Ṭa (Indic)
Ṭa is a consonant of Indic abugidas. It is derived from the early "Ashoka" Brahmi letter ![]() after having gone through the Gupta letter
after having gone through the Gupta letter ![]() . As with the other retroflex consonants, ṭa is absent from most scripts not used for a language of India.
. As with the other retroflex consonants, ṭa is absent from most scripts not used for a language of India.
| Ṭa | |
|---|---|
 | |
| Example glyphs | |
| Bengali-Assamese | |
| Tibetan | ཊ |
| Tamil | |
| Thai | ฎ |
| Malayalam | ട |
| Sinhala | ට |
| Ashoka Brahmi | |
| Devanagari | |
| Cognates | |
| Hebrew | ט |
| Greek | Θ |
| Cyrillic | Ѳ |
| Properties | |
| Phonemic representation | /ʈ/ /ɗ/B /t/C |
| IAST transliteration | ṭa Ṭa |
| ISCII code point | BD (189) |
^B for initial value in Khmer ^C for final value in Khmer | |
| Indic letters | |||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Consonants | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Vowels | |||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Other marks | |||||||||||||||||||||||||||||||||||||||||||||||||
| Punctuation | |||||||||||||||||||||||||||||||||||||||||||||||||
Āryabhaṭa numeration
Aryabhata used Devanagari letters for numbers, very similar to the Greek numerals, even after the invention of Indian numerals. The values of the different forms of ट are:[1]
- ट [ʈə] = 11 (११)
- टि [ʈɪ] = 1,100 (१ १००)
- टु [ʈʊ] = 110,000 (१ १० ०००)
- टृ [ʈri] = 11,000,000 (१ १० ०० ०००)
- टॢ [ʈlə] = 1,100,000,000 (१ १० ०० ०० ०००)
- टे [ʈe] = 11×1010 (११×१०१०)
- टै [ʈɛː] = 11×1012 (११×१०१२)
- टो [ʈoː] = 11×1014 (११×१०१४)
- टौ [ʈɔː] = 11×1016 (११×१०१६)
Historic Tta
There are three different general early historic scripts - Brahmi and its variants, Kharoṣṭhī, and Tocharian, the so-called slanting Brahmi. Tta as found in standard Brahmi, ![]() was a simple geometric shape, with variations toward more flowing forms by the Gupta
was a simple geometric shape, with variations toward more flowing forms by the Gupta ![]() . The Tocharian Tta
. The Tocharian Tta ![]() did not have an alternate Fremdzeichen form. The third form of tta, in Kharoshthi (
did not have an alternate Fremdzeichen form. The third form of tta, in Kharoshthi (![]() ) was probably derived from Aramaic separately from the Brahmi letter.
) was probably derived from Aramaic separately from the Brahmi letter.
Brahmi Tta
The Brahmi letter ![]() , Tta, is probably derived from the altered Aramaic Teth
, Tta, is probably derived from the altered Aramaic Teth ![]() , and is thus related to the modern Greek Theta. Several identifiable styles of writing the Brahmi Tta can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[2] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, with vowel marks not attested until later forms of Brahmi back-formed to match the geometric writing style.
, and is thus related to the modern Greek Theta. Several identifiable styles of writing the Brahmi Tta can be found, most associated with a specific set of inscriptions from an artifact or diverse records from an historic period.[2] As the earliest and most geometric style of Brahmi, the letters found on the Edicts of Ashoka and other records from around that time are normally the reference form for Brahmi letters, with vowel marks not attested until later forms of Brahmi back-formed to match the geometric writing style.
| Ashoka (3rd-1st c. BCE) | Girnar (~150 BCE) | Kushana (~150-250 CE) | Gujarat (~250 CE) | Gupta (~350 CE) |
|---|---|---|---|---|
Tocharian Tta
The Tocharian letter ![]() is derived from the Brahmi
is derived from the Brahmi ![]() , but does not have an alternate Fremdzeichen form.
, but does not have an alternate Fremdzeichen form.
| Tta | Ttā | Tti | Ttī | Ttu | Ttū | Ttr | Ttr̄ | Tte | Ttai | Tto | Ttau | Ttä |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Devanagari script
| Devanāgarī |
|---|
 |
Ṭa (ट) is the eleventh consonant of the Devanagari abugida. [3] It ultimately arose from the Brahmi letter ![]() , after having gone through the Gupta letter
, after having gone through the Gupta letter ![]() . Letters that derive from it are the Gujarati letter ટ, and the Modi letter 𑘘.
. Letters that derive from it are the Gujarati letter ટ, and the Modi letter 𑘘.
Devanagari-using Languages
In many languages, ट is pronounced as [ʈə] or [ʈ] when appropriate. In Marathi, ट is sometimes pronounced as [tə] or [t] in addition to [ʈə] or [ʈ]. Like all Indic scripts, Devanagari uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
| Ṭa | Ṭā | Ṭi | Ṭī | Ṭu | Ṭū | Ṭr | Ṭr̄ | Ṭl | Ṭl̄ | Ṭe | Ṭai | Ṭo | Ṭau | Ṭ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ट | टा | टि | टी | टु | टू | टृ | टॄ | टॢ | टॣ | टे | टै | टो | टौ | ट् |
Conjuncts with ट
Devanagari exhibits conjunct ligatures, as is common in Indic scripts. In modern Devanagari texts, most conjuncts are formed by reducing the letter shape to fit tightly to the following letter, usually by dropping a character's vertical stem, sometimes referred to as a "half form". Some conjunct clusters are always represented by a true ligature, instead of a shape that can be broken into constituent independent letters. Vertically stacked conjuncts are ubiquitous in older texts, while only a few are still used routinely in modern Devanagari texts. Lacking a vertical stem to drop for making a half form, Ṭa either forms a stacked conjunct/ligature, or uses its full form with Virama. The use of ligatures and vertical conjuncts may vary across languages using the Devanagari script, with Marathi in particular avoiding their use where other languages would use them.[4]
Ligature conjuncts of ट
True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Devanagari are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra. Nepali and Marathi texts use the "eyelash" Ra half form ![]() for an initial "R" instead of repha.
for an initial "R" instead of repha.
- Repha र্ (r) + ट (ṭa) gives the ligature rṭa: note

- Eyelash र্ (r) + ट (ṭa) gives the ligature rṭa:

- ट্ (ṭ) + rakar र (ra) gives the ligature ṭra:

- प্ (p) + ट (ṭa) gives the ligature pṭa:

- ष্ (ṣ) + ट (ṭa) gives the ligature ṣṭa:

- Repha र্ (r) + ष্ (ṣ) + ट্ (ṭ) + rakar र (ra) gives the ligature rṣṭra:

- ष্ (ṣ) + ट্ (ṭ) + व (va) gives the ligature ṣṭva:

Stacked conjuncts of ट
Vertically stacked ligatures are the most common conjunct forms found in Devanagari text. Although the constituent characters may need to be stretched and moved slightly in order to stack neatly, stacked conjuncts can be broken down into recognizable base letters, or a letter and an otherwise standard ligature.
- छ্ (ch) + ट (ṭa) gives the ligature chṭa:

- ढ্ (ḍʱ) + ट (ṭa) gives the ligature ḍʱṭa:

- ड্ (ḍ) + ट (ṭa) gives the ligature ḍṭa:

- द্ (d) + ट (ṭa) gives the ligature dṭa:

- ङ্ (ŋ) + ट (ṭa) gives the ligature ŋṭa:

- ट্ (ṭ) + ब (ba) gives the ligature ṭba:

- ट্ (ṭ) + भ (bha) gives the ligature ṭbha:

- ट্ (ṭ) + च (ca) gives the ligature ṭca:

- ट্ (ṭ) + छ (cha) gives the ligature ṭcha:

- ट্ (ṭ) + द (da) gives the ligature ṭda:

- ट্ (ṭ) + ड (ḍa) gives the ligature ṭḍa:

- ट্ (ṭ) + ढ (ḍʱa) gives the ligature ṭḍʱa:

- ट্ (ṭ) + ध (dʱa) gives the ligature ṭdʱa:

- ट্ (ṭ) + ग (ga) gives the ligature ṭga:

- ट্ (ṭ) + घ (ɡʱa) gives the ligature ṭɡʱa:

- ट্ (ṭ) + ह (ha) gives the ligature ṭha:

- ठ্ (ṭh) + ट (ṭa) gives the ligature ṭhṭa:

- ट্ (ṭ) + ज (ja) gives the ligature ṭja:

- ट্ (ṭ) + झ (jha) gives the ligature ṭjha:

- ट্ (ṭ) + ज্ (j) + ञ (ña) gives the ligature ṭjña:

- ट্ (ṭ) + क (ka) gives the ligature ṭka:

- ट্ (ṭ) + ख (kha) gives the ligature ṭkha:

- ट্ (ṭ) + क্ (k) + ष (ṣa) gives the ligature ṭkṣa:

- ट্ (ṭ) + ल (la) gives the ligature ṭla:

- ट্ (ṭ) + ळ (ḷa) gives the ligature ṭḷa:

- ट্ (ṭ) + म (ma) gives the ligature ṭma:

- ट্ (ṭ) + न (na) gives the ligature ṭna:

- ट্ (ṭ) + ङ (ŋa) gives the ligature ṭŋa:

- ट্ (ṭ) + ण (ṇa) gives the ligature ṭṇa:

- ट্ (ṭ) + ञ (ña) gives the ligature ṭña:

- ट্ (ṭ) + प (pa) gives the ligature ṭpa:

- ट্ (ṭ) + फ (pha) gives the ligature ṭpha:

- ट্ (ṭ) + स (sa) gives the ligature ṭsa:

- ट্ (ṭ) + श (ʃa) gives the ligature ṭʃa:

- ट্ (ṭ) + ष (ṣa) gives the ligature ṭṣa:

- ट্ (ṭ) + त (ta) gives the ligature ṭta:

- ट্ (ṭ) + थ (tha) gives the ligature ṭtha:

- ट্ (ṭ) + ट (ṭa) gives the ligature ṭṭa:

- ट্ (ṭ) + ठ (ṭha) gives the ligature ṭṭha:

- ट্ (ṭ) + व (va) gives the ligature ṭva:

- ट্ (ṭ) + य (ya) gives the ligature ṭya:

Bengali script
The Bengali script ট is derived from the Siddhaṃ ![]() , and is marked by a similar horizontal head line, but less geometric shape, than its Devanagari counterpart, ट. The inherent vowel of Bengali consonant letters is /ɔ/, so the bare letter ট will sometimes be transliterated as "tto" instead of "tta". Adding okar, the "o" vowel mark, gives a reading of /t̳o/.
Like all Indic consonants, ট can be modified by marks to indicate another (or no) vowel than its inherent "a".
, and is marked by a similar horizontal head line, but less geometric shape, than its Devanagari counterpart, ट. The inherent vowel of Bengali consonant letters is /ɔ/, so the bare letter ট will sometimes be transliterated as "tto" instead of "tta". Adding okar, the "o" vowel mark, gives a reading of /t̳o/.
Like all Indic consonants, ট can be modified by marks to indicate another (or no) vowel than its inherent "a".
| tta | ttā | tti | ttī | ttu | ttū | ttr | ttr̄ | tte | ttai | tto | ttau | tt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ট | টা | টি | টী | টু | টূ | টৃ | টৄ | টে | টৈ | টো | টৌ | ট্ |
ট in Bengali-using languages
ট is used as a basic consonant character in all of the major Bengali script orthographies, including Bengali and Assamese.
Conjuncts with ট
Bengali ট exhibits conjunct ligatures, as is common in Indic scripts, and commonly shows both stacked and linear (horizontal) ligatures.[5]
- ক্ (k) + ট (ṭa) gives the ligature kṭa:

- ক্ (k) + ট্ (ṭ) + র (ra) gives the ligature kṭra, with the ra phala suffix:

- ল্ (l) + ট (ṭa) gives the ligature lṭa:

- ণ্ (ṇ) + ট (ṭa) gives the ligature ṇṭa:

- ন্ (n) + ট (ṭa) gives the ligature nṭa:

- ন্ (n) + ট্ (ṭ) + র (ra) gives the ligature nṭra, with the ra phala suffix:

- প্ (p) + ট (ṭa) gives the ligature pṭa:

- র্ (r) + ট (ṭa) gives the ligature rṭa, with the repha prefix:

- ষ্ (ṣ) + ট (ṭa) gives the ligature ṣṭa:

- ষ্ (ṣ) + ট্ (ṭ) + র (ra) gives the ligature ṣṭra, with the ra phala suffix:

- ষ্ (ṣ) + ট্ (ṭ) + য (ya) gives the ligature ṣṭya, with the ya phala suffix:

- স্ (s) + ট (ṭa) gives the ligature sṭa:

- স্ (s) + ট্ (ṭ) + র (ra) gives the ligature sṭra, with the ra phala suffix:

- ট্ (ṭ) + ম (ma) gives the ligature ṭma:

- ট্ (ṭ) + র (ra) gives the ligature ṭra, with the ra phala suffix:

- ট্ (ṭ) + ট (ṭa) gives the ligature ṭṭa:

- ট্ (ṭ) + ব (va) gives the ligature ṭva, with the va phala suffix:

- ট্ (ṭ) + য (ya) gives the ligature ṭya, with the ya phala suffix:

Gujarati Ṭa

Ṭa (ટ) is the eleventh consonant of the Gujarati abugida. It is derived from the Devanagari Ṭa ![]() with the top bar (shiro rekha) removed, and ultimately the Brahmi letter
with the top bar (shiro rekha) removed, and ultimately the Brahmi letter ![]() .
.
Gujarati-using Languages
The Gujarati script is used to write the Gujarati and Kutchi languages. In both languages, ટ is pronounced as [ʈə] or [ʈ] when appropriate. Like all Indic scripts, Gujarati uses vowel marks attached to the base consonant to override the inherent /ə/ vowel:
| Ṭa | Ṭā | Ṭi | Ṭī | Ṭu | Ṭū | Ṭr | Ṭl | Ṭr̄ | Ṭl̄ | Ṭĕ | Ṭe | Ṭai | Ṭŏ | Ṭo | Ṭau | Ṭ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 | ||||||||||||||||
| Gujarati Ṭa syllables, with vowel marks in red. | ||||||||||||||||
Conjuncts with ટ
Gujarati ટ exhibits conjunct ligatures, much like its parent Devanagari Script. While most Gujarati conjuncts can only be formed by reducing the letter shape to create a "half form" that fits tightly to following letter, Ṭa does not have a half form. A few conjunct clusters can be represented by a true ligature, instead of a shape that can be broken into constituent independent letters, and vertically stacked conjuncts can also be found in Gujarati, although much less commonly than in Devanagari. Lacking a half form, Ṭa will normally use an explicit virama when forming conjuncts without a true ligature. True ligatures are quite rare in Indic scripts. The most common ligated conjuncts in Gujarati are in the form of a slight mutation to fit in context or as a consistent variant form appended to the adjacent characters. Those variants include Na and the Repha and Rakar forms of Ra.
- ર્ (r) + ટ (ʈa) gives the ligature RṬa:

- ટ્ (ʈ) + ર (ra) gives the ligature ṬRa:
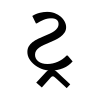
- ટ્ (ʈ) + ટ (ʈa) gives the ligature ṬṬa:

- ટ્ (ʈ) + ઠ (ʈha) gives the ligature ṬṬha:

- ટ્ (ʈ) + વ (va) gives the ligature ṬVa:

Burmese script
Ta T'lin Cheik (ဋ) is the eleventh letter of the Burmese script.
Thai script
Do Chada (ฎ) and To Patak (ฏ) are the fourteenth and fifteenth letters of the Thai script. As with ta and pa, the Indic letter has been split into two letters to distinguish the originally preglottalised (and now voiced) sound from the voiceless sound.

Do chada
Do chada falls under the middle class of Thai consonants. In IPA, do chada is pronounced as [d] at the beginning of a syllable and as [t̚] at the end of a syllable. The 20th letter of the alphabet, do dek (ด), is also named do and falls under the middle class of Thai consonants. Thai consonants do not form conjunct ligatures, and may use the pinthu—an explicit virama with a dot shape—to indicate bare consonants. In the acrophony of the Thai script, chada (ชฎา) means 'headdress'. Do chada and to patak both correspond to the Devanagari character 'ट'.

To patak
To patak falls under the middle class of Thai consonants. In IPA, to patak is pronounced as [t] at the beginning of a syllable and may not be used to close a syllable. The 21st letter of the alphabet, to tao (ต), is also named to and falls under the middle class of Thai consonants. Thai consonants do not form conjunct ligatures, and may use the pinthu—an explicit virama with a dot shape—to indicate bare consonants. In the acrophony of the Thai script, patak (ปฏัก) means '(cattle) goad'. Do chada and to patak both correspond to the Devanagari character 'ट'.
Javanese script
Telugu Ṭa


Ṭa (ట) is a consonant of the Telugu abugida. It ultimately arose from the Brahmi letter ![]() . It is closely related to the Kannada letter ಟ. Since it lacks the v-shaped headstroke common to most Telugu letters, X remains unaltered by most vowel matras, and its subjoined form is simply a smaller version of the normal letter shape.
Telugu conjuncts are created by reducing trailing letters to a subjoined form that appears below the initial consonant of the conjunct. Many subjoined forms are created by dropping their headline, with many extending the end of the stroke of the main letter body to form an extended tail reaching up to the right of the preceding consonant. This subjoining of trailing letters to create conjuncts is in contrast to the leading half forms of Devanagari and Bengali letters. Ligature conjuncts are not a feature in Telugu, with the only non-standard construction being an alternate subjoined form of Ṣa (borrowed from Kannada) in the KṢa conjunct.
. It is closely related to the Kannada letter ಟ. Since it lacks the v-shaped headstroke common to most Telugu letters, X remains unaltered by most vowel matras, and its subjoined form is simply a smaller version of the normal letter shape.
Telugu conjuncts are created by reducing trailing letters to a subjoined form that appears below the initial consonant of the conjunct. Many subjoined forms are created by dropping their headline, with many extending the end of the stroke of the main letter body to form an extended tail reaching up to the right of the preceding consonant. This subjoining of trailing letters to create conjuncts is in contrast to the leading half forms of Devanagari and Bengali letters. Ligature conjuncts are not a feature in Telugu, with the only non-standard construction being an alternate subjoined form of Ṣa (borrowed from Kannada) in the KṢa conjunct.
Malayalam Ṭa

Ṭa (ട) is a consonant of the Malayalam abugida. It ultimately arose from the Brahmi letter ![]() , via the Grantha letter
, via the Grantha letter ![]() Tta. Like in other Indic scripts, Malayalam consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Tta. Like in other Indic scripts, Malayalam consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Conjuncts of ട
As is common in Indic scripts, Malayalam joins letters together to form conjunct consonant clusters. There are several ways in which conjuncts are formed in Malayalam texts: using a post-base form of a trailing consonant placed under the initial consonant of a conjunct, a combined ligature of two or more consonants joined together, a conjoining form that appears as a combining mark on the rest of the conjunct, the use of an explicit candrakkala mark to suppress the inherent "a" vowel, or a special consonant form called a "chillu" letter, representing a bare consonant without the inherent "a" vowel. Texts written with the modern reformed Malayalam orthography, put̪iya lipi, may favor more regular conjunct forms than older texts in paḻaya lipi, due to changes undertaken in the 1970s by the Government of Kerala.
- ക് (k) + ട (ṭa) gives the ligature kṭa:

- ട് (ṭ) + ട (ṭa) gives the ligature ṭṭa:

- ണ് (ṇ) + ട (ṭa) gives the ligature ṇṭa:

- ഷ് (ṣ) + ട (ṭa) gives the ligature ṣṭa:
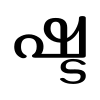
Canadian Aboriginal Syllabics Te
| Canadian Aboriginal Syllabics | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||
ᑌ, ᑎ, ᑐ and ᑕ are the base characters "Te", "Ti", "To" and "Ta" in the Canadian Aboriginal Syllabics. The bare consonant ᑦ (T) is a small version of the A-series letter ᑕ, although the Western Cree letter ᐟ, derived from Pitman shorthand was the original bare consonant symbol for T. The character ᑌ is derived from a handwritten form of the Devanagari letter ट, without the headline or vertical stem, and the forms for different vowels are derived by rotation.[6][7] Unlike most writing systems without legacy computer encodings, complex Canadian syllabic letters are represented in Unicode with pre-composed characters, rather than with base characters and diacritical marks.
| Variant | E-series | I-series | O-series | A-series | Other | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| T + vowel | ᑌ | ᑎ | ᑐ | ᑕ | ᢷ | ||||||
| Te | Ti | To | Ta | Tay | |||||||
| Small | - | ᣕ | - | ᑦ | ᐟ | ||||||
| - | Ojibway T | - | T | Cree T | |||||||
| T with long vowels | - | ᑏ | ᑑ | ᑒ | ᑖ | ᑍ | |||||
| - | Tī | Tō | Cree Tō | Tā | Tāi | ||||||
| T + W-vowels | ᑗ | ᑘ | ᑙ | ᑚ | ᑝ | ᑞ | ᑡ | ᑢ | - | ||
| Twe | Cree Twe | Twi | Cree Twi | Two | Cree Two | Twa | Cree Twa | - | |||
| T + long W-vowels | - | ᑛ | ᑜ | ᑟ | ᑠ | ᑣ | ᑥ | ᑤ | - | ||
| - | Twī | Cree Twī | Twō | Cree Twō | Twā | Naskapi Twā | Cree Twā | - | |||
| Tt + vowel | ᑧ | ᑨ | ᑩ | ᑪ | - | ||||||
| Tte | Tti | Tto | Tta | ||||||||
| Ty + vowel | ᕰ | ᕱ | ᕲ | ᕳ | - | ||||||
| Tye | Tyi | Tyo | Tya | ||||||||
| Tth + vowel | ᕫ | ᕬ | ᕭ | ᕮ | - | ||||||
| Tthe | Tthi | Ttho | Ttha | ||||||||
| Tth other | ᣥ | - | ᣦ | ᣧ | - | ||||||
| Tthwe | - | Tthoo | Tthaa | ||||||||
Odia Ṭa


Ṭa (ଟ) is a consonant of the Odia abugida. It ultimately arose from the Brahmi letter ![]() , via the Siddhaṃ letter
, via the Siddhaṃ letter ![]() Tta. Like in other Indic scripts, Odia consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Tta. Like in other Indic scripts, Odia consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
| Tta | Ttā | Tti | Ttī | Ttu | Ttū | Ttr̥ | Ttr̥̄ | Ttl̥ | Ttl̥̄ | Tte | Ttai | Tto | Ttau | Tt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ଟ | ଟା | ଟି | ଟୀ | ଟୁ | ଟୂ | ଟୃ | ଟୄ | ଟୢ | ଟୣ | ଟେ | ଟୈ | ଟୋ | ଟୌ | ଟ୍ |
Conjuncts of ଟ
As is common in Indic scripts, Odia joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a small subjoined form of trailing consonants. Most consonants' subjoined forms are identical to the full form, just reduced in size, although a few drop the curved headline or have a subjoined form not directly related to the full form of the consonant. The second type of conjunct formation is through pure ligatures, where the constituent consonants are written together in a single graphic form. This ligature may be recognizable as being a combination of two characters or it can have a conjunct ligature unrelated to its constituent characters.
- ଟ୍ (ṭ) + ଟ (ṭa) gives the ligature ṭṭa:

Kaithi Ṭa
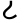
Ṭa (𑂗) is a consonant of the Kaithi abugida. It ultimately arose from the Brahmi letter ![]() , via the Siddhaṃ letter
, via the Siddhaṃ letter ![]() Tta. Like in other Indic scripts, Kaithi consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
Tta. Like in other Indic scripts, Kaithi consonants have the inherent vowel "a", and take one of several modifying vowel signs to represent syllables with another vowel or no vowel at all.
| Tta | Ttā | Tti | Ttī | Ttu | Ttū | Tte | Ttai | Tto | Ttau | Tt |
|---|---|---|---|---|---|---|---|---|---|---|
| 𑂗 | 𑂗𑂰 | 𑂗𑂱 | 𑂗𑂲 | 𑂗𑂳 | 𑂗𑂴 | 𑂗𑂵 | 𑂗𑂶 | 𑂗𑂷 | 𑂗𑂸 | 𑂗𑂹 |
Conjuncts of 𑂗
As is common in Indic scripts, Kaithi joins letters together to form conjunct consonant clusters. The most common conjunct formation is achieved by using a half form of preceding consonants, although several consonants use an explicit virama. Most half forms are derived from the full form by removing the vertical stem. As is common in most Indic scripts, conjucts of ra are indicated with a repha or rakar mark attached to the rest of the consonant cluster. In addition, there are a few vertical conjuncts that can be found in Kaithi writing, but true ligatures are not used in the modern Kaithi script.
- 𑂩୍ (r) + 𑂗 (ṭa) gives the ligature rṭa:

Comparison of Ṭa
The various Indic scripts are generally related to each other through adaptation and borrowing, and as such the glyphs for cognate letters, including Ṭa, are related as well.
| Comparison of Ṭa in different scripts |
|---|
|
Notes
|
Character encodings of Ṭa
Most Indic scripts are encoded in the Unicode Standard, and as such the letter Ṭa in those scripts can be represented in plain text with unique codepoint. Ṭa from several modern-use scripts can also be found in legacy encodings, such as ISCII.
| Preview | ట | ଟ | ಟ | ട | ટ | ਟ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | DEVANAGARI LETTER TTA | BENGALI LETTER TTA | TAMIL LETTER TTA | TELUGU LETTER TTA | ORIYA LETTER TTA | KANNADA LETTER TTA | MALAYALAM LETTER TTA | GUJARATI LETTER TTA | GURMUKHI LETTER TTA | |||||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 2335 | U+091F | 2463 | U+099F | 2975 | U+0B9F | 3103 | U+0C1F | 2847 | U+0B1F | 3231 | U+0C9F | 3359 | U+0D1F | 2719 | U+0A9F | 2591 | U+0A1F |
| UTF-8 | 224 164 159 | E0 A4 9F | 224 166 159 | E0 A6 9F | 224 174 159 | E0 AE 9F | 224 176 159 | E0 B0 9F | 224 172 159 | E0 AC 9F | 224 178 159 | E0 B2 9F | 224 180 159 | E0 B4 9F | 224 170 159 | E0 AA 9F | 224 168 159 | E0 A8 9F |
| Numeric character reference | ट | ट | ট | ট | ட | ட | ట | ట | ଟ | ଟ | ಟ | ಟ | ട | ട | ટ | ટ | ਟ | ਟ |
| ISCII | 189 | BD | 189 | BD | 189 | BD | 189 | BD | 189 | BD | 189 | BD | 189 | BD | 189 | BD | 189 | BD |
| Preview | Ashoka Kushana Gupta | 𑌟 | ||||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | BRAHMI LETTER TTA | KHAROSHTHI LETTER TTA | SIDDHAM LETTER TTA | GRANTHA LETTER TTA | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 69661 | U+1101D | 68122 | U+10A1A | 71064 | U+11598 | 70431 | U+1131F |
| UTF-8 | 240 145 128 157 | F0 91 80 9D | 240 144 168 154 | F0 90 A8 9A | 240 145 150 152 | F0 91 96 98 | 240 145 140 159 | F0 91 8C 9F |
| UTF-16 | 55300 56349 | D804 DC1D | 55298 56858 | D802 DE1A | 55301 56728 | D805 DD98 | 55300 57119 | D804 DF1F |
| Numeric character reference | 𑀝 | 𑀝 | 𐨚 | 𐨚 | 𑖘 | 𑖘 | 𑌟 | 𑌟 |
| Preview | ཊ | ྚ | 𑨔 | 𑐚 | 𑰘 | 𑆛 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TIBETAN LETTER TTA | TIBETAN SUBJOINED LETTER TTA | ZANABAZAR SQUARE LETTER TTA | NEWA LETTER TTA | BHAIKSUKI LETTER TTA | SHARADA LETTER TTA | ||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 3914 | U+0F4A | 3994 | U+0F9A | 72212 | U+11A14 | 70682 | U+1141A | 72728 | U+11C18 | 70043 | U+1119B |
| UTF-8 | 224 189 138 | E0 BD 8A | 224 190 154 | E0 BE 9A | 240 145 168 148 | F0 91 A8 94 | 240 145 144 154 | F0 91 90 9A | 240 145 176 152 | F0 91 B0 98 | 240 145 134 155 | F0 91 86 9B |
| UTF-16 | 3914 | 0F4A | 3994 | 0F9A | 55302 56852 | D806 DE14 | 55301 56346 | D805 DC1A | 55303 56344 | D807 DC18 | 55300 56731 | D804 DD9B |
| Numeric character reference | ཊ | ཊ | ྚ | ྚ | 𑨔 | 𑨔 | 𑐚 | 𑐚 | 𑰘 | 𑰘 | 𑆛 | 𑆛 |
| Preview | ဋ | ᨭ | ||
|---|---|---|---|---|
| Unicode name | MYANMAR LETTER TTA | TAI THAM LETTER RATA | ||
| Encodings | decimal | hex | dec | hex |
| Unicode | 4107 | U+100B | 6701 | U+1A2D |
| UTF-8 | 225 128 139 | E1 80 8B | 225 168 173 | E1 A8 AD |
| Numeric character reference | ဋ | ဋ | ᨭ | ᨭ |
| Preview | ដ | ຏ | ฏ | ฎ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | KHMER LETTER DA | LAO LETTER PALI TTA | THAI CHARACTER TO PATAK | THAI CHARACTER DO CHADA | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 6026 | U+178A | 3727 | U+0E8F | 3599 | U+0E0F | 3598 | U+0E0E |
| UTF-8 | 225 158 138 | E1 9E 8A | 224 186 143 | E0 BA 8F | 224 184 143 | E0 B8 8F | 224 184 142 | E0 B8 8E |
| Numeric character reference | ដ | ដ | ຏ | ຏ | ฏ | ฏ | ฎ | ฎ |
| Preview | ට | 𑄑 | 𑤖 | ꢜ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | SINHALA LETTER ALPAPRAANA TTAYANNA | CHAKMA LETTER TTAA | DIVES AKURU LETTER TTA | SAURASHTRA LETTER TTA | ||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 3495 | U+0DA7 | 69905 | U+11111 | 71958 | U+11916 | 43164 | U+A89C |
| UTF-8 | 224 182 167 | E0 B6 A7 | 240 145 132 145 | F0 91 84 91 | 240 145 164 150 | F0 91 A4 96 | 234 162 156 | EA A2 9C |
| UTF-16 | 3495 | 0DA7 | 55300 56593 | D804 DD11 | 55302 56598 | D806 DD16 | 43164 | A89C |
| Numeric character reference | ට | ට | 𑄑 | 𑄑 | 𑤖 | 𑤖 | ꢜ | ꢜ |
| Preview | 𑘘 | 𑦸 | 𑩦 | ꠐ | 𑵽 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | MODI LETTER TTA | NANDINAGARI LETTER TTA | SOYOMBO LETTER TTA | SYLOTI NAGRI LETTER TTO | GUNJALA GONDI LETTER TTA | KAITHI LETTER TTA | ||||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 71192 | U+11618 | 72120 | U+119B8 | 72294 | U+11A66 | 43024 | U+A810 | 73085 | U+11D7D | 69783 | U+11097 |
| UTF-8 | 240 145 152 152 | F0 91 98 98 | 240 145 166 184 | F0 91 A6 B8 | 240 145 169 166 | F0 91 A9 A6 | 234 160 144 | EA A0 90 | 240 145 181 189 | F0 91 B5 BD | 240 145 130 151 | F0 91 82 97 |
| UTF-16 | 55301 56856 | D805 DE18 | 55302 56760 | D806 DDB8 | 55302 56934 | D806 DE66 | 43024 | A810 | 55303 56701 | D807 DD7D | 55300 56471 | D804 DC97 |
| Numeric character reference | 𑘘 | 𑘘 | 𑦸 | 𑦸 | 𑩦 | 𑩦 | ꠐ | ꠐ | 𑵽 | 𑵽 | 𑂗 | 𑂗 |
| Preview | 𑒙 | |
|---|---|---|
| Unicode name | TIRHUTA LETTER TTA | |
| Encodings | decimal | hex |
| Unicode | 70809 | U+11499 |
| UTF-8 | 240 145 146 153 | F0 91 92 99 |
| UTF-16 | 55301 56473 | D805 DC99 |
| Numeric character reference | 𑒙 | 𑒙 |
| Preview | 𑚔 | 𑠔 | 𑋆 | 𑅞 | 𑊐 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | TAKRI LETTER TTA | DOGRA LETTER TTA | KHUDAWADI LETTER TTA | MAHAJANI LETTER TTA | MULTANI LETTER TTA | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 71316 | U+11694 | 71700 | U+11814 | 70342 | U+112C6 | 69982 | U+1115E | 70288 | U+11290 |
| UTF-8 | 240 145 154 148 | F0 91 9A 94 | 240 145 160 148 | F0 91 A0 94 | 240 145 139 134 | F0 91 8B 86 | 240 145 133 158 | F0 91 85 9E | 240 145 138 144 | F0 91 8A 90 |
| UTF-16 | 55301 56980 | D805 DE94 | 55302 56340 | D806 DC14 | 55300 57030 | D804 DEC6 | 55300 56670 | D804 DD5E | 55300 56976 | D804 DE90 |
| Numeric character reference | 𑚔 | 𑚔 | 𑠔 | 𑠔 | 𑋆 | 𑋆 | 𑅞 | 𑅞 | 𑊐 | 𑊐 |
| Preview | ᬝ | ꦛ | ||
|---|---|---|---|---|
| Unicode name | BALINESE LETTER TA LATIK | JAVANESE LETTER TTA | ||
| Encodings | decimal | hex | dec | hex |
| Unicode | 6941 | U+1B1D | 43419 | U+A99B |
| UTF-8 | 225 172 157 | E1 AC 9D | 234 166 155 | EA A6 9B |
| Numeric character reference | ᬝ | ᬝ | ꦛ | ꦛ |
| Preview | 𑴖 | |
|---|---|---|
| Unicode name | MASARAM GONDI LETTER TTA | |
| Encodings | decimal | hex |
| Unicode | 72982 | U+11D16 |
| UTF-8 | 240 145 180 150 | F0 91 B4 96 |
| UTF-16 | 55303 56598 | D807 DD16 |
| Numeric character reference | 𑴖 | 𑴖 |
| Preview | ᑌ | ᑎ | ᑐ | ᑕ | ᑦ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | CANADIAN SYLLABICS TE | CANADIAN SYLLABICS TI | CANADIAN SYLLABICS TO | CANADIAN SYLLABICS TA | CANADIAN SYLLABICS T | |||||
| Encodings | decimal | hex | dec | hex | dec | hex | dec | hex | dec | hex |
| Unicode | 5196 | U+144C | 5198 | U+144E | 5200 | U+1450 | 5205 | U+1455 | 5222 | U+1466 |
| UTF-8 | 225 145 140 | E1 91 8C | 225 145 142 | E1 91 8E | 225 145 144 | E1 91 90 | 225 145 149 | E1 91 95 | 225 145 166 | E1 91 A6 |
| Numeric character reference | ᑌ | ᑌ | ᑎ | ᑎ | ᑐ | ᑐ | ᑕ | ᑕ | ᑦ | ᑦ |
- The full range of E Canadian syllabic characters can be found at the codepoint ranges .
References
- Ifrah, Georges (2000). The Universal History of Numbers. From Prehistory to the Invention of the Computer. New York: John Wiley & Sons. pp. 447–450. ISBN 0-471-39340-1.
- Evolutionary chart, Journal of the Asiatic Society of Bengal Vol 7, 1838
- Bahri, Harder (2004). Hindi-Angrezi Shabdkosh. p. xiii.
- Pall, Peeter. "Microsoft Word - kblhi2" (PDF). Eesti Keele Instituudi kohanimeandmed. Eesti Keele Instituudi kohanimeandmed. Retrieved 19 June 2020.
- "The Bengali Alphabet" (PDF). Archived from the original (PDF) on 2013-09-28.
- Zui. "Writing in North America — Canadian Aboriginal Syllabics". The Language Closet. Retrieved 2 April 2023.
- Andrew Dalby (2004:139) Dictionary of Languages
Further reading
- Kurt Elfering: Die Mathematik des Aryabhata I. Text, Übersetzung aus dem Sanskrit und Kommentar. Wilhelm Fink Verlag, München, 1975, ISBN 3-7705-1326-6
- Georges Ifrah: The Universal History of Numbers. From Prehistory to the Invention of the Computer. John Wiley & Sons, New York, 2000, ISBN 0-471-39340-1.
- B. L. van der Waerden: Erwachende Wissenschaft. Ägyptische, babylonische und griechische Mathematik. Birkhäuser-Verlag, Basel Stuttgart, 1966, ISBN 3-7643-0399-9
- Fleet, J. F. (January 1911). "Aryabhata's System of Expressing Numbers". Journal of the Royal Asiatic Society of Great Britain and Ireland. 43: 109–126. doi:10.1017/S0035869X00040995. ISSN 0035-869X. JSTOR 25189823.
- Fleet, J. F. (1911). "Aryabhata's System of Expressing Numbers". The Journal of the Royal Asiatic Society of Great Britain and Ireland. Royal Asiatic Society of Great Britain and Ireland. 43: 109–126. doi:10.1017/S0035869X00040995. JSTOR 25189823.