Folded normal distribution
The folded normal distribution is a probability distribution related to the normal distribution. Given a normally distributed random variable X with mean μ and variance σ2, the random variable Y = |X| has a folded normal distribution. Such a case may be encountered if only the magnitude of some variable is recorded, but not its sign. The distribution is called "folded" because probability mass to the left of x = 0 is folded over by taking the absolute value. In the physics of heat conduction, the folded normal distribution is a fundamental solution of the heat equation on the half space; it corresponds to having a perfect insulator on a hyperplane through the origin.
|
Probability density function 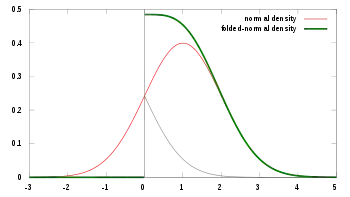 μ=1, σ=1 | |||
|
Cumulative distribution function 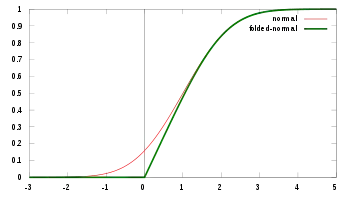 μ=1, σ=1 | |||
| Parameters |
μ ∈ R (location) σ2 > 0 (scale) | ||
|---|---|---|---|
| Support | x ∈ [0,∞) | ||
| CDF | |||
| Mean | |||
| Variance | |||

![{\frac {1}{2}}\left[{\mbox{erf}}\left({\frac {x+\mu }{\sigma {\sqrt {2}}}}\right)+{\mbox{erf}}\left({\frac {x-\mu }{\sigma {\sqrt {2}}}}\right)\right]](../I/ad88ca4e426758e5b8472945b7562acc5db7d03b.svg)


Definitions
Density
The probability density function (PDF) is given by

for x ≥ 0, and 0 everywhere else. An alternative formulation is given by
- ,

where cosh is the cosine Hyperbolic function. It follows that the cumulative distribution function (CDF) is given by:
![{\displaystyle F_{Y}(x;\mu ,\sigma ^{2})={\frac {1}{2}}\left[{\mbox{erf}}\left({\frac {x+\mu }{\sqrt {2\sigma ^{2}}}}\right)+{\mbox{erf}}\left({\frac {x-\mu }{\sqrt {2\sigma ^{2}}}}\right)\right]}](../I/bbf74023157cbecf10c9340dd9a0bfe09e3f4f1b.svg)
for x ≥ 0, where erf() is the error function. This expression reduces to the CDF of the half-normal distribution when μ = 0.
The mean of the folded distribution is then

or
![{\displaystyle \mu _{Y}={\sqrt {\frac {2}{\pi }}}\sigma e^{-{\frac {\mu ^{2}}{2\sigma ^{2}}}}+\mu \left[1-2\Phi \left(-{\frac {\mu }{\sigma }}\right)\right]}](../I/fd5bfcd3dc54605d03817a06f63bebc3a87ca556.svg)
where is the normal cumulative distribution function:

![{\displaystyle \Phi (x)\;=\;{\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {x}{\sqrt {2}}}\right)\right].}](../I/1d4a69ed96ae507f5766a6d5b8a23da4eeec1109.svg)
The variance then is expressed easily in terms of the mean:

Both the mean (μ) and variance (σ2) of X in the original normal distribution can be interpreted as the location and scale parameters of Y in the folded distribution.
Properties
Mode
The mode of the distribution is the value of for which the density is maximised. In order to find this value, we take the first derivative of the density with respect to and set it equal to zero. Unfortunately, there is no closed form. We can, however, write the derivative in a better way and end up with a non-linear equation


![{\displaystyle x\left[e^{-{\frac {1}{2}}{\frac {\left(x-\mu \right)^{2}}{\sigma ^{2}}}}+e^{-{\frac {1}{2}}{\frac {\left(x+\mu \right)^{2}}{\sigma ^{2}}}}\right]-\mu \left[e^{-{\frac {1}{2}}{\frac {\left(x-\mu \right)^{2}}{\sigma ^{2}}}}-e^{-{\frac {1}{2}}{\frac {\left(x+\mu \right)^{2}}{\sigma ^{2}}}}\right]=0}](../I/69f19ceec33ed5147ed745256c7244c5cb468364.svg)


.

Tsagris et al. (2014) saw from numerical investigation that when , the maximum is met when , and when becomes greater than , the maximum approaches . This is of course something to be expected, since, in this case, the folded normal converges to the normal distribution. In order to avoid any trouble with negative variances, the exponentiation of the parameter is suggested. Alternatively, you can add a constraint, such as if the optimiser goes for a negative variance the value of the log-likelihood is NA or something very small.




Characteristic function and other related functions
- The characteristic function is given by
.

- The moment generating function is given by
.

- The cumulant generating function is given by
.
![{\displaystyle K_{x}\left(t\right)=\log {M_{x}\left(t\right)}=\left({\frac {\sigma ^{2}t^{2}}{2}}+\mu t\right)+\log {\left\lbrace 1-\Phi \left(-{\frac {\mu }{\sigma }}-\sigma t\right)+e^{{\frac {\sigma ^{2}t^{2}}{2}}-\mu t}\left[1-\Phi \left({\frac {\mu }{\sigma }}-\sigma t\right)\right]\right\rbrace }}](../I/18260983046f5c9d546d518542872acee9d90678.svg)
- The Laplace transformation is given by
.
![{\displaystyle E\left(e^{-tx}\right)=e^{{\frac {\sigma ^{2}t^{2}}{2}}-\mu t}\left[1-\Phi \left(-{\frac {\mu }{\sigma }}+\sigma t\right)\right]+e^{{\frac {\sigma ^{2}t^{2}}{2}}+\mu t}\left[1-\Phi \left({\frac {\mu }{\sigma }}+\sigma t\right)\right]}](../I/bcf88b418505cfad95c727604e731d1801bfa53d.svg)
- The Fourier transform is given by
.
![{\displaystyle {\hat {f}}\left(t\right)=\varphi _{x}\left(-2\pi t\right)=e^{{\frac {-4\pi ^{2}\sigma ^{2}t^{2}}{2}}-i2\pi \mu t}\left[1-\Phi \left(-{\frac {\mu }{\sigma }}-i2\pi \sigma t\right)\right]+e^{-{\frac {4\pi ^{2}\sigma ^{2}t^{2}}{2}}+i2\pi \mu t}\left[1-\Phi \left({\frac {\mu }{\sigma }}-i2\pi \sigma t\right)\right]}](../I/301baa300d00800f827cc1fb35fd4d8924802c9b.svg)
Related distributions
- When μ = 0, the distribution of Y is a half-normal distribution.
- The random variable (Y/σ)2 has a noncentral chi-squared distribution with 1 degree of freedom and noncentrality equal to (μ/σ)2.
- The folded normal distribution can also be seen as the limit of the folded non-standardized t distribution as the degrees of freedom go to infinity.
- There is a bivariate version developed by Psarakis and Panaretos (2001) as well as a multivariate version developed by Chakraborty and Chatterjee (2013).
- The Rice distribution is a multivariate generalization of the folded normal distribution.
- Modified half-normal distribution[1] with the pdf on is given as , where denotes the Fox–Wright Psi function.



Statistical Inference
Estimation of parameters
There are a few ways of estimating the parameters of the folded normal. All of them are essentially the maximum likelihood estimation procedure, but in some cases, a numerical maximization is performed, whereas in other cases, the root of an equation is being searched. The log-likelihood of the folded normal when a sample of size is available can be written in the following way


![{\displaystyle l=-{\frac {n}{2}}\log {2\pi \sigma ^{2}}+\sum _{i=1}^{n}\log {\left[e^{-{\frac {\left(x_{i}-\mu \right)^{2}}{2\sigma ^{2}}}}+e^{-{\frac {\left(x_{i}+\mu \right)^{2}}{2\sigma ^{2}}}}\right]}}](../I/38356615fcbbd3459fa6208500c4f7510f58abc3.svg)
![{\displaystyle l=-{\frac {n}{2}}\log {2\pi \sigma ^{2}}+\sum _{i=1}^{n}\log {\left[e^{-{\frac {\left(x_{i}-\mu \right)^{2}}{2\sigma ^{2}}}}\left(1+e^{-{\frac {\left(x_{i}+\mu \right)^{2}}{2\sigma ^{2}}}}e^{\frac {\left(x_{i}-\mu \right)^{2}}{2\sigma ^{2}}}\right)\right]}}](../I/e73ea6fa7d9c0d187340912c1cb8aeb4f5ac8676.svg)

In R (programming language), using the package Rfast one can obtain the MLE really fast (command foldnorm.mle). Alternatively, the command optim or nlm will fit this distribution. The maximisation is easy, since two parameters ( and ) are involved. Note, that both positive and negative values for are acceptable, since belongs to the real line of numbers, hence, the sign is not important because the distribution is symmetric with respect to it. The next code is written in R

folded <- function(y) {
## y is a vector with positive data
n <- length(y) ## sample size
sy2 <- sum(y^2)
sam <- function(para, n, sy2) {
me <- para[1] ; se <- exp( para[2] )
f <- - n/2 * log(2/pi/se) + n * me^2 / 2 / se +
sy2 / 2 / se - sum( log( cosh( me * y/se ) ) )
f
}
mod <- optim( c( mean(y), sd(y) ), n = n, sy2 = sy2, sam, control = list(maxit = 2000) )
mod <- optim( mod$par, sam, n = n, sy2 = sy2, control = list(maxit = 20000) )
result <- c( -mod$value, mod$par[1], exp(mod$par[2]) )
names(result) <- c("log-likelihood", "mu", "sigma squared")
result
}
The partial derivatives of the log-likelihood are written as



.

By equating the first partial derivative of the log-likelihood to zero, we obtain a nice relationship
.

Note that the above equation has three solutions, one at zero and two more with the opposite sign. By substituting the above equation, to the partial derivative of the log-likelihood w.r.t and equating it to zero, we get the following expression for the variance
,

which is the same formula as in the normal distribution. A main difference here is that and are not statistically independent. The above relationships can be used to obtain maximum likelihood estimates in an efficient recursive way. We start with an initial value for and find the positive root () of the last equation. Then, we get an updated value of . The procedure is being repeated until the change in the log-likelihood value is negligible. Another easier and more efficient way is to perform a search algorithm. Let us write the last equation in a more elegant way

.

It becomes clear that the optimization the log-likelihood with respect to the two parameters has turned into a root search of a function. This of course is identical to the previous root search. Tsagris et al. (2014) spotted that there are three roots to this equation for , i.e. there are three possible values of that satisfy this equation. The and , which are the maximum likelihood estimates and 0, which corresponds to the minimum log-likelihood.


See also
- Folded cumulative distribution
- Half-normal distribution
- Modified half-normal distribution[1] with the pdf on is given as , where denotes the Fox–Wright Psi function.
- Truncated normal distribution
References
- Sun, Jingchao; Kong, Maiying; Pal, Subhadip (22 June 2021). "The Modified-Half-Normal distribution: Properties and an efficient sampling scheme". Communications in Statistics - Theory and Methods. 52 (5): 1591–1613. doi:10.1080/03610926.2021.1934700. ISSN 0361-0926. S2CID 237919587.
- Tsagris, M.; Beneki, C.; Hassani, H. (2014). "On the folded normal distribution". Mathematics. 2 (1): 12–28. arXiv:1402.3559. doi:10.3390/math2010012.
- Leone FC, Nottingham RB, Nelson LS (1961). "The Folded Normal Distribution". Technometrics. 3 (4): 543–550. doi:10.2307/1266560. hdl:2027/mdp.39015095248541. JSTOR 1266560.
- Johnson NL (1962). "The folded normal distribution: accuracy of the estimation by maximum likelihood". Technometrics. 4 (2): 249–256. doi:10.2307/1266622. JSTOR 1266622.
- Nelson LS (1980). "The Folded Normal Distribution". J Qual Technol. 12 (4): 236–238. doi:10.1080/00224065.1980.11980971. hdl:2027/mdp.39015095248541.
- Elandt RC (1961). "The folded normal distribution: two methods of estimating parameters from moments". Technometrics. 3 (4): 551–562. doi:10.2307/1266561. JSTOR 1266561.
- Lin PC (2005). "Application of the generalized folded-normal distribution to the process capability measures". Int J Adv Manuf Technol. 26 (7–8): 825–830. doi:10.1007/s00170-003-2043-x. S2CID 123589207.
- Psarakis, S.; Panaretos, J. (1990). "The folded t distribution". Communications in Statistics - Theory and Methods. 19 (7): 2717–2734. doi:10.1080/03610929008830342. S2CID 121332770.
- Psarakis, S.; Panaretos, J. (2001). "On some bivariate extensions of the folded normal and the folded-t distributions". Journal of Applied Statistical Science. 10 (2): 119–136.
- Chakraborty, A. K.; Chatterjee, M. (2013). "On multivariate folded normal distribution". Sankhyā: The Indian Journal of Statistics, Series B. 75 (1): 1–15. JSTOR 42003783.