Pareto distribution
The Pareto distribution, named after the Italian civil engineer, economist, and sociologist Vilfredo Pareto,[1] is a power-law probability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population.[2][3] The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value (α) of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena[4] and human activities.[5][6]
|
Probability density function 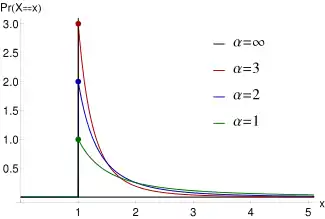 Pareto Type I probability density functions for various with As the distribution approaches where is the Dirac delta function. | |||
|
Cumulative distribution function 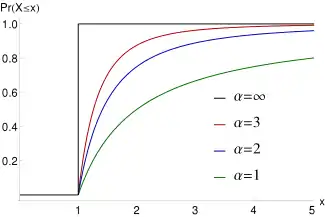 Pareto Type I cumulative distribution functions for various with | |||
| Parameters |
scale (real) shape (real) | ||
|---|---|---|---|
| Support | |||
| CDF | |||
| Quantile | |||
| Mean | |||
| Median | |||
| Mode | |||
| Variance | |||
| Skewness | |||
| Ex. kurtosis | |||
| Entropy | |||
| MGF | does not exist | ||
| CF | |||
| Fisher information |
Right: | ||












![x_\mathrm{m} \sqrt[\alpha]{2}](../I/ef1a9e02a1d60cf9cd611b13188b078509904bc7.svg)








Definitions
If X is a random variable with a Pareto (Type I) distribution,[7] then the probability that X is greater than some number x, i.e., the survival function (also called tail function), is given by

where xm is the (necessarily positive) minimum possible value of X, and α is a positive parameter. The type I Pareto distribution is characterized by a scale parameter xm and a shape parameter α, which is known as the tail index. If this distribution is used to model the distribution of wealth, then the parameter α is called the Pareto index.
Cumulative distribution function
From the definition, the cumulative distribution function of a Pareto random variable with parameters α and xm is

Probability density function
It follows (by differentiation) that the probability density function is

When plotted on linear axes, the distribution assumes the familiar J-shaped curve which approaches each of the orthogonal axes asymptotically. All segments of the curve are self-similar (subject to appropriate scaling factors). When plotted in a log-log plot, the distribution is represented by a straight line.
Properties
Moments and characteristic function
- The expected value of a random variable following a Pareto distribution is

- The variance of a random variable following a Pareto distribution is
![{\displaystyle \operatorname {Var} (X)={\begin{cases}\infty &\alpha \in (1,2],\\\left({\frac {x_{\mathrm {m} }}{\alpha -1}}\right)^{2}{\frac {\alpha }{\alpha -2}}&\alpha >2.\end{cases}}}](../I/bda6ae1a69ab2c130545abd2053226a4d6510558.svg)
- (If α ≤ 1, the variance does not exist.)
- The raw moments are

- The moment generating function is only defined for non-positive values t ≤ 0 as
![{\displaystyle M\left(t;\alpha ,x_{\mathrm {m} }\right)=\operatorname {E} \left[e^{tX}\right]=\alpha (-x_{\mathrm {m} }t)^{\alpha }\Gamma (-\alpha ,-x_{\mathrm {m} }t)}](../I/0b03963721b9c85e5030aa7a26056af4ef07a4e4.svg)

Thus, since the expectation does not converge on an open interval containing we say that the moment generating function does not exist.

- The characteristic function is given by

- where Γ(a, x) is the incomplete gamma function.
The parameters may be solved for using the method of moments.[8]
Conditional distributions
The conditional probability distribution of a Pareto-distributed random variable, given the event that it is greater than or equal to a particular number exceeding , is a Pareto distribution with the same Pareto index but with minimum instead of . This implies that the conditional expected value (if it is finite, i.e. ) is proportional to . In case of random variables that describe the lifetime of an object, this means that life expectancy is proportional to age, and is called the Lindy effect or Lindy's Law.[9]



A characterization theorem
Suppose are independent identically distributed random variables whose probability distribution is supported on the interval for some . Suppose that for all , the two random variables and are independent. Then the common distribution is a Pareto distribution.








Graphical representation
The characteristic curved 'long tail' distribution, when plotted on a linear scale, masks the underlying simplicity of the function when plotted on a log-log graph, which then takes the form of a straight line with negative gradient: It follows from the formula for the probability density function that for x ≥ xm,

Since α is positive, the gradient −(α + 1) is negative.
Related distributions
Generalized Pareto distributions
There is a hierarchy [7][11] of Pareto distributions known as Pareto Type I, II, III, IV, and Feller–Pareto distributions.[7][11][12] Pareto Type IV contains Pareto Type I–III as special cases. The Feller–Pareto[11][13] distribution generalizes Pareto Type IV.
Pareto types I–IV
The Pareto distribution hierarchy is summarized in the next table comparing the survival functions (complementary CDF).
When μ = 0, the Pareto distribution Type II is also known as the Lomax distribution.[14]
In this section, the symbol xm, used before to indicate the minimum value of x, is replaced by σ.
| Support | Parameters | ||
|---|---|---|---|
| Type I | |||
| Type II | |||
| Lomax | |||
| Type III | |||
| Type IV | |||

![{\displaystyle \left[{\frac {x}{\sigma }}\right]^{-\alpha }}](../I/debc11c1d4259755203a2e95e5171e4b2c28b695.svg)


![{\displaystyle \left[1+{\frac {x-\mu }{\sigma }}\right]^{-\alpha }}](../I/c1c05d4c866664355381925ebc7f1d6854a8b4b2.svg)


![{\displaystyle \left[1+{\frac {x}{\sigma }}\right]^{-\alpha }}](../I/b5f6d8660cc815594ad3f6fbbba08e57eaa4bf12.svg)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma }}\right)^{1/\gamma }\right]^{-1}}](../I/08d45a24039951a4a164feb7f48ee05c3b852a28.svg)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma }}\right)^{1/\gamma }\right]^{-\alpha }}](../I/a95750fc2c1674af87b4f4d3115af6dbf9728743.svg)

The shape parameter α is the tail index, μ is location, σ is scale, γ is an inequality parameter. Some special cases of Pareto Type (IV) are



The finiteness of the mean, and the existence and the finiteness of the variance depend on the tail index α (inequality index γ). In particular, fractional δ-moments are finite for some δ > 0, as shown in the table below, where δ is not necessarily an integer.
| Condition | Condition | |||
|---|---|---|---|---|
| Type I | ||||
| Type II | ||||
| Type III | ||||
| Type IV | ||||
![\operatorname {E} [X]](../I/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93.svg)
![{\displaystyle \operatorname {E} [X^{\delta }]}](../I/fab8f72a2621c18717c6afbb3a3772ca30a36b4d.svg)














Feller–Pareto distribution
Feller[11][13] defines a Pareto variable by transformation U = Y−1 − 1 of a beta random variable ,Y, whose probability density function is

where B( ) is the beta function. If

then W has a Feller–Pareto distribution FP(μ, σ, γ, γ1, γ2).[7]
If and are independent Gamma variables, another construction of a Feller–Pareto (FP) variable is[15]



and we write W ~ FP(μ, σ, γ, δ1, δ2). Special cases of the Feller–Pareto distribution are




Inverse-Pareto Distribution / Power Distribution
When a random variable follows a pareto distribution, then its inverse follows an Inverse Pareto distribution. Inverse Pareto distribution is equivalent to a Power distribution[16]



Relation to the exponential distribution
The Pareto distribution is related to the exponential distribution as follows. If X is Pareto-distributed with minimum xm and index α, then

is exponentially distributed with rate parameter α. Equivalently, if Y is exponentially distributed with rate α, then

is Pareto-distributed with minimum xm and index α.
This can be shown using the standard change-of-variable techniques:

The last expression is the cumulative distribution function of an exponential distribution with rate α.
Pareto distribution can be constructed by hierarchical exponential distributions.[17] Let and . Then we have and, as a result, .




More in general, if (shape-rate parametrization) and , then .



Equivalently, if and , then .



Relation to the log-normal distribution
The Pareto distribution and log-normal distribution are alternative distributions for describing the same types of quantities. One of the connections between the two is that they are both the distributions of the exponential of random variables distributed according to other common distributions, respectively the exponential distribution and normal distribution. (See the previous section.)
Relation to the generalized Pareto distribution
The Pareto distribution is a special case of the generalized Pareto distribution, which is a family of distributions of similar form, but containing an extra parameter in such a way that the support of the distribution is either bounded below (at a variable point), or bounded both above and below (where both are variable), with the Lomax distribution as a special case. This family also contains both the unshifted and shifted exponential distributions.
The Pareto distribution with scale and shape is equivalent to the generalized Pareto distribution with location , scale and shape and, conversely, one can get the Pareto distribution from the GPD by taking and if .







Bounded Pareto distribution
| Parameters |
location (real) | ||
|---|---|---|---|
| Support | |||
| CDF | |||
| Mean |
| ||
| Median | |||
| Variance |
(this is the second raw moment, not the variance) | ||
| Skewness |
(this is the kth raw moment, not the skewness) | ||











The bounded (or truncated) Pareto distribution has three parameters: α, L and H. As in the standard Pareto distribution α determines the shape. L denotes the minimal value, and H denotes the maximal value.
The probability density function is
- ,
where L ≤ x ≤ H, and α > 0.
Generating bounded Pareto random variables
If U is uniformly distributed on (0, 1), then applying inverse-transform method [18]


is a bounded Pareto-distributed.
Symmetric Pareto distribution
The purpose of the Symmetric and Zero Symmetric Pareto distributions is to capture some special statistical distribution with a sharp probability peak and symmetric long probability tails. These two distributions are derived from the Pareto distribution. Long probability tails normally means that probability decays slowly, and can be used to fit a variety of datasets. But if the distribution has symmetric structure with two slow decaying tails, Pareto could not do it. Then Symmetric Pareto or Zero Symmetric Pareto distribution is applied instead.[19]
The Cumulative distribution function (CDF) of Symmetric Pareto distribution is defined as following:[19]

The corresponding probability density function (PDF) is:[19]

This distribution has two parameters: a and b. It is symmetric by b. Then the mathematic expectation is b. When, it has variance as following:

The CDF of Zero Symmetric Pareto (ZSP) distribution is defined as following:

The corresponding PDF is:

This distribution is symmetric by zero. Parameter a is related to the decay rate of probability and (a/2b) represents peak magnitude of probability.[19]
Multivariate Pareto distribution
The univariate Pareto distribution has been extended to a multivariate Pareto distribution.[20]
Statistical inference
Estimation of parameters
The likelihood function for the Pareto distribution parameters α and xm, given an independent sample x = (x1, x2, ..., xn), is

Therefore, the logarithmic likelihood function is

It can be seen that is monotonically increasing with xm, that is, the greater the value of xm, the greater the value of the likelihood function. Hence, since x ≥ xm, we conclude that


To find the estimator for α, we compute the corresponding partial derivative and determine where it is zero:

Thus the maximum likelihood estimator for α is:

The expected statistical error is:[21]

Malik (1970)[22] gives the exact joint distribution of . In particular, and are independent and is Pareto with scale parameter xm and shape parameter nα, whereas has an inverse-gamma distribution with shape and scale parameters n − 1 and nα, respectively.



Occurrence and applications
General
Vilfredo Pareto originally used this distribution to describe the allocation of wealth among individuals since it seemed to show rather well the way that a larger portion of the wealth of any society is owned by a smaller percentage of the people in that society. He also used it to describe distribution of income.[3] This idea is sometimes expressed more simply as the Pareto principle or the "80-20 rule" which says that 20% of the population controls 80% of the wealth.[23] As Michael Hudson points out (The Collapse of Antiquity [2023] p. 85 & n.7) "a mathematical corollary [is] that 10% would have 65% of the wealth, and 5% would have half the national wealth.” However, the 80-20 rule corresponds to a particular value of α, and in fact, Pareto's data on British income taxes in his Cours d'économie politique indicates that about 30% of the population had about 70% of the income. The probability density function (PDF) graph at the beginning of this article shows that the "probability" or fraction of the population that owns a small amount of wealth per person is rather high, and then decreases steadily as wealth increases. (The Pareto distribution is not realistic for wealth for the lower end, however. In fact, net worth may even be negative.) This distribution is not limited to describing wealth or income, but to many situations in which an equilibrium is found in the distribution of the "small" to the "large". The following examples are sometimes seen as approximately Pareto-distributed:
- The sizes of human settlements (few cities, many hamlets/villages)[24][25]
- File size distribution of Internet traffic which uses the TCP protocol (many smaller files, few larger ones)[24]
- Hard disk drive error rates[26]
- Clusters of Bose–Einstein condensate near absolute zero[27]
- The values of oil reserves in oil fields (a few large fields, many small fields)[24]
- The length distribution in jobs assigned to supercomputers (a few large ones, many small ones)[28]
- The standardized price returns on individual stocks [24]
- Sizes of sand particles [24]
- The size of meteorites
- Severity of large casualty losses for certain lines of business such as general liability, commercial auto, and workers compensation.[29][30]
- Amount of time a user on Steam will spend playing different games. (Some games get played a lot, but most get played almost never.)
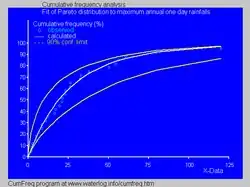
- In hydrology the Pareto distribution is applied to extreme events such as annually maximum one-day rainfalls and river discharges.[31] The blue picture illustrates an example of fitting the Pareto distribution to ranked annually maximum one-day rainfalls showing also the 90% confidence belt based on the binomial distribution. The rainfall data are represented by plotting positions as part of the cumulative frequency analysis.
- In Electric Utility Distribution Reliability (80% of the Customer Minutes Interrupted occur on approximately 20% of the days in a given year).
Relation to Zipf's law
The Pareto distribution is a continuous probability distribution. Zipf's law, also sometimes called the zeta distribution, is a discrete distribution, separating the values into a simple ranking. Both are a simple power law with a negative exponent, scaled so that their cumulative distributions equal 1. Zipf's can be derived from the Pareto distribution if the values (incomes) are binned into ranks so that the number of people in each bin follows a 1/rank pattern. The distribution is normalized by defining so that where is the generalized harmonic number. This makes Zipf's probability density function derivable from Pareto's.





where and is an integer representing rank from 1 to N where N is the highest income bracket. So a randomly selected person (or word, website link, or city) from a population (or language, internet, or country) has probability of ranking .


Relation to the "Pareto principle"
The "80–20 law", according to which 20% of all people receive 80% of all income, and 20% of the most affluent 20% receive 80% of that 80%, and so on, holds precisely when the Pareto index is . This result can be derived from the Lorenz curve formula given below. Moreover, the following have been shown[32] to be mathematically equivalent:

- Income is distributed according to a Pareto distribution with index α > 1.
- There is some number 0 ≤ p ≤ 1/2 such that 100p % of all people receive 100(1 − p)% of all income, and similarly for every real (not necessarily integer) n > 0, 100pn % of all people receive 100(1 − p)n percentage of all income. α and p are related by

This does not apply only to income, but also to wealth, or to anything else that can be modeled by this distribution.
This excludes Pareto distributions in which 0 < α ≤ 1, which, as noted above, have an infinite expected value, and so cannot reasonably model income distribution.
Relation to Price's law
Price's square root law is sometimes offered as a property of or as similar to the Pareto distribution. However, the law only holds in the case that . Note that in this case, the total and expected amount of wealth are not defined, and the rule only applies asymptotically to random samples. The extended Pareto Principle mentioned above is a far more general rule.

Lorenz curve and Gini coefficient
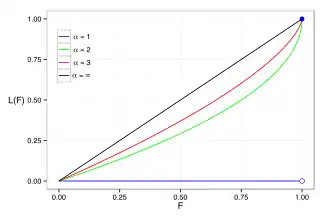
The Lorenz curve is often used to characterize income and wealth distributions. For any distribution, the Lorenz curve L(F) is written in terms of the PDF f or the CDF F as

where x(F) is the inverse of the CDF. For the Pareto distribution,

and the Lorenz curve is calculated to be

For the denominator is infinite, yielding L=0. Examples of the Lorenz curve for a number of Pareto distributions are shown in the graph on the right.

According to Oxfam (2016) the richest 62 people have as much wealth as the poorest half of the world's population.[33] We can estimate the Pareto index that would apply to this situation. Letting ε equal we have:


or

The solution is that α equals about 1.15, and about 9% of the wealth is owned by each of the two groups. But actually the poorest 69% of the world adult population owns only about 3% of the wealth.[34]
The Gini coefficient is a measure of the deviation of the Lorenz curve from the equidistribution line which is a line connecting [0, 0] and [1, 1], which is shown in black (α = ∞) in the Lorenz plot on the right. Specifically, the Gini coefficient is twice the area between the Lorenz curve and the equidistribution line. The Gini coefficient for the Pareto distribution is then calculated (for ) to be


(see Aaberge 2005).
Random variate generation
Random samples can be generated using inverse transform sampling. Given a random variate U drawn from the uniform distribution on the unit interval (0, 1], the variate T given by

is Pareto-distributed.[35] If U is uniformly distributed on [0, 1), it can be exchanged with (1 − U).
See also
- Bradford's law – Pattern of references in science journals
- Gutenberg–Richter law – Law in seismology describing earthquake frequency and magnitude
- Matthew effect – The rich get richer and the poor get poorer
- Pareto analysis – Statistical concept
- Pareto efficiency – Concept in studies of efficiency
- Pareto interpolation
- Power law probability distributions – Functional relationship between two quantities
- Sturgeon's law – "Ninety percent of everything is crap"
- Traffic generation model – simulated flow of data in a communications network
- Zipf's law – Probability distribution
- Heavy-tailed distribution – Probability distribution
References
- Amoroso, Luigi (1938). "VILFREDO PARETO". Econometrica (Pre-1986); Jan 1938; 6, 1; ProQuest. 6.
- Pareto, Vilfredo (1898). "Cours d'economie politique". Journal of Political Economy. 6. doi:10.1086/250536.
- Pareto, Vilfredo, Cours d'Économie Politique: Nouvelle édition par G.-H. Bousquet et G. Busino, Librairie Droz, Geneva, 1964, pp. 299–345. Original book archived
- VAN MONTFORT, M.A.J. (1986). "The Generalized Pareto distribution applied to rainfall depths". Hydrological Sciences Journal. 31 (2): 151–162. doi:10.1080/02626668609491037.
- Oancea, Bogdan (2017). "Income inequality in Romania: The exponential-Pareto distribution". Physica A: Statistical Mechanics and Its Applications. 469: 486–498. Bibcode:2017PhyA..469..486O. doi:10.1016/j.physa.2016.11.094.
- Morella, Matteo. "Pareto Distribution". academia.edu.
- Barry C. Arnold (1983). Pareto Distributions. International Co-operative Publishing House. ISBN 978-0-89974-012-6.
- S. Hussain, S.H. Bhatti (2018). Parameter estimation of Pareto distribution: Some modified moment estimators. Maejo International Journal of Science and Technology 12(1):11-27.
- Eliazar, Iddo (November 2017). "Lindy's Law". Physica A: Statistical Mechanics and Its Applications. 486: 797–805. Bibcode:2017PhyA..486..797E. doi:10.1016/j.physa.2017.05.077. S2CID 125349686.
- Johnson NL, Kotz S, Balakrishnan N (1994) Continuous univariate distributions Vol 1. Wiley Series in Probability and Statistics.
- Johnson, Kotz, and Balakrishnan (1994), (20.4).
- Christian Kleiber & Samuel Kotz (2003). Statistical Size Distributions in Economics and Actuarial Sciences. Wiley. ISBN 978-0-471-15064-0.
- Feller, W. (1971). An Introduction to Probability Theory and its Applications. Vol. II (2nd ed.). New York: Wiley. p. 50. "The densities (4.3) are sometimes called after the economist Pareto. It was thought (rather naïvely from a modern statistical standpoint) that income distributions should have a tail with a density ~ Ax−α as x → ∞".
- Lomax, K. S. (1954). "Business failures. Another example of the analysis of failure data". Journal of the American Statistical Association. 49 (268): 847–52. doi:10.1080/01621459.1954.10501239.
- Chotikapanich, Duangkamon (16 September 2008). "Chapter 7: Pareto and Generalized Pareto Distributions". Modeling Income Distributions and Lorenz Curves. pp. 121–22. ISBN 9780387727967.
- Dallas, A. C. "Characterizing the Pareto and power distributions." Annals of the Institute of Statistical Mathematics 28.1 (1976): 491-497.
- White, Gentry (2006). Bayesian semiparametric spatial and joint spatio-temporal modeling (Thesis thesis). University of Missouri--Columbia. section 5.3.1.
- "Inverse Transform Method". Archived from the original on 2012-01-17. Retrieved 2012-08-27.
- Huang, Xiao-dong (2004). "A Multiscale Model for MPEG-4 Varied Bit Rate Video Traffic". IEEE Transactions on Broadcasting. 50 (3): 323–334. doi:10.1109/TBC.2004.834013.
- Rootzén, Holger; Tajvidi, Nader (2006). "Multivariate generalized Pareto distributions". Bernoulli. 12 (5): 917–30. CiteSeerX 10.1.1.145.2991. doi:10.3150/bj/1161614952. S2CID 16504396.
- M. E. J. Newman (2005). "Power laws, Pareto distributions and Zipf's law". Contemporary Physics. 46 (5): 323–51. arXiv:cond-mat/0412004. Bibcode:2005ConPh..46..323N. doi:10.1080/00107510500052444. S2CID 202719165.
- H. J. Malik (1970). "Estimation of the Parameters of the Pareto Distribution". Metrika. 15: 126–132. doi:10.1007/BF02613565. S2CID 124007966.
- For a two-quantile population, where approximately 18% of the population owns 82% of the wealth, the Theil index takes the value 1.
- Reed, William J.; et al. (2004). "The Double Pareto-Lognormal Distribution – A New Parametric Model for Size Distributions". Communications in Statistics – Theory and Methods. 33 (8): 1733–53. CiteSeerX 10.1.1.70.4555. doi:10.1081/sta-120037438. S2CID 13906086.
- Reed, William J. (2002). "On the rank‐size distribution for human settlements". Journal of Regional Science. 42 (1): 1–17. doi:10.1111/1467-9787.00247. S2CID 154285730.
- Schroeder, Bianca; Damouras, Sotirios; Gill, Phillipa (2010-02-24). "Understanding latent sector error and how to protect against them" (PDF). 8th Usenix Conference on File and Storage Technologies (FAST 2010). Retrieved 2010-09-10.
We experimented with 5 different distributions (Geometric, Weibull, Rayleigh, Pareto, and Lognormal), that are commonly used in the context of system reliability, and evaluated their fit through the total squared differences between the actual and hypothesized frequencies (χ2 statistic). We found consistently across all models that the geometric distribution is a poor fit, while the Pareto distribution provides the best fit.
- Yuji Ijiri; Simon, Herbert A. (May 1975). "Some Distributions Associated with Bose–Einstein Statistics". Proc. Natl. Acad. Sci. USA. 72 (5): 1654–57. Bibcode:1975PNAS...72.1654I. doi:10.1073/pnas.72.5.1654. PMC 432601. PMID 16578724.
- Harchol-Balter, Mor; Downey, Allen (August 1997). "Exploiting Process Lifetime Distributions for Dynamic Load Balancing" (PDF). ACM Transactions on Computer Systems. 15 (3): 253–258. doi:10.1145/263326.263344. S2CID 52861447.
- Kleiber and Kotz (2003): p. 94.
- Seal, H. (1980). "Survival probabilities based on Pareto claim distributions". ASTIN Bulletin. 11: 61–71. doi:10.1017/S0515036100006620.
- CumFreq, software for cumulative frequency analysis and probability distribution fitting
- Hardy, Michael (2010). "Pareto's Law". Mathematical Intelligencer. 32 (3): 38–43. doi:10.1007/s00283-010-9159-2. S2CID 121797873.
- "62 people own the same as half the world, reveals Oxfam Davos report". Oxfam. Jan 2016.
- "Global Wealth Report 2013". Credit Suisse. Oct 2013. p. 22. Archived from the original on 2015-02-14. Retrieved 2016-01-24.
- Tanizaki, Hisashi (2004). Computational Methods in Statistics and Econometrics. CRC Press. p. 133. ISBN 9780824750886.
Notes
- M. O. Lorenz (1905). "Methods of measuring the concentration of wealth". Publications of the American Statistical Association. 9 (70): 209–19. Bibcode:1905PAmSA...9..209L. doi:10.2307/2276207. JSTOR 2276207. S2CID 154048722.
- Pareto, Vilfredo (1965). Librairie Droz (ed.). Ecrits sur la courbe de la répartition de la richesse. Œuvres complètes : T. III. p. 48. ISBN 9782600040211.
- Pareto, Vilfredo (1895). "La legge della domanda". Giornale Degli Economisti. 10: 59–68.
- Pareto, Vilfredo (1896). "Cours d'économie politique". doi:10.1177/000271629700900314. S2CID 143528002.
{{cite journal}}: Cite journal requires|journal=(help)
External links
- "Pareto distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. "Pareto distribution". MathWorld.
- Aabergé, Rolf (May 2005). "Gini's Nuclear Family". International Conference to Honor Two Eminent Social Scientists (PDF).
- Crovella, Mark E.; Bestavros, Azer (December 1997). Self-Similarity in World Wide Web Traffic: Evidence and Possible Causes (PDF). IEEE/ACM Transactions on Networking. Vol. 5. pp. 835–846. Archived from the original (PDF) on 2016-03-04. Retrieved 2019-02-25.
- syntraf1.c is a C program to generate synthetic packet traffic with bounded Pareto burst size and exponential interburst time.