two extreme observations uses all the sample information. This illustrates how, for short-tailed distributions, the extreme observations should get more weight." By contrast, it follows that the median of "U-shaped" bimodal distributions with modes at the edge of the distribution (with Beta(α, β) such that α, β ≤ 1) is not robust, as the sample median drops the extreme sample observations from consideration. A practical application of this occurs for example for random walks, since the probability for the time of the last visit to the origin in a random walk is distributed as the arcsine distribution Beta(1/2, 1/2):[5][11] the mean of a number of realizations of a random walk is a much more robust estimator than the median (which is an inappropriate sample measure estimate in this case).
Geometric mean
_for_Beta_Distribution_versus_alpha_and_beta_from_0_to_2_-_J._Rodal.jpg.webp)
%252C_Yellow%253DG(1-X)%252C_smaller_values_alpha_and_beta_in_front_-_J._Rodal.jpg.webp)
%252C_Yellow%253DG(1-X)%252C_larger_values_alpha_and_beta_in_front_-_J._Rodal.jpg.webp)
The logarithm of the geometric mean GX of a distribution with random variable X is the arithmetic mean of ln(X), or, equivalently, its expected value:
![\ln G_X = \operatorname{E}[\ln X]](../I/64b67cb73b90bc0e09ba41003b44f84b6e1d3feb.svg)
For a beta distribution, the expected value integral gives:
![{\displaystyle {\begin{aligned}\operatorname {E} [\ln X]&=\int _{0}^{1}\ln x\,f(x;\alpha ,\beta )\,dx\\[4pt]&=\int _{0}^{1}\ln x\,{\frac {x^{\alpha -1}(1-x)^{\beta -1}}{\mathrm {B} (\alpha ,\beta )}}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}\,\int _{0}^{1}{\frac {\partial x^{\alpha -1}(1-x)^{\beta -1}}{\partial \alpha }}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}{\frac {\partial }{\partial \alpha }}\int _{0}^{1}x^{\alpha -1}(1-x)^{\beta -1}\,dx\\[4pt]&={\frac {1}{\mathrm {B} (\alpha ,\beta )}}{\frac {\partial \mathrm {B} (\alpha ,\beta )}{\partial \alpha }}\\[4pt]&={\frac {\partial \ln \mathrm {B} (\alpha ,\beta )}{\partial \alpha }}\\[4pt]&={\frac {\partial \ln \Gamma (\alpha )}{\partial \alpha }}-{\frac {\partial \ln \Gamma (\alpha +\beta )}{\partial \alpha }}\\[4pt]&=\psi (\alpha )-\psi (\alpha +\beta )\end{aligned}}}](../I/cd9db519e08e3c72cd6f9e2f0c90a7c57bdba035.svg)
where ψ is the digamma function.
Therefore, the geometric mean of a beta distribution with shape parameters α and β is the exponential of the digamma functions of α and β as follows:
![G_X =e^{\operatorname{E}[\ln X]}= e^{\psi(\alpha) - \psi(\alpha + \beta)}](../I/c93ffa7f0155fa3816fcb151c3eb677700aabca2.svg)
While for a beta distribution with equal shape parameters α = β, it follows that skewness = 0 and mode = mean = median = 1/2, the geometric mean is less than 1/2: 0 < GX < 1/2. The reason for this is that the logarithmic transformation strongly weights the values of X close to zero, as ln(X) strongly tends towards negative infinity as X approaches zero, while ln(X) flattens towards zero as X → 1.
Along a line α = β, the following limits apply:

Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

The accompanying plot shows the difference between the mean and the geometric mean for shape parameters α and β from zero to 2. Besides the fact that the difference between them approaches zero as α and β approach infinity and that the difference becomes large for values of α and β approaching zero, one can observe an evident asymmetry of the geometric mean with respect to the shape parameters α and β. The difference between the geometric mean and the mean is larger for small values of α in relation to β than when exchanging the magnitudes of β and α.
N. L.Johnson and S. Kotz[1] suggest the logarithmic approximation to the digamma function ψ(α) ≈ ln(α − 1/2) which results in the following approximation to the geometric mean:

Numerical values for the relative error in this approximation follow: [(α = β = 1): 9.39%]; [(α = β = 2): 1.29%]; [(α = 2, β = 3): 1.51%]; [(α = 3, β = 2): 0.44%]; [(α = β = 3): 0.51%]; [(α = β = 4): 0.26%]; [(α = 3, β = 4): 0.55%]; [(α = 4, β = 3): 0.24%].
Similarly, one can calculate the value of shape parameters required for the geometric mean to equal 1/2. Given the value of the parameter β, what would be the value of the other parameter, α, required for the geometric mean to equal 1/2?. The answer is that (for β > 1), the value of α required tends towards β + 1/2 as β → ∞. For example, all these couples have the same geometric mean of 1/2: [β = 1, α = 1.4427], [β = 2, α = 2.46958], [β = 3, α = 3.47943], [β = 4, α = 4.48449], [β = 5, α = 5.48756], [β = 10, α = 10.4938], [β = 100, α = 100.499].
The fundamental property of the geometric mean, which can be proven to be false for any other mean, is

This makes the geometric mean the only correct mean when averaging normalized results, that is results that are presented as ratios to reference values.[12] This is relevant because the beta distribution is a suitable model for the random behavior of percentages and it is particularly suitable to the statistical modelling of proportions. The geometric mean plays a central role in maximum likelihood estimation, see section "Parameter estimation, maximum likelihood." Actually, when performing maximum likelihood estimation, besides the geometric mean GX based on the random variable X, also another geometric mean appears naturally: the geometric mean based on the linear transformation ––(1 − X), the mirror-image of X, denoted by G(1−X):
![G_{(1-X)} = e^{\operatorname{E}[\ln(1-X)] } = e^{\psi(\beta) - \psi(\alpha + \beta)}](../I/b8013e6a62bd5140a4e7919686761225dd54847e.svg)
Along a line α = β, the following limits apply:

Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

It has the following approximate value:

Although both GX and G(1−X) are asymmetric, in the case that both shape parameters are equal α = β, the geometric means are equal: GX = G(1−X). This equality follows from the following symmetry displayed between both geometric means:

Harmonic mean
%252C_Yellow%253DH(1-X)%252C_smaller_values_alpha_and_beta_in_front_-_J._Rodal.jpg.webp)
%252C_Yellow%253DH(1-X)%252C_larger_values_alpha_and_beta_in_front_-_J._Rodal.jpg.webp)
The inverse of the harmonic mean (HX) of a distribution with random variable X is the arithmetic mean of 1/X, or, equivalently, its expected value. Therefore, the harmonic mean (HX) of a beta distribution with shape parameters α and β is:
![\begin{align}
H_X &= \frac{1}{\operatorname{E}\left[\frac{1}{X}\right]} \\
&=\frac{1}{\int_0^1 \frac{f(x;\alpha,\beta)}{x}\,dx} \\
&=\frac{1}{\int_0^1 \frac{x^{\alpha-1}(1-x)^{\beta-1}}{x \Beta(\alpha,\beta)}\,dx} \\
&= \frac{\alpha - 1}{\alpha + \beta - 1}\text{ if } \alpha > 1 \text{ and } \beta > 0 \\
\end{align}](../I/ed7d99dd7493b9c085cd5d407861730e2a2abf6c.svg)
The harmonic mean (HX) of a Beta distribution with α < 1 is undefined, because its defining expression is not bounded in [0, 1] for shape parameter α less than unity.
Letting α = β in the above expression one obtains

showing that for α = β the harmonic mean ranges from 0, for α = β = 1, to 1/2, for α = β → ∞.
Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

The harmonic mean plays a role in maximum likelihood estimation for the four parameter case, in addition to the geometric mean. Actually, when performing maximum likelihood estimation for the four parameter case, besides the harmonic mean HX based on the random variable X, also another harmonic mean appears naturally: the harmonic mean based on the linear transformation (1 − X), the mirror-image of X, denoted by H1 − X:
![{\displaystyle H_{1-X}={\frac {1}{\operatorname {E} \left[{\frac {1}{1-X}}\right]}}={\frac {\beta -1}{\alpha +\beta -1}}{\text{ if }}\beta >1,{\text{ and }}\alpha >0.}](../I/48f4fd69f20c4259cb8a50e754df8dfed5a1ddca.svg)
The harmonic mean (H(1 − X)) of a Beta distribution with β < 1 is undefined, because its defining expression is not bounded in [0, 1] for shape parameter β less than unity.
Letting α = β in the above expression one obtains

showing that for α = β the harmonic mean ranges from 0, for α = β = 1, to 1/2, for α = β → ∞.
Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

Although both HX and H1−X are asymmetric, in the case that both shape parameters are equal α = β, the harmonic means are equal: HX = H1−X. This equality follows from the following symmetry displayed between both harmonic means:

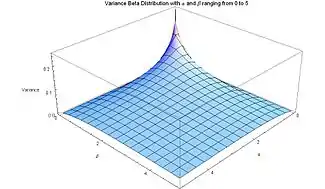
Variance
The variance (the second moment centered on the mean) of a Beta distribution random variable X with parameters α and β is:[1][13]
![\operatorname{var}(X) = \operatorname{E}[(X - \mu)^2] = \frac{\alpha \beta}{(\alpha + \beta)^2(\alpha + \beta + 1)}](../I/d96555f71897dc80e2f31ec71b3cbfbcf39950bc.svg)
Letting α = β in the above expression one obtains

showing that for α = β the variance decreases monotonically as α = β increases. Setting α = β = 0 in this expression, one finds the maximum variance var(X) = 1/4[1] which only occurs approaching the limit, at α = β = 0.
The beta distribution may also be parametrized in terms of its mean μ (0 < μ < 1) and sample size ν = α + β (ν > 0) (see subsection Mean and sample size):

Using this parametrization, one can express the variance in terms of the mean μ and the sample size ν as follows:

Since ν = α + β > 0, it follows that var(X) < μ(1 − μ).
For a symmetric distribution, the mean is at the middle of the distribution, μ = 1/2, and therefore:

Also, the following limits (with only the noted variable approaching the limit) can be obtained from the above expressions:

Geometric variance and covariance


The logarithm of the geometric variance, ln(varGX), of a distribution with random variable X is the second moment of the logarithm of X centered on the geometric mean of X, ln(GX):
![{\displaystyle {\begin{aligned}\ln \operatorname {var} _{GX}&=\operatorname {E} \left[(\ln X-\ln G_{X})^{2}\right]\\&=\operatorname {E} [(\ln X-\operatorname {E} \left[\ln X])^{2}\right]\\&=\operatorname {E} \left[(\ln X)^{2}\right]-(\operatorname {E} [\ln X])^{2}\\&=\operatorname {var} [\ln X]\end{aligned}}}](../I/5737429860855b238c6ac72ae064e4bb6d8cb772.svg)
and therefore, the geometric variance is:
![{\displaystyle \operatorname {var} _{GX}=e^{\operatorname {var} [\ln X]}}](../I/524cf664ccfd5eb381fd1987926209f1c401a200.svg)
In the Fisher information matrix, and the curvature of the log likelihood function, the logarithm of the geometric variance of the reflected variable 1 − X and the logarithm of the geometric covariance between X and 1 − X appear:
![{\displaystyle {\begin{aligned}\ln \operatorname {var_{G(1-X)}} &=\operatorname {E} [(\ln(1-X)-\ln G_{1-X})^{2}]\\&=\operatorname {E} [(\ln(1-X)-\operatorname {E} [\ln(1-X)])^{2}]\\&=\operatorname {E} [(\ln(1-X))^{2}]-(\operatorname {E} [\ln(1-X)])^{2}\\&=\operatorname {var} [\ln(1-X)]\\&\\\operatorname {var_{G(1-X)}} &=e^{\operatorname {var} [\ln(1-X)]}\\&\\\ln \operatorname {cov_{G{X,1-X}}} &=\operatorname {E} [(\ln X-\ln G_{X})(\ln(1-X)-\ln G_{1-X})]\\&=\operatorname {E} [(\ln X-\operatorname {E} [\ln X])(\ln(1-X)-\operatorname {E} [\ln(1-X)])]\\&=\operatorname {E} \left[\ln X\ln(1-X)\right]-\operatorname {E} [\ln X]\operatorname {E} [\ln(1-X)]\\&=\operatorname {cov} [\ln X,\ln(1-X)]\\&\\\operatorname {cov} _{G{X,(1-X)}}&=e^{\operatorname {cov} [\ln X,\ln(1-X)]}\end{aligned}}}](../I/9951a17fba87115b493918bfd9271c8e2193d0a8.svg)
For a beta distribution, higher order logarithmic moments can be derived by using the representation of a beta distribution as a proportion of two Gamma distributions and differentiating through the integral. They can be expressed in terms of higher order poly-gamma functions. See the section § Moments of logarithmically transformed random variables. The variance of the logarithmic variables and covariance of ln X and ln(1−X) are:
![\operatorname{var}[\ln X]= \psi_1(\alpha) - \psi_1(\alpha + \beta)](../I/e396e8700267735eb741f73e8906445579c43bc6.svg)
![\operatorname{var}[\ln (1-X)] = \psi_1(\beta) - \psi_1(\alpha + \beta)](../I/70eefadef46c7d56cc13c8221aa3df1d71596b7f.svg)
![\operatorname{cov}[\ln X, \ln(1-X)] = -\psi_1(\alpha+\beta)](../I/e7a515ada0b9d62c5a3a7b35662b03256d66e3b9.svg)
where the trigamma function, denoted ψ1(α), is the second of the polygamma functions, and is defined as the derivative of the digamma function:

Therefore,
![{\displaystyle \ln \operatorname {var} _{GX}=\operatorname {var} [\ln X]=\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta )}](../I/194b00552edda5d8d026a24872cdb27b604516c9.svg)
![{\displaystyle \ln \operatorname {var} _{G(1-X)}=\operatorname {var} [\ln(1-X)]=\psi _{1}(\beta )-\psi _{1}(\alpha +\beta )}](../I/96dd82553307c025c84da68a3c373aad7467abd2.svg)
![{\displaystyle \ln \operatorname {cov} _{GX,1-X}=\operatorname {cov} [\ln X,\ln(1-X)]=-\psi _{1}(\alpha +\beta )}](../I/40a793c0271e457f671edb0668edc15bbae8740f.svg)
The accompanying plots show the log geometric variances and log geometric covariance versus the shape parameters α and β. The plots show that the log geometric variances and log geometric covariance are close to zero for shape parameters α and β greater than 2, and that the log geometric variances rapidly rise in value for shape parameter values α and β less than unity. The log geometric variances are positive for all values of the shape parameters. The log geometric covariance is negative for all values of the shape parameters, and it reaches large negative values for α and β less than unity.
Following are the limits with one parameter finite (non-zero) and the other approaching these limits:

Limits with two parameters varying:

Although both ln(varGX) and ln(varG(1 − X)) are asymmetric, when the shape parameters are equal, α = β, one has: ln(varGX) = ln(varG(1−X)). This equality follows from the following symmetry displayed between both log geometric variances:

The log geometric covariance is symmetric:

Mean absolute deviation around the mean

The mean absolute deviation around the mean for the beta distribution with shape parameters α and β is:[8]
![{\displaystyle \operatorname {E} [|X-E[X]|]={\frac {2\alpha ^{\alpha }\beta ^{\beta }}{\mathrm {B} (\alpha ,\beta )(\alpha +\beta )^{\alpha +\beta +1}}}}](../I/6d1c6330a91df22b40cedc7903dbc70120d66cf9.svg)
The mean absolute deviation around the mean is a more robust estimator of statistical dispersion than the standard deviation for beta distributions with tails and inflection points at each side of the mode, Beta(α, β) distributions with α,β > 2, as it depends on the linear (absolute) deviations rather than the square deviations from the mean. Therefore, the effect of very large deviations from the mean are not as overly weighted.
Using Stirling's approximation to the Gamma function, N.L.Johnson and S.Kotz[1] derived the following approximation for values of the shape parameters greater than unity (the relative error for this approximation is only −3.5% for α = β = 1, and it decreases to zero as α → ∞, β → ∞):
![\begin{align}
\frac{\text{mean abs. dev. from mean}}{\text{standard deviation}} &=\frac{\operatorname{E}[|X - E[X]|]}{\sqrt{\operatorname{var}(X)}}\\
&\approx \sqrt{\frac{2}{\pi}} \left(1+\frac{7}{12 (\alpha+\beta)}{}-\frac{1}{12 \alpha}-\frac{1}{12 \beta} \right), \text{ if } \alpha, \beta > 1.
\end{align}](../I/c196a5a2eb110b71471a3dc019241c6cb8c3f927.svg)
At the limit α → ∞, β → ∞, the ratio of the mean absolute deviation to the standard deviation (for the beta distribution) becomes equal to the ratio of the same measures for the normal distribution: . For α = β = 1 this ratio equals , so that from α = β = 1 to α, β → ∞ the ratio decreases by 8.5%. For α = β = 0 the standard deviation is exactly equal to the mean absolute deviation around the mean. Therefore, this ratio decreases by 15% from α = β = 0 to α = β = 1, and by 25% from α = β = 0 to α, β → ∞ . However, for skewed beta distributions such that α → 0 or β → 0, the ratio of the standard deviation to the mean absolute deviation approaches infinity (although each of them, individually, approaches zero) because the mean absolute deviation approaches zero faster than the standard deviation.


Using the parametrization in terms of mean μ and sample size ν = α + β > 0:
- α = μν, β = (1−μ)ν
one can express the mean absolute deviation around the mean in terms of the mean μ and the sample size ν as follows:
![\operatorname{E}[| X - E[X]|] = \frac{2 \mu^{\mu\nu} (1-\mu)^{(1-\mu)\nu}}{\nu \Beta(\mu \nu,(1-\mu)\nu)}](../I/027efecf8aaefea8c805194e47a1374ffcb63cb8.svg)
For a symmetric distribution, the mean is at the middle of the distribution, μ = 1/2, and therefore:
![{\displaystyle {\begin{aligned}\operatorname {E} [|X-E[X]|]={\frac {2^{1-\nu }}{\nu \mathrm {B} ({\tfrac {\nu }{2}},{\tfrac {\nu }{2}})}}&={\frac {2^{1-\nu }\Gamma (\nu )}{\nu (\Gamma ({\tfrac {\nu }{2}}))^{2}}}\\\lim _{\nu \to 0}\left(\lim _{\mu \to {\frac {1}{2}}}\operatorname {E} [|X-E[X]|]\right)&={\tfrac {1}{2}}\\\lim _{\nu \to \infty }\left(\lim _{\mu \to {\frac {1}{2}}}\operatorname {E} [|X-E[X]|]\right)&=0\end{aligned}}}](../I/87aa0eff7a4da0f5abe2d211e2b7dda8c8fff801.svg)
Also, the following limits (with only the noted variable approaching the limit) can be obtained from the above expressions:
![{\displaystyle {\begin{aligned}\lim _{\beta \to 0}\operatorname {E} [|X-E[X]|]&=\lim _{\alpha \to 0}\operatorname {E} [|X-E[X]|]=0\\\lim _{\beta \to \infty }\operatorname {E} [|X-E[X]|]&=\lim _{\alpha \to \infty }\operatorname {E} [|X-E[X]|]=0\\\lim _{\mu \to 0}\operatorname {E} [|X-E[X]|]&=\lim _{\mu \to 1}\operatorname {E} [|X-E[X]|]=0\\\lim _{\nu \to 0}\operatorname {E} [|X-E[X]|]&={\sqrt {\mu (1-\mu )}}\\\lim _{\nu \to \infty }\operatorname {E} [|X-E[X]|]&=0\end{aligned}}}](../I/87c43b4a05f8ea3acf3f15b0a16f6ee07811ac6b.svg)
Mean absolute difference
The mean absolute difference for the Beta distribution is:

The Gini coefficient for the Beta distribution is half of the relative mean absolute difference:

Skewness
The skewness (the third moment centered on the mean, normalized by the 3/2 power of the variance) of the beta distribution is[1]
![\gamma_1 =\frac{\operatorname{E}[(X - \mu)^3]}{(\operatorname{var}(X))^{3/2}} = \frac{2(\beta - \alpha)\sqrt{\alpha + \beta + 1}}{(\alpha + \beta + 2) \sqrt{\alpha \beta}} .](../I/e2334c6fa1e6326760870b716521460bba115a92.svg)
Letting α = β in the above expression one obtains γ1 = 0, showing once again that for α = β the distribution is symmetric and hence the skewness is zero. Positive skew (right-tailed) for α < β, negative skew (left-tailed) for α > β.
Using the parametrization in terms of mean μ and sample size ν = α + β:

one can express the skewness in terms of the mean μ and the sample size ν as follows:
![\gamma_1 =\frac{\operatorname{E}[(X - \mu)^3]}{(\operatorname{var}(X))^{3/2}} = \frac{2(1-2\mu)\sqrt{1+\nu}}{(2+\nu)\sqrt{\mu (1 - \mu)}}.](../I/d71042628a42bfedc972e01f8ba5c27f63c3fae4.svg)
The skewness can also be expressed just in terms of the variance var and the mean μ as follows:
![\gamma_1 =\frac{\operatorname{E}[(X - \mu)^3]}{(\operatorname{var}(X))^{3/2}} = \frac{2(1-2\mu)\sqrt{\text{ var }}}{ \mu(1-\mu) + \operatorname{var}}\text{ if } \operatorname{var} < \mu(1-\mu)](../I/1e30c818c1af07028336494d35562333ffd903f1.svg)
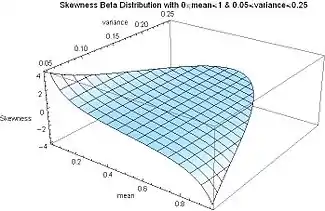
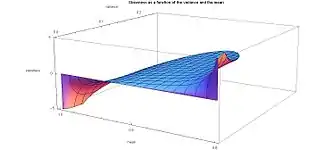
The accompanying plot of skewness as a function of variance and mean shows that maximum variance (1/4) is coupled with zero skewness and the symmetry condition (μ = 1/2), and that maximum skewness (positive or negative infinity) occurs when the mean is located at one end or the other, so that the "mass" of the probability distribution is concentrated at the ends (minimum variance).
The following expression for the square of the skewness, in terms of the sample size ν = α + β and the variance var, is useful for the method of moments estimation of four parameters:
![(\gamma_1)^2 =\frac{(\operatorname{E}[(X - \mu)^3])^2}{(\operatorname{var}(X))^3} = \frac{4}{(2+\nu)^2}\bigg(\frac{1}{\text{var}}-4(1+\nu)\bigg)](../I/d9d9343b5e45ab6ac483a8f0fb8efd1699e0158d.svg)
This expression correctly gives a skewness of zero for α = β, since in that case (see § Variance): .

For the symmetric case (α = β), skewness = 0 over the whole range, and the following limits apply:

For the asymmetric cases (α ≠ β) the following limits (with only the noted variable approaching the limit) can be obtained from the above expressions:



Kurtosis

The beta distribution has been applied in acoustic analysis to assess damage to gears, as the kurtosis of the beta distribution has been reported to be a good indicator of the condition of a gear.[14] Kurtosis has also been used to distinguish the seismic signal generated by a person's footsteps from other signals. As persons or other targets moving on the ground generate continuous signals in the form of seismic waves, one can separate different targets based on the seismic waves they generate. Kurtosis is sensitive to impulsive signals, so it's much more sensitive to the signal generated by human footsteps than other signals generated by vehicles, winds, noise, etc.[15] Unfortunately, the notation for kurtosis has not been standardized. Kenney and Keeping[16] use the symbol γ2 for the excess kurtosis, but Abramowitz and Stegun[17] use different terminology. To prevent confusion[18] between kurtosis (the fourth moment centered on the mean, normalized by the square of the variance) and excess kurtosis, when using symbols, they will be spelled out as follows:[8][19]
![\begin{align}
\text{excess kurtosis}
&=\text{kurtosis} - 3\\
&=\frac{\operatorname{E}[(X - \mu)^4]}{{(\operatorname{var}(X))^{2}}}-3\\
&=\frac{6[\alpha^3-\alpha^2(2\beta - 1) + \beta^2(\beta + 1) - 2\alpha\beta(\beta + 2)]}{\alpha \beta (\alpha + \beta + 2)(\alpha + \beta + 3)}\\
&=\frac{6[(\alpha - \beta)^2 (\alpha +\beta + 1) - \alpha \beta (\alpha + \beta + 2)]}
{\alpha \beta (\alpha + \beta + 2) (\alpha + \beta + 3)} .
\end{align}](../I/ed8320d4f38ba9260f8ad91c30238abc08306dc8.svg)
Letting α = β in the above expression one obtains
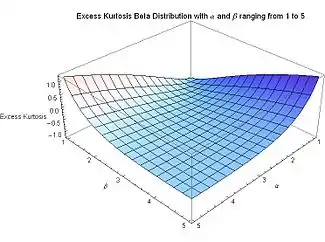
- .

Therefore, for symmetric beta distributions, the excess kurtosis is negative, increasing from a minimum value of −2 at the limit as {α = β} → 0, and approaching a maximum value of zero as {α = β} → ∞. The value of −2 is the minimum value of excess kurtosis that any distribution (not just beta distributions, but any distribution of any possible kind) can ever achieve. This minimum value is reached when all the probability density is entirely concentrated at each end x = 0 and x = 1, with nothing in between: a 2-point Bernoulli distribution with equal probability 1/2 at each end (a coin toss: see section below "Kurtosis bounded by the square of the skewness" for further discussion). The description of kurtosis as a measure of the "potential outliers" (or "potential rare, extreme values") of the probability distribution, is correct for all distributions including the beta distribution. When rare, extreme values can occur in the beta distribution, the higher its kurtosis; otherwise, the kurtosis is lower. For α ≠ β, skewed beta distributions, the excess kurtosis can reach unlimited positive values (particularly for α → 0 for finite β, or for β → 0 for finite α) because the side away from the mode will produce occasional extreme values. Minimum kurtosis takes place when the mass density is concentrated equally at each end (and therefore the mean is at the center), and there is no probability mass density in between the ends.
Using the parametrization in terms of mean μ and sample size ν = α + β:
one can express the excess kurtosis in terms of the mean μ and the sample size ν as follows:

The excess kurtosis can also be expressed in terms of just the following two parameters: the variance var, and the sample size ν as follows:

and, in terms of the variance var and the mean μ as follows:

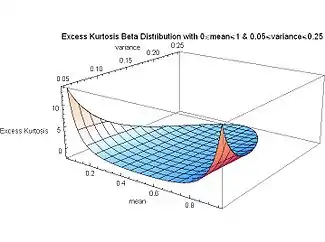
The plot of excess kurtosis as a function of the variance and the mean shows that the minimum value of the excess kurtosis (−2, which is the minimum possible value for excess kurtosis for any distribution) is intimately coupled with the maximum value of variance (1/4) and the symmetry condition: the mean occurring at the midpoint (μ = 1/2). This occurs for the symmetric case of α = β = 0, with zero skewness. At the limit, this is the 2 point Bernoulli distribution with equal probability 1/2 at each Dirac delta function end x = 0 and x = 1 and zero probability everywhere else. (A coin toss: one face of the coin being x = 0 and the other face being x = 1.) Variance is maximum because the distribution is bimodal with nothing in between the two modes (spikes) at each end. Excess kurtosis is minimum: the probability density "mass" is zero at the mean and it is concentrated at the two peaks at each end. Excess kurtosis reaches the minimum possible value (for any distribution) when the probability density function has two spikes at each end: it is bi-"peaky" with nothing in between them.
On the other hand, the plot shows that for extreme skewed cases, where the mean is located near one or the other end (μ = 0 or μ = 1), the variance is close to zero, and the excess kurtosis rapidly approaches infinity when the mean of the distribution approaches either end.
Alternatively, the excess kurtosis can also be expressed in terms of just the following two parameters: the square of the skewness, and the sample size ν as follows:

From this last expression, one can obtain the same limits published over a century ago by Karl Pearson[20] for the beta distribution (see section below titled "Kurtosis bounded by the square of the skewness"). Setting α + β= ν = 0 in the above expression, one obtains Pearson's lower boundary (values for the skewness and excess kurtosis below the boundary (excess kurtosis + 2 − skewness2 = 0) cannot occur for any distribution, and hence Karl Pearson appropriately called the region below this boundary the "impossible region"). The limit of α + β = ν → ∞ determines Pearson's upper boundary.

therefore:

Values of ν = α + β such that ν ranges from zero to infinity, 0 < ν < ∞, span the whole region of the beta distribution in the plane of excess kurtosis versus squared skewness.
For the symmetric case (α = β), the following limits apply:

For the unsymmetric cases (α ≠ β) the following limits (with only the noted variable approaching the limit) can be obtained from the above expressions:


Characteristic function
_Beta_Distr_alpha%253Dbeta_from_0_to_25_Back_-_J._Rodal.jpg.webp)
_Beta_Distr_alpha%253Dbeta_from_0_to_25_Front-_J._Rodal.jpg.webp)
_Beta_Distr_alpha_from_0_to_25_and_beta%253Dalpha%252B0.5_Back_-_J._Rodal.jpg.webp)
_Beta_Distrib._beta_from_0_to_25%252C_alpha%253Dbeta%252B0.5_Back_-_J._Rodal.jpg.webp)
_Beta_Distr._beta_from_0_to_25%252C_alpha%253Dbeta%252B0.5_Front_-_J._Rodal.jpg.webp)
The characteristic function is the Fourier transform of the probability density function. The characteristic function of the beta distribution is Kummer's confluent hypergeometric function (of the first kind):[1][17][21]
![{\displaystyle {\begin{aligned}\varphi _{X}(\alpha ;\beta ;t)&=\operatorname {E} \left[e^{itX}\right]\\&=\int _{0}^{1}e^{itx}f(x;\alpha ,\beta )dx\\&={}_{1}F_{1}(\alpha ;\alpha +\beta ;it)\!\\&=\sum _{n=0}^{\infty }{\frac {\alpha ^{(n)}(it)^{n}}{(\alpha +\beta )^{(n)}n!}}\\&=1+\sum _{k=1}^{\infty }\left(\prod _{r=0}^{k-1}{\frac {\alpha +r}{\alpha +\beta +r}}\right){\frac {(it)^{k}}{k!}}\end{aligned}}}](../I/d709a81766f7f8f900633cdfb4d67c1d1d137d6f.svg)
where

is the rising factorial, also called the "Pochhammer symbol". The value of the characteristic function for t = 0, is one:
- .

Also, the real and imaginary parts of the characteristic function enjoy the following symmetries with respect to the origin of variable t:
![{\displaystyle {\textrm {Re}}\left[{}_{1}F_{1}(\alpha ;\alpha +\beta ;it)\right]={\textrm {Re}}\left[{}_{1}F_{1}(\alpha ;\alpha +\beta ;-it)\right]}](../I/faa05f9f4cdefd2109ef732a8c7e6c84430e48f5.svg)
![{\displaystyle {\textrm {Im}}\left[{}_{1}F_{1}(\alpha ;\alpha +\beta ;it)\right]=-{\textrm {Im}}\left[{}_{1}F_{1}(\alpha ;\alpha +\beta ;-it)\right]}](../I/197280c554f4ede1d62a8bfa3c33a42451019853.svg)
The symmetric case α = β simplifies the characteristic function of the beta distribution to a Bessel function, since in the special case α + β = 2α the confluent hypergeometric function (of the first kind) reduces to a Bessel function (the modified Bessel function of the first kind ) using Kummer's second transformation as follows:


In the accompanying plots, the real part (Re) of the characteristic function of the beta distribution is displayed for symmetric (α = β) and skewed (α ≠ β) cases.
Moment generating function
It also follows[1][8] that the moment generating function is
![{\displaystyle {\begin{aligned}M_{X}(\alpha ;\beta ;t)&=\operatorname {E} \left[e^{tX}\right]\\[4pt]&=\int _{0}^{1}e^{tx}f(x;\alpha ,\beta )\,dx\\[4pt]&={}_{1}F_{1}(\alpha ;\alpha +\beta ;t)\\[4pt]&=\sum _{n=0}^{\infty }{\frac {\alpha ^{(n)}}{(\alpha +\beta )^{(n)}}}{\frac {t^{n}}{n!}}\\[4pt]&=1+\sum _{k=1}^{\infty }\left(\prod _{r=0}^{k-1}{\frac {\alpha +r}{\alpha +\beta +r}}\right){\frac {t^{k}}{k!}}\end{aligned}}}](../I/6f2ccc34699ad28c71419340168b2b51c683a93d.svg)
In particular MX(α; β; 0) = 1.
Higher moments
Using the moment generating function, the k-th raw moment is given by[1] the factor

multiplying the (exponential series) term in the series of the moment generating function

![\operatorname{E}[X^k]= \frac{\alpha^{(k)}}{(\alpha + \beta)^{(k)}} = \prod_{r=0}^{k-1} \frac{\alpha+r}{\alpha+\beta+r}](../I/e03c03f31b903a1bc73ea8b637e3134b110a85a2.svg)
where (x)(k) is a Pochhammer symbol representing rising factorial. It can also be written in a recursive form as
![\operatorname{E}[X^k] = \frac{\alpha + k - 1}{\alpha + \beta + k - 1}\operatorname{E}[X^{k - 1}].](../I/069cb373a905b1e8a5a82a0e3b028e88f63672e2.svg)
Since the moment generating function has a positive radius of convergence, the beta distribution is determined by its moments.[22]

Moments of linearly transformed, product and inverted random variables
One can also show the following expectations for a transformed random variable,[1] where the random variable X is Beta-distributed with parameters α and β: X ~ Beta(α, β). The expected value of the variable 1 − X is the mirror-symmetry of the expected value based on X:
![{\displaystyle {\begin{aligned}&\operatorname {E} [1-X]={\frac {\beta }{\alpha +\beta }}\\&\operatorname {E} [X(1-X)]=\operatorname {E} [(1-X)X]={\frac {\alpha \beta }{(\alpha +\beta )(\alpha +\beta +1)}}\end{aligned}}}](../I/9dde48c56a3ff737bc5941fb764065845fea3681.svg)
Due to the mirror-symmetry of the probability density function of the beta distribution, the variances based on variables X and 1 − X are identical, and the covariance on X(1 − X is the negative of the variance:
![\operatorname{var}[(1-X)]=\operatorname{var}[X] = -\operatorname{cov}[X,(1-X)]= \frac{\alpha \beta}{(\alpha + \beta)^2(\alpha + \beta + 1)}](../I/7273cc84a6c789724b985c34059fa75a62bce631.svg)
These are the expected values for inverted variables, (these are related to the harmonic means, see § Harmonic mean):
![\begin{align}
& \operatorname{E} \left [\frac{1}{X} \right ] = \frac{\alpha+\beta-1 }{\alpha -1 } \text{ if } \alpha > 1\\
& \operatorname{E}\left [\frac{1}{1-X} \right ] =\frac{\alpha+\beta-1 }{\beta-1 } \text{ if } \beta > 1
\end{align}](../I/c3f1f27c9014c9c38a30ae2ceea61a8d7856a275.svg)
The following transformation by dividing the variable X by its mirror-image X/(1 − X) results in the expected value of the "inverted beta distribution" or beta prime distribution (also known as beta distribution of the second kind or Pearson's Type VI):[1]
![\begin{align}
& \operatorname{E}\left[\frac{X}{1-X}\right] =\frac{\alpha}{\beta - 1 } \text{ if }\beta > 1\\
& \operatorname{E}\left[\frac{1-X}{X}\right] =\frac{\beta}{\alpha- 1 }\text{ if }\alpha > 1
\end{align}](../I/c40c2f689db6159d44deb7d06de6dedcadc4ca82.svg)
Variances of these transformed variables can be obtained by integration, as the expected values of the second moments centered on the corresponding variables:
![{\displaystyle \operatorname {var} \left[{\frac {1}{X}}\right]=\operatorname {E} \left[\left({\frac {1}{X}}-\operatorname {E} \left[{\frac {1}{X}}\right]\right)^{2}\right]=}](../I/563b0d2b40921c19ff1b1b6259f4297634f71062.svg)
![{\displaystyle \operatorname {var} \left[{\frac {1-X}{X}}\right]=\operatorname {E} \left[\left({\frac {1-X}{X}}-\operatorname {E} \left[{\frac {1-X}{X}}\right]\right)^{2}\right]={\frac {\beta (\alpha +\beta -1)}{(\alpha -2)(\alpha -1)^{2}}}{\text{ if }}\alpha >2}](../I/f4d1f81494368d71838507bdbbbbb967a75c0f90.svg)
The following variance of the variable X divided by its mirror-image (X/(1−X) results in the variance of the "inverted beta distribution" or beta prime distribution (also known as beta distribution of the second kind or Pearson's Type VI):[1]
![{\displaystyle \operatorname {var} \left[{\frac {1}{1-X}}\right]=\operatorname {E} \left[\left({\frac {1}{1-X}}-\operatorname {E} \left[{\frac {1}{1-X}}\right]\right)^{2}\right]=\operatorname {var} \left[{\frac {X}{1-X}}\right]=}](../I/9391bc56ac6980c6cf6e1a821fc1168a9cfcdc33.svg)
![{\displaystyle \operatorname {E} \left[\left({\frac {X}{1-X}}-\operatorname {E} \left[{\frac {X}{1-X}}\right]\right)^{2}\right]={\frac {\alpha (\alpha +\beta -1)}{(\beta -2)(\beta -1)^{2}}}{\text{ if }}\beta >2}](../I/ac107de23ff64a12fc3ca45910d7dba24821ea2b.svg)
The covariances are:
![\operatorname{cov}\left [\frac{1}{X},\frac{1}{1-X} \right ] = \operatorname{cov}\left[\frac{1-X}{X},\frac{X}{1-X} \right] =\operatorname{cov}\left[\frac{1}{X},\frac{X}{1-X}\right ] = \operatorname{cov}\left[\frac{1-X}{X},\frac{1}{1-X} \right] =\frac{\alpha+\beta-1}{(\alpha-1)(\beta-1) } \text{ if } \alpha, \beta > 1](../I/fa2342c3fe24a7ed5b840fd9583c055aa5791486.svg)
These expectations and variances appear in the four-parameter Fisher information matrix (§ Fisher information.)
Moments of logarithmically transformed random variables
Expected values for logarithmic transformations (useful for maximum likelihood estimates, see § Parameter estimation, Maximum likelihood) are discussed in this section. The following logarithmic linear transformations are related to the geometric means GX and G(1−X) (see § Geometric Mean):
![\begin{align}
\operatorname{E}[\ln(X)] &= \psi(\alpha) - \psi(\alpha + \beta)= - \operatorname{E}\left[\ln \left (\frac{1}{X} \right )\right],\\
\operatorname{E}[\ln(1-X)] &=\psi(\beta) - \psi(\alpha + \beta)= - \operatorname{E} \left[\ln \left (\frac{1}{1-X} \right )\right].
\end{align}](../I/6125bcdc7551c82f7451b444b941c97b83abdf20.svg)
Where the digamma function ψ(α) is defined as the logarithmic derivative of the gamma function:[17]

Logit transformations are interesting,[23] as they usually transform various shapes (including J-shapes) into (usually skewed) bell-shaped densities over the logit variable, and they may remove the end singularities over the original variable:
![\begin{align}
\operatorname{E}\left[\ln \left (\frac{X}{1-X} \right ) \right] &=\psi(\alpha) - \psi(\beta)= \operatorname{E}[\ln(X)] +\operatorname{E} \left[\ln \left (\frac{1}{1-X} \right) \right],\\
\operatorname{E}\left [\ln \left (\frac{1-X}{X} \right ) \right ] &=\psi(\beta) - \psi(\alpha)= - \operatorname{E} \left[\ln \left (\frac{X}{1-X} \right) \right] .
\end{align}](../I/519d77a6f894b5ebc9240b813a675477194f8858.svg)
Johnson[24] considered the distribution of the logit - transformed variable ln(X/1−X), including its moment generating function and approximations for large values of the shape parameters. This transformation extends the finite support [0, 1] based on the original variable X to infinite support in both directions of the real line (−∞, +∞).
Higher order logarithmic moments can be derived by using the representation of a beta distribution as a proportion of two Gamma distributions and differentiating through the integral. They can be expressed in terms of higher order poly-gamma functions as follows:
![\begin{align}
\operatorname{E} \left [\ln^2(X) \right ] &= (\psi(\alpha) - \psi(\alpha + \beta))^2+\psi_1(\alpha)-\psi_1(\alpha+\beta), \\
\operatorname{E} \left [\ln^2(1-X) \right ] &= (\psi(\beta) - \psi(\alpha + \beta))^2+\psi_1(\beta)-\psi_1(\alpha+\beta), \\
\operatorname{E} \left [\ln (X)\ln(1-X) \right ] &=(\psi(\alpha) - \psi(\alpha + \beta))(\psi(\beta) - \psi(\alpha + \beta)) -\psi_1(\alpha+\beta).
\end{align}](../I/b42eb1276e349df39df3051df11e0e16afe88e2e.svg)
therefore the variance of the logarithmic variables and covariance of ln(X) and ln(1−X) are:
![{\displaystyle {\begin{aligned}\operatorname {cov} [\ln(X),\ln(1-X)]&=\operatorname {E} \left[\ln(X)\ln(1-X)\right]-\operatorname {E} [\ln(X)]\operatorname {E} [\ln(1-X)]=-\psi _{1}(\alpha +\beta )\\&\\\operatorname {var} [\ln X]&=\operatorname {E} [\ln ^{2}(X)]-(\operatorname {E} [\ln(X)])^{2}\\&=\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta )\\&=\psi _{1}(\alpha )+\operatorname {cov} [\ln(X),\ln(1-X)]\\&\\\operatorname {var} [\ln(1-X)]&=\operatorname {E} [\ln ^{2}(1-X)]-(\operatorname {E} [\ln(1-X)])^{2}\\&=\psi _{1}(\beta )-\psi _{1}(\alpha +\beta )\\&=\psi _{1}(\beta )+\operatorname {cov} [\ln(X),\ln(1-X)]\end{aligned}}}](../I/e76df52180954247e1d1aa62646a20f7e3d68a36.svg)
where the trigamma function, denoted ψ1(α), is the second of the polygamma functions, and is defined as the derivative of the digamma function:
- .

The variances and covariance of the logarithmically transformed variables X and (1−X) are different, in general, because the logarithmic transformation destroys the mirror-symmetry of the original variables X and (1−X), as the logarithm approaches negative infinity for the variable approaching zero.
These logarithmic variances and covariance are the elements of the Fisher information matrix for the beta distribution. They are also a measure of the curvature of the log likelihood function (see section on Maximum likelihood estimation).
The variances of the log inverse variables are identical to the variances of the log variables:
![\begin{align}
\operatorname{var}\left[\ln \left (\frac{1}{X} \right ) \right] & =\operatorname{var}[\ln(X)] = \psi_1(\alpha) - \psi_1(\alpha + \beta), \\
\operatorname{var}\left[\ln \left (\frac{1}{1-X} \right ) \right] &=\operatorname{var}[\ln (1-X)] = \psi_1(\beta) - \psi_1(\alpha + \beta), \\
\operatorname{cov}\left[\ln \left (\frac{1}{X} \right), \ln \left (\frac{1}{1-X}\right ) \right] &=\operatorname{cov}[\ln(X),\ln(1-X)]= -\psi_1(\alpha + \beta).\end{align}](../I/d335167cf1713083b3fb1c4d0cfadb04c1d40d43.svg)
It also follows that the variances of the logit transformed variables are:
![\operatorname{var}\left[\ln \left (\frac{X}{1-X} \right )\right]=\operatorname{var}\left[\ln \left (\frac{1-X}{X} \right ) \right]=-\operatorname{cov}\left [\ln \left (\frac{X}{1-X} \right ), \ln \left (\frac{1-X}{X} \right ) \right]= \psi_1(\alpha) + \psi_1(\beta)](../I/bb1b29b7309248f8859985ea134ab777c8ad91dc.svg)
Quantities of information (entropy)
Given a beta distributed random variable, X ~ Beta(α, β), the differential entropy of X is (measured in nats),[25] the expected value of the negative of the logarithm of the probability density function:
![{\displaystyle {\begin{aligned}h(X)&=\operatorname {E} [-\ln(f(x;\alpha ,\beta ))]\\[4pt]&=\int _{0}^{1}-f(x;\alpha ,\beta )\ln(f(x;\alpha ,\beta ))\,dx\\[4pt]&=\ln(\mathrm {B} (\alpha ,\beta ))-(\alpha -1)\psi (\alpha )-(\beta -1)\psi (\beta )+(\alpha +\beta -2)\psi (\alpha +\beta )\end{aligned}}}](../I/0bc995dbbf41c91536ce4d0efaff554d8b0a77fe.svg)
where f(x; α, β) is the probability density function of the beta distribution:

The digamma function ψ appears in the formula for the differential entropy as a consequence of Euler's integral formula for the harmonic numbers which follows from the integral:

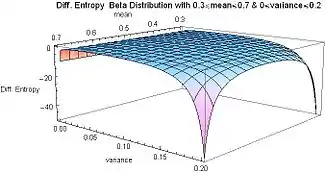
The differential entropy of the beta distribution is negative for all values of α and β greater than zero, except at α = β = 1 (for which values the beta distribution is the same as the uniform distribution), where the differential entropy reaches its maximum value of zero. It is to be expected that the maximum entropy should take place when the beta distribution becomes equal to the uniform distribution, since uncertainty is maximal when all possible events are equiprobable.
For α or β approaching zero, the differential entropy approaches its minimum value of negative infinity. For (either or both) α or β approaching zero, there is a maximum amount of order: all the probability density is concentrated at the ends, and there is zero probability density at points located between the ends. Similarly for (either or both) α or β approaching infinity, the differential entropy approaches its minimum value of negative infinity, and a maximum amount of order. If either α or β approaches infinity (and the other is finite) all the probability density is concentrated at an end, and the probability density is zero everywhere else. If both shape parameters are equal (the symmetric case), α = β, and they approach infinity simultaneously, the probability density becomes a spike (Dirac delta function) concentrated at the middle x = 1/2, and hence there is 100% probability at the middle x = 1/2 and zero probability everywhere else.
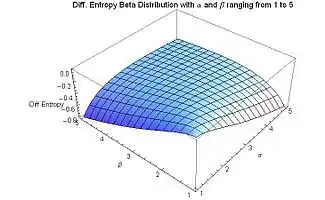
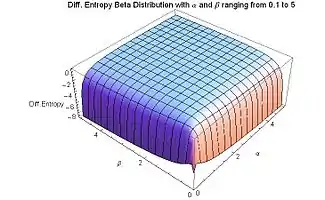
The (continuous case) differential entropy was introduced by Shannon in his original paper (where he named it the "entropy of a continuous distribution"), as the concluding part of the same paper where he defined the discrete entropy.[26] It is known since then that the differential entropy may differ from the infinitesimal limit of the discrete entropy by an infinite offset, therefore the differential entropy can be negative (as it is for the beta distribution). What really matters is the relative value of entropy.
Given two beta distributed random variables, X1 ~ Beta(α, β) and X2 ~ Beta(α′, β′), the cross-entropy is (measured in nats)[27]
![{\displaystyle {\begin{aligned}H(X_{1},X_{2})&=\int _{0}^{1}-f(x;\alpha ,\beta )\ln(f(x;\alpha ',\beta '))\,dx\\[4pt]&=\ln \left(\mathrm {B} (\alpha ',\beta ')\right)-(\alpha '-1)\psi (\alpha )-(\beta '-1)\psi (\beta )+(\alpha '+\beta '-2)\psi (\alpha +\beta ).\end{aligned}}}](../I/711e6ef61e56ccd8ba515b8db5013d1847939ec8.svg)
The cross entropy has been used as an error metric to measure the distance between two hypotheses.[28][29] Its absolute value is minimum when the two distributions are identical. It is the information measure most closely related to the log maximum likelihood [27](see section on "Parameter estimation. Maximum likelihood estimation")).
The relative entropy, or Kullback–Leibler divergence DKL(X1 || X2), is a measure of the inefficiency of assuming that the distribution is X2 ~ Beta(α′, β′) when the distribution is really X1 ~ Beta(α, β). It is defined as follows (measured in nats).
![{\displaystyle {\begin{aligned}D_{\mathrm {KL} }(X_{1}||X_{2})&=\int _{0}^{1}f(x;\alpha ,\beta )\ln \left({\frac {f(x;\alpha ,\beta )}{f(x;\alpha ',\beta ')}}\right)\,dx\\[4pt]&=\left(\int _{0}^{1}f(x;\alpha ,\beta )\ln(f(x;\alpha ,\beta ))\,dx\right)-\left(\int _{0}^{1}f(x;\alpha ,\beta )\ln(f(x;\alpha ',\beta '))\,dx\right)\\[4pt]&=-h(X_{1})+H(X_{1},X_{2})\\[4pt]&=\ln \left({\frac {\mathrm {B} (\alpha ',\beta ')}{\mathrm {B} (\alpha ,\beta )}}\right)+(\alpha -\alpha ')\psi (\alpha )+(\beta -\beta ')\psi (\beta )+(\alpha '-\alpha +\beta '-\beta )\psi (\alpha +\beta ).\end{aligned}}}](../I/5002efd169d75c8ab9a110dc2d4bfb0a23a76250.svg)
The relative entropy, or Kullback–Leibler divergence, is always non-negative. A few numerical examples follow:
- X1 ~ Beta(1, 1) and X2 ~ Beta(3, 3); DKL(X1 || X2) = 0.598803; DKL(X2 || X1) = 0.267864; h(X1) = 0; h(X2) = −0.267864
- X1 ~ Beta(3, 0.5) and X2 ~ Beta(0.5, 3); DKL(X1 || X2) = 7.21574; DKL(X2 || X1) = 7.21574; h(X1) = −1.10805; h(X2) = −1.10805.
The Kullback–Leibler divergence is not symmetric DKL(X1 || X2) ≠ DKL(X2 || X1) for the case in which the individual beta distributions Beta(1, 1) and Beta(3, 3) are symmetric, but have different entropies h(X1) ≠ h(X2). The value of the Kullback divergence depends on the direction traveled: whether going from a higher (differential) entropy to a lower (differential) entropy or the other way around. In the numerical example above, the Kullback divergence measures the inefficiency of assuming that the distribution is (bell-shaped) Beta(3, 3), rather than (uniform) Beta(1, 1). The "h" entropy of Beta(1, 1) is higher than the "h" entropy of Beta(3, 3) because the uniform distribution Beta(1, 1) has a maximum amount of disorder. The Kullback divergence is more than two times higher (0.598803 instead of 0.267864) when measured in the direction of decreasing entropy: the direction that assumes that the (uniform) Beta(1, 1) distribution is (bell-shaped) Beta(3, 3) rather than the other way around. In this restricted sense, the Kullback divergence is consistent with the second law of thermodynamics.
The Kullback–Leibler divergence is symmetric DKL(X1 || X2) = DKL(X2 || X1) for the skewed cases Beta(3, 0.5) and Beta(0.5, 3) that have equal differential entropy h(X1) = h(X2).
The symmetry condition:

follows from the above definitions and the mirror-symmetry f(x; α, β) = f(1−x; α, β) enjoyed by the beta distribution.
Mean, mode and median relationship
If 1 < α < β then mode ≤ median ≤ mean.[9] Expressing the mode (only for α, β > 1), and the mean in terms of α and β:

If 1 < β < α then the order of the inequalities are reversed. For α, β > 1 the absolute distance between the mean and the median is less than 5% of the distance between the maximum and minimum values of x. On the other hand, the absolute distance between the mean and the mode can reach 50% of the distance between the maximum and minimum values of x, for the (pathological) case of α = 1 and β = 1, for which values the beta distribution approaches the uniform distribution and the differential entropy approaches its maximum value, and hence maximum "disorder".
For example, for α = 1.0001 and β = 1.00000001:
- mode = 0.9999; PDF(mode) = 1.00010
- mean = 0.500025; PDF(mean) = 1.00003
- median = 0.500035; PDF(median) = 1.00003
- mean − mode = −0.499875
- mean − median = −9.65538 × 10−6
where PDF stands for the value of the probability density function.


Mean, geometric mean and harmonic mean relationship

It is known from the inequality of arithmetic and geometric means that the geometric mean is lower than the mean. Similarly, the harmonic mean is lower than the geometric mean. The accompanying plot shows that for α = β, both the mean and the median are exactly equal to 1/2, regardless of the value of α = β, and the mode is also equal to 1/2 for α = β > 1, however the geometric and harmonic means are lower than 1/2 and they only approach this value asymptotically as α = β → ∞.
Kurtosis bounded by the square of the skewness
_Parameter_estimates_vs._excess_Kurtosis_and_(squared)_Skewness_Beta_distribution_-_J._Rodal.png.webp)
As remarked by Feller,[5] in the Pearson system the beta probability density appears as type I (any difference between the beta distribution and Pearson's type I distribution is only superficial and it makes no difference for the following discussion regarding the relationship between kurtosis and skewness). Karl Pearson showed, in Plate 1 of his paper [20] published in 1916, a graph with the kurtosis as the vertical axis (ordinate) and the square of the skewness as the horizontal axis (abscissa), in which a number of distributions were displayed.[30] The region occupied by the beta distribution is bounded by the following two lines in the (skewness2,kurtosis) plane, or the (skewness2,excess kurtosis) plane:

or, equivalently,

At a time when there were no powerful digital computers, Karl Pearson accurately computed further boundaries,[31][20] for example, separating the "U-shaped" from the "J-shaped" distributions. The lower boundary line (excess kurtosis + 2 − skewness2 = 0) is produced by skewed "U-shaped" beta distributions with both values of shape parameters α and β close to zero. The upper boundary line (excess kurtosis − (3/2) skewness2 = 0) is produced by extremely skewed distributions with very large values of one of the parameters and very small values of the other parameter. Karl Pearson showed[20] that this upper boundary line (excess kurtosis − (3/2) skewness2 = 0) is also the intersection with Pearson's distribution III, which has unlimited support in one direction (towards positive infinity), and can be bell-shaped or J-shaped. His son, Egon Pearson, showed[30] that the region (in the kurtosis/squared-skewness plane) occupied by the beta distribution (equivalently, Pearson's distribution I) as it approaches this boundary (excess kurtosis − (3/2) skewness2 = 0) is shared with the noncentral chi-squared distribution. Karl Pearson[32] (Pearson 1895, pp. 357, 360, 373–376) also showed that the gamma distribution is a Pearson type III distribution. Hence this boundary line for Pearson's type III distribution is known as the gamma line. (This can be shown from the fact that the excess kurtosis of the gamma distribution is 6/k and the square of the skewness is 4/k, hence (excess kurtosis − (3/2) skewness2 = 0) is identically satisfied by the gamma distribution regardless of the value of the parameter "k"). Pearson later noted that the chi-squared distribution is a special case of Pearson's type III and also shares this boundary line (as it is apparent from the fact that for the chi-squared distribution the excess kurtosis is 12/k and the square of the skewness is 8/k, hence (excess kurtosis − (3/2) skewness2 = 0) is identically satisfied regardless of the value of the parameter "k"). This is to be expected, since the chi-squared distribution X ~ χ2(k) is a special case of the gamma distribution, with parametrization X ~ Γ(k/2, 1/2) where k is a positive integer that specifies the "number of degrees of freedom" of the chi-squared distribution.
An example of a beta distribution near the upper boundary (excess kurtosis − (3/2) skewness2 = 0) is given by α = 0.1, β = 1000, for which the ratio (excess kurtosis)/(skewness2) = 1.49835 approaches the upper limit of 1.5 from below. An example of a beta distribution near the lower boundary (excess kurtosis + 2 − skewness2 = 0) is given by α= 0.0001, β = 0.1, for which values the expression (excess kurtosis + 2)/(skewness2) = 1.01621 approaches the lower limit of 1 from above. In the infinitesimal limit for both α and β approaching zero symmetrically, the excess kurtosis reaches its minimum value at −2. This minimum value occurs at the point at which the lower boundary line intersects the vertical axis (ordinate). (However, in Pearson's original chart, the ordinate is kurtosis, instead of excess kurtosis, and it increases downwards rather than upwards).
Values for the skewness and excess kurtosis below the lower boundary (excess kurtosis + 2 − skewness2 = 0) cannot occur for any distribution, and hence Karl Pearson appropriately called the region below this boundary the "impossible region". The boundary for this "impossible region" is determined by (symmetric or skewed) bimodal "U"-shaped distributions for which the parameters α and β approach zero and hence all the probability density is concentrated at the ends: x = 0, 1 with practically nothing in between them. Since for α ≈ β ≈ 0 the probability density is concentrated at the two ends x = 0 and x = 1, this "impossible boundary" is determined by a Bernoulli distribution, where the two only possible outcomes occur with respective probabilities p and q = 1−p. For cases approaching this limit boundary with symmetry α = β, skewness ≈ 0, excess kurtosis ≈ −2 (this is the lowest excess kurtosis possible for any distribution), and the probabilities are p ≈ q ≈ 1/2. For cases approaching this limit boundary with skewness, excess kurtosis ≈ −2 + skewness2, and the probability density is concentrated more at one end than the other end (with practically nothing in between), with probabilities at the left end x = 0 and at the right end x = 1.


Symmetry
All statements are conditional on α, β > 0
- Probability density function reflection symmetry

- Cumulative distribution function reflection symmetry plus unitary translation

- Mode reflection symmetry plus unitary translation

- Median reflection symmetry plus unitary translation

- Mean reflection symmetry plus unitary translation

- Geometric Means each is individually asymmetric, the following symmetry applies between the geometric mean based on X and the geometric mean based on its reflection (1-X)

- Harmonic means each is individually asymmetric, the following symmetry applies between the harmonic mean based on X and the harmonic mean based on its reflection (1-X)
- .

- Variance symmetry

- Geometric variances each is individually asymmetric, the following symmetry applies between the log geometric variance based on X and the log geometric variance based on its reflection (1-X)

- Geometric covariance symmetry

- Mean absolute deviation around the mean symmetry
![\operatorname{E}[|X - E[X]| ] (\Beta(\alpha, \beta))=\operatorname{E}[| X - E[X]|] (\Beta(\beta, \alpha))](../I/83468b7365d9095b07e04bfbb5c9cff50c64ea2d.svg)
- Skewness skew-symmetry

- Excess kurtosis symmetry

- Characteristic function symmetry of Real part (with respect to the origin of variable "t")
![\text{Re} [{}_1F_1(\alpha; \alpha+\beta; it) ] = \text{Re} [ {}_1F_1(\alpha; \alpha+\beta; - it)]](../I/55bbddff6ec53eb39eccc603618459ba36e10ad2.svg)
- Characteristic function skew-symmetry of Imaginary part (with respect to the origin of variable "t")
![\text{Im} [{}_1F_1(\alpha; \alpha+\beta; it) ] = - \text{Im} [ {}_1F_1(\alpha; \alpha+\beta; - it) ]](../I/ebb682c9915a60ef8d982340de042127ab262a0f.svg)
- Characteristic function symmetry of Absolute value (with respect to the origin of variable "t")
![\text{Abs} [ {}_1F_1(\alpha; \alpha+\beta; it) ] = \text{Abs} [ {}_1F_1(\alpha; \alpha+\beta; - it) ]](../I/08c1c15ff4c63020b66d2404d439514d965946d0.svg)
- Differential entropy symmetry

- Relative Entropy (also called Kullback–Leibler divergence) symmetry

- Fisher information matrix symmetry

Inflection points
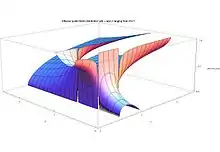
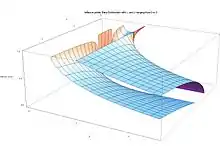
For certain values of the shape parameters α and β, the probability density function has inflection points, at which the curvature changes sign. The position of these inflection points can be useful as a measure of the dispersion or spread of the distribution.
Defining the following quantity:

Points of inflection occur,[1][7][8][19] depending on the value of the shape parameters α and β, as follows:
- (α > 2, β > 2) The distribution is bell-shaped (symmetric for α = β and skewed otherwise), with two inflection points, equidistant from the mode:

- (α = 2, β > 2) The distribution is unimodal, positively skewed, right-tailed, with one inflection point, located to the right of the mode:

- (α > 2, β = 2) The distribution is unimodal, negatively skewed, left-tailed, with one inflection point, located to the left of the mode:

- (1 < α < 2, β > 2, α+β>2) The distribution is unimodal, positively skewed, right-tailed, with one inflection point, located to the right of the mode:

- (0 < α < 1, 1 < β < 2) The distribution has a mode at the left end x = 0 and it is positively skewed, right-tailed. There is one inflection point, located to the right of the mode:

- (α > 2, 1 < β < 2) The distribution is unimodal negatively skewed, left-tailed, with one inflection point, located to the left of the mode:

- (1 < α < 2, 0 < β < 1) The distribution has a mode at the right end x=1 and it is negatively skewed, left-tailed. There is one inflection point, located to the left of the mode:

There are no inflection points in the remaining (symmetric and skewed) regions: U-shaped: (α, β < 1) upside-down-U-shaped: (1 < α < 2, 1 < β < 2), reverse-J-shaped (α < 1, β > 2) or J-shaped: (α > 2, β < 1)
The accompanying plots show the inflection point locations (shown vertically, ranging from 0 to 1) versus α and β (the horizontal axes ranging from 0 to 5). There are large cuts at surfaces intersecting the lines α = 1, β = 1, α = 2, and β = 2 because at these values the beta distribution change from 2 modes, to 1 mode to no mode.
Shapes
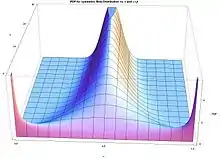

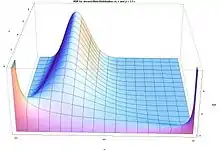


The beta density function can take a wide variety of different shapes depending on the values of the two parameters α and β. The ability of the beta distribution to take this great diversity of shapes (using only two parameters) is partly responsible for finding wide application for modeling actual measurements:
Symmetric (α = β)
- the density function is symmetric about 1/2 (blue & teal plots).
- median = mean = 1/2.
- skewness = 0.
- variance = 1/(4(2α + 1))
- α = β < 1
- U-shaped (blue plot).
- bimodal: left mode = 0, right mode =1, anti-mode = 1/2
- 1/12 < var(X) < 1/4[1]
- −2 < excess kurtosis(X) < −6/5
- α = β = 1/2 is the arcsine distribution
- var(X) = 1/8
- excess kurtosis(X) = −3/2
- CF = Rinc (t) [33]
- α = β → 0 is a 2-point Bernoulli distribution with equal probability 1/2 at each Dirac delta function end x = 0 and x = 1 and zero probability everywhere else. A coin toss: one face of the coin being x = 0 and the other face being x = 1.
- a lower value than this is impossible for any distribution to reach.
- The differential entropy approaches a minimum value of −∞
- α = β = 1
- the uniform [0, 1] distribution
- no mode
- var(X) = 1/12
- excess kurtosis(X) = −6/5
- The (negative anywhere else) differential entropy reaches its maximum value of zero
- CF = Sinc (t)
- α = β > 1
- symmetric unimodal
- mode = 1/2.
- 0 < var(X) < 1/12[1]
- −6/5 < excess kurtosis(X) < 0
- α = β = 3/2 is a semi-elliptic [0, 1] distribution, see: Wigner semicircle distribution[34]
- var(X) = 1/16.
- excess kurtosis(X) = −1
- CF = 2 Jinc (t)
- α = β = 2 is the parabolic [0, 1] distribution
- var(X) = 1/20
- excess kurtosis(X) = −6/7
- CF = 3 Tinc (t) [35]
- α = β > 2 is bell-shaped, with inflection points located to either side of the mode
- 0 < var(X) < 1/20
- −6/7 < excess kurtosis(X) < 0
- α = β → ∞ is a 1-point Degenerate distribution with a Dirac delta function spike at the midpoint x = 1/2 with probability 1, and zero probability everywhere else. There is 100% probability (absolute certainty) concentrated at the single point x = 1/2.
- The differential entropy approaches a minimum value of −∞




Skewed (α ≠ β)
The density function is skewed. An interchange of parameter values yields the mirror image (the reverse) of the initial curve, some more specific cases:
- α < 1, β < 1
- U-shaped
- Positive skew for α < β, negative skew for α > β.
- bimodal: left mode = 0, right mode = 1, anti-mode =
- 0 < median < 1.
- 0 < var(X) < 1/4
- α > 1, β > 1
- unimodal (magenta & cyan plots),
- Positive skew for α < β, negative skew for α > β.
- 0 < median < 1
- 0 < var(X) < 1/12
- α < 1, β ≥ 1
- reverse J-shaped with a right tail,
- positively skewed,
- strictly decreasing, convex
- mode = 0
- 0 < median < 1/2.
- (maximum variance occurs for , or α = Φ the golden ratio conjugate)
- α ≥ 1, β < 1
- J-shaped with a left tail,
- negatively skewed,
- strictly increasing, convex
- mode = 1
- 1/2 < median < 1
- (maximum variance occurs for , or β = Φ the golden ratio conjugate)
- α = 1, β > 1
- positively skewed,
- strictly decreasing (red plot),
- a reversed (mirror-image) power function [0,1] distribution
- mean = 1 / (β + 1)
- median = 1 - 1/21/β
- mode = 0
- α = 1, 1 < β < 2
- concave
- 1/18 < var(X) < 1/12.
- α = 1, β = 2
- a straight line with slope −2, the right-triangular distribution with right angle at the left end, at x = 0
- var(X) = 1/18
- α = 1, β > 2
- reverse J-shaped with a right tail,
- convex
- 0 < var(X) < 1/18
- α > 1, β = 1
- negatively skewed,
- strictly increasing (green plot),
- the power function [0, 1] distribution[8]
- mean = α / (α + 1)
- median = 1/21/α
- mode = 1
- 2 > α > 1, β = 1
- concave
- 1/18 < var(X) < 1/12
- α = 2, β = 1
- a straight line with slope +2, the right-triangular distribution with right angle at the right end, at x = 1
- var(X) = 1/18
- α > 2, β = 1
- J-shaped with a left tail, convex
- 0 < var(X) < 1/18











Related distributions
Transformations
- If X ~ Beta(α, β) then 1 − X ~ Beta(β, α) mirror-image symmetry
- If X ~ Beta(α, β) then . The beta prime distribution, also called "beta distribution of the second kind".
- If , then has a generalized logistic distribution, with density , where is the logistic sigmoid.
- If X ~ Beta(α, β) then .
- If X ~ Beta(n/2, m/2) then (assuming n > 0 and m > 0), the Fisher–Snedecor F distribution.
- If then min + X(max − min) ~ PERT(min, max, m, λ) where PERT denotes a PERT distribution used in PERT analysis, and m=most likely value.[36] Traditionally[37] λ = 4 in PERT analysis.
- If X ~ Beta(1, β) then X ~ Kumaraswamy distribution with parameters (1, β)
- If X ~ Beta(α, 1) then X ~ Kumaraswamy distribution with parameters (α, 1)
- If X ~ Beta(α, 1) then −ln(X) ~ Exponential(α)








Special and limiting cases
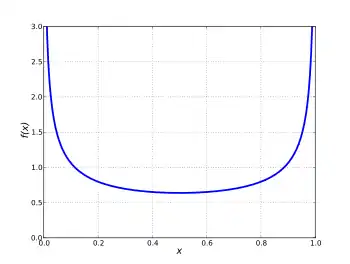
- Beta(1, 1) ~ U(0, 1) with density 1 on that interval.
- Beta(n, 1) ~ Maximum of n independent rvs. with U(0, 1), sometimes called a a standard power function distribution with density n xn-1 on that interval.
- Beta(1, n) ~ Minimum of n independent rvs. with U(0, 1) with density n (1-x)n-1 on that interval.
- If X ~ Beta(3/2, 3/2) and r > 0 then 2rX − r ~ Wigner semicircle distribution.
- Beta(1/2, 1/2) is equivalent to the arcsine distribution. This distribution is also Jeffreys prior probability for the Bernoulli and binomial distributions. The arcsine probability density is a distribution that appears in several random-walk fundamental theorems. In a fair coin toss random walk, the probability for the time of the last visit to the origin is distributed as an (U-shaped) arcsine distribution.[5][11] In a two-player fair-coin-toss game, a player is said to be in the lead if the random walk (that started at the origin) is above the origin. The most probable number of times that a given player will be in the lead, in a game of length 2N, is not N. On the contrary, N is the least likely number of times that the player will be in the lead. The most likely number of times in the lead is 0 or 2N (following the arcsine distribution).
- the exponential distribution.
- the gamma distribution.
- For large , the normal distribution. More precisely, if then converges in distribution to a normal distribution with mean 0 and variance as n increases.







Derived from other distributions
- The kth order statistic of a sample of size n from the uniform distribution is a beta random variable, U(k) ~ Beta(k, n+1−k).[38]
- If X ~ Gamma(α, θ) and Y ~ Gamma(β, θ) are independent, then .
- If and are independent, then .
- If X ~ U(0, 1) and α > 0 then X1/α ~ Beta(α, 1). The power function distribution.
- If , then for discrete values of n and k where and .[39]
- If X ~ Cauchy(0, 1) then









Combination with other distributions
- X ~ Beta(α, β) and Y ~ F(2β,2α) then for all x > 0.

Compounding with other distributions
- If p ~ Beta(α, β) and X ~ Bin(k, p) then X ~ beta-binomial distribution
- If p ~ Beta(α, β) and X ~ NB(r, p) then X ~ beta negative binomial distribution
Generalisations
- The generalization to multiple variables, i.e. a multivariate Beta distribution, is called a Dirichlet distribution. Univariate marginals of the Dirichlet distribution have a beta distribution. The beta distribution is conjugate to the binomial and Bernoulli distributions in exactly the same way as the Dirichlet distribution is conjugate to the multinomial distribution and categorical distribution.
- The Pearson type I distribution is identical to the beta distribution (except for arbitrary shifting and re-scaling that can also be accomplished with the four parameter parametrization of the beta distribution).
- The beta distribution is the special case of the noncentral beta distribution where : .
- The generalized beta distribution is a five-parameter distribution family which has the beta distribution as a special case.
- The matrix variate beta distribution is a distribution for positive-definite matrices.


Statistical inference
Two unknown parameters
Two unknown parameters ( of a beta distribution supported in the [0,1] interval) can be estimated, using the method of moments, with the first two moments (sample mean and sample variance) as follows. Let:


be the sample mean estimate and

be the sample variance estimate. The method-of-moments estimates of the parameters are
- if
- if




When the distribution is required over a known interval other than [0, 1] with random variable X, say [a, c] with random variable Y, then replace with and with in the above couple of equations for the shape parameters (see the "Alternative parametrizations, four parameters" section below).,[40] where:






Four unknown parameters
All four parameters ( of a beta distribution supported in the [a, c] interval -see section "Alternative parametrizations, Four parameters"-) can be estimated, using the method of moments developed by Karl Pearson, by equating sample and population values of the first four central moments (mean, variance, skewness and excess kurtosis).[1][41][42] The excess kurtosis was expressed in terms of the square of the skewness, and the sample size ν = α + β, (see previous section "Kurtosis") as follows:


One can use this equation to solve for the sample size ν= α + β in terms of the square of the skewness and the excess kurtosis as follows:[41]


This is the ratio (multiplied by a factor of 3) between the previously derived limit boundaries for the beta distribution in a space (as originally done by Karl Pearson[20]) defined with coordinates of the square of the skewness in one axis and the excess kurtosis in the other axis (see § Kurtosis bounded by the square of the skewness):
The case of zero skewness, can be immediately solved because for zero skewness, α = β and hence ν = 2α = 2β, therefore α = β = ν/2


(Excess kurtosis is negative for the beta distribution with zero skewness, ranging from -2 to 0, so that -and therefore the sample shape parameters- is positive, ranging from zero when the shape parameters approach zero and the excess kurtosis approaches -2, to infinity when the shape parameters approach infinity and the excess kurtosis approaches zero).

For non-zero sample skewness one needs to solve a system of two coupled equations. Since the skewness and the excess kurtosis are independent of the parameters , the parameters can be uniquely determined from the sample skewness and the sample excess kurtosis, by solving the coupled equations with two known variables (sample skewness and sample excess kurtosis) and two unknowns (the shape parameters):




resulting in the following solution:[41]


Where one should take the solutions as follows: for (negative) sample skewness < 0, and for (positive) sample skewness > 0.


The accompanying plot shows these two solutions as surfaces in a space with horizontal axes of (sample excess kurtosis) and (sample squared skewness) and the shape parameters as the vertical axis. The surfaces are constrained by the condition that the sample excess kurtosis must be bounded by the sample squared skewness as stipulated in the above equation. The two surfaces meet at the right edge defined by zero skewness. Along this right edge, both parameters are equal and the distribution is symmetric U-shaped for α = β < 1, uniform for α = β = 1, upside-down-U-shaped for 1 < α = β < 2 and bell-shaped for α = β > 2. The surfaces also meet at the front (lower) edge defined by "the impossible boundary" line (excess kurtosis + 2 - skewness2 = 0). Along this front (lower) boundary both shape parameters approach zero, and the probability density is concentrated more at one end than the other end (with practically nothing in between), with probabilities at the left end x = 0 and at the right end x = 1. The two surfaces become further apart towards the rear edge. At this rear edge the surface parameters are quite different from each other. As remarked, for example, by Bowman and Shenton,[43] sampling in the neighborhood of the line (sample excess kurtosis - (3/2)(sample skewness)2 = 0) (the just-J-shaped portion of the rear edge where blue meets beige), "is dangerously near to chaos", because at that line the denominator of the expression above for the estimate ν = α + β becomes zero and hence ν approaches infinity as that line is approached. Bowman and Shenton [43] write that "the higher moment parameters (kurtosis and skewness) are extremely fragile (near that line). However, the mean and standard deviation are fairly reliable." Therefore, the problem is for the case of four parameter estimation for very skewed distributions such that the excess kurtosis approaches (3/2) times the square of the skewness. This boundary line is produced by extremely skewed distributions with very large values of one of the parameters and very small values of the other parameter. See § Kurtosis bounded by the square of the skewness for a numerical example and further comments about this rear edge boundary line (sample excess kurtosis - (3/2)(sample skewness)2 = 0). As remarked by Karl Pearson himself [44] this issue may not be of much practical importance as this trouble arises only for very skewed J-shaped (or mirror-image J-shaped) distributions with very different values of shape parameters that are unlikely to occur much in practice). The usual skewed-bell-shape distributions that occur in practice do not have this parameter estimation problem.
The remaining two parameters can be determined using the sample mean and the sample variance using a variety of equations.[1][41] One alternative is to calculate the support interval range based on the sample variance and the sample kurtosis. For this purpose one can solve, in terms of the range , the equation expressing the excess kurtosis in terms of the sample variance, and the sample size ν (see § Kurtosis and § Alternative parametrizations, four parameters):


to obtain:

Another alternative is to calculate the support interval range based on the sample variance and the sample skewness.[41] For this purpose one can solve, in terms of the range , the equation expressing the squared skewness in terms of the sample variance, and the sample size ν (see section titled "Skewness" and "Alternative parametrizations, four parameters"):

to obtain:[41]

The remaining parameter can be determined from the sample mean and the previously obtained parameters: :


and finally, .

In the above formulas one may take, for example, as estimates of the sample moments:

The estimators G1 for sample skewness and G2 for sample kurtosis are used by DAP/SAS, PSPP/SPSS, and Excel. However, they are not used by BMDP and (according to [45]) they were not used by MINITAB in 1998. Actually, Joanes and Gill in their 1998 study[45] concluded that the skewness and kurtosis estimators used in BMDP and in MINITAB (at that time) had smaller variance and mean-squared error in normal samples, but the skewness and kurtosis estimators used in DAP/SAS, PSPP/SPSS, namely G1 and G2, had smaller mean-squared error in samples from a very skewed distribution. It is for this reason that we have spelled out "sample skewness", etc., in the above formulas, to make it explicit that the user should choose the best estimator according to the problem at hand, as the best estimator for skewness and kurtosis depends on the amount of skewness (as shown by Joanes and Gill[45]).
Two unknown parameters
_for_Beta_distribution_Maxima_at_alpha%253Dbeta%253D2_-_J._Rodal.png.webp)
_for_Beta_distribution_Maxima_at_alpha%253Dbeta%253D_0.25%252C0.5%252C1%252C2%252C4%252C6%252C8_-_J._Rodal.png.webp)
As is also the case for maximum likelihood estimates for the gamma distribution, the maximum likelihood estimates for the beta distribution do not have a general closed form solution for arbitrary values of the shape parameters. If X1, ..., XN are independent random variables each having a beta distribution, the joint log likelihood function for N iid observations is:

Finding the maximum with respect to a shape parameter involves taking the partial derivative with respect to the shape parameter and setting the expression equal to zero yielding the maximum likelihood estimator of the shape parameters:


where:


since the digamma function denoted ψ(α) is defined as the logarithmic derivative of the gamma function:[17]

To ensure that the values with zero tangent slope are indeed a maximum (instead of a saddle-point or a minimum) one has to also satisfy the condition that the curvature is negative. This amounts to satisfying that the second partial derivative with respect to the shape parameters is negative


using the previous equations, this is equivalent to:


where the trigamma function, denoted ψ1(α), is the second of the polygamma functions, and is defined as the derivative of the digamma function:

These conditions are equivalent to stating that the variances of the logarithmically transformed variables are positive, since:
![\operatorname{var}[\ln (X)] = \operatorname{E}[\ln^2 (X)] - (\operatorname{E}[\ln (X)])^2 = \psi_1(\alpha) - \psi_1(\alpha + \beta)](../I/d7737d681fea7490e27f8760c6bcc8fccb154904.svg)
![\operatorname{var}[\ln (1-X)] = \operatorname{E}[\ln^2 (1-X)] - (\operatorname{E}[\ln (1-X)])^2 = \psi_1(\beta) - \psi_1(\alpha + \beta)](../I/f84c3747955206cf2190c61bd7875a6cd739ac04.svg)
Therefore, the condition of negative curvature at a maximum is equivalent to the statements:
![\operatorname{var}[\ln (X)] > 0](../I/5fb5a5d0db057469fb9dad8df2902fe93e3f3b0d.svg)
![\operatorname{var}[\ln (1-X)] > 0](../I/c66a5aaa8362f578beb9b141b4108138b9d21e89.svg)
Alternatively, the condition of negative curvature at a maximum is also equivalent to stating that the following logarithmic derivatives of the geometric means GX and G(1−X) are positive, since:


While these slopes are indeed positive, the other slopes are negative:

The slopes of the mean and the median with respect to α and β display similar sign behavior.
From the condition that at a maximum, the partial derivative with respect to the shape parameter equals zero, we obtain the following system of coupled maximum likelihood estimate equations (for the average log-likelihoods) that needs to be inverted to obtain the (unknown) shape parameter estimates in terms of the (known) average of logarithms of the samples X1, ..., XN:[1]
![{\displaystyle {\begin{aligned}{\hat {\operatorname {E} }}[\ln(X)]&=\psi ({\hat {\alpha }})-\psi ({\hat {\alpha }}+{\hat {\beta }})={\frac {1}{N}}\sum _{i=1}^{N}\ln X_{i}=\ln {\hat {G}}_{X}\\{\hat {\operatorname {E} }}[\ln(1-X)]&=\psi ({\hat {\beta }})-\psi ({\hat {\alpha }}+{\hat {\beta }})={\frac {1}{N}}\sum _{i=1}^{N}\ln(1-X_{i})=\ln {\hat {G}}_{(1-X)}\end{aligned}}}](../I/0e43bfd770a92437c9b0bbef4c7c6ead3534eba3.svg)
where we recognize as the logarithm of the sample geometric mean and as the logarithm of the sample geometric mean based on (1 − X), the mirror-image of X. For , it follows that .





These coupled equations containing digamma functions of the shape parameter estimates must be solved by numerical methods as done, for example, by Beckman et al.[46] Gnanadesikan et al. give numerical solutions for a few cases.[47] N.L.Johnson and S.Kotz[1] suggest that for "not too small" shape parameter estimates , the logarithmic approximation to the digamma function may be used to obtain initial values for an iterative solution, since the equations resulting from this approximation can be solved exactly:



which leads to the following solution for the initial values (of the estimate shape parameters in terms of the sample geometric means) for an iterative solution:


Alternatively, the estimates provided by the method of moments can instead be used as initial values for an iterative solution of the maximum likelihood coupled equations in terms of the digamma functions.
When the distribution is required over a known interval other than [0, 1] with random variable X, say [a, c] with random variable Y, then replace ln(Xi) in the first equation with

and replace ln(1−Xi) in the second equation with

(see "Alternative parametrizations, four parameters" section below).
If one of the shape parameters is known, the problem is considerably simplified. The following logit transformation can be used to solve for the unknown shape parameter (for skewed cases such that , otherwise, if symmetric, both -equal- parameters are known when one is known):

![\hat{\operatorname{E}} \left[\ln \left(\frac{X}{1-X} \right) \right]=\psi(\hat{\alpha}) - \psi(\hat{\beta})=\frac{1}{N}\sum_{i=1}^N \ln\frac{X_i}{1-X_i} = \ln \hat{G}_X - \ln \left(\hat{G}_{(1-X)}\right)](../I/3d5d9a3105854f3fe65f5a72aa4418da4a50ba11.svg)
This logit transformation is the logarithm of the transformation that divides the variable X by its mirror-image (X/(1 - X) resulting in the "inverted beta distribution" or beta prime distribution (also known as beta distribution of the second kind or Pearson's Type VI) with support [0, +∞). As previously discussed in the section "Moments of logarithmically transformed random variables," the logit transformation , studied by Johnson,[24] extends the finite support [0, 1] based on the original variable X to infinite support in both directions of the real line (−∞, +∞).

If, for example, is known, the unknown parameter can be obtained in terms of the inverse[48] digamma function of the right hand side of this equation:




In particular, if one of the shape parameters has a value of unity, for example for (the power function distribution with bounded support [0,1]), using the identity ψ(x + 1) = ψ(x) + 1/x in the equation , the maximum likelihood estimator for the unknown parameter is,[1] exactly:



The beta has support [0, 1], therefore , and hence , and therefore



In conclusion, the maximum likelihood estimates of the shape parameters of a beta distribution are (in general) a complicated function of the sample geometric mean, and of the sample geometric mean based on (1−X), the mirror-image of X. One may ask, if the variance (in addition to the mean) is necessary to estimate two shape parameters with the method of moments, why is the (logarithmic or geometric) variance not necessary to estimate two shape parameters with the maximum likelihood method, for which only the geometric means suffice? The answer is because the mean does not provide as much information as the geometric mean. For a beta distribution with equal shape parameters α = β, the mean is exactly 1/2, regardless of the value of the shape parameters, and therefore regardless of the value of the statistical dispersion (the variance). On the other hand, the geometric mean of a beta distribution with equal shape parameters α = β, depends on the value of the shape parameters, and therefore it contains more information. Also, the geometric mean of a beta distribution does not satisfy the symmetry conditions satisfied by the mean, therefore, by employing both the geometric mean based on X and geometric mean based on (1 − X), the maximum likelihood method is able to provide best estimates for both parameters α = β, without need of employing the variance.
One can express the joint log likelihood per N iid observations in terms of the sufficient statistics (the sample geometric means) as follows:

We can plot the joint log likelihood per N observations for fixed values of the sample geometric means to see the behavior of the likelihood function as a function of the shape parameters α and β. In such a plot, the shape parameter estimators correspond to the maxima of the likelihood function. See the accompanying graph that shows that all the likelihood functions intersect at α = β = 1, which corresponds to the values of the shape parameters that give the maximum entropy (the maximum entropy occurs for shape parameters equal to unity: the uniform distribution). It is evident from the plot that the likelihood function gives sharp peaks for values of the shape parameter estimators close to zero, but that for values of the shape parameters estimators greater than one, the likelihood function becomes quite flat, with less defined peaks. Obviously, the maximum likelihood parameter estimation method for the beta distribution becomes less acceptable for larger values of the shape parameter estimators, as the uncertainty in the peak definition increases with the value of the shape parameter estimators. One can arrive at the same conclusion by noticing that the expression for the curvature of the likelihood function is in terms of the geometric variances
![{\displaystyle {\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{\partial \alpha ^{2}}}=-\operatorname {var} [\ln X]}](../I/517a09a3b13d22689a3e1e400cbcab3af08e130c.svg)
![{\displaystyle {\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{\partial \beta ^{2}}}=-\operatorname {var} [\ln(1-X)]}](../I/1715f50fc408ceba307005a3f9e404520edd5a20.svg)
These variances (and therefore the curvatures) are much larger for small values of the shape parameter α and β. However, for shape parameter values α, β > 1, the variances (and therefore the curvatures) flatten out. Equivalently, this result follows from the Cramér–Rao bound, since the Fisher information matrix components for the beta distribution are these logarithmic variances. The Cramér–Rao bound states that the variance of any unbiased estimator of α is bounded by the reciprocal of the Fisher information:
![\mathrm{var}(\hat{\alpha})\geq\frac{1}{\operatorname{var}[\ln X]}\geq\frac{1}{\psi_1(\hat{\alpha}) - \psi_1(\hat{\alpha} + \hat{\beta})}](../I/744f1e8421337ed7a2e6cae00fccec1eaf68e3dc.svg)
![\mathrm{var}(\hat{\beta}) \geq\frac{1}{\operatorname{var}[\ln (1-X)]}\geq\frac{1}{\psi_1(\hat{\beta}) - \psi_1(\hat{\alpha} + \hat{\beta})}](../I/f01dc5c3eb614cfa71a500fd34f3fa430c183c76.svg)
so the variance of the estimators increases with increasing α and β, as the logarithmic variances decrease.
Also one can express the joint log likelihood per N iid observations in terms of the digamma function expressions for the logarithms of the sample geometric means as follows:

this expression is identical to the negative of the cross-entropy (see section on "Quantities of information (entropy)"). Therefore, finding the maximum of the joint log likelihood of the shape parameters, per N iid observations, is identical to finding the minimum of the cross-entropy for the beta distribution, as a function of the shape parameters.

with the cross-entropy defined as follows:

Four unknown parameters
The procedure is similar to the one followed in the two unknown parameter case. If Y1, ..., YN are independent random variables each having a beta distribution with four parameters, the joint log likelihood function for N iid observations is:

Finding the maximum with respect to a shape parameter involves taking the partial derivative with respect to the shape parameter and setting the expression equal to zero yielding the maximum likelihood estimator of the shape parameters:




these equations can be re-arranged as the following system of four coupled equations (the first two equations are geometric means and the second two equations are the harmonic means) in terms of the maximum likelihood estimates for the four parameters :




with sample geometric means:


The parameters are embedded inside the geometric mean expressions in a nonlinear way (to the power 1/N). This precludes, in general, a closed form solution, even for an initial value approximation for iteration purposes. One alternative is to use as initial values for iteration the values obtained from the method of moments solution for the four parameter case. Furthermore, the expressions for the harmonic means are well-defined only for , which precludes a maximum likelihood solution for shape parameters less than unity in the four-parameter case. Fisher's information matrix for the four parameter case is positive-definite only for α, β > 2 (for further discussion, see section on Fisher information matrix, four parameter case), for bell-shaped (symmetric or unsymmetric) beta distributions, with inflection points located to either side of the mode. The following Fisher information components (that represent the expectations of the curvature of the log likelihood function) have singularities at the following values:

![{\displaystyle \alpha =2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial a^{2}}}\right]={\mathcal {I}}_{a,a}}](../I/53538160a2404a5d7b74ae2033fbbb2dbc1045eb.svg)
![{\displaystyle \beta =2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial c^{2}}}\right]={\mathcal {I}}_{c,c}}](../I/ee2c6ecfcafe60e54799ab4a16451cf478d65f7d.svg)
![{\displaystyle \alpha =2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha \partial a}}\right]={\mathcal {I}}_{\alpha ,a}}](../I/8b8af544d7c5e0cc278aa725daba7f3de2f70d31.svg)
![{\displaystyle \beta =1:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \beta \partial c}}\right]={\mathcal {I}}_{\beta ,c}}](../I/2f87b32b39997964dcbc95bc64c1364e6832db1d.svg)
(for further discussion see section on Fisher information matrix). Thus, it is not possible to strictly carry on the maximum likelihood estimation for some well known distributions belonging to the four-parameter beta distribution family, like the uniform distribution (Beta(1, 1, a, c)), and the arcsine distribution (Beta(1/2, 1/2, a, c)). N.L.Johnson and S.Kotz[1] ignore the equations for the harmonic means and instead suggest "If a and c are unknown, and maximum likelihood estimators of a, c, α and β are required, the above procedure (for the two unknown parameter case, with X transformed as X = (Y − a)/(c − a)) can be repeated using a succession of trial values of a and c, until the pair (a, c) for which maximum likelihood (given a and c) is as great as possible, is attained" (where, for the purpose of clarity, their notation for the parameters has been translated into the present notation).
Fisher information matrix
Let a random variable X have a probability density f(x;α). The partial derivative with respect to the (unknown, and to be estimated) parameter α of the log likelihood function is called the score. The second moment of the score is called the Fisher information:
![{\displaystyle {\mathcal {I}}(\alpha )=\operatorname {E} \left[\left({\frac {\partial }{\partial \alpha }}\ln {\mathcal {L}}(\alpha \mid X)\right)^{2}\right],}](../I/daec13972d17a073bcd447abfde55a6b0e168720.svg)
The expectation of the score is zero, therefore the Fisher information is also the second moment centered on the mean of the score: the variance of the score.
If the log likelihood function is twice differentiable with respect to the parameter α, and under certain regularity conditions,[49] then the Fisher information may also be written as follows (which is often a more convenient form for calculation purposes):
![{\displaystyle {\mathcal {I}}(\alpha )=-\operatorname {E} \left[{\frac {\partial ^{2}}{\partial \alpha ^{2}}}\ln({\mathcal {L}}(\alpha \mid X))\right].}](../I/92244569d1fab7e801097aa25a9c883ff75be5aa.svg)
Thus, the Fisher information is the negative of the expectation of the second derivative with respect to the parameter α of the log likelihood function. Therefore, Fisher information is a measure of the curvature of the log likelihood function of α. A low curvature (and therefore high radius of curvature), flatter log likelihood function curve has low Fisher information; while a log likelihood function curve with large curvature (and therefore low radius of curvature) has high Fisher information. When the Fisher information matrix is computed at the evaluates of the parameters ("the observed Fisher information matrix") it is equivalent to the replacement of the true log likelihood surface by a Taylor's series approximation, taken as far as the quadratic terms.[50] The word information, in the context of Fisher information, refers to information about the parameters. Information such as: estimation, sufficiency and properties of variances of estimators. The Cramér–Rao bound states that the inverse of the Fisher information is a lower bound on the variance of any estimator of a parameter α:
![\operatorname{var}[\hat\alpha] \geq \frac{1}{\mathcal{I}(\alpha)}.](../I/d93d4983a2717258c52eb47d1562e849a3a66c5c.svg)
The precision to which one can estimate the estimator of a parameter α is limited by the Fisher Information of the log likelihood function. The Fisher information is a measure of the minimum error involved in estimating a parameter of a distribution and it can be viewed as a measure of the resolving power of an experiment needed to discriminate between two alternative hypothesis of a parameter.[51]
When there are N parameters

then the Fisher information takes the form of an N×N positive semidefinite symmetric matrix, the Fisher Information Matrix, with typical element:
![{(\mathcal{I}(\theta))}_{i, j}=\operatorname{E} \left [\left (\frac{\partial}{\partial\theta_i} \ln \mathcal{L} \right) \left(\frac{\partial}{\partial\theta_j} \ln \mathcal{L} \right) \right ].](../I/21548fc75268a39c9137d0476132992173ec961d.svg)
Under certain regularity conditions,[49] the Fisher Information Matrix may also be written in the following form, which is often more convenient for computation:
![{(\mathcal{I}(\theta))}_{i, j} = - \operatorname{E} \left [\frac{\partial^2}{\partial\theta_i \, \partial\theta_j} \ln (\mathcal{L}) \right ]\,.](../I/faab65dd329813220161fa8f3772f043a1018d04.svg)
With X1, ..., XN iid random variables, an N-dimensional "box" can be constructed with sides X1, ..., XN. Costa and Cover[52] show that the (Shannon) differential entropy h(X) is related to the volume of the typical set (having the sample entropy close to the true entropy), while the Fisher information is related to the surface of this typical set.
Two parameters
For X1, ..., XN independent random variables each having a beta distribution parametrized with shape parameters α and β, the joint log likelihood function for N iid observations is:

therefore the joint log likelihood function per N iid observations is:

For the two parameter case, the Fisher information has 4 components: 2 diagonal and 2 off-diagonal. Since the Fisher information matrix is symmetric, one of these off diagonal components is independent. Therefore, the Fisher information matrix has 3 independent components (2 diagonal and 1 off diagonal).
Aryal and Nadarajah[53] calculated Fisher's information matrix for the four-parameter case, from which the two parameter case can be obtained as follows:
![{\displaystyle -{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\partial \alpha ^{2}}}=\operatorname {var} [\ln(X)]=\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\alpha ,\alpha }=\operatorname {E} \left[-{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\partial \alpha ^{2}}}\right]=\ln \operatorname {var} _{GX}}](../I/c90003d5bd2f6d2bcfe2c788585689726b4b7e36.svg)
![{\displaystyle -{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\,\partial \beta ^{2}}}=\operatorname {var} [\ln(1-X)]=\psi _{1}(\beta )-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\beta ,\beta }=\operatorname {E} \left[-{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\partial \beta ^{2}}}\right]=\ln \operatorname {var} _{G(1-X)}}](../I/b59bcc31f14f1f4b3b07bd92a66426bb6ac126b1.svg)
![{\displaystyle -{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\,\partial \alpha \,\partial \beta }}=\operatorname {cov} [\ln X,\ln(1-X)]=-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\alpha ,\beta }=\operatorname {E} \left[-{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta \mid X)}{N\,\partial \alpha \,\partial \beta }}\right]=\ln \operatorname {cov} _{G{X,(1-X)}}}](../I/a6c3268da3b23c062ce981ab02d4c454a0267365.svg)
Since the Fisher information matrix is symmetric

The Fisher information components are equal to the log geometric variances and log geometric covariance. Therefore, they can be expressed as trigamma functions, denoted ψ1(α), the second of the polygamma functions, defined as the derivative of the digamma function:

These derivatives are also derived in the § Two unknown parameters and plots of the log likelihood function are also shown in that section. § Geometric variance and covariance contains plots and further discussion of the Fisher information matrix components: the log geometric variances and log geometric covariance as a function of the shape parameters α and β. § Moments of logarithmically transformed random variables contains formulas for moments of logarithmically transformed random variables. Images for the Fisher information components and are shown in § Geometric variance.


The determinant of Fisher's information matrix is of interest (for example for the calculation of Jeffreys prior probability). From the expressions for the individual components of the Fisher information matrix, it follows that the determinant of Fisher's (symmetric) information matrix for the beta distribution is:
![{\displaystyle {\begin{aligned}\det({\mathcal {I}}(\alpha ,\beta ))&={\mathcal {I}}_{\alpha ,\alpha }{\mathcal {I}}_{\beta ,\beta }-{\mathcal {I}}_{\alpha ,\beta }{\mathcal {I}}_{\alpha ,\beta }\\[4pt]&=(\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta ))(\psi _{1}(\beta )-\psi _{1}(\alpha +\beta ))-(-\psi _{1}(\alpha +\beta ))(-\psi _{1}(\alpha +\beta ))\\[4pt]&=\psi _{1}(\alpha )\psi _{1}(\beta )-(\psi _{1}(\alpha )+\psi _{1}(\beta ))\psi _{1}(\alpha +\beta )\\[4pt]\lim _{\alpha \to 0}\det({\mathcal {I}}(\alpha ,\beta ))&=\lim _{\beta \to 0}\det({\mathcal {I}}(\alpha ,\beta ))=\infty \\[4pt]\lim _{\alpha \to \infty }\det({\mathcal {I}}(\alpha ,\beta ))&=\lim _{\beta \to \infty }\det({\mathcal {I}}(\alpha ,\beta ))=0\end{aligned}}}](../I/b2c5ccf59b05ea730fc108360c07e9ac9634e829.svg)
From Sylvester's criterion (checking whether the diagonal elements are all positive), it follows that the Fisher information matrix for the two parameter case is positive-definite (under the standard condition that the shape parameters are positive α > 0 and β > 0).
Four parameters
_for_alpha%253Dbeta_vs_range_(c-a)_and_exponent_alpha%253Dbeta_-_J._Rodal.png.webp)
_for_alpha%253Dbeta%252C_vs._range_(c_-_a)_and_exponent_alpha%253Dbeta_-_J._Rodal.png.webp)
If Y1, ..., YN are independent random variables each having a beta distribution with four parameters: the exponents α and β, and also a (the minimum of the distribution range), and c (the maximum of the distribution range) (section titled "Alternative parametrizations", "Four parameters"), with probability density function:
the joint log likelihood function per N iid observations is:

For the four parameter case, the Fisher information has 4*4=16 components. It has 12 off-diagonal components = (4×4 total − 4 diagonal). Since the Fisher information matrix is symmetric, half of these components (12/2=6) are independent. Therefore, the Fisher information matrix has 6 independent off-diagonal + 4 diagonal = 10 independent components. Aryal and Nadarajah[53] calculated Fisher's information matrix for the four parameter case as follows:
![{\displaystyle -{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha ^{2}}}=\operatorname {var} [\ln(X)]=\psi _{1}(\alpha )-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\alpha ,\alpha }=\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha ^{2}}}\right]=\ln(\operatorname {var_{GX}} )}](../I/31be86f2c53663c6d3975bc2676806ba3e538423.svg)
![{\displaystyle -{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \beta ^{2}}}=\operatorname {var} [\ln(1-X)]=\psi _{1}(\beta )-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\beta ,\beta }=\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \beta ^{2}}}\right]=\ln(\operatorname {var_{G(1-X)}} )}](../I/25ab885119f25fae0b9919326db96395d13e3bc3.svg)
![{\displaystyle -{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha \,\partial \beta }}=\operatorname {cov} [\ln X,(1-X)]=-\psi _{1}(\alpha +\beta )={\mathcal {I}}_{\alpha ,\beta }=\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha \,\partial \beta }}\right]=\ln(\operatorname {cov} _{G{X,(1-X)}})}](../I/02a56af746fb9315340cf382951fe0c3f3640678.svg)
In the above expressions, the use of X instead of Y in the expressions var[ln(X)] = ln(varGX) is not an error. The expressions in terms of the log geometric variances and log geometric covariance occur as functions of the two parameter X ~ Beta(α, β) parametrization because when taking the partial derivatives with respect to the exponents (α, β) in the four parameter case, one obtains the identical expressions as for the two parameter case: these terms of the four parameter Fisher information matrix are independent of the minimum a and maximum c of the distribution's range. The only non-zero term upon double differentiation of the log likelihood function with respect to the exponents α and β is the second derivative of the log of the beta function: ln(B(α, β)). This term is independent of the minimum a and maximum c of the distribution's range. Double differentiation of this term results in trigamma functions. The sections titled "Maximum likelihood", "Two unknown parameters" and "Four unknown parameters" also show this fact.
The Fisher information for N i.i.d. samples is N times the individual Fisher information (eq. 11.279, page 394 of Cover and Thomas[27]). (Aryal and Nadarajah[53] take a single observation, N = 1, to calculate the following components of the Fisher information, which leads to the same result as considering the derivatives of the log likelihood per N observations. Moreover, below the erroneous expression for in Aryal and Nadarajah has been corrected.)

![{\displaystyle {\begin{aligned}\alpha >2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial a^{2}}}\right]&={\mathcal {I}}_{a,a}={\frac {\beta (\alpha +\beta -1)}{(\alpha -2)(c-a)^{2}}}\\\beta >2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial c^{2}}}\right]&={\mathcal {I}}_{c,c}={\frac {\alpha (\alpha +\beta -1)}{(\beta -2)(c-a)^{2}}}\\\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial a\,\partial c}}\right]&={\mathcal {I}}_{a,c}={\frac {(\alpha +\beta -1)}{(c-a)^{2}}}\\\alpha >1:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha \,\partial a}}\right]&={\mathcal {I}}_{\alpha ,a}={\frac {\beta }{(\alpha -1)(c-a)}}\\\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \alpha \,\partial c}}\right]&={\mathcal {I}}_{\alpha ,c}={\frac {1}{(c-a)}}\\\operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \beta \,\partial a}}\right]&={\mathcal {I}}_{\beta ,a}=-{\frac {1}{(c-a)}}\\\beta >1:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha ,\beta ,a,c\mid Y)}{\partial \beta \,\partial c}}\right]&={\mathcal {I}}_{\beta ,c}=-{\frac {\alpha }{(\beta -1)(c-a)}}\end{aligned}}}](../I/636646f51bdb1a3193b1721483878e98f4f19c3e.svg)
The lower two diagonal entries of the Fisher information matrix, with respect to the parameter a (the minimum of the distribution's range): , and with respect to the parameter c (the maximum of the distribution's range): are only defined for exponents α > 2 and β > 2 respectively. The Fisher information matrix component for the minimum a approaches infinity for exponent α approaching 2 from above, and the Fisher information matrix component for the maximum c approaches infinity for exponent β approaching 2 from above.

The Fisher information matrix for the four parameter case does not depend on the individual values of the minimum a and the maximum c, but only on the total range (c − a). Moreover, the components of the Fisher information matrix that depend on the range (c − a), depend only through its inverse (or the square of the inverse), such that the Fisher information decreases for increasing range (c − a).
The accompanying images show the Fisher information components and . Images for the Fisher information components and are shown in § Geometric variance. All these Fisher information components look like a basin, with the "walls" of the basin being located at low values of the parameters.



The following four-parameter-beta-distribution Fisher information components can be expressed in terms of the two-parameter: X ~ Beta(α, β) expectations of the transformed ratio ((1 − X)/X) and of its mirror image (X/(1 − X)), scaled by the range (c − a), which may be helpful for interpretation:
![\mathcal{I}_{\alpha, a} =\frac{\operatorname{E} \left[\frac{1-X}{X} \right ]}{c-a}= \frac{\beta}{(\alpha-1)(c-a)} \text{ if }\alpha > 1](../I/e670565bb8d06bace69cf892864520f5c83b5449.svg)
![\mathcal{I}_{\beta, c} = -\frac{\operatorname{E} \left [\frac{X}{1-X} \right ]}{c-a}=- \frac{\alpha}{(\beta-1)(c-a)}\text{ if }\beta> 1](../I/94f9b7788a4f19e1cbc765ab8fc85a7ad55dec4f.svg)
These are also the expected values of the "inverted beta distribution" or beta prime distribution (also known as beta distribution of the second kind or Pearson's Type VI) [1] and its mirror image, scaled by the range (c − a).
Also, the following Fisher information components can be expressed in terms of the harmonic (1/X) variances or of variances based on the ratio transformed variables ((1-X)/X) as follows:
![{\displaystyle {\begin{aligned}\alpha >2:\quad {\mathcal {I}}_{a,a}&=\operatorname {var} \left[{\frac {1}{X}}\right]\left({\frac {\alpha -1}{c-a}}\right)^{2}=\operatorname {var} \left[{\frac {1-X}{X}}\right]\left({\frac {\alpha -1}{c-a}}\right)^{2}={\frac {\beta (\alpha +\beta -1)}{(\alpha -2)(c-a)^{2}}}\\\beta >2:\quad {\mathcal {I}}_{c,c}&=\operatorname {var} \left[{\frac {1}{1-X}}\right]\left({\frac {\beta -1}{c-a}}\right)^{2}=\operatorname {var} \left[{\frac {X}{1-X}}\right]\left({\frac {\beta -1}{c-a}}\right)^{2}={\frac {\alpha (\alpha +\beta -1)}{(\beta -2)(c-a)^{2}}}\\{\mathcal {I}}_{a,c}&=\operatorname {cov} \left[{\frac {1}{X}},{\frac {1}{1-X}}\right]{\frac {(\alpha -1)(\beta -1)}{(c-a)^{2}}}=\operatorname {cov} \left[{\frac {1-X}{X}},{\frac {X}{1-X}}\right]{\frac {(\alpha -1)(\beta -1)}{(c-a)^{2}}}={\frac {(\alpha +\beta -1)}{(c-a)^{2}}}\end{aligned}}}](../I/f1f89730020364bb58791ca0eb47d0de25c896c2.svg)
See section "Moments of linearly transformed, product and inverted random variables" for these expectations.
The determinant of Fisher's information matrix is of interest (for example for the calculation of Jeffreys prior probability). From the expressions for the individual components, it follows that the determinant of Fisher's (symmetric) information matrix for the beta distribution with four parameters is:

Using Sylvester's criterion (checking whether the diagonal elements are all positive), and since diagonal components and have singularities at α=2 and β=2 it follows that the Fisher information matrix for the four parameter case is positive-definite for α>2 and β>2. Since for α > 2 and β > 2 the beta distribution is (symmetric or unsymmetric) bell shaped, it follows that the Fisher information matrix is positive-definite only for bell-shaped (symmetric or unsymmetric) beta distributions, with inflection points located to either side of the mode. Thus, important well known distributions belonging to the four-parameter beta distribution family, like the parabolic distribution (Beta(2,2,a,c)) and the uniform distribution (Beta(1,1,a,c)) have Fisher information components () that blow up (approach infinity) in the four-parameter case (although their Fisher information components are all defined for the two parameter case). The four-parameter Wigner semicircle distribution (Beta(3/2,3/2,a,c)) and arcsine distribution (Beta(1/2,1/2,a,c)) have negative Fisher information determinants for the four-parameter case.

Bayesian inference
_Uniform_distribution_-_J._Rodal.png.webp)

The use of Beta distributions in Bayesian inference is due to the fact that they provide a family of conjugate prior probability distributions for binomial (including Bernoulli) and geometric distributions. The domain of the beta distribution can be viewed as a probability, and in fact the beta distribution is often used to describe the distribution of a probability value p:[23]

Examples of beta distributions used as prior probabilities to represent ignorance of prior parameter values in Bayesian inference are Beta(1,1), Beta(0,0) and Beta(1/2,1/2).
Rule of succession
A classic application of the beta distribution is the rule of succession, introduced in the 18th century by Pierre-Simon Laplace[54] in the course of treating the sunrise problem. It states that, given s successes in n conditionally independent Bernoulli trials with probability p, that the estimate of the expected value in the next trial is . This estimate is the expected value of the posterior distribution over p, namely Beta(s+1, n−s+1), which is given by Bayes' rule if one assumes a uniform prior probability over p (i.e., Beta(1, 1)) and then observes that p generated s successes in n trials. Laplace's rule of succession has been criticized by prominent scientists. R. T. Cox described Laplace's application of the rule of succession to the sunrise problem ([55] p. 89) as "a travesty of the proper use of the principle". Keynes remarks ([56] Ch.XXX, p. 382) "indeed this is so foolish a theorem that to entertain it is discreditable". Karl Pearson[57] showed that the probability that the next (n + 1) trials will be successes, after n successes in n trials, is only 50%, which has been considered too low by scientists like Jeffreys and unacceptable as a representation of the scientific process of experimentation to test a proposed scientific law. As pointed out by Jeffreys ([58] p. 128) (crediting C. D. Broad[59] ) Laplace's rule of succession establishes a high probability of success ((n+1)/(n+2)) in the next trial, but only a moderate probability (50%) that a further sample (n+1) comparable in size will be equally successful. As pointed out by Perks,[60] "The rule of succession itself is hard to accept. It assigns a probability to the next trial which implies the assumption that the actual run observed is an average run and that we are always at the end of an average run. It would, one would think, be more reasonable to assume that we were in the middle of an average run. Clearly a higher value for both probabilities is necessary if they are to accord with reasonable belief." These problems with Laplace's rule of succession motivated Haldane, Perks, Jeffreys and others to search for other forms of prior probability (see the next § Bayesian inference). According to Jaynes,[51] the main problem with the rule of succession is that it is not valid when s=0 or s=n (see rule of succession, for an analysis of its validity).

Bayes-Laplace prior probability (Beta(1,1))
The beta distribution achieves maximum differential entropy for Beta(1,1): the uniform probability density, for which all values in the domain of the distribution have equal density. This uniform distribution Beta(1,1) was suggested ("with a great deal of doubt") by Thomas Bayes[61] as the prior probability distribution to express ignorance about the correct prior distribution. This prior distribution was adopted (apparently, from his writings, with little sign of doubt[54]) by Pierre-Simon Laplace, and hence it was also known as the "Bayes-Laplace rule" or the "Laplace rule" of "inverse probability" in publications of the first half of the 20th century. In the later part of the 19th century and early part of the 20th century, scientists realized that the assumption of uniform "equal" probability density depended on the actual functions (for example whether a linear or a logarithmic scale was most appropriate) and parametrizations used. In particular, the behavior near the ends of distributions with finite support (for example near x = 0, for a distribution with initial support at x = 0) required particular attention. Keynes ([56] Ch.XXX, p. 381) criticized the use of Bayes's uniform prior probability (Beta(1,1)) that all values between zero and one are equiprobable, as follows: "Thus experience, if it shows anything, shows that there is a very marked clustering of statistical ratios in the neighborhoods of zero and unity, of those for positive theories and for correlations between positive qualities in the neighborhood of zero, and of those for negative theories and for correlations between negative qualities in the neighborhood of unity. "
Haldane's prior probability (Beta(0,0))


The Beta(0,0) distribution was proposed by J.B.S. Haldane,[62] who suggested that the prior probability representing complete uncertainty should be proportional to p−1(1−p)−1. The function p−1(1−p)−1 can be viewed as the limit of the numerator of the beta distribution as both shape parameters approach zero: α, β → 0. The Beta function (in the denominator of the beta distribution) approaches infinity, for both parameters approaching zero, α, β → 0. Therefore, p−1(1−p)−1 divided by the Beta function approaches a 2-point Bernoulli distribution with equal probability 1/2 at each end, at 0 and 1, and nothing in between, as α, β → 0. A coin-toss: one face of the coin being at 0 and the other face being at 1. The Haldane prior probability distribution Beta(0,0) is an "improper prior" because its integration (from 0 to 1) fails to strictly converge to 1 due to the singularities at each end. However, this is not an issue for computing posterior probabilities unless the sample size is very small. Furthermore, Zellner[63] points out that on the log-odds scale, (the logit transformation ln(p/1−p)), the Haldane prior is the uniformly flat prior. The fact that a uniform prior probability on the logit transformed variable ln(p/1−p) (with domain (-∞, ∞)) is equivalent to the Haldane prior on the domain [0, 1] was pointed out by Harold Jeffreys in the first edition (1939) of his book Theory of Probability ([58] p. 123). Jeffreys writes "Certainly if we take the Bayes-Laplace rule right up to the extremes we are led to results that do not correspond to anybody's way of thinking. The (Haldane) rule dx/(x(1−x)) goes too far the other way. It would lead to the conclusion that if a sample is of one type with respect to some property there is a probability 1 that the whole population is of that type." The fact that "uniform" depends on the parametrization, led Jeffreys to seek a form of prior that would be invariant under different parametrizations.
Jeffreys' prior probability (Beta(1/2,1/2) for a Bernoulli or for a binomial distribution)




_-_J._Rodal.png.webp)
Harold Jeffreys[58][64] proposed to use an uninformative prior probability measure that should be invariant under reparameterization: proportional to the square root of the determinant of Fisher's information matrix. For the Bernoulli distribution, this can be shown as follows: for a coin that is "heads" with probability p ∈ [0, 1] and is "tails" with probability 1 − p, for a given (H,T) ∈ {(0,1), (1,0)} the probability is pH(1 − p)T. Since T = 1 − H, the Bernoulli distribution is pH(1 − p)1 − H. Considering p as the only parameter, it follows that the log likelihood for the Bernoulli distribution is

The Fisher information matrix has only one component (it is a scalar, because there is only one parameter: p), therefore:
![{\displaystyle {\begin{aligned}{\sqrt {{\mathcal {I}}(p)}}&={\sqrt {\operatorname {E} \!\left[\left({\frac {d}{dp}}\ln({\mathcal {L}}(p\mid H))\right)^{2}\right]}}\\[6pt]&={\sqrt {\operatorname {E} \!\left[\left({\frac {H}{p}}-{\frac {1-H}{1-p}}\right)^{2}\right]}}\\[6pt]&={\sqrt {p^{1}(1-p)^{0}\left({\frac {1}{p}}-{\frac {0}{1-p}}\right)^{2}+p^{0}(1-p)^{1}\left({\frac {0}{p}}-{\frac {1}{1-p}}\right)^{2}}}\\&={\frac {1}{\sqrt {p(1-p)}}}.\end{aligned}}}](../I/324e2e5a963eed1652cf2d3a9ba95e5491b5df95.svg)
Similarly, for the Binomial distribution with n Bernoulli trials, it can be shown that

Thus, for the Bernoulli, and Binomial distributions, Jeffreys prior is proportional to , which happens to be proportional to a beta distribution with domain variable x = p, and shape parameters α = β = 1/2, the arcsine distribution:


It will be shown in the next section that the normalizing constant for Jeffreys prior is immaterial to the final result because the normalizing constant cancels out in Bayes theorem for the posterior probability. Hence Beta(1/2,1/2) is used as the Jeffreys prior for both Bernoulli and binomial distributions. As shown in the next section, when using this expression as a prior probability times the likelihood in Bayes theorem, the posterior probability turns out to be a beta distribution. It is important to realize, however, that Jeffreys prior is proportional to for the Bernoulli and binomial distribution, but not for the beta distribution. Jeffreys prior for the beta distribution is given by the determinant of Fisher's information for the beta distribution, which, as shown in the § Fisher information matrix is a function of the trigamma function ψ1 of shape parameters α and β as follows:

As previously discussed, Jeffreys prior for the Bernoulli and binomial distributions is proportional to the arcsine distribution Beta(1/2,1/2), a one-dimensional curve that looks like a basin as a function of the parameter p of the Bernoulli and binomial distributions. The walls of the basin are formed by p approaching the singularities at the ends p → 0 and p → 1, where Beta(1/2,1/2) approaches infinity. Jeffreys prior for the beta distribution is a 2-dimensional surface (embedded in a three-dimensional space) that looks like a basin with only two of its walls meeting at the corner α = β = 0 (and missing the other two walls) as a function of the shape parameters α and β of the beta distribution. The two adjoining walls of this 2-dimensional surface are formed by the shape parameters α and β approaching the singularities (of the trigamma function) at α, β → 0. It has no walls for α, β → ∞ because in this case the determinant of Fisher's information matrix for the beta distribution approaches zero.
It will be shown in the next section that Jeffreys prior probability results in posterior probabilities (when multiplied by the binomial likelihood function) that are intermediate between the posterior probability results of the Haldane and Bayes prior probabilities.
Jeffreys prior may be difficult to obtain analytically, and for some cases it just doesn't exist (even for simple distribution functions like the asymmetric triangular distribution). Berger, Bernardo and Sun, in a 2009 paper[65] defined a reference prior probability distribution that (unlike Jeffreys prior) exists for the asymmetric triangular distribution. They cannot obtain a closed-form expression for their reference prior, but numerical calculations show it to be nearly perfectly fitted by the (proper) prior

where θ is the vertex variable for the asymmetric triangular distribution with support [0, 1] (corresponding to the following parameter values in Wikipedia's article on the triangular distribution: vertex c = θ, left end a = 0,and right end b = 1). Berger et al. also give a heuristic argument that Beta(1/2,1/2) could indeed be the exact Berger–Bernardo–Sun reference prior for the asymmetric triangular distribution. Therefore, Beta(1/2,1/2) not only is Jeffreys prior for the Bernoulli and binomial distributions, but also seems to be the Berger–Bernardo–Sun reference prior for the asymmetric triangular distribution (for which the Jeffreys prior does not exist), a distribution used in project management and PERT analysis to describe the cost and duration of project tasks.
Clarke and Barron[66] prove that, among continuous positive priors, Jeffreys prior (when it exists) asymptotically maximizes Shannon's mutual information between a sample of size n and the parameter, and therefore Jeffreys prior is the most uninformative prior (measuring information as Shannon information). The proof rests on an examination of the Kullback–Leibler divergence between probability density functions for iid random variables.
Effect of different prior probability choices on the posterior beta distribution
If samples are drawn from the population of a random variable X that result in s successes and f failures in "n" Bernoulli trials n = s + f, then the likelihood function for parameters s and f given x = p (the notation x = p in the expressions below will emphasize that the domain x stands for the value of the parameter p in the binomial distribution), is the following binomial distribution:

If beliefs about prior probability information are reasonably well approximated by a beta distribution with parameters α Prior and β Prior, then:

According to Bayes' theorem for a continuous event space, the posterior probability is given by the product of the prior probability and the likelihood function (given the evidence s and f = n − s), normalized so that the area under the curve equals one, as follows:
![{\displaystyle {\begin{aligned}&\operatorname {posteriorprobability} (x=p\mid s,n-s)\\[6pt]={}&{\frac {\operatorname {PriorProbability} (x=p;\alpha \operatorname {Prior} ,\beta \operatorname {Prior} ){\mathcal {L}}(s,f\mid x=p)}{\int _{0}^{1}\operatorname {PriorProbability} (x=p;\alpha \operatorname {Prior} ,\beta \operatorname {Prior} ){\mathcal {L}}(s,f\mid x=p)dx}}\\[6pt]={}&{\frac {{n \choose s}x^{s+\alpha \operatorname {Prior} -1}(1-x)^{n-s+\beta \operatorname {Prior} -1}/\mathrm {B} (\alpha \operatorname {Prior} ,\beta \operatorname {Prior} )}{\int _{0}^{1}\left({n \choose s}x^{s+\alpha \operatorname {Prior} -1}(1-x)^{n-s+\beta \operatorname {Prior} -1}/\mathrm {B} (\alpha \operatorname {Prior} ,\beta \operatorname {Prior} )\right)dx}}\\[6pt]={}&{\frac {x^{s+\alpha \operatorname {Prior} -1}(1-x)^{n-s+\beta \operatorname {Prior} -1}}{\int _{0}^{1}\left(x^{s+\alpha \operatorname {Prior} -1}(1-x)^{n-s+\beta \operatorname {Prior} -1}\right)dx}}\\[6pt]={}&{\frac {x^{s+\alpha \operatorname {Prior} -1}(1-x)^{n-s+\beta \operatorname {Prior} -1}}{\mathrm {B} (s+\alpha \operatorname {Prior} ,n-s+\beta \operatorname {Prior} )}}.\end{aligned}}}](../I/3604b1c47e226d5ce09894b1a3b372fba8c9f8a3.svg)

appears both in the numerator and the denominator of the posterior probability, and it does not depend on the integration variable x, hence it cancels out, and it is irrelevant to the final result. Similarly the normalizing factor for the prior probability, the beta function B(αPrior,βPrior) cancels out and it is immaterial to the final result. The same posterior probability result can be obtained if one uses an un-normalized prior

because the normalizing factors all cancel out. Several authors (including Jeffreys himself) thus use an un-normalized prior formula since the normalization constant cancels out. The numerator of the posterior probability ends up being just the (un-normalized) product of the prior probability and the likelihood function, and the denominator is its integral from zero to one. The beta function in the denominator, B(s + α Prior, n − s + β Prior), appears as a normalization constant to ensure that the total posterior probability integrates to unity.
The ratio s/n of the number of successes to the total number of trials is a sufficient statistic in the binomial case, which is relevant for the following results.
For the Bayes' prior probability (Beta(1,1)), the posterior probability is:

For the Jeffreys' prior probability (Beta(1/2,1/2)), the posterior probability is:

and for the Haldane prior probability (Beta(0,0)), the posterior probability is:

From the above expressions it follows that for s/n = 1/2) all the above three prior probabilities result in the identical location for the posterior probability mean = mode = 1/2. For s/n < 1/2, the mean of the posterior probabilities, using the following priors, are such that: mean for Bayes prior > mean for Jeffreys prior > mean for Haldane prior. For s/n > 1/2 the order of these inequalities is reversed such that the Haldane prior probability results in the largest posterior mean. The Haldane prior probability Beta(0,0) results in a posterior probability density with mean (the expected value for the probability of success in the "next" trial) identical to the ratio s/n of the number of successes to the total number of trials. Therefore, the Haldane prior results in a posterior probability with expected value in the next trial equal to the maximum likelihood. The Bayes prior probability Beta(1,1) results in a posterior probability density with mode identical to the ratio s/n (the maximum likelihood).
In the case that 100% of the trials have been successful s = n, the Bayes prior probability Beta(1,1) results in a posterior expected value equal to the rule of succession (n + 1)/(n + 2), while the Haldane prior Beta(0,0) results in a posterior expected value of 1 (absolute certainty of success in the next trial). Jeffreys prior probability results in a posterior expected value equal to (n + 1/2)/(n + 1). Perks[60] (p. 303) points out: "This provides a new rule of succession and expresses a 'reasonable' position to take up, namely, that after an unbroken run of n successes we assume a probability for the next trial equivalent to the assumption that we are about half-way through an average run, i.e. that we expect a failure once in (2n + 2) trials. The Bayes–Laplace rule implies that we are about at the end of an average run or that we expect a failure once in (n + 2) trials. The comparison clearly favours the new result (what is now called Jeffreys prior) from the point of view of 'reasonableness'."
Conversely, in the case that 100% of the trials have resulted in failure (s = 0), the Bayes prior probability Beta(1,1) results in a posterior expected value for success in the next trial equal to 1/(n + 2), while the Haldane prior Beta(0,0) results in a posterior expected value of success in the next trial of 0 (absolute certainty of failure in the next trial). Jeffreys prior probability results in a posterior expected value for success in the next trial equal to (1/2)/(n + 1), which Perks[60] (p. 303) points out: "is a much more reasonably remote result than the Bayes-Laplace result 1/(n + 2)".
Jaynes[51] questions (for the uniform prior Beta(1,1)) the use of these formulas for the cases s = 0 or s = n because the integrals do not converge (Beta(1,1) is an improper prior for s = 0 or s = n). In practice, the conditions 0<s<n necessary for a mode to exist between both ends for the Bayes prior are usually met, and therefore the Bayes prior (as long as 0 < s < n) results in a posterior mode located between both ends of the domain.
As remarked in the section on the rule of succession, K. Pearson showed that after n successes in n trials the posterior probability (based on the Bayes Beta(1,1) distribution as the prior probability) that the next (n + 1) trials will all be successes is exactly 1/2, whatever the value of n. Based on the Haldane Beta(0,0) distribution as the prior probability, this posterior probability is 1 (absolute certainty that after n successes in n trials the next (n + 1) trials will all be successes). Perks[60] (p. 303) shows that, for what is now known as the Jeffreys prior, this probability is ((n + 1/2)/(n + 1))((n + 3/2)/(n + 2))...(2n + 1/2)/(2n + 1), which for n = 1, 2, 3 gives 15/24, 315/480, 9009/13440; rapidly approaching a limiting value of as n tends to infinity. Perks remarks that what is now known as the Jeffreys prior: "is clearly more 'reasonable' than either the Bayes-Laplace result or the result on the (Haldane) alternative rule rejected by Jeffreys which gives certainty as the probability. It clearly provides a very much better correspondence with the process of induction. Whether it is 'absolutely' reasonable for the purpose, i.e. whether it is yet large enough, without the absurdity of reaching unity, is a matter for others to decide. But it must be realized that the result depends on the assumption of complete indifference and absence of knowledge prior to the sampling experiment."

Following are the variances of the posterior distribution obtained with these three prior probability distributions:
for the Bayes' prior probability (Beta(1,1)), the posterior variance is:

for the Jeffreys' prior probability (Beta(1/2,1/2)), the posterior variance is:

and for the Haldane prior probability (Beta(0,0)), the posterior variance is:

So, as remarked by Silvey,[49] for large n, the variance is small and hence the posterior distribution is highly concentrated, whereas the assumed prior distribution was very diffuse. This is in accord with what one would hope for, as vague prior knowledge is transformed (through Bayes theorem) into a more precise posterior knowledge by an informative experiment. For small n the Haldane Beta(0,0) prior results in the largest posterior variance while the Bayes Beta(1,1) prior results in the more concentrated posterior. Jeffreys prior Beta(1/2,1/2) results in a posterior variance in between the other two. As n increases, the variance rapidly decreases so that the posterior variance for all three priors converges to approximately the same value (approaching zero variance as n → ∞). Recalling the previous result that the Haldane prior probability Beta(0,0) results in a posterior probability density with mean (the expected value for the probability of success in the "next" trial) identical to the ratio s/n of the number of successes to the total number of trials, it follows from the above expression that also the Haldane prior Beta(0,0) results in a posterior with variance identical to the variance expressed in terms of the max. likelihood estimate s/n and sample size (in § Variance):

with the mean μ = s/n and the sample size ν = n.
In Bayesian inference, using a prior distribution Beta(αPrior,βPrior) prior to a binomial distribution is equivalent to adding (αPrior − 1) pseudo-observations of "success" and (βPrior − 1) pseudo-observations of "failure" to the actual number of successes and failures observed, then estimating the parameter p of the binomial distribution by the proportion of successes over both real- and pseudo-observations. A uniform prior Beta(1,1) does not add (or subtract) any pseudo-observations since for Beta(1,1) it follows that (αPrior − 1) = 0 and (βPrior − 1) = 0. The Haldane prior Beta(0,0) subtracts one pseudo observation from each and Jeffreys prior Beta(1/2,1/2) subtracts 1/2 pseudo-observation of success and an equal number of failure. This subtraction has the effect of smoothing out the posterior distribution. If the proportion of successes is not 50% (s/n ≠ 1/2) values of αPrior and βPrior less than 1 (and therefore negative (αPrior − 1) and (βPrior − 1)) favor sparsity, i.e. distributions where the parameter p is closer to either 0 or 1. In effect, values of αPrior and βPrior between 0 and 1, when operating together, function as a concentration parameter.
The accompanying plots show the posterior probability density functions for sample sizes n ∈ {3,10,50}, successes s ∈ {n/2,n/4} and Beta(αPrior,βPrior) ∈ {Beta(0,0),Beta(1/2,1/2),Beta(1,1)}. Also shown are the cases for n = {4,12,40}, success s = {n/4} and Beta(αPrior,βPrior) ∈ {Beta(0,0),Beta(1/2,1/2),Beta(1,1)}. The first plot shows the symmetric cases, for successes s ∈ {n/2}, with mean = mode = 1/2 and the second plot shows the skewed cases s ∈ {n/4}. The images show that there is little difference between the priors for the posterior with sample size of 50 (characterized by a more pronounced peak near p = 1/2). Significant differences appear for very small sample sizes (in particular for the flatter distribution for the degenerate case of sample size = 3). Therefore, the skewed cases, with successes s = {n/4}, show a larger effect from the choice of prior, at small sample size, than the symmetric cases. For symmetric distributions, the Bayes prior Beta(1,1) results in the most "peaky" and highest posterior distributions and the Haldane prior Beta(0,0) results in the flattest and lowest peak distribution. The Jeffreys prior Beta(1/2,1/2) lies in between them. For nearly symmetric, not too skewed distributions the effect of the priors is similar. For very small sample size (in this case for a sample size of 3) and skewed distribution (in this example for s ∈ {n/4}) the Haldane prior can result in a reverse-J-shaped distribution with a singularity at the left end. However, this happens only in degenerate cases (in this example n = 3 and hence s = 3/4 < 1, a degenerate value because s should be greater than unity in order for the posterior of the Haldane prior to have a mode located between the ends, and because s = 3/4 is not an integer number, hence it violates the initial assumption of a binomial distribution for the likelihood) and it is not an issue in generic cases of reasonable sample size (such that the condition 1 < s < n − 1, necessary for a mode to exist between both ends, is fulfilled).
In Chapter 12 (p. 385) of his book, Jaynes[51] asserts that the Haldane prior Beta(0,0) describes a prior state of knowledge of complete ignorance, where we are not even sure whether it is physically possible for an experiment to yield either a success or a failure, while the Bayes (uniform) prior Beta(1,1) applies if one knows that both binary outcomes are possible. Jaynes states: "interpret the Bayes-Laplace (Beta(1,1)) prior as describing not a state of complete ignorance, but the state of knowledge in which we have observed one success and one failure...once we have seen at least one success and one failure, then we know that the experiment is a true binary one, in the sense of physical possibility." Jaynes [51] does not specifically discuss Jeffreys prior Beta(1/2,1/2) (Jaynes discussion of "Jeffreys prior" on pp. 181, 423 and on chapter 12 of Jaynes book[51] refers instead to the improper, un-normalized, prior "1/p dp" introduced by Jeffreys in the 1939 edition of his book,[58] seven years before he introduced what is now known as Jeffreys' invariant prior: the square root of the determinant of Fisher's information matrix. "1/p" is Jeffreys' (1946) invariant prior for the exponential distribution, not for the Bernoulli or binomial distributions). However, it follows from the above discussion that Jeffreys Beta(1/2,1/2) prior represents a state of knowledge in between the Haldane Beta(0,0) and Bayes Beta (1,1) prior.
Similarly, Karl Pearson in his 1892 book The Grammar of Science[67][68] (p. 144 of 1900 edition) maintained that the Bayes (Beta(1,1) uniform prior was not a complete ignorance prior, and that it should be used when prior information justified to "distribute our ignorance equally"". K. Pearson wrote: "Yet the only supposition that we appear to have made is this: that, knowing nothing of nature, routine and anomy (from the Greek ανομία, namely: a- "without", and nomos "law") are to be considered as equally likely to occur. Now we were not really justified in making even this assumption, for it involves a knowledge that we do not possess regarding nature. We use our experience of the constitution and action of coins in general to assert that heads and tails are equally probable, but we have no right to assert before experience that, as we know nothing of nature, routine and breach are equally probable. In our ignorance we ought to consider before experience that nature may consist of all routines, all anomies (normlessness), or a mixture of the two in any proportion whatever, and that all such are equally probable. Which of these constitutions after experience is the most probable must clearly depend on what that experience has been like."
If there is sufficient sampling data, and the posterior probability mode is not located at one of the extremes of the domain (x=0 or x=1), the three priors of Bayes (Beta(1,1)), Jeffreys (Beta(1/2,1/2)) and Haldane (Beta(0,0)) should yield similar posterior probability densities. Otherwise, as Gelman et al.[69] (p. 65) point out, "if so few data are available that the choice of noninformative prior distribution makes a difference, one should put relevant information into the prior distribution", or as Berger[4] (p. 125) points out "when different reasonable priors yield substantially different answers, can it be right to state that there is a single answer? Would it not be better to admit that there is scientific uncertainty, with the conclusion depending on prior beliefs?."
Occurrence and applications
Order statistics
The beta distribution has an important application in the theory of order statistics. A basic result is that the distribution of the kth smallest of a sample of size n from a continuous uniform distribution has a beta distribution.[38] This result is summarized as:

From this, and application of the theory related to the probability integral transform, the distribution of any individual order statistic from any continuous distribution can be derived.[38]
Subjective logic
In standard logic, propositions are considered to be either true or false. In contradistinction, subjective logic assumes that humans cannot determine with absolute certainty whether a proposition about the real world is absolutely true or false. In subjective logic the posteriori probability estimates of binary events can be represented by beta distributions.[70]
Wavelet analysis
A wavelet is a wave-like oscillation with an amplitude that starts out at zero, increases, and then decreases back to zero. It can typically be visualized as a "brief oscillation" that promptly decays. Wavelets can be used to extract information from many different kinds of data, including – but certainly not limited to – audio signals and images. Thus, wavelets are purposefully crafted to have specific properties that make them useful for signal processing. Wavelets are localized in both time and frequency whereas the standard Fourier transform is only localized in frequency. Therefore, standard Fourier Transforms are only applicable to stationary processes, while wavelets are applicable to non-stationary processes. Continuous wavelets can be constructed based on the beta distribution. Beta wavelets[71] can be viewed as a soft variety of Haar wavelets whose shape is fine-tuned by two shape parameters α and β.
Population genetics
The Balding–Nichols model is a two-parameter parametrization of the beta distribution used in population genetics.[72] It is a statistical description of the allele frequencies in the components of a sub-divided population:

where and ; here F is (Wright's) genetic distance between two populations.


Project management: task cost and schedule modeling
The beta distribution can be used to model events which are constrained to take place within an interval defined by a minimum and maximum value. For this reason, the beta distribution — along with the triangular distribution — is used extensively in PERT, critical path method (CPM), Joint Cost Schedule Modeling (JCSM) and other project management/control systems to describe the time to completion and the cost of a task. In project management, shorthand computations are widely used to estimate the mean and standard deviation of the beta distribution:[37]

where a is the minimum, c is the maximum, and b is the most likely value (the mode for α > 1 and β > 1).
The above estimate for the mean is known as the PERT three-point estimation and it is exact for either of the following values of β (for arbitrary α within these ranges):

- β = α > 1 (symmetric case) with standard deviation , skewness = 0, and excess kurtosis =


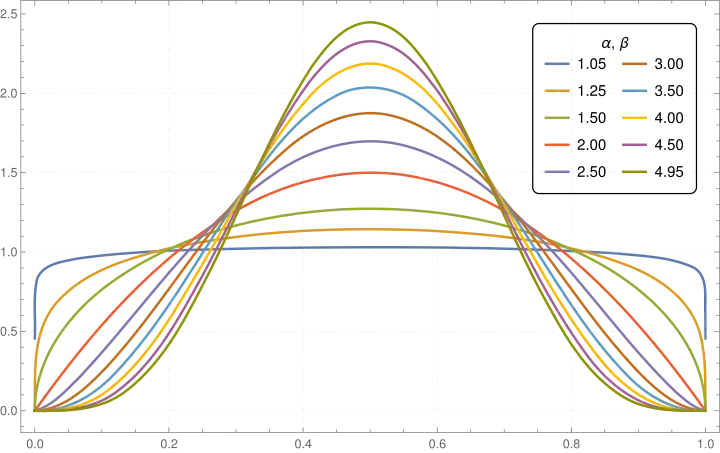
or
- β = 6 − α for 5 > α > 1 (skewed case) with standard deviation

skewness = , and excess kurtosis =



The above estimate for the standard deviation σ(X) = (c − a)/6 is exact for either of the following values of α and β:
- α = β = 4 (symmetric) with skewness = 0, and excess kurtosis = −6/11.
- β = 6 − α and (right-tailed, positive skew) with skewness , and excess kurtosis = 0
- β = 6 − α and (left-tailed, negative skew) with skewness , and excess kurtosis = 0




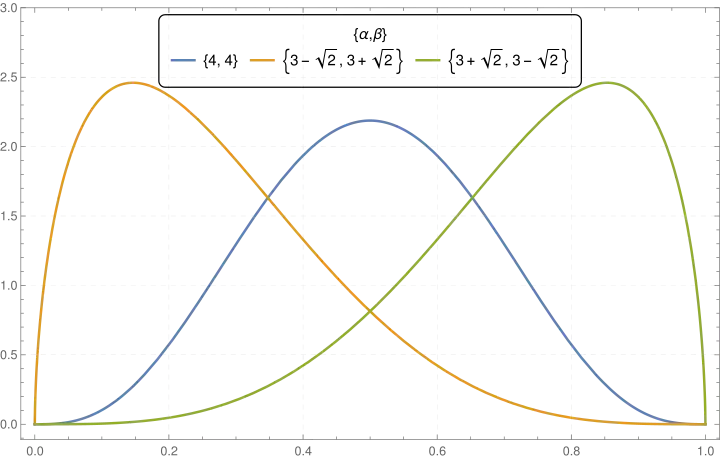
Otherwise, these can be poor approximations for beta distributions with other values of α and β, exhibiting average errors of 40% in the mean and 549% in the variance.[73][74][75]
Random variate generation
If X and Y are independent, with and then



So one algorithm for generating beta variates is to generate , where X is a gamma variate with parameters (α, 1) and Y is an independent gamma variate with parameters (β, 1).[76] In fact, here and are independent, and . If and is independent of and , then and is independent of . This shows that the product of independent and random variables is a random variable.












Also, the kth order statistic of n uniformly distributed variates is , so an alternative if α and β are small integers is to generate α + β − 1 uniform variates and choose the α-th smallest.[38]

Another way to generate the Beta distribution is by Pólya urn model. According to this method, one start with an "urn" with α "black" balls and β "white" balls and draw uniformly with replacement. Every trial an additional ball is added according to the color of the last ball which was drawn. Asymptotically, the proportion of black and white balls will be distributed according to the Beta distribution, where each repetition of the experiment will produce a different value.
It is also possible to use the inverse transform sampling.
Normal approximation to the Beta distribution
A beta distribution with α ~ β and α and β >> 1 is approximately normal with mean 1/2 and variance 1/4(2α + 1). If α ≥ β the Normal approximation can be improved by taking the cube-root of the logarithm of the reciprocal of [77]
History
Thomas Bayes, in a posthumous paper [61] published in 1763 by Richard Price, obtained a beta distribution as the density of the probability of success in Bernoulli trials (see § Applications, Bayesian inference), but the paper does not analyze any of the moments of the beta distribution or discuss any of its properties.

The first systematic modern discussion of the beta distribution is probably due to Karl Pearson.[78][79] In Pearson's papers[20][32] the beta distribution is couched as a solution of a differential equation: Pearson's Type I distribution which it is essentially identical to except for arbitrary shifting and re-scaling (the beta and Pearson Type I distributions can always be equalized by proper choice of parameters). In fact, in several English books and journal articles in the few decades prior to World War II, it was common to refer to the beta distribution as Pearson's Type I distribution. William P. Elderton in his 1906 monograph "Frequency curves and correlation"[41] further analyzes the beta distribution as Pearson's Type I distribution, including a full discussion of the method of moments for the four parameter case, and diagrams of (what Elderton describes as) U-shaped, J-shaped, twisted J-shaped, "cocked-hat" shapes, horizontal and angled straight-line cases. Elderton wrote "I am chiefly indebted to Professor Pearson, but the indebtedness is of a kind for which it is impossible to offer formal thanks." Elderton in his 1906 monograph [41] provides an impressive amount of information on the beta distribution, including equations for the origin of the distribution chosen to be the mode, as well as for other Pearson distributions: types I through VII. Elderton also included a number of appendixes, including one appendix ("II") on the beta and gamma functions. In later editions, Elderton added equations for the origin of the distribution chosen to be the mean, and analysis of Pearson distributions VIII through XII.
As remarked by Bowman and Shenton[43] "Fisher and Pearson had a difference of opinion in the approach to (parameter) estimation, in particular relating to (Pearson's method of) moments and (Fisher's method of) maximum likelihood in the case of the Beta distribution." Also according to Bowman and Shenton, "the case of a Type I (beta distribution) model being the center of the controversy was pure serendipity. A more difficult model of 4 parameters would have been hard to find." The long running public conflict of Fisher with Karl Pearson can be followed in a number of articles in prestigious journals. For example, concerning the estimation of the four parameters for the beta distribution, and Fisher's criticism of Pearson's method of moments as being arbitrary, see Pearson's article "Method of moments and method of maximum likelihood" [44] (published three years after his retirement from University College, London, where his position had been divided between Fisher and Pearson's son Egon) in which Pearson writes "I read (Koshai's paper in the Journal of the Royal Statistical Society, 1933) which as far as I am aware is the only case at present published of the application of Professor Fisher's method. To my astonishment that method depends on first working out the constants of the frequency curve by the (Pearson) Method of Moments and then superposing on it, by what Fisher terms "the Method of Maximum Likelihood" a further approximation to obtain, what he holds, he will thus get, "more efficient values" of the curve constants".
David and Edwards's treatise on the history of statistics[80] cites the first modern treatment of the beta distribution, in 1911,[81] using the beta designation that has become standard, due to Corrado Gini, an Italian statistician, demographer, and sociologist, who developed the Gini coefficient. N.L.Johnson and S.Kotz, in their comprehensive and very informative monograph[82] on leading historical personalities in statistical sciences credit Corrado Gini[83] as "an early Bayesian...who dealt with the problem of eliciting the parameters of an initial Beta distribution, by singling out techniques which anticipated the advent of the so-called empirical Bayes approach."
References
- Johnson, Norman L.; Kotz, Samuel; Balakrishnan, N. (1995). "Chapter 25:Beta Distributions". Continuous Univariate Distributions Vol. 2 (2nd ed.). Wiley. ISBN 978-0-471-58494-0.
- Rose, Colin; Smith, Murray D. (2002). Mathematical Statistics with MATHEMATICA. Springer. ISBN 978-0387952345.
- Kruschke, John K. (2011). Doing Bayesian data analysis: A tutorial with R and BUGS. Academic Press / Elsevier. p. 83. ISBN 978-0123814852.
- Berger, James O. (2010). Statistical Decision Theory and Bayesian Analysis (2nd ed.). Springer. ISBN 978-1441930743.
- Feller, William (1971). An Introduction to Probability Theory and Its Applications, Vol. 2. Wiley. ISBN 978-0471257097.
- Kruschke, John K. (2015). Doing Bayesian Data Analysis: A Tutorial with R, JAGS and Stan. Academic Press / Elsevier. ISBN 978-0-12-405888-0.
- Wadsworth, George P. and Joseph Bryan (1960). Introduction to Probability and Random Variables. McGraw-Hill.
- Gupta, Arjun K., ed. (2004). Handbook of Beta Distribution and Its Applications. CRC Press. ISBN 978-0824753962.
- Kerman J (2011) "A closed-form approximation for the median of the beta distribution". arXiv:1111.0433v1
- Mosteller, Frederick and John Tukey (1977). Data Analysis and Regression: A Second Course in Statistics. Addison-Wesley Pub. Co. Bibcode:1977dars.book.....M. ISBN 978-0201048544.
- Feller, William (1968). An Introduction to Probability Theory and Its Applications. Vol. 1 (3rd ed.). ISBN 978-0471257080.
- Philip J. Fleming and John J. Wallace. How not to lie with statistics: the correct way to summarize benchmark results. Communications of the ACM, 29(3):218–221, March 1986.
- "NIST/SEMATECH e-Handbook of Statistical Methods 1.3.6.6.17. Beta Distribution". National Institute of Standards and Technology Information Technology Laboratory. April 2012. Retrieved May 31, 2016.
- Oguamanam, D.C.D.; Martin, H. R.; Huissoon, J. P. (1995). "On the application of the beta distribution to gear damage analysis". Applied Acoustics. 45 (3): 247–261. doi:10.1016/0003-682X(95)00001-P.
- Zhiqiang Liang; Jianming Wei; Junyu Zhao; Haitao Liu; Baoqing Li; Jie Shen; Chunlei Zheng (27 August 2008). "The Statistical Meaning of Kurtosis and Its New Application to Identification of Persons Based on Seismic Signals". Sensors. 8 (8): 5106–5119. Bibcode:2008Senso...8.5106L. doi:10.3390/s8085106. PMC 3705491. PMID 27873804.
- Kenney, J. F., and E. S. Keeping (1951). Mathematics of Statistics Part Two, 2nd edition. D. Van Nostrand Company Inc.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Abramowitz, Milton and Irene A. Stegun (1965). Handbook Of Mathematical Functions With Formulas, Graphs, And Mathematical Tables. Dover. ISBN 978-0-486-61272-0.
- Weisstein., Eric W. "Kurtosis". MathWorld--A Wolfram Web Resource. Retrieved 13 August 2012.
- Panik, Michael J (2005). Advanced Statistics from an Elementary Point of View. Academic Press. ISBN 978-0120884940.
- Pearson, Karl (1916). "Mathematical contributions to the theory of evolution, XIX: Second supplement to a memoir on skew variation". Philosophical Transactions of the Royal Society A. 216 (538–548): 429–457. Bibcode:1916RSPTA.216..429P. doi:10.1098/rsta.1916.0009. JSTOR 91092.
- Gradshteyn, Izrail Solomonovich; Ryzhik, Iosif Moiseevich; Geronimus, Yuri Veniaminovich; Tseytlin, Michail Yulyevich; Jeffrey, Alan (2015) [October 2014]. Zwillinger, Daniel; Moll, Victor Hugo (eds.). Table of Integrals, Series, and Products. Translated by Scripta Technica, Inc. (8 ed.). Academic Press, Inc. ISBN 978-0-12-384933-5. LCCN 2014010276.
- Billingsley, Patrick (1995). "30". Probability and measure (3rd ed.). Wiley-Interscience. ISBN 978-0-471-00710-4.
- MacKay, David (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press; First Edition. Bibcode:2003itil.book.....M. ISBN 978-0521642989.
- Johnson, N.L. (1949). "Systems of frequency curves generated by methods of translation" (PDF). Biometrika. 36 (1–2): 149–176. doi:10.1093/biomet/36.1-2.149. hdl:10338.dmlcz/135506. PMID 18132090.
- Verdugo Lazo, A. C. G.; Rathie, P. N. (1978). "On the entropy of continuous probability distributions". IEEE Trans. Inf. Theory. 24 (1): 120–122. doi:10.1109/TIT.1978.1055832.
- Shannon, Claude E. (1948). "A Mathematical Theory of Communication". Bell System Technical Journal. 27 (4): 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x.
- Cover, Thomas M. and Joy A. Thomas (2006). Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience; 2 edition. ISBN 978-0471241959.
- Plunkett, Kim, and Jeffrey Elman (1997). Exercises in Rethinking Innateness: A Handbook for Connectionist Simulations (Neural Network Modeling and Connectionism). A Bradford Book. p. 166. ISBN 978-0262661058.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Nallapati, Ramesh (2006). The smoothed dirichlet distribution: understanding cross-entropy ranking in information retrieval (Thesis). Computer Science Dept., University of Massachusetts Amherst.
- Pearson, Egon S. (July 1969). "Some historical reflections traced through the development of the use of frequency curves". THEMIS Statistical Analysis Research Program, Technical Report 38. Office of Naval Research, Contract N000014-68-A-0515 (Project NR 042–260).
- Hahn, Gerald J.; Shapiro, S. (1994). Statistical Models in Engineering (Wiley Classics Library). Wiley-Interscience. ISBN 978-0471040651.
- Pearson, Karl (1895). "Contributions to the mathematical theory of evolution, II: Skew variation in homogeneous material". Philosophical Transactions of the Royal Society. 186: 343–414. Bibcode:1895RSPTA.186..343P. doi:10.1098/rsta.1895.0010. JSTOR 90649.
- Buchanan, K.; Rockway, J.; Sternberg, O.; Mai, N. N. (May 2016). "Sum-difference beamforming for radar applications using circularly tapered random arrays". 2016 IEEE Radar Conference (RadarConf). pp. 1–5. doi:10.1109/RADAR.2016.7485289. ISBN 978-1-5090-0863-6. S2CID 32525626.
- Buchanan, K.; Flores, C.; Wheeland, S.; Jensen, J.; Grayson, D.; Huff, G. (May 2017). "Transmit beamforming for radar applications using circularly tapered random arrays". 2017 IEEE Radar Conference (RadarConf). pp. 0112–0117. doi:10.1109/RADAR.2017.7944181. ISBN 978-1-4673-8823-8. S2CID 38429370.
- Ryan, Buchanan, Kristopher (2014-05-29). "Theory and Applications of Aperiodic (Random) Phased Arrays".
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: multiple names: authors list (link) - Herrerías-Velasco, José Manuel and Herrerías-Pleguezuelo, Rafael and René van Dorp, Johan. (2011). Revisiting the PERT mean and Variance. European Journal of Operational Research (210), p. 448–451.
- Malcolm, D. G.; Roseboom, J. H.; Clark, C. E.; Fazar, W. (September–October 1958). "Application of a Technique for Research and Development Program Evaluation". Operations Research. 7 (5): 646–669. doi:10.1287/opre.7.5.646. ISSN 0030-364X.
- David, H. A., Nagaraja, H. N. (2003) Order Statistics (3rd Edition). Wiley, New Jersey pp 458. ISBN 0-471-38926-9
- "Beta distribution". www.statlect.com.
- "1.3.6.6.17. Beta Distribution". www.itl.nist.gov.
- Elderton, William Palin (1906). Frequency-Curves and Correlation. Charles and Edwin Layton (London).
- Elderton, William Palin and Norman Lloyd Johnson (2009). Systems of Frequency Curves. Cambridge University Press. ISBN 978-0521093361.
- Bowman, K. O.; Shenton, L. R. (2007). "The beta distribution, moment method, Karl Pearson and R.A. Fisher" (PDF). Far East J. Theo. Stat. 23 (2): 133–164.
- Pearson, Karl (June 1936). "Method of moments and method of maximum likelihood". Biometrika. 28 (1/2): 34–59. doi:10.2307/2334123. JSTOR 2334123.
- Joanes, D. N.; C. A. Gill (1998). "Comparing measures of sample skewness and kurtosis". The Statistician. 47 (Part 1): 183–189. doi:10.1111/1467-9884.00122.
- Beckman, R. J.; G. L. Tietjen (1978). "Maximum likelihood estimation for the beta distribution". Journal of Statistical Computation and Simulation. 7 (3–4): 253–258. doi:10.1080/00949657808810232.
- Gnanadesikan, R.,Pinkham and Hughes (1967). "Maximum likelihood estimation of the parameters of the beta distribution from smallest order statistics". Technometrics. 9 (4): 607–620. doi:10.2307/1266199. JSTOR 1266199.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - Fackler, Paul. "Inverse Digamma Function (Matlab)". Harvard University School of Engineering and Applied Sciences. Retrieved 2012-08-18.
- Silvey, S.D. (1975). Statistical Inference. Chapman and Hal. p. 40. ISBN 978-0412138201.
- Edwards, A. W. F. (1992). Likelihood. The Johns Hopkins University Press. ISBN 978-0801844430.
- Jaynes, E.T. (2003). Probability theory, the logic of science. Cambridge University Press. ISBN 978-0521592710.
- Costa, Max, and Cover, Thomas (September 1983). On the similarity of the entropy power inequality and the Brunn Minkowski inequality (PDF). Tech.Report 48, Dept. Statistics, Stanford University.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Aryal, Gokarna; Saralees Nadarajah (2004). "Information matrix for beta distributions" (PDF). Serdica Mathematical Journal (Bulgarian Academy of Science). 30: 513–526.
- Laplace, Pierre Simon, marquis de (1902). A philosophical essay on probabilities. New York : J. Wiley ; London : Chapman & Hall. ISBN 978-1-60206-328-0.
{{cite book}}: CS1 maint: multiple names: authors list (link) - Cox, Richard T. (1961). Algebra of Probable Inference. The Johns Hopkins University Press. ISBN 978-0801869822.
- Keynes, John Maynard (2010) [1921]. A Treatise on Probability: The Connection Between Philosophy and the History of Science. Wildside Press. ISBN 978-1434406965.
- Pearson, Karl (1907). "On the Influence of Past Experience on Future Expectation". Philosophical Magazine. 6 (13): 365–378.
- Jeffreys, Harold (1998). Theory of Probability. Oxford University Press, 3rd edition. ISBN 978-0198503682.
- Broad, C. D. (October 1918). "On the relation between induction and probability". MIND, A Quarterly Review of Psychology and Philosophy. 27 (New Series) (108): 389–404. doi:10.1093/mind/XXVII.4.389. JSTOR 2249035.
- Perks, Wilfred (January 1947). "Some observations on inverse probability including a new indifference rule". Journal of the Institute of Actuaries. 73 (2): 285–334. doi:10.1017/S0020268100012270.
- Bayes, Thomas; communicated by Richard Price (1763). "An Essay towards solving a Problem in the Doctrine of Chances". Philosophical Transactions of the Royal Society. 53: 370–418. doi:10.1098/rstl.1763.0053. JSTOR 105741.
- Haldane, J.B.S. (1932). "A note on inverse probability". Mathematical Proceedings of the Cambridge Philosophical Society. 28 (1): 55–61. Bibcode:1932PCPS...28...55H. doi:10.1017/s0305004100010495. S2CID 122773707.
- Zellner, Arnold (1971). An Introduction to Bayesian Inference in Econometrics. Wiley-Interscience. ISBN 978-0471169376.
- Jeffreys, Harold (September 1946). "An Invariant Form for the Prior Probability in Estimation Problems". Proceedings of the Royal Society. A 24. 186 (1007): 453–461. Bibcode:1946RSPSA.186..453J. doi:10.1098/rspa.1946.0056. PMID 20998741.
- Berger, James; Bernardo, Jose; Sun, Dongchu (2009). "The formal definition of reference priors". The Annals of Statistics. 37 (2): 905–938. arXiv:0904.0156. Bibcode:2009arXiv0904.0156B. doi:10.1214/07-AOS587. S2CID 3221355.
- Clarke, Bertrand S.; Andrew R. Barron (1994). "Jeffreys' prior is asymptotically least favorable under entropy risk" (PDF). Journal of Statistical Planning and Inference. 41: 37–60. doi:10.1016/0378-3758(94)90153-8.
- Pearson, Karl (1892). The Grammar of Science. Walter Scott, London.
- Pearson, Karl (2009). The Grammar of Science. BiblioLife. ISBN 978-1110356119.
- Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B. (2003). Bayesian Data Analysis. Chapman and Hall/CRC. ISBN 978-1584883883.
{{cite book}}: CS1 maint: multiple names: authors list (link) - A. Jøsang. A Logic for Uncertain Probabilities. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems. 9(3), pp.279-311, June 2001. PDF
- H.M. de Oliveira and G.A.A. Araújo,. Compactly Supported One-cyclic Wavelets Derived from Beta Distributions. Journal of Communication and Information Systems. vol.20, n.3, pp.27-33, 2005.
- Balding, David J.; Nichols, Richard A. (1995). "A method for quantifying differentiation between populations at multi-allelic loci and its implications for investigating identity and paternity". Genetica. Springer. 96 (1–2): 3–12. doi:10.1007/BF01441146. PMID 7607457. S2CID 30680826.
- Keefer, Donald L. and Verdini, William A. (1993). Better Estimation of PERT Activity Time Parameters. Management Science 39(9), p. 1086–1091.
- Keefer, Donald L. and Bodily, Samuel E. (1983). Three-point Approximations for Continuous Random variables. Management Science 29(5), p. 595–609.
- "Defense Resource Management Institute - Naval Postgraduate School". www.nps.edu.
- van der Waerden, B. L., "Mathematical Statistics", Springer, ISBN 978-3-540-04507-6.
- On normalizing the incomplete beta-function for fitting to dose-response curves M.E. Wise Biometrika vol 47, No. 1/2, June 1960, pp. 173-175
- Yule, G. U.; Filon, L. N. G. (1936). "Karl Pearson. 1857-1936". Obituary Notices of Fellows of the Royal Society. 2 (5): 72. doi:10.1098/rsbm.1936.0007. JSTOR 769130.
- "Library and Archive catalogue". Sackler Digital Archive. Royal Society. Archived from the original on 2011-10-25. Retrieved 2011-07-01.
- David, H. A. and A.W.F. Edwards (2001). Annotated Readings in the History of Statistics. Springer; 1 edition. ISBN 978-0387988443.
- Gini, Corrado (1911). "Considerazioni Sulle Probabilità Posteriori e Applicazioni al Rapporto dei Sessi Nelle Nascite Umane". Studi Economico-Giuridici della Università de Cagliari. Anno III (reproduced in Metron 15, 133, 171, 1949): 5–41.
- Johnson, Norman L. and Samuel Kotz, ed. (1997). Leading Personalities in Statistical Sciences: From the Seventeenth Century to the Present (Wiley Series in Probability and Statistics. Wiley. ISBN 978-0471163817.
- Metron journal. "Biography of Corrado Gini". Metron Journal. Archived from the original on 2012-07-16. Retrieved 2012-08-18.
External links
- "Beta Distribution" by Fiona Maclachlan, the Wolfram Demonstrations Project, 2007.
- Beta Distribution – Overview and Example, xycoon.com
- Beta Distribution, brighton-webs.co.uk
- Beta Distribution Video, exstrom.com
- "Beta-distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. "Beta Distribution". MathWorld.
- Harvard University Statistics 110 Lecture 23 Beta Distribution, Prof. Joe Blitzstein