Arabic script
The Arabic script is the writing system used for Arabic and several other languages of Asia and Africa. It is the second-most widely used alphabetic writing system in the world (after the Latin script),[2] the second-most widely used writing system in the world by number of countries using it, and the third-most by number of users (after the Latin and Chinese scripts).[3]
| Arabic script | |
|---|---|
 | |
| Script type | primarily, alphabet in some adaptations |
Time period | 4th century CE to the present[1] |
| Direction | right-to-left script |
| Official script | 19 sovereign states Co-official script in: 10 sovereign states |
| Languages | See below |
| Related scripts | |
Parent systems | |
Child systems | N'Ko Hanifi script |
| ISO 15924 | |
| ISO 15924 | Arab (160), Arabic |
| Unicode | |
Unicode alias | Arabic |
| |
The script was first used to write texts in Arabic, most notably the Quran, the holy book of Islam. With the religion's spread, it came to be used as the primary script for many language families, leading to the addition of new letters and other symbols. Such languages still using it are: Persian (Farsi), Malay (Jawi), Uyghur, Kurdish, Punjabi (Shahmukhi), Sindhi, Balti, Balochi, Pashto, Lurish, Urdu, Kashmiri, Rohingya, Somali, Mandinka, and Mooré, among others.[4] Until the 16th century, it was also used for some Spanish texts, and—prior to the language reform in 1928—it was the writing system of Turkish.[5]
The script is written from right to left in a cursive style, in which most of the letters are written in slightly different forms according to whether they stand alone or are joined to a following or preceding letter. However, the basic letter form remains unchanged. The script does not have capital letters.[6] In most cases, the letters transcribe consonants, or consonants and a few vowels, so most Arabic alphabets are abjads, with the versions used for some languages, such as Sorani, Uyghur, Mandarin, and Serbo-Croatian, being alphabets. It is also the basis for the tradition of Arabic calligraphy.
| Calligraphy |
|---|
| Worldwide use of the Arabic and Perso-Arabic script | ||
|---|---|---|
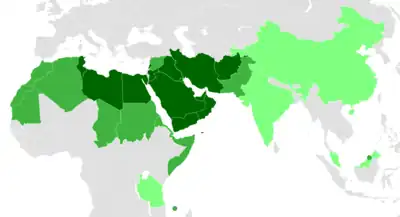 Arabic alphabet world distribution | ||
| Countries where the Arabic or Perso-Arabic script is: | ||
| → | the sole official script | |
| → | official alongside other scripts | |
| → | official at a provincial level (China, India, Tanzania) or a recognized second script of the official language (Malaysia, Tajikistan) | |
History
The Arabic alphabet is derived either from the Nabataean alphabet[7][8] or (less widely believed) directly from the Syriac alphabet,[9] which are both derived from the Aramaic alphabet (which also gave rise to the Hebrew alphabet), which, in turn, descended from the Phoenician alphabet. In addition to the Aramaic script (and, therefore, the Arabic and Hebrew scripts), the Phoenician script also gave rise to the Greek alphabet (and, therefore, both the Cyrillic alphabet and the Latin alphabet used to write this article).
Origins
In the 6th and 5th centuries BCE, northern Arab tribes emigrated and founded a kingdom centred around Petra, Jordan. These people (now named Nabataeans from the name of one of the tribes, Nabatu) spoke Nabataean Arabic, a dialect of the Arabic language. In the 2nd or 1st centuries BCE,[10][11] the first known records of the Nabataean alphabet were written in the Aramaic language (which was the language of communication and trade), but included some Arabic language features: the Nabataeans did not write the language which they spoke. They wrote in a form of the Aramaic alphabet, which continued to evolve; it separated into two forms: one intended for inscriptions (known as "monumental Nabataean") and the other, more cursive and hurriedly written and with joined letters, for writing on papyrus.[12] This cursive form influenced the monumental form more and more and gradually changed into the Arabic alphabet.
Overview
| خ | ح | ج | ث | ت | ب | ا |
| khā’ | ḥā’ | jīm | tha’ | tā’ | bā’ | alif |
| ص | ش | س | ز | ر | ذ | د |
| ṣād | shīn | sīn | zāy / zayn |
rā’ | dhāl | dāl |
| ق | ف | غ | ع | ظ | ط | ض |
| qāf | fā’ | ghayn | ‘ayn | ẓā’ | ṭā’ | ḍād |
| ي | و | ه | ن | م | ل | ك |
| yā’ | wāw | hā’ | nūn | mīm | lām | kāf |
| أ | آ | إ | ئ | ؠ | ء | ࢬ |
| alif hamza↑ | alif madda | alif hamza↓ | yā’ hamza↑ | kashmiri yā’ | hamza | rohingya yā’ |
| ى | ٱ | ی | ە | ً | ٌ | ٍ |
| alif maksura | alif wasla | farsi yā’ | ae | fathatan | dammatan | kasratan |
| َ | ُ | ِ | ّ | ْ | ٓ | ۤ |
| fatha | damma | kasra | shadda | sukun | maddah | madda |
| ں | ٹ | ٺ | ٻ | پ | ٿ | ڃ |
| nūn ghunna | ttā’ | ttāhā’ | bāā’ | pā’ | tāhā’ | nyā’ |
| ڄ | چ | ڇ | ڈ | ڌ | ڍ | ڎ |
| dyā’ | tchā’ | tchahā’ | ddāl | dāhāl | ddāhāl | duul |
| ڑ | ژ | ڤ | ڦ | ک | ڭ | گ |
| rrā’ | jā’ | vā’ | pāḥā’ | kāḥā’ | ng | gāf |
| ڳ | ڻ | ھ | ہ | ة | ۃ | ۅ |
| gueh | rnūn | hā’ doachashmee | hā’ goal | tā’ marbuta | tā’ marbuta goal | kirghiz oe |
| ۆ | ۇ | ۈ | ۉ | ۋ | ې | ے |
| oe | u | yu | kirghiz yu | ve | e | yā’ barree |
| (see below for other alphabets) | ||||||
The Arabic script has been adapted for use in a wide variety of languages besides Arabic, including Persian, Malay and Urdu, which are not Semitic. Such adaptations may feature altered or new characters to represent phonemes that do not appear in Arabic phonology. For example, the Arabic language lacks a voiceless bilabial plosive (the [p] sound), therefore many languages add their own letter to represent [p] in the script, though the specific letter used varies from language to language. These modifications tend to fall into groups: Indian and Turkic languages written in the Arabic script tend to use the Persian modified letters, whereas the languages of Indonesia tend to imitate those of Jawi. The modified version of the Arabic script originally devised for use with Persian is known as the Perso-Arabic script by scholars.
When the Arabic script is used to write Serbo-Croatian, Sorani, Kashmiri, Mandarin Chinese, or Uyghur, vowels are mandatory. The Arabic script can, therefore, be used as a true alphabet as well as an abjad, although it is often strongly, if erroneously, connected to the latter due to it being originally used only for Arabic.
Use of the Arabic script in West African languages, especially in the Sahel, developed with the spread of Islam. To a certain degree the style and usage tends to follow those of the Maghreb (for instance the position of the dots in the letters fāʼ and qāf).[13][14] Additional diacritics have come into use to facilitate the writing of sounds not represented in the Arabic language. The term ʻAjamī, which comes from the Arabic root for "foreign", has been applied to Arabic-based orthographies of African languages.

Table of writing styles
| Script or style | Alphabet(s) | Language(s) | Region | Derived from | Comment |
|---|---|---|---|---|---|
| Naskh | Arabic & others |
Arabic & others |
Every region where Arabic scripts are used | Sometimes refers to a very specific calligraphic style, but sometimes used to refer more broadly to almost every font that is not Kufic or Nastaliq. | |
| Nastaliq | Urdu, Persian, & others |
Urdu, Persian, & others |
Southern and Western Asia | Taliq | Used for almost all modern Urdu text, but only occasionally used for Persian. (The term "Nastaliq" is sometimes used by Urdu speakers to refer to all Perso-Arabic scripts.) |
| Taliq | Persian | Persian | A predecessor of Nastaliq. | ||
| Kufic | Arabic | Arabic | Middle East and parts of North Africa | ||
| Rasm | Restricted Arabic alphabet | Arabic | Mainly historical | Omits all diacritics including i'jam. Digital replication usually requires some special characters. See: ٮ ڡ ٯ (links to Wiktionary). | |
Table of alphabets
| Alphabet | Letters | Additional Characters |
Script or Style | Languages | Region | Derived from: (or related to) |
Note |
|---|---|---|---|---|---|---|---|
| Arabic | 28 | ^(see above) | Naskh, Kufi, Rasm, & others | Arabic | North Africa, West Asia | Aramaic, Syriac, Nabataean |
|
| Ajami script | 33 | ٻ تٜ تٰٜ | Naskh | Hausa, Yoruba, Swahili | West Africa | Arabic | Abjad | documented use likely between the 15th to 18th Century for Hausa, Mande, Pulaar, Swahili, Wolof, and Yoruba Languages |
| Aljamiado | 28 | Naskh and Nastaliq | Old Spanish, Mozarabic, Ladino, Aragonese, Old Galician-Portuguese | Southwest Europe | Perso-Arabic | 8th–13th centuries for Mozarabic, 14th–16th centuries for the other languages | |
| Arebica | 30 | ڄ ە اٖى ي ڵ ںٛ ۉ ۆ | Naskh | Serbo-Croatian | Southeastern Europe | Perso-Arabic | Latest stage has full vowel marking |
| Arwi alphabet | 41 | ڊ ڍ ڔ صٜ ۻ ࢳ ڣ ࢴ ڹ ݧ | Naskh | Tamil | Southern India, Sri Lanka | Perso-Arabic | |
| Belarusian Arabic alphabet | 32 | ࢮ ࢯ | Naskh | Belarusian | Eastern Europe | Perso-Arabic | 15th / 16th century |
| Balochi Standard Alphabet(s) | 29 | ٹ ڈ ۏ ݔ ے | Naskh and Nastaliq | Balochi | South-West Asia | Perso-Arabic, also borrows multiple glyphs from Urdu | This standardization is based on the previous orthography. For more information, see Balochi writing. |
| Berber Arabic alphabet(s) | 33 | چ ژ ڞ ݣ ء | Various Berber languages | North Africa | Arabic | ||
| Burushaski | 53 | ݳ ݴ ݼ څ ڎ ݽ ڞ ݣ ݸ ݹ ݶ ݷ ݺ ݻ (see note) |
Nastaliq | Burushaski | South-West Asia (Pakistan) | Urdu | Also uses the additional letters shown for Urdu.(see below) Sometimes written with just the Urdu alphabet, or with the Latin alphabet. |
| Chagatai alphabet | 32 | ݣ | Nastaliq and Naskh | Chagatai | Central Asia | Perso-Arabic | ݣ is interchangeable with نگ and ڭ. |
| Galal | 32 | Naskh | Somali | Horn of Africa | Arabic | ||
| Jawi | 36 | ڠ ڤ ݢ ڽ ۏ ى | Naskh | Malay | Peninsular Malaysia, Sumatra and part of Borneo | Perso-Arabic | Since 1303 AD (Trengganu Stone) |
| Kashmiri | 44 | ۆ ۄ ؠ ێ | Nastaliq | Kashmiri | South Asia | Urdu | This orthography is fully voweled. 3 out of the 4 (ۆ, ۄ, ێ) additional glyphs are actually vowels. Not all vowels are listed here since they are not separate letters. For further information, see Kashmiri writing. |
| Kazakh Arabic alphabet | 35 | ٵ ٶ ۇ ٷ ۋ ۆ ە ھ ى ٸ ي | Naskh | Kazakh | Central Asia, China | Chagatai | In use since 11th century, reformed in the early 20th century, now official only in China |
| Khowar | 45 | ݯ ݮ څ ځ ݱ ݰ ڵ | Nastaliq | Khowar | South Asia | Urdu, however, borrows multiple glyphs from Pashto | |
| Kyrgyz Arabic alphabet | 33 | ۅ ۇ ۉ ۋ ە ى ي | Naskh | Kyrgyz | Central Asia | Chagatai | In use since 11th century, reformed in the early 20th century, now official only in China |
| Pashto | 45 | ټ څ ځ ډ ړ ږ ښ ګ ڼ ۀ ي ې ۍ ئ | Naskh and occasionally, Nastaliq | Pashto | South-West Asia, Afghanistan and Pakistan | Perso-Arabic | ګ is interchangeable with گ. Also, the glyphs ی and ې are often replaced with ے in Pakistan. |
| Pegon script | 35 | ڎ ڟ ڠ ڤ ڮ ۑ | Naskh | Javanese, Sundanese | South-East Asia (Indonesia) | Perso-Arabic | |
| Persian | 32 | پ چ ژ گ | Naskh and Nastaliq | Persian (Farsi) | West Asia (Iran etc. ) | Arabic | Also known as Perso-Arabic. |
| Shahmukhi | 41 | ݪ ݨ | Nastaliq | Punjabi | South Asia (Pakistan) | Perso-Arabic | |
| Saraiki | 45 | ٻ ڄ ݙ ڳ | Nastaliq | Saraiki | South Asia (Pakistan) | Urdu | |
| Sindhi | 52 | ڪ ڳ ڱ گ ک پ ڀ ٻ ٽ ٿ ٺ ڻ ڦ ڇ چ ڄ ڃ ھ ڙ ڌ ڏ ڎ ڍ ڊ |
Naskh | Sindhi | South Asia (Pakistan) | Perso-Arabic | |
| Sorabe | 28 | Naskh | Malagasy | Madagascar | Arabic | ||
| Soranî | 33 | ڕ ڤ ڵ ۆ ێ | Naskh | Kurdish languages | Middle-East | Perso-Arabic | Vowels are mandatory, i.e. alphabet |
| Swahili Arabic script | 28 | Naskh | Swahili | Western and Southern Africa | Arabic | ||
| İske imlâ | 35 | ۋ | Naskh | Tatar | Volga region | Chagatai | Used prior to 1920. |
| Ottoman Turkish | 32 | ﭖ ﭺ ﮊ ﮒ ﯓ ﻻ | Ottoman Turkish | Ottoman Empire | Chagatai | Official until 1928 | |
| Urdu | 39+ (see notes) |
ٹ ڈ ڑ ں ہ ھ ے (see notes) |
Nastaliq | Urdu | South Asia | Perso-Arabic | 58 letters including digraphs representing aspirated consonants. بھ پھ تھ ٹھ جھ چھ دھ ڈھ کھ گھ |
| Uyghur | 32 | ئا ئە ھ ئو ئۇ ئۆ ئۈ ۋ ئې ئى | Naskh | Uyghur | China, Central Asia | Chagatai | Reform of older Arabic-script Uyghur orthography that was used prior the 1950s. Vowels are mandatory, i.e. alphabet |
| Wolofal | 33 | ݖ گ ݧ ݝ ݒ | Naskh | Wolof | West Africa | Arabic, however, borrows at least one glyph from Perso-Arabic | |
| Xiao'erjing | 36 | ٿ س﮲ ڞ ي | Naskh | Sinitic languages | China, Central Asia | Chagatai | Used to write Chinese languages by Muslims living in China such as the Hui people. |
| Yaña imlâ | 29 | ئا ئە ئی ئو ئۇ ئ ھ | Naskh | Tatar | Volga region | İske imlâ alphabet | 1920–1927 replaced with Cyrillic |
Current use
Today Iran, Afghanistan, Pakistan, India, and China are the main non-Arabic speaking states using the Arabic alphabet to write one or more official national languages, including Azerbaijani, Baluchi, Brahui, Persian, Pashto, Central Kurdish, Urdu, Sindhi, Kashmiri, Punjabi and Uyghur.
An Arabic alphabet is currently used for the following languages:
Middle East and Central Asia
- Arabic
- Garshuni (or Karshuni) originated in the 7th century, when Arabic became the dominant spoken language in the Fertile Crescent, but Arabic script was not yet fully developed or widely read, and so the Syriac alphabet was used. There is evidence that writing Arabic in this other set of letters (known as Garshuni) influenced the style of modern Arabic script. After this initial period, Garshuni writing has continued to the present day among some Syriac Christian communities in the Arabic-speaking regions of the Levant and Mesopotamia.
- Kazakh in Kazakhstan, China, Iran and Afghanistan
- Kurdish in Northern Iraq and Northwest Iran. (In Turkey and Syria the Latin script is used for Kurdish)
- Kyrgyz by its 150,000 speakers in the Xinjiang Uyghur Autonomous Region in northwestern China, Pakistan, Kyrgyzstan and Afghanistan
- Turkmen in Turkmenistan, Afghanistan and Iran
- Uzbek in Uzbekistan and Afghanistan
- Persian in Iranian Persian and Dari in Afghanistan. It had former use in Tajikistan but is no longer used in Standard Tajik
- Baluchi in Iran, in Pakistan's Balochistan region, Afghanistan and Oman[15]
- Southwestern Iranian languages as Lori dialects and Bakhtiari language[16][17]
- Pashto in Afghanistan and Pakistan, and Tajikistan
- Uyghur changed to Latin script in 1969 and back to a simplified, fully voweled Arabic script in 1983
- Judeo-Arabic languages
- Azerbaijani language in Iran
- Talysh language in Iran
- Mazanderani language in Iran
- Shughni language in Afghanistan
East Asia
- The Chinese language is written by some Hui in the Arabic-derived Xiao'erjing alphabet (see also Sini (script))
- The Turkic Salar language is written by some Salar in the Arabic alphabet
- Uyghur alphabet
South Asia
- Balochi in Pakistan and Iran
- Dari in Afghanistan
- Kashmiri in India and Pakistan (also written in Sharada and Devanagari although Kashmiri is more commonly written in Perso-Arabic Script)
- Pashto in Afghanistan and Pakistan
- Khowar in Northern Pakistan, also uses the Latin script
- Punjabi (Shahmukhi) in Pakistan, also written in the Brahmic script known as Gurmukhi in India
- Saraiki, written with a modified Arabic script – that has 45 letters
- Sindhi, a British commissioner in Sindh on August 29, 1857, ordered to change Arabic script,[19] also written in Devanagari in India
- Aer language[20]
- Bhadrawahi language[21]
- Ladakhi (India), although it is more commonly written using the Tibetan script
- Balti (a Sino-Tibetan language), also rarely written in the Tibetan script
- Brahui language in Pakistan and Afghanistan[22]
- Burushaski or Burusho language, a language isolated to Pakistan.
- Urdu in Pakistan (and historically several other Hindustani languages). Urdu is one of several official languages in the states of Jammu and Kashmir, Delhi, Uttar Pradesh, Bihar, Jharkhand, West Bengal and Telangana.
- Dogri, spoken by about five million people in India and Pakistan, chiefly in the Jammu region of Jammu and Kashmir and in Himachal Pradesh, but also in northern Punjab, although Dogri is more commonly written in Devanagari
- Arwi language (a mixture of Arabic and Tamil) uses the Arabic script together with the addition of 13 letters. It is mainly used in Sri Lanka and the South Indian state of Tamil Nadu for religious purposes. Arwi language is the language of Tamil Muslims
- Arabi Malayalam is Malayalam written in the Arabic script. The script has particular letters to represent the peculiar sounds of Malayalam. This script is mainly used in madrasas of the South Indian state of Kerala and of Lakshadweep.
- Rohingya language (Ruáingga) is a language spoken by the Rohingya people of Rakhine State, formerly known as Arakan (Rakhine), Burma (Myanmar). It is similar to Chittagonian language in neighboring Bangladesh[23] and sometimes written using the Roman script, or an Arabic-derived script known as Hanifi
- Ishkashimi language (Ishkashimi) in Afghanistan
Southeast Asia
- Malay in the Arabic script known as Jawi. In some cases it can be seen in the signboards of shops and market stalls. Particularly in Brunei, Jawi is used in terms of writing or reading for Islamic religious educational programs in primary school, secondary school, college, or even higher educational institutes such as universities. In addition, some television programming uses Jawi, such as announcements, advertisements, news, social programs or Islamic programs
- co-official in Brunei
- Malaysia but co-official in Kelantan and Kedah, Islamic states in Malaysia
- Indonesia, Jawi script is co-used with Latin in provinces of Aceh, Riau, Riau Islands and Jambi. The Javanese, Madurese and Sundanese also use another Arabic variant, the Pegon in Islamic writings and pesantren community.
- Southern Thailand
- Predominantly Muslim areas of the Philippines (especially Tausug language)
- Ida'an language (also Idahan) a Malayo-Polynesian language spoken by the Ida'an people of Sabah, Malaysia[24]
- Cham language in Cambodia besides Western Cham script.
Africa
- North Africa
- Arabic
- Berber languages have often been written in an adaptation of the Arabic alphabet. The use of the Arabic alphabet, as well as the competing Latin and Tifinagh scripts, has political connotations
- Tuareg language, (sometimes called Tamasheq) which is also a Berber language
- Coptic language of Egyptians as Coptic text written in Arabic letters[25]
- Northeast Africa
- Bedawi or Beja, mainly in northeastern Sudan
- Wadaad's writing, used in Somalia
- Nubian languages
- Dongolawi language or Andaandi language of Nubia, in the Nile Vale of northern Sudan
- Nobiin language, the largest Nubian language (previously known by the geographic terms Mahas and Fadicca/Fiadicca) is not yet standardized, being written variously in both Latinized and Arabic scripts; also, there have been recent efforts to revive the Old Nubian alphabet.[26][27]
- Fur language of Darfur, Sudan
- Southeast Africa
- Comorian, in the Comoros, currently side by side with the Latin alphabet (neither is official)
- Swahili, was originally written in Arabic alphabet, Swahili orthography is now based on the Latin alphabet that was introduced by Christian missionaries and colonial administrators
- West Africa
- Zarma language of the Songhay family. It is the language of the southwestern lobe of the West African nation of Niger, and it is the second leading language of Niger, after Hausa, which is spoken in south central Niger[28]
- Tadaksahak is a Songhay language spoken by the pastoralist Idaksahak of the Ménaka area of Mali[29]
- Hausa language uses an adaptation of the Arabic script known as Ajami, for many purposes, especially religious, but including newspapers, mass mobilization posters and public information[30]
- Dyula language is a Mandé language spoken in Burkina Faso, Côte d'Ivoire and Mali.[31]
- Jola-Fonyi language of the Casamance region of Senegal[32]
- Balanta language a Bak language of west Africa spoken by the Balanta people and Balanta-Ganja dialect in Senegal
- Mandinka, widely but unofficially (known as Ajami), (another non-Latin script used is the N'Ko script)
- Fula, especially the Pular of Guinea (known as Ajami)
- Wolof (at zaouia schools), known as Wolofal.
- Yoruba, earliest attested history of use since 17th Century, however earliest verifiable history of use dates to the 19th Century. Yoruba Ajami used in Muslim praise verse, poetry, personal and esoteric use[33]
- Arabic script outside Africa
- In writings of African American slaves
- Writings of by Omar Ibn Said (1770–1864) of Senegal[34]
- The Bilali Document also known as Bilali Muhammad Document is a handwritten, Arabic manuscript[35] on West African Islamic law. It was written by Bilali Mohammet in the 19th century. The document is currently housed in the library at the University of Georgia
- Letter written by Ayuba Suleiman Diallo (1701–1773)
- Arabic Text From 1768[36]
- Letter written by Abdul Rahman Ibrahima Sori (1762–1829)
- In writings of African American slaves
Former use
With the establishment of Muslim rule in the subcontinent, one or more forms of the Arabic script were incorporated among the assortment of scripts used for writing native languages.[37] In the 20th century, the Arabic script was generally replaced by the Latin alphabet in the Balkans, parts of Sub-Saharan Africa, and Southeast Asia, while in the Soviet Union, after a brief period of Latinisation,[38] use of Cyrillic was mandated. Turkey changed to the Latin alphabet in 1928 as part of an internal Westernizing revolution. After the collapse of the Soviet Union in 1991, many of the Turkic languages of the ex-USSR attempted to follow Turkey's lead and convert to a Turkish-style Latin alphabet. However, renewed use of the Arabic alphabet has occurred to a limited extent in Tajikistan, whose language's close resemblance to Persian allows direct use of publications from Afghanistan and Iran.[39]
Africa
- Afrikaans (as it was first written among the "Cape Malays", see Arabic Afrikaans)
- Berber in North Africa, particularly Shilha in Morocco (still being considered, along with Tifinagh and Latin, for Central Atlas Tamazight)
- French by the Arabs and Berbers in Algeria and other parts of North Africa during the French colonial period
- Harari, by the Harari people of the Harari Region in Ethiopia. Now uses the Geʻez and Latin alphabets
- For the West African languages—Hausa, Fula, Mandinka, Wolof and some more (e.g. Yoruba)—the Latin alphabet has officially replaced Arabic transcriptions for use in literacy and education
- Kinyarwanda in Rwanda
- Kirundi in Burundi
- Malagasy in Madagascar (script known as Sorabe)
- Nubian
- Shona in Zimbabwe
- Somali (see wadaad's Arabic) has mostly used the Latin alphabet since 1972
- Songhay in West Africa, particularly in Timbuktu
- Swahili (has used the Latin alphabet since the 19th century)
- Yoruba in West Africa
Europe
- Albanian called Elifbaja shqip
- Aljamiado (Mozarabic, Berber, Aragonese, Portuguese, Ladino, and Spanish, during and residually after the Muslim rule in the Iberian peninsula)
- Belarusian (among ethnic Tatars; see Belarusian Arabic alphabet)
- Bosnian (only for literary purposes; currently written in the Latin alphabet; Text example: مۉلٖىمۉ سه تهبٖى بۉژه = Molimo se tebi, Bože (We pray to you, O God); see Arebica)
- Crimean Tatar
- Greek in certain areas in Greece and Anatolia. In particular, Cappadocian Greek written in Perso-Arabic
- Polish (among ethnic Lipka Tatars)
Central Asia and Caucasus
- Adyghe language also known as West Circassian, is an official languages of the Republic of Adygea in the Russian Federation. It used Arabic alphabet before 1927
- Avar as well as other languages of Daghestan: Nogai, Kumyk, Lezgian, Lak and Dargwa
- Azeri in Azerbaijan (now written in the Latin alphabet and Cyrillic script in Azerbaijan)
- Bashkir (officially for some years from the October Revolution of 1917 until 1928, changed to Latin, now uses the Cyrillic script)
- Chaghatay across Central Asia
- Chechen (sporadically from the adoption of Islam; officially from 1917 until 1928)[40]
- Circassian and some other members of the Abkhaz–Adyghe family in the western Caucasus and sporadically – in the countries of Middle East, like Syria
- Ingush
- Karachay-Balkar in the central Caucasus
- Karakalpak
- Kazakh in Kazakhstan (until the 1930s, changed to Latin, currently using Cyrillic, phasing in Latin)
- Kyrgyz in Kyrgyzstan (until the 1930s, changed to Latin, now uses the Cyrillic script)
- Mandarin Chinese and Dungan, among the Hui people (script known as Xiao'erjing)
- Ottoman Turkish
- Tat in South-Eastern Caucasus
- Tatar before 1928 (changed to Latin Yañalif), reformed in the 1880s (İske imlâ), 1918 (Yaña imlâ – with the omission of some letters)
- Turkmen in Turkmenistan (changed to Latin in 1929, then to the Cyrillic script, then back to Latin in 1991)
- Uzbek in Uzbekistan (changed to Latin, then to the Cyrillic script, then back to Latin in 1991)
- Some Northeast Caucasian languages of the Muslim peoples of the USSR between 1918 and 1928 (many also earlier), including Chechen, Lak, etc. After 1928, their script became Latin, then later Cyrillic
South and Southeast Asia
- Acehnese in Sumatra, Indonesia
- Assamese in Assam, India
- Banjarese in Kalimantan, Indonesia
- Bengali in Bengal, Arabic scripts have been used historically in places like Chittagong and West Bengal among other places. See Dobhashi for further information.
- Maguindanaon in the Philippines
- Malay in Malaysia, Singapore and Indonesia. Although Malay speakers in Brunei and Southern Thailand still use the script on a daily basis
- Minangkabau in Sumatra, Indonesia
- Pegon script of Javanese, Madurese and Sundanese in Indonesia, used only in Islamic schools and institutions
- Tausug in the Philippines, Malaysia, and Indonesia it can be used in Islamic schools in the Philippines
- Maranao in the Philippines
- Rakhine in Burma and Bangladesh
- Mongolian in Afghanistan There is also a language in the Mongolic family that spoken in the Afghanistan it is called Mogholi language
- Tagalog in the Philippines
- Yakan in Basilan
- Aslian in Malaysia
- Ternate in Indonesia by the Muslims
- Tidore in Indonesia
- Meitei in Bangladesh
- Shughni in Afghanistan
- Thai in Malaysia
- Sylheti in Arakan, Bengal, Chittagong, and Tripura
- Kedah Malay in Myanmar, Malaysia, and Thailand
- Uab Meto in Indonesia
- Molbog in Sabah used by the Muslims even though in Palawan
- Bonggi in Sabah by the Muslims
- Kadazan in Malaysia is a Muslim language
- Dusun used in Brunei, and Malaysia
- Sama used in Philippines, Malaysia, and Indonesia
- Bajau is in Philippines, Malaysia, and Indonesia
- Sarawak Bisaya used in Malaysia, and Brunei
- Sabah Bisaya is used in Sabah
- Lotud spoken in Malaysia only
- Lun Bawang in Sarawak, Sabah, Temburong and Kalimantan
- Tiruray in the Bangsamoro
- Chavacano in Cotabato, Zamboanga Peninsula, Sulu, Basilan, Tawi-Tawi, Sabah, and Kalimantan
- Maranao has Arabic script in Lanao del Sur, Lanao del Norte, and Sabah
- Iranun used in Islamic schools in Mindanao,and Malaysia
Middle East
- Hebrew was written in Arabic letters in a number of places in the past[41][42]
- Northern Kurdish in Turkey and Syria was written in Arabic script until 1932, when a modified Kurdish Latin alphabet was introduced by Jaladat Ali Badirkhan in Syria
- Turkish in the Ottoman Empire was written in Arabic script until Mustafa Kemal Atatürk declared the change to Latin script in 1928. This form of Turkish is now known as Ottoman Turkish and is held by many to be a different language, due to its much higher percentage of Persian and Arabic loanwords (Ottoman Turkish alphabet)
Unicode
As of Unicode 15.1, the following ranges encode Arabic characters:
- Arabic (0600–06FF)
- Arabic Supplement (0750–077F)
- Arabic Extended-A (08A0–08FF)
- Arabic Extended-B (0870–089F)
- Arabic Extended-C (10EC0–10EFF)
- Arabic Presentation Forms-A (FB50–FDFF)
- Arabic Presentation Forms-B (FE70–FEFF)
- Arabic Mathematical Alphabetic Symbols (1EE00–1EEFF)
- Rumi Numeral Symbols (10E60–10E7F)
- Indic Siyaq Numbers (1EC70–1ECBF)
- Ottoman Siyaq Numbers (1ED00–1ED4F)
Additional letters used in other languages
Assignment of phonemes to graphemes
| Language family | Austron. | Dravid | Turkic | Indic | Iranian | Germanic | Arabic | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Language/script | Jawi | Pegon | Arwi | Ottoman | Uyghur | Tatars | Sindhi | Punjabi | Urdu | Persian | Balochi | Kurdish | Pashto | Afrikaans | Moroccan | Tunisian | Algerian | Egyptian | Najdi | Hejazi | Levantine | Iraqi | Gulf | |
| /p/ | ڤ | ڣ | پ | پ / ب | ||||||||||||||||||||
| /g/ | ݢ | ؼ | گ | ګ | گ | ڭ / گ | ڨ / ڧـ ـڧـ ـٯ / ق | ج | ق | ك / ج | گ / ك | ق / گ | ||||||||||||
| /t͡ʃ/ | چ | ∅ | چ | ڜ | تش | چ | ||||||||||||||||||
| /v/ | ۏ | ف | و | ۋ | و | ∅ | ڤ | ∅ | ڤ | ڥ / ڢ / ف | ڤ / ف | |||||||||||||
| /ʒ/ | ∅ | ژ | ∅ | ژ | ج | ∅ | چ / ج | ∅ | ج | ∅ | ||||||||||||||
| /ŋ/ | ڠ | ࢳ | ڭ | ڱ | ن٘ | ∅ | ڠ | ∅ | ||||||||||||||||
| /ɳ/ | ∅ | ∅ | ڹ | ∅ | ڻ | ݨ | ن | ∅ | ڼ | ∅ | ∅ | |||||||||||||
| /ɲ/ | ڽ | ۑ | ݧ | ∅ | ڃ | نج | ∅ | ∅ | ||||||||||||||||
| Letter or Digraph [upper-alpha 1] | Use & Pronunciation | Unicode | i'jam & other additions | Shape | Similar Arabic Letter(s) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| U+ | [upper-alpha 2] | [upper-alpha 3] | above | below | |||||||
| پ | پـ ـپـ ـپ | Pe, used to represent the phoneme /p/ in Persian, Pashto, Punjabi, Khowar, Sindhi, Urdu, Kurdish, Kashmiri; it can be used in Arabic to describe the phoneme /p/ otherwise it is normalized to /b/ ب e.g. پول Paul also written بول | U+067E | ﮹ | none | 3 dots | ٮ | ب | |||
| ݐ | ݐـ ـݐـ ـݐ | used to represent the equivalent of the Latin letter Ƴ (palatalized glottal stop /ʔʲ/) in some African languages such as Fulfulde. | U+0750 | ﮳﮳﮳ | none | 3 dots (horizontal) |
ٮ | ب | |||
| ٻ | ٻـ ـٻـ ـٻ | B̤ē, used to represent a voiced bilabial implosive /ɓ/ in Hausa, Sindhi and Saraiki. | U+067B | ﮾ | none | 2 dots (vertically) |
ٮ | ب | |||
| ڀ | ڀـ ـڀـ ـڀ | represents an aspirated voiced bilabial plosive /bʱ/ in Sindhi. | U+0680 | ﮻ | none | 4 dots | ٮ | ب | |||
| ٺ | ٺـ ـٺـ ـٺ | Ṭhē, represents the aspirated voiceless retroflex plosive /ʈʰ/ in Sindhi. | U+067A | ﮽ | 2 dots (vertically) |
none | ٮ | ت | |||
| ټ | ټـ ـټـ ـټ | Ṭē, used to represent the phoneme /ʈ/ in Pashto. | U+067C | ﮿ | ﮴ | 2 dots | ring | ٮ | ت | ||
| ٽ | ٽـ ـٽـ ـٽ | Ṭe, used to represent the phoneme (a voiceless retroflex plosive /ʈ/) in Sindhi | U+067D | ﮸ | 3 dots (inverted) |
none | ٮ | ت | |||
| ﭦ | ٹـ ـٹـ ـٹ | Ṭe, used to represent Ṭ (a voiceless retroflex plosive /ʈ/) in Punjabi, Kashmiri, Urdu. | U+0679 | ◌ؕ | small ط |
none | ٮ | ت | |||
| ٿ | ٿـ ـٿـ ـٿ | Teheh, used in Sindhi and Rajasthani (when written in Sindhi alphabet); used to represent the phoneme /t͡ɕʰ/ (pinyin q) in Chinese Xiao'erjing. | U+067F | ﮺ | 4 dots | none | ٮ | ت | |||
| ڄ | ڄـ ـڄـ ـڄ | represents the "c" voiceless dental affricate /t͡s/ phoneme in Bosnian. | U+0684 | ﮾ | none | 2 dots (vertically) |
ح | ج | |||
| ڃ | ڃـ ـڃـ ـڃ | represents the "ć" voiceless alveolo-palatal affricate /t͡ɕ/ phoneme in Bosnian. | U+0683 | ﮵ | none | 2 dots | ح | ح ج | |||
| چ | چـ ـچـ ـچ | Che, used to represent /t͡ʃ/ ("ch"). It is used in Persian, Pashto, Punjabi, Urdu, Kashmiri and Kurdish. /ʒ/ in Egypt. | U+0686 | ﮹ | none | 3 dots | ح | ج | |||
| څ | څـ ـڅـ ـڅ | Ce, used to represent the phoneme /t͡s/ in Pashto. | U+0685 | ﮶ | 3 dots | none | ح | ج خ ح | |||
| ݗ | ݗـ ـݗـ ـݗ | represents the "đ" voiced alveolo-palatal affricate /d͡ʑ/ phoneme in Bosnian. | U+0757 | ﮴ | 2 dots | none | ح | ح | |||
| ځ | ځـ ـځـ ـځ | Źim, used to represent the phoneme /d͡z/ in Pashto. | U+0681 | ◌ٔ | Hamza | none | ح | ج خ ح | |||
| ݙ | ݙ ـݙ | used in Saraiki to represent a Voiced alveolar implosive /ɗ̢/. | U+0759 | ﯀ | ﮾ | small ط |
2 dots (vertically) |
د | د | ||
| ڊ | ڊ ـڊ | used in Saraiki to represent a voiced retroflex implosive /ᶑ/. | U+068A | ﮳ | none | 1 dot | د | د | |||
| ڈ | ڈ ـڈ | Ḍal, used to represent a Ḍ (a voiced retroflex plosive /ɖ/) in Punjabi, Kashmiri and Urdu. | U+0688 | ◌ؕ | small ط | none | د | د | |||
| ڌ | ڌ ـڌ | Dhal, used to represent the phoneme /d̪ʱ/ in Sindhi | U+068C | ﮴ | 2 dots | none | د | د | |||
| ډ | ډ ـډ | Ḍal, used to represent the phoneme /ɖ/ in Pashto. | U+0689 | ﮿ | none | ring | د | د | |||
| ڑ | ڑ ـڑ | Ṛe, represents a retroflex flap /ɽ/ in Punjabi and Urdu. | U+0691 | ◌ؕ | small ط | none | ر | ر | |||
| ړ | ړ ـړ | Ṛe, used to represent a retroflex lateral flap in Pashto. | U+0693 | ﮿ | none | ring | ر | ر | |||
| ݫ | ݫ ـݫ | used in Ormuri to represent a voiced alveolo-palatal fricative /ʑ/, as well as in Torwali. | U+076B | ﮽ | 2 dots (vertically) |
none | ر | ر | |||
| ژ | ژ ـژ | Že / zhe, used to represent the voiced postalveolar fricative /ʒ/ in, Persian, Pashto, Kurdish, Urdu, Punjabi and Uyghur. | U+0698 | ﮶ | 3 dots | none | ر | ز | |||
| ږ | ږ ـږ | Ǵe / ẓ̌e, used to represent the phoneme /ʐ/ /ɡ/ /ʝ/ in Pashto. | U+0696 | ﮲ | ﮳ | 1 dot | 1 dot | ر | ز | ||
| ڕ | ڕ ـڕ | used in Kurdish to represent rr /r/ in Soranî dialect. | U+0695 | ٚ | none | V pointing down | ر | ر | |||
| ݭ | ݭـ ـݭـ ـݭ | used in Kalami to represent a voiceless retroflex fricative /ʂ/, and in Ormuri to represent a voiceless alveolo-palatal fricative /ɕ/. | U+076D | ﮽ | 2 dots vertically | none | س | س | |||
| ݜ | ݜـ ـݜـ ـݜ | used in Shina to represent a voiceless retroflex fricative /ʂ/. | U+075C | ﮺ | 4 dots | none | س | ش س | |||
| ښ | ښـ ـښـ ـښ | X̌īn / ṣ̌īn, used to represent the phoneme /x/ /ʂ/ /ç/ in Pashto. | U+069A | ﮲ | ﮳ | 1 dot | 1 dot | س | ش س | ||
| ڜ | ڜـ ـڜـ ـڜ | Unofficially used to represent Spanish words with /t͡ʃ/ in Morocco. | U+069C | ﮶ | ﮹ | 3 dots | 3 dots | س | ش س | ||
| ڨ | ڨـ ـڨـ ـڨ | Ga, used to represent the voiced velar plosive /ɡ/ in Algerian and Tunisian. | U+06A8 | ﮶ | 3 dots | none | ٯ | ق | |||
| گ | گـ ـگـ ـگ | Gaf, represents a voiced velar plosive /ɡ/ in Persian, Pashto, Punjabi, Kyrgyz, Kazakh, Kurdish, Uyghur, Mesopotamian Arabic, Urdu and Ottoman Turkish. | U+06AF | line | horizontal line | none | گ | ك | |||
| ګ | ګـ ـګـ ـګ | Gaf, used to represent the phoneme /ɡ/ in Pashto. | U+06AB | ﮿ | ring | none | ک | ك | |||
| ݢ | ݢـ ـݢـ ـݢ | Gaf, represents a voiced velar plosive /ɡ/ in the Jawi script of Malay. | U+0762 | ﮲ | 1 dot | none | ک | ك | |||
| ڬ | ڬـ ـڬـ ـڬ | U+06AC | ﮲ | 1 dot | none | ك | ك | ||||
| ؼ | ؼـ ـؼـ ـؼ | Gaf, represents a voiced velar plosive /ɡ/ in the Pegon script of Indonesian. | U+08B4 | ﮳ | none | 3 dots | | ك | |||
| ڭ | ڭـ ـڭـ ـڭ | Ng, used to represent the /ŋ/ phone in Ottoman Turkish, Kazakh, Kyrgyz, and Uyghur, and to unofficially represent the /ɡ/ in Morocco and in many dialects of Algerian. | U+06AD | ﮶ | 3 dots | none | ك | ك | |||
| أي | أيـ ـأيـ ـأي | Ee, used to represent the phoneme /eː/ in Somali. | U+0623 U+064A | ◌ٔ | ﮵ | Hamza | 2 dots | اى | أ + ي | ||
| ئ | ئـ ـئـ ـئ | E, used to represent the phoneme /e/ in Somali. | U+0626 | ◌ٔ | Hamza | none | ى | ي ی | |||
| ىٓ | ىٓـ ـىٓـ ـىٓ | Ii, used to represent the phoneme /iː/ in Somali and Saraiki. | U+0649 U+0653 | ◌ٓ | Madda | none | ى | ي | |||
| ؤ | ؤ ـؤ | O, used to represent the phoneme /o/ in Somali. | U+0624 | ◌ٔ | Hamza | none | و | ؤ | |||
| ۅ | ۅ ـۅ | Ö, used to represent the phoneme /ø/ in Kyrgyz. | U+0624 | ◌̵ | Strikethrough[upper-alpha 4] | none | و | و | |||
| ې | ېـ ـېـ ـې | Pasta Ye, used to represent the phoneme /e/ in Pashto and Uyghur. | U+06D0 | ﮾ | none | 2 dots vertical | ى | ي | |||
| ی | یـ ـیـ ـی | Nārīna Ye, used to represent the phoneme [ɑj] and phoneme /j/ in Pashto. | U+06CC | ﮵ | 2 dots (start + mid) |
none | ى | ي | |||
| ۍ | ـۍ | end only |
X̌əźīna ye Ye, used to represent the phoneme [əi] in Pashto. | U+06CD | line | horizontal line |
none | ى | ي | ||
| ئ | ئـ ـئـ ـئ | Fāiliya Ye, used to represent the phoneme [əi] and /j/ in Pashto, Punjabi, Saraiki and Urdu | U+0626 | ◌ٔ | Hamza | none | ى | ي ى | |||
| أو | أو ـأو | Oo, used to represent the phoneme /oː/ in Somali. | U+0623 U+0648 | ◌ٔ | Hamza | none | او | أ + و | |||
| ﻭٓ | ﻭٓ ـﻭٓ | Uu, used to represent the phoneme /uː/ in Somali. | ﻭ + ◌ٓ U+0648 U+0653 | ◌ٓ | Madda | none | و | ﻭ + ◌ٓ | |||
| ڳ | ڳـ ـڳـ ـڳ | represents a voiced velar implosive /ɠ/ in Sindhi and Saraiki | U+06B1 | ﮾ | horizontal line |
2 dots | گ | ك | |||
| ڱ | ڱـ ـڱـ ـڱ | represents the Velar nasal /ŋ/ phoneme in Sindhi. | U+06B1 | ﮴ | 2 dots + horizontal line |
none | گ | ك | |||
| ک | کـ ـکـ ـک | Khē, represents /kʰ/ in Sindhi. | U+06A9 | none | none | none | ک | ك | |||
| ڪ | ڪـ ـڪـ ـڪ | "Swash kāf" is a stylistic variant of ك in Arabic, but represents un- aspirated /k/ in Sindhi. | U+06AA | none | none | none | ڪ | ك or ڪ | |||
| ݣ | ݣـ ـݣـ ـݣ | used to represent the phoneme /ŋ/ (pinyin ng) in Chinese. | U+0763 | ﮹ | none | 3 dots | ک | ك | |||
| ڼ | ڼـ ـڼـ ـڼ | represents the retroflex nasal /ɳ/ phoneme in Pashto. | U+06BC | ﮲ | ﮿ | 1 dot | ring | ں | ن | ||
| ڻ | ڻـ ـڻـ ـڻ | represents the retroflex nasal /ɳ/ phoneme in Sindhi. | U+06BB | ◌ؕ | small ط | none | ں | ن | |||
| ݨ | ݨـ ـݨـ ـݨ | used in Punjabi to represent /ɳ/ and Saraiki to represent /ɲ/. | U+0768 | ﮲ | ﯀ | 1 dot + small ط | none | ں | ن | ||
| ڽ | ڽـ ـڽـ ـڽ | Nya /ɲ/ in the Jawi script. | U+06BD | ﮶ | 3 dots | none | ں | ن | |||
| ۑ | ۑـ ـۑـ ـۑ | Nya /ɲ/ in the Pegon script. | U+06D1 | ﮹ | none | 3 dots | ى | ى | |||
| ڠ | ڠـ ـڠـ ـڠ | Nga /ŋ/ in the Jawi script and Pegon script. | U+06A0 | ﮶ | 3 dots | none | ع | غ | |||
| ݪ | ݪـ ـݪـ ـݪ | used in Marwari to represent a retroflex lateral flap /ɺ̢/, and in Kalami to represent a voiceless lateral fricative /ɬ/. | U+076A | line | horizontal line |
none | ل | ل | |||
| ࣇ | ࣇ ࣇ ࣇ | ࣇ – or alternately typeset as لؕ – is used in Punjabi to represent voiced retroflex lateral approximant /ɭ/[43] | U+08C7 | ◌ؕ | small ط | none | ل | ل | |||
| لؕ | لؕـ ـلؕـ ـلؕ | U+0644 U+0615 | |||||||||
| ڥ | ڥـ ـڥـ ـڥ | Vi, used in Algerian Arabic and Tunisian Arabic when written in Arabic script to represent the sound /v/ (unofficial). | U+06A5 | ﮹ | none | 3 dots | ڡ | ف | |||
| ڤ | ڤـ ـڤـ ـڤ | Ve, used in by some Arabic speakers to represent the phoneme /v/ in loanwords, and in the Kurdish language when written in Arabic script to represent the sound /v/. Also used as pa /p/ in the Jawi script and Pegon script. | U+06A4 | ﮶ | 3 dots | none | ڡ | ف | |||
| ۏ | ۏ ـۏ | Va in the Jawi script. | U+06CF | ﮲ | 1 dot | none | و | و | |||
| ۋ | ۋ ـۋ | represents a voiced labiodental fricative /v/ in Kyrgyz, Uyghur, and Old Tatar; and /w, ʊw, ʉw/ in Kazakh; also formerly used in Nogai. | U+06CB | ﮶ | 3 dots | none | و | و | |||
| ۆ | ۆ ـۆ | represents "O" /o/ in Kurdish, and in Uyghur it represents the sound similar to the French eu and œu /ø/ sound. It represents the "у" close back rounded vowel /u/ phoneme in Bosnian. | U+06C6 | ◌ٚ | V pointing down | none | و | و | |||
| ۇ | ۇ ـۇ | U, used to represents the Close back rounded vowel /u/ phoneme in Azerbaijani, Kazakh, Kyrgyz and Uyghur. | U+06C7 | ◌ُ | Damma[upper-alpha 5] | none | و | و | |||
| ێ | ێـ ـێـ ـێ | represents Ê or É /e/ in Kurdish. | U+06CE | ◌ٚ | V pointing down | 2 dots (start + mid) |
ى | ي | |||
| ھ ھ |
ھـ ـھـ ـھ ھھھ |
Do-chashmi he (two-eyed hāʼ), used in digraphs for aspiration /ʰ/ and breathy voice /ʱ/ in Punjabi and Urdu. Also used to represent /h/ in Kazakh, Sorani and Uyghur.[upper-alpha 6] | U+06BE | none | none | none | ھ | ه | |||
| ە | ە ـە | Ae, used represent /æ/ and /ɛ/ in Kazakh, Sorani and Uyghur. | U+06D5 | none | none | none | ھ | إ | |||
| ے | ـے | end only |
Baṛī ye ('big yāʼ'), is a stylistic variant of ي in Arabic, but represents "ai" or "e" /ɛː/, /eː/ in Urdu and Punjabi. | U+06D2 | none | none | none | ے | ي | ||
| ڞ | ڞـ ـڞـ ـڞ | used to represent the phoneme /tsʰ/ (pinyin c) in Chinese. | U+069E | ﮶ | 3 dots | none | ص | ص ض | |||
| ط | طـ ـطـ ـط | used to represent the phoneme /t͡s/ (pinyin z) in Chinese. | U+0637 | ط | ط | ||||||
| ۉ | ۉ ـۉ | represents the "o" open-mid back rounded vowel /ɔ/ phoneme in Bosnian. | U+06C9 | ◌ٛ | V pointing up | none | و | و | |||
| ݩ | ݩـ ـݩـ ـݩ | represents the "nj" palatal nasal /ɲ/ phoneme in Bosnian. | U+0769 | ﮲ | ◌ٚ | 1 dot V pointing down |
none | ں | ن | ||
| ڵ | ڵـ ـڵـ ـڵ | used in Kurdish to represent ll /ɫ/ in Soranî dialect. | U+06B5 | ◌ٚ | V pointing down | none | ل | ل | |||
| ڵ | ڵـ ـڵـ ـڵ | represents the "lj" palatal lateral approximant /ʎ/ phoneme in Bosnian. | U+06B5 | ◌ٚ | V pointing down | none | ل | ل | |||
| اٖى | اٖىـ ـاٖىـ ـاٖى | represents the "i" close front unrounded vowel /i/ phoneme in Bosnian. | U+0627 U+0656 U+0649 | ◌ٖ | Alef | none | اى | اٖ + ى | |||
- Footnotes:
- From right: start, middle, end, and isolated forms.
- Joined to the letter, closest to the letter, on the first letter, or above.
- Further away from the letter, or on the second letter, or below.
- A variant that end up with loop also exists.
- Although the letter also known as Waw with Damma, some publications and fonts features filled Damma that looks similar to comma.
- Shown in Naskh (top) and Nastaliq (bottom) styles. The Nastaliq version of the connected forms are connected to each other, because the tatweel character U+0640 used to show the other forms does not work in many Nastaliq fonts.
Letter construction
Most languages that use alphabets based on the Arabic alphabet use the same base shapes. Most additional letters in languages that use alphabets based on the Arabic alphabet are built by adding (or removing) diacritics to existing Arabic letters. Some stylistic variants in Arabic have distinct meanings in other languages. For example, variant forms of kāf ك ک ڪ are used in some languages and sometimes have specific usages. In Urdu and some neighbouring languages, the letter Hā has diverged into two forms ھ dō-čašmī hē and ہ ہـ ـہـ ـہ gōl hē,[44] while a variant form of ي yā referred to as baṛī yē ے is used at the end of some words.[44]
Table of Letter Components
See also
- Arabic (Unicode block)
- Eastern Arabic numerals (digit shapes commonly used with Arabic script)
- History of the Arabic alphabet
- Transliteration of Arabic
- Xiao'erjing
References
- Daniels, Peter T.; Bright, William, eds. (1996). The World's Writing Systems. Oxford University Press, Inc. p. 559. ISBN 978-0195079937.
- "Arabic Alphabet". Encyclopædia Britannica online. Archived from the original on 26 April 2015. Retrieved 2015-05-16.
- Vaughan, Don. "The World's 5 Most Commonly Used Writing Systems". Encyclopædia Britannica. Archived from the original on 2023-07-29. Retrieved 2023-07-29.
- Mahinnaz Mirdehghan. 2010. Persian, Urdu, and Pashto: A comparative orthographic analysis. Writing Systems Research Vol. 2, No. 1, 9–23.
- "Exposición Virtual. Biblioteca Nacional de España". Bne.es. Archived from the original on 2012-02-18. Retrieved 2012-04-06.
- Ahmad, Syed Barakat. (11 January 2013). Introduction to Qur'anic script. Routledge. ISBN 978-1-136-11138-9. OCLC 1124340016.
- Gruendler, Beatrice (1993). The Development of the Arabic Scripts: From the Nabatean Era to the First Islamic Century According to Dated Texts. Scholars Press. p. 1. ISBN 9781555407100.
- Healey, John F.; Smith, G. Rex (2012-02-13). "II - The Origin of the Arabic Alphabet". A Brief Introduction to The Arabic Alphabet. Saqi. ISBN 9780863568817.
- Senner, Wayne M. (1991). The Origins of Writing. U of Nebraska Press. p. 100. ISBN 0803291671.
- "Nabataean abjad". www.omniglot.com. Retrieved 2017-03-08.
- Naveh, Joseph. "Nabatean Language, Script and Inscriptions" (PDF).
- Taylor, Jane (2001). Petra and the Lost Kingdom of the Nabataeans. I.B.Tauris. p. 152. ISBN 9781860645082.
- "Zribi, I., Boujelbane, R., Masmoudi, A., Ellouze, M., Belguith, L., & Habash, N. (2014). A Conventional Orthography for Tunisian Arabic. In Proceedings of the Language Resources and Evaluation Conference (LREC), Reykjavík, Iceland".
- Brustad, K. (2000). The syntax of spoken Arabic: A comparative study of Moroccan, Egyptian, Syrian, and Kuwaiti dialects. Georgetown University Press.
- "Sayad Zahoor Shah Hashmii". baask.com.
- Sarlak, Riz̤ā (2002). "Dictionary of the Bakhtiari dialect of Chahar-lang". google.com.eg.
- Iran, Mojdeh (5 February 2011). "Bakhtiari Language Video (bak) بختياري ها! خبری مهم" – via Vimeo.
- "Ethnologue". Retrieved Feb 1, 2020.
- "Pakistan should mind all of its languages!". tribune.com.pk. June 2011.
- "Ethnologue". Retrieved Feb 1, 2020.
- "Ethnologue". Retrieved Feb 1, 2020.
- "The Bible in Brahui". Worldscriptures.org. Archived from the original on October 30, 2016. Retrieved August 5, 2013.
- "Rohingya Language Book A-Z". Scribd.
- "Ida'an". scriptsource.org.
- "The Coptic Studies' Corner". stshenouda.com. Archived from the original on 2012-04-19. Retrieved 2012-04-17.
- "--The Cradle of Nubian Civilisation--". thenubian.net. Archived from the original on 2012-04-24. Retrieved 2012-04-17.
- "2 » AlNuba egypt". 19 July 2012. Archived from the original on 19 July 2012.
- "Zarma". scriptsource.org.
- "Tadaksahak". scriptsource.org.
- "Lost Language — Bostonia Summer 2009". bu.edu.
- "Dyula". scriptsource.org.
- "Jola-Fonyi". scriptsource.org.
- "African Arabic-Script Languages Title: From the 'Sacred' to the 'Profane': the Yoruba Ajami Script and the Challenges of a Standard Orthography". researchgate.net. October 2021.
- "Ibn Sayyid manuscript". Archived from the original on 2015-09-08. Retrieved 2018-09-27.
- "Muhammad Arabic letter". Archived from the original on 2015-09-08. Retrieved 2018-09-27.
- "Charno Letter". Muslims In America. Archived from the original on May 20, 2013. Retrieved August 5, 2013.
- Asani, Ali S. (2002). Ecstasy and enlightenment : the Ismaili devotional literature of South Asia. Institute of Ismaili Studies. London: I.B. Tauris. p. 124. ISBN 1-86064-758-8. OCLC 48193876.
- Alphabet Transitions – The Latin Script: A New Chronology – Symbol of a New Azerbaijan Archived 2007-04-03 at the Wayback Machine, by Tamam Bayatly
- Sukhail Siddikzoda. "Tajik Language: Farsi or Not Farsi?" (PDF). Archived from the original (PDF) on June 13, 2006.
- "Brief history of writing in Chechen". Archived from the original on December 23, 2008.
- p. 20, Samuel Noel Kramer. 1986. In the World of Sumer: An Autobiography. Detroit: Wayne State University Press.
- J. Blau. 2000. Hebrew written in Arabic characters: An instance of radical change in tradition. (In Hebrew, with English summary). In Heritage and Innovation in Judaeo-Arabic Culture: Proceedings of the Sixth Conference of the Society For Judaeo-Arabic Studies, p. 27-31. Ramat Gan.
- Lorna Priest Evans; M. G. Abbas Malik. "Proposal to encode ARABIC LETTER LAM WITH SMALL ARABIC LETTER TAH ABOVE in the UCS" (PDF). www.unicode.org. Retrieved 10 May 2020.
- "Urdu Alphabet". www.user.uni-hannover.de. Archived from the original on 11 September 2019. Retrieved 4 May 2020.
External links
- Unicode collation charts—including Arabic letters, sorted by shape
- "Why the right side of your brain doesn't like Arabic"
- Arabic fonts by SIL's Non-Roman Script Initiative
- Alexis Neme and Sébastien Paumier (2019), "Restoring Arabic vowels through omission-tolerant dictionary lookup", Lang Resources & Evaluation, Vol. 53, pp. 1–65. arXiv:1905.04051; doi:10.1007/s10579-019-09464-6
| Europe | |
|---|---|
| Asia | |
| Africa | |
| |
Arabic language | |||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Overviews | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Scripts | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Letters | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Varieties |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| Academic | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Linguistics | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Calligraphy · Script | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Technical |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||