Generalized logistic distribution
The term generalized logistic distribution is used as the name for several different families of probability distributions. For example, Johnson et al.[1] list four forms, which are listed below.
Type I has also been called the skew-logistic distribution. Type IV subsumes the other types and is obtained when applying the logit transform to beta random variates. Following the same convention as for the log-normal distribution, type IV may be referred to as the logistic-beta distribution, with reference to the standard logistic function, which is the inverse of the logit transform.
For other families of distributions that have also been called generalized logistic distributions, see the shifted log-logistic distribution, which is a generalization of the log-logistic distribution; and the metalog ("meta-logistic") distribution, which is highly shape-and-bounds flexible and can be fit to data with linear least squares.
Definitions
The following definitions are for standardized versions of the families, which can be expanded to the full form as a location-scale family. Each is defined using either the cumulative distribution function (F) or the probability density function (ƒ), and is defined on (-∞,∞).
Type I

The corresponding probability density function is:

This type has also been called the "skew-logistic" distribution.
Type II

The corresponding probability density function is:

Type III

Here B is the beta function. The moment generating function for this type is

The corresponding cumulative distribution function is:

Type IV
![{\displaystyle {\begin{aligned}f(x;\alpha ,\beta )&={\frac {1}{B(\alpha ,\beta )}}{\frac {e^{-\beta x}}{(1+e^{-x})^{\alpha +\beta }}},\quad \alpha ,\beta >0\\[4pt]&={\frac {\sigma (x)^{\alpha }\sigma (-x)^{\beta }}{B(\alpha ,\beta )}}.\end{aligned}}}](../I/dde2f594badb97b515aaeab56c39c71a5f024524.svg)
Where, B is the beta function and is the standard logistic function. The moment generating function for this type is


This type is also called the "exponential generalized beta of the second type".[1]
The corresponding cumulative distribution function is:

Relationship between types
Type IV is the most general form of the distribution. The Type III distribution can be obtained from Type IV by fixing . The Type II distribution can be obtained from Type IV by fixing (and renaming to ). The Type I distribution can be obtained from Type IV by fixing . Fixing gives the standard logistic distribution.






Type IV (logistic-beta) properties
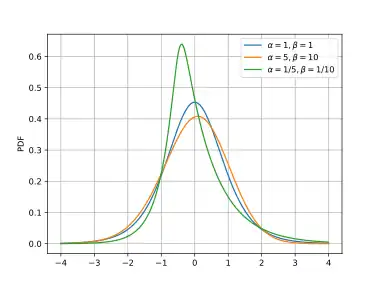
The Type IV generalized logistic, or logistic-beta distribution, with support and shape parameters , has (as shown above) the probability density function (pdf):



where is the standard logistic function. The probability density functions for three different sets of shape parameters are shown in the plot, where the distributions have been scaled and shifted to give zero means and unity variances, in order to facilitate comparison of the shapes.
In what follows, the notation is used to denote the Type IV distribution.

Relationship with Gamma Distribution
This distribution can be obtained in terms of the gamma distribution as follows. Let and independently, and let . Then .[2]




Symmetry
If , then .

Mean and variance
By using the logarithmic expectations of the gamma distribution, the mean and variance can be derived as:
![{\displaystyle {\begin{aligned}{\text{E}}[x]&=\psi (\alpha )-\psi (\beta )\\{\text{var}}[x]&=\psi '(\alpha )+\psi '(\beta )\\\end{aligned}}}](../I/68064330be9b2a11b6bf24f6bca5537b1f9b24dc.svg)
where is the digamma function, while is its first derivative, also known as the trigamma function, or the first polygamma function. Since is strictly increasing, the sign of the mean is the same as the sign of . Since is strictly decreasing, the shape parameters can also be interpreted as concentration parameters. Indeed, as shown below, the left and right tails respectively become thinner as or are increased. The two terms of the variance represent the contributions to the variance of the left and right parts of the distribution.




Cumulants and skewness
The cumulant generating function is , where the moment generating function is given above. The cumulants, , are the -th derivatives of , evaluated at :







where and are the digamma and polygamma functions. In agreement with the derivation above, the first cumulant, , is the mean and the second, , is the variance.




The third cumulant, , is the third central moment , which when scaled by the third power of the standard deviation gives the skewness:

![{\displaystyle E[(x-E[x])^{3}]}](../I/a06437668d92337b4033164e3043e766461b8b3d.svg)
![{\displaystyle {\text{skew}}[x]={\frac {\psi ^{(2)}(\alpha )-\psi ^{(2)}(\beta )}{{\sqrt {{\text{var}}[x]}}^{3}}}}](../I/b4022d86e006fff45896deb99fe404689289d9dd.svg)
The sign (and therefore the handedness) of the skewness is the same as the sign of .
Mode
The mode (pdf maximum) can be derived by finding where the log pdf derivative is zero:


This simplifies to , so that:[2]

![{\displaystyle {\text{mode}}[x]=\ln {\frac {\alpha }{\beta }}}](../I/20d03be601a3e04a9870bc8c3d6accd9f752e78b.svg)
Tail behaviour
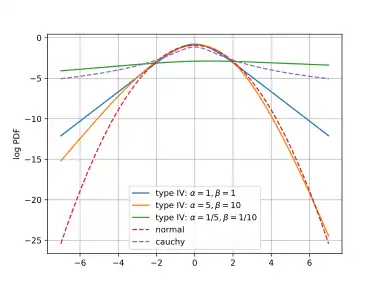
In each of the left and right tails, one of the sigmoids in the pdf saturates to one, so that the tail is formed by the other sigmoid. For large negative , the left tail of the pdf is proportional to , while the right tail (large positive ) is proportional to . This means the tails are independently controlled by and . Although type IV tails are heavier than those of the normal distribution (, for variance ), the type IV means and variances remain finite for all . This is in contrast with the Cauchy distribution for which the mean and variance do not exist. In the log pdf plots shown here, the type IV tails are linear, the normal distribution tails are quadratic and the Cauchy tails are logarithmic.




Exponential family properties
forms an exponential family with natural parameters and and sufficient statistics and . The expected values of the sufficient statistics can be found by differentiation of the log-normalizer:[3]


![{\displaystyle {\begin{aligned}E[\log \sigma (x)]&={\frac {\partial \log B(\alpha ,\beta )}{\partial \alpha }}=\psi (\alpha )-\psi (\alpha +\beta )\\E[\log \sigma (-x)]&={\frac {\partial \log B(\alpha ,\beta )}{\partial \beta }}=\psi (\beta )-\psi (\alpha +\beta )\\\end{aligned}}}](../I/2a9a058de74cb42622526627b4f0ad274607d001.svg)
Given a data set assumed to have been generated IID from , the maximum-likelihood parameter estimate is:


where the overlines denote the averages of the sufficient statistics. The maximum-likelihood estimate depends on the data only via these average statistics. Indeed, at the maximum-likelihood estimate the expected values and averages agree:

which is also where the partial derivatives of the above maximand vanish.
Relationships with other distributions
Relationships with other distributions include:
- The log-ratio of gamma variates is of type IV as detailed above.
- If , then has a type IV distribution, with parameters and . See beta prime distribution.
- If and , where is used as the rate parameter of the second gamma distribution, then has a compound gamma distribution, which is the same as , so that has a type IV distribution.
- If , then has a type IV distribution, with parameters and . See beta distribution. The logit function, is the inverse of the logistic function. This relationship explains the name logistic-beta for this distribution: if the logistic function is applied to logistic-beta variates, the transformed distribution is beta.










Large shape parameters


For large values of the shape parameters, , the distribution becomes more Gaussian, with:

![{\displaystyle {\begin{aligned}E[x]&\approx \ln {\frac {\alpha }{\beta }}\\{\text{var}}[x]&\approx {\frac {\alpha +\beta }{\alpha \beta }}\end{aligned}}}](../I/940766da1e5b2453b754b1918863e21daa62a7e5.svg)
This is demonstrated in the pdf and log pdf plots here.
Random variate generation
Since random sampling from the gamma and beta distributions are readily available on many software platforms, the above relationships with those distributions can be used to generate variates from the type IV distribution.
Generalization with location and scale parameters
A flexible, four-parameter family can be obtained by adding location and scale parameters. One way to do this is if , then let , where is the scale parameter and is the location parameter. The four-parameter family obtained thus has the desired additional flexibility, but the new parameters may be hard to interpret because and . Moreover maximum-likelihood estimation with this parametrization is hard. These problems can be addressed as follows.



![{\displaystyle \delta \neq E[y]}](../I/c78f9b8549795d5c1e854c850fe319797d6aec65.svg)
![{\displaystyle k^{2}\neq {\text{var}}[y]}](../I/1eae619c0768b6be23d90d5735053dd988e64dda.svg)
Recall that the mean and variance of are:

Now expand the family with location parameter and scale parameter , via the transformation:



so that and are now interpretable. It may be noted that allowing to be either positive or negative does not generalize this family, because of the above-noted symmetry property. We adopt the notation for this family.
![{\displaystyle \mu =E[y]}](../I/003fd6897115e1dae8ee31d2e6186b54eb736c13.svg)
![{\displaystyle s^{2}={\text{var}}[y]}](../I/d9280da3026a1485c301a98df8d2f22840cbac7e.svg)


If the pdf for is , then the pdf for is:


where it is understood that is computed as detailed above, as a function of . The pdf and log-pdf plots above, where the captions contain (means=0, variances=1), are for .


Maximum likelihood parameter estimation
In this section, maximum-likelihood estimation of the distribution parameters, given a dataset is discussed in turn for the families and .

Maximum likelihood for standard Type IV
As noted above, is an exponential family with natural parameters , the maximum-likelihood estimates of which depend only on averaged sufficient statistics:

Once these statistics have been accumulated, the maximum-likelihood estimate is given by:

By using the parametrization and an unconstrained numerical optimization algorithm like BFGS can be used. Optimization iterations are fast, because they are independent of the size of the data-set.


An alternative is to use an EM-algorithm based on the composition: if and . Because of the self-conjugacy of the gamma distribution, the posterior expectations, and that are required for the E-step can be computed in closed form. The M-step parameter update can be solved analogously to maximum-likelihood for the gamma distribution.




Maximum likelihood for the four-parameter family
The maximum-likelihood problem for , having pdf is:


This is no longer an exponential family, so that each optimization iteration has to traverse the whole data-set. Moreover the computation of the partial derivatives (as required for example by BFGS) is considerably more complex than for the above two-parameter case. However, all the component functions are readily available in software packages with automatic differentiation. Again, the positive parameters can be parametrized in terms of their logarithms to obtain an unconstrained numerical optimization problem.
For this problem, numerical optimization may fail unless the initial location and scale parameters are chosen appropriately. However the above-mentioned interpretability of these parameters in the parametrization of can be used to do this. Specifically, the initial values for and can be set to the empirical mean and variance of the data.



See also
- Champernowne distribution, another generalization of the logistic distribution.
References
- Johnson, N.L., Kotz, S., Balakrishnan, N. (1995) Continuous Univariate Distributions, Volume 2, Wiley. ISBN 0-471-58494-0 (pages 140–142)
- Leigh J. Halliwell (2018). "The Log-Gamma Distribution and Non-Normal Error". S2CID 173176687.
{{cite journal}}: Cite journal requires|journal=(help) - C.M.Bishop, Pattern Recognition and Machine Learning, Springer 2006.