Geometric distribution
In probability theory and statistics, the geometric distribution is either one of two discrete probability distributions:
- The probability distribution of the number X of Bernoulli trials needed to get one success, supported on the set ;
- The probability distribution of the number Y = X − 1 of failures before the first success, supported on the set .


|
Probability mass function 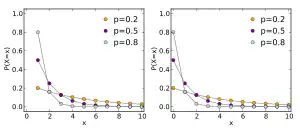 | |||
|
Cumulative distribution function 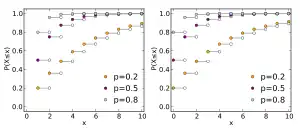 | |||
| Parameters | success probability (real) | success probability (real) | |
|---|---|---|---|
| Support | k trials where | k failures where | |
| PMF | |||
| CDF |
for , for |
for , for | |
| Mean | |||
| Median |
|
| |
| Mode | |||
| Variance | |||
| Skewness | |||
| Ex. kurtosis | |||
| Entropy | |||
| MGF |
for |
for | |
| CF | |||
| PGF | |||





























Which of these is called the geometric distribution is a matter of convention and convenience.
These two different geometric distributions should not be confused with each other. Often, the name shifted geometric distribution is adopted for the former one (distribution of the number X); however, to avoid ambiguity, it is considered wise to indicate which is intended, by mentioning the support explicitly.
The geometric distribution gives the probability that the first occurrence of success requires k independent trials, each with success probability p. If the probability of success on each trial is p, then the probability that the kth trial is the first success is

for k = 1, 2, 3, 4, ....
The above form of the geometric distribution is used for modeling the number of trials up to and including the first success. By contrast, the following form of the geometric distribution is used for modeling the number of failures until the first success:

for k = 0, 1, 2, 3, ....
In either case, the sequence of probabilities is a geometric sequence.
For example, suppose an ordinary die is thrown repeatedly until the first time a "1" appears. The probability distribution of the number of times it is thrown is supported on the infinite set { 1, 2, 3, ... } and is a geometric distribution with p = 1/6.
The geometric distribution is denoted by Geo(p) where 0 < p ≤ 1. [1]
Definitions
Consider a sequence of trials, where each trial has only two possible outcomes (designated failure and success). The probability of success is assumed to be the same for each trial. In such a sequence of trials, the geometric distribution is useful to model the number of failures before the first success since the experiment can have an indefinite number of trials until success, unlike the binomial distribution which has a set number of trials. The distribution gives the probability that there are zero failures before the first success, one failure before the first success, two failures before the first success, and so on.[2]
Assumptions: When is the geometric distribution an appropriate model?
The geometric distribution is an appropriate model if the following assumptions are true.[3]
- The phenomenon being modelled is a sequence of independent trials.
- There are only two possible outcomes for each trial, often designated success or failure.
- The probability of success, p, is the same for every trial.
If these conditions are true, then the geometric random variable Y is the count of the number of failures before the first success. The possible number of failures before the first success is 0, 1, 2, 3, and so on. In the graphs above, this formulation is shown on the right.
An alternative formulation is that the geometric random variable X is the total number of trials up to and including the first success, and the number of failures is X − 1. In the graphs above, this formulation is shown on the left.
Probability outcomes examples
The general formula to calculate the probability of k failures before the first success, where the probability of success is p and the probability of failure is q = 1 − p, is

for k = 0, 1, 2, 3, ...
E1) A doctor is seeking an antidepressant for a newly diagnosed patient. Suppose that, of the available anti-depressant drugs, the probability that any particular drug will be effective for a particular patient is p = 0.6. What is the probability that the first drug found to be effective for this patient is the first drug tried, the second drug tried, and so on? What is the expected number of drugs that will be tried to find one that is effective?
The probability that the first drug works. There are zero failures before the first success. Y = 0 failures. The probability Pr(zero failures before first success) is simply the probability that the first drug works.

The probability that the first drug fails, but the second drug works. There is one failure before the first success. Y = 1 failure. The probability for this sequence of events is Pr(first drug fails) p(second drug succeeds), which is given by


The probability that the first drug fails, the second drug fails, but the third drug works. There are two failures before the first success. Y = 2 failures. The probability for this sequence of events is Pr(first drug fails) p(second drug fails) Pr(third drug is success)

E2) A newlywed couple plans to have children and will continue until the first girl. What is the probability that there are zero boys before the first girl, one boy before the first girl, two boys before the first girl, and so on?
The probability of having a girl (success) is p= 0.5 and the probability of having a boy (failure) is q = 1 − p = 0.5.
The probability of no boys before the first girl is

The probability of one boy before the first girl is

The probability of two boys before the first girl is

and so on.
Properties
Moments and cumulants
The expected value for the number of independent trials to get the first success, and the variance of a geometrically distributed random variable X is:

Similarly, the expected value and variance of the geometrically distributed random variable Y = X - 1 (See definition of distribution ) is:


Expected value of X
Consider the expected value of X as above, i.e. the average number of trials until a success. On the first trial we either succeed with probability , or we fail with probability . If we fail the remaining mean number of trials until a success is identical to the original mean. This follows from the fact that all trials are independent. From this we get the formula:




which if solved for gives:

Expected value of Y
That the expected value of Y as above is (1 − p)/p can be shown in the following way:
![{\begin{aligned}\mathrm {E} (Y)&{}=\sum _{k=0}^{\infty }(1-p)^{k}p\cdot k\\&{}=p\sum _{k=0}^{\infty }(1-p)^{k}k\\&{}=p(1-p)\sum _{k=0}^{\infty }(1-p)^{k-1}\cdot k\\&{}=p(1-p)\left[{\frac {d}{dp}}\left(-\sum _{k=0}^{\infty }(1-p)^{k}\right)\right]\\&{}=p(1-p){\frac {d}{dp}}\left(-{\frac {1}{p}}\right)={\frac {1-p}{p}}.\end{aligned}}](../I/eed9d98386b21f65694931aa570c738cc487a952.svg)
The interchange of summation and differentiation is justified by the fact that convergent power series converge uniformly on compact subsets of the set of points where they converge.
Let μ = (1 − p)/p be the expected value of Y. Then the cumulants of the probability distribution of Y satisfy the recursion


Expected value examples
E3) A patient is waiting for a suitable matching kidney donor for a transplant. If the probability that a randomly selected donor is a suitable match is p = 0.1, what is the expected number of donors who will be tested before a matching donor is found?
With p = 0.1, the mean number of failures before the first success is E(Y) = (1 − p)/p =(1 − 0.1)/0.1 = 9.
For the alternative formulation, where X is the number of trials up to and including the first success, the expected value is E(X) = 1/p = 1/0.1 = 10.
For example 1 above, with p = 0.6, the mean number of failures before the first success is E(Y) = (1 − p)/p = (1 − 0.6)/0.6 = 0.67.
Higher-order moments
The moments for the number of failures before the first success are given by

where is the polylogarithm function.

General properties
- The probability-generating functions of X and Y are, respectively,
![{\begin{aligned}G_{X}(s)&={\frac {s\,p}{1-s\,(1-p)}},\\[10pt]G_{Y}(s)&={\frac {p}{1-s\,(1-p)}},\quad |s|<(1-p)^{-1}.\end{aligned}}](../I/e81d59e7b9c72ddc1d36e3d1514af978f56cb3a7.svg)
- Like its continuous analogue (the exponential distribution), the geometric distribution is memoryless. That is, the following holds for every m and n.
- The geometric distribution supported on {1, 2, 3, ... } is the only memoryless discrete distribution. Note that the geometric distribution supported on {0, 1, 2, ... } is not memoryless.

- Among all discrete probability distributions supported on {1, 2, 3, ... } with given expected value μ, the geometric distribution X with parameter p = 1/μ is the one with the largest entropy.[4]
- The geometric distribution of the number Y of failures before the first success is infinitely divisible, i.e., for any positive integer n, there exist independent identically distributed random variables Y1, ..., Yn whose sum has the same distribution that Y has. These will not be geometrically distributed unless n = 1; they follow a negative binomial distribution.
- The decimal digits of the geometrically distributed random variable Y are a sequence of independent (and not identically distributed) random variables. For example, the hundreds digit D has this probability distribution:
- where q = 1 − p, and similarly for the other digits, and, more generally, similarly for numeral systems with other bases than 10. When the base is 2, this shows that a geometrically distributed random variable can be written as a sum of independent random variables whose probability distributions are indecomposable.

- Golomb coding is the optimal prefix code for the geometric discrete distribution.[5]
- The sum of two independent Geo(p) distributed random variables is not a geometric distribution. [1]
Related distributions
- The geometric distribution Y is a special case of the negative binomial distribution, with r = 1. More generally, if Y1, ..., Yr are independent geometrically distributed variables with parameter p, then the sum

- follows a negative binomial distribution with parameters r and p.[6]
- The geometric distribution is a special case of discrete compound Poisson distribution.
- If Y1, ..., Yr are independent geometrically distributed variables (with possibly different success parameters pm), then their minimum
- is also geometrically distributed, with parameter [7]


- Suppose 0 < r < 1, and for k = 1, 2, 3, ... the random variable Xk has a Poisson distribution with expected value r k/k. Then

- has a geometric distribution taking values in the set {0, 1, 2, ...}, with expected value r/(1 − r).
- The exponential distribution is the continuous analogue of the geometric distribution. If X is an exponentially distributed random variable with parameter λ, then

- where is the floor (or greatest integer) function, is a geometrically distributed random variable with parameter p = 1 − e−λ (thus λ = −ln(1 − p)[8]) and taking values in the set {0, 1, 2, ...}. This can be used to generate geometrically distributed pseudorandom numbers by first generating exponentially distributed pseudorandom numbers from a uniform pseudorandom number generator: then is geometrically distributed with parameter , if is uniformly distributed in [0,1].



- If p = 1/n and X is geometrically distributed with parameter p, then the distribution of X/n approaches an exponential distribution with expected value 1 as n → ∞, since
![{\displaystyle {\begin{aligned}\Pr(X/n>a)=\Pr(X>na)&=(1-p)^{na}=\left(1-{\frac {1}{n}}\right)^{na}=\left[\left(1-{\frac {1}{n}}\right)^{n}\right]^{a}\\&\to [e^{-1}]^{a}=e^{-a}{\text{ as }}n\to \infty .\end{aligned}}}](../I/9fdd83f47032166ee398aafe41caf5ecc8b95e2e.svg)
More generally, if p = λ/n, where λ is a parameter, then as n→ ∞ the distribution of X/n approaches an exponential distribution with rate λ:

therefore the distribution function of X/n converges to , which is that of an exponential random variable.

Statistical inference
Parameter estimation
For both variants of the geometric distribution, the parameter p can be estimated by equating the expected value with the sample mean. This is the method of moments, which in this case happens to yield maximum likelihood estimates of p.[9][10]
Specifically, for the first variant let k = k1, ..., kn be a sample where ki ≥ 1 for i = 1, ..., n. Then p can be estimated as

In Bayesian inference, the Beta distribution is the conjugate prior distribution for the parameter p. If this parameter is given a Beta(α, β) prior, then the posterior distribution is

The posterior mean E[p] approaches the maximum likelihood estimate as α and β approach zero.

In the alternative case, let k1, ..., kn be a sample where ki ≥ 0 for i = 1, ..., n. Then p can be estimated as

The posterior distribution of p given a Beta(α, β) prior is[11]

Again the posterior mean E[p] approaches the maximum likelihood estimate as α and β approach zero.
For either estimate of using Maximum Likelihood, the bias is equal to
![{\displaystyle b\equiv \operatorname {E} {\bigg [}\;({\hat {p}}_{\mathrm {mle} }-p)\;{\bigg ]}={\frac {p\,(1-p)}{n}}}](../I/b5376191212d82c6747c9da455f9ca65abd7129e.svg)
which yields the bias-corrected maximum likelihood estimator

Computational methods
Geometric distribution using R
The R function dgeom(k, prob) calculates the probability that there are k failures before the first success, where the argument "prob" is the probability of success on each trial.
For example,
dgeom(0,0.6) = 0.6
dgeom(1,0.6) = 0.24
R uses the convention that k is the number of failures, so that the number of trials up to and including the first success is k + 1.
The following R code creates a graph of the geometric distribution from Y = 0 to 10, with p = 0.6.
Y=0:10
plot(Y, dgeom(Y,0.6), type="h", ylim=c(0,1), main="Geometric distribution for p=0.6", ylab="Pr(Y=Y)", xlab="Y=Number of failures before first success")
Geometric distribution using Excel
The geometric distribution, for the number of failures before the first success, is a special case of the negative binomial distribution, for the number of failures before s successes.
The Excel function NEGBINOMDIST(number_f, number_s, probability_s) calculates the probability of k = number_f failures before s = number_s successes where p = probability_s is the probability of success on each trial. For the geometric distribution, let number_s = 1 success.[12]
For example,
=NEGBINOMDIST(0, 1, 0.6)= 0.6
=NEGBINOMDIST(1, 1, 0.6)= 0.24
Like R, Excel uses the convention that k is the number of failures, so that the number of trials up to and including the first success is k + 1.
See also
References
- A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. pp. 48–50, 61–62, 152. ISBN 9781852338961. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - Holmes, Alexander; Illowsky, Barbara; Dean, Susan (29 November 2017). Introductory Business Statistics. Houston, Texas: OpenStax.
- Raikar, Sanat Pai (31 August 2023). "Geometric distribution". Encyclopedia Britannica.
- Park, Sung Y.; Bera, Anil K. (June 2009). "Maximum entropy autoregressive conditional heteroskedasticity model". Journal of Econometrics. 150 (2): 219–230. doi:10.1016/j.jeconom.2008.12.014.
- Gallager, R.; van Voorhis, D. (March 1975). "Optimal source codes for geometrically distributed integer alphabets (Corresp.)". IEEE Transactions on Information Theory. 21 (2): 228–230. doi:10.1109/TIT.1975.1055357. ISSN 0018-9448.
- Pitman, Jim. Probability (1993 edition). Springer Publishers. pp 372.
- Ciardo, Gianfranco; Leemis, Lawrence M.; Nicol, David (1 June 1995). "On the minimum of independent geometrically distributed random variables". Statistics & Probability Letters. 23 (4): 313–326. doi:10.1016/0167-7152(94)00130-Z. S2CID 1505801.
- "Wolfram-Alpha: Computational Knowledge Engine". www.wolframalpha.com.
- casella, george; berger, roger l (2002). statistical inference (2nd ed.). pp. 312–315. ISBN 0-534-24312-6.
- "MLE Examples: Exponential and Geometric Distributions Old Kiwi - Rhea". www.projectrhea.org. Retrieved 2019-11-17.
- "3. Conjugate families of distributions" (PDF). Archived (PDF) from the original on 2010-04-08.
- "3.5 Geometric Probability Distribution using Excel Spreadsheet". Statistics LibreTexts. 2021-07-24. Retrieved 2023-10-20.